HTTP协议的缓存控制和Squid的配置迅雷为什优化(这里有关于迅雷为什么下的快的原因)
Posted 健身IT青年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTP协议的缓存控制和Squid的配置迅雷为什优化(这里有关于迅雷为什么下的快的原因)相关的知识,希望对你有一定的参考价值。
最佳实践2:理解HTTP协议中的缓存控制——服务器端缓存控制头部信息
介绍前我们要知道三点:
HTTP协议采用客户端请求(Request)、服务器端响应(Response)的模型。
在请求和响应中,都能通过相关控制指令对对端的缓存行为进行管理。
服务器端响应中的缓存控制头部,利用这些头部控制信息可以精细化地管理客户端的缓存行为。
以wget命令为例:
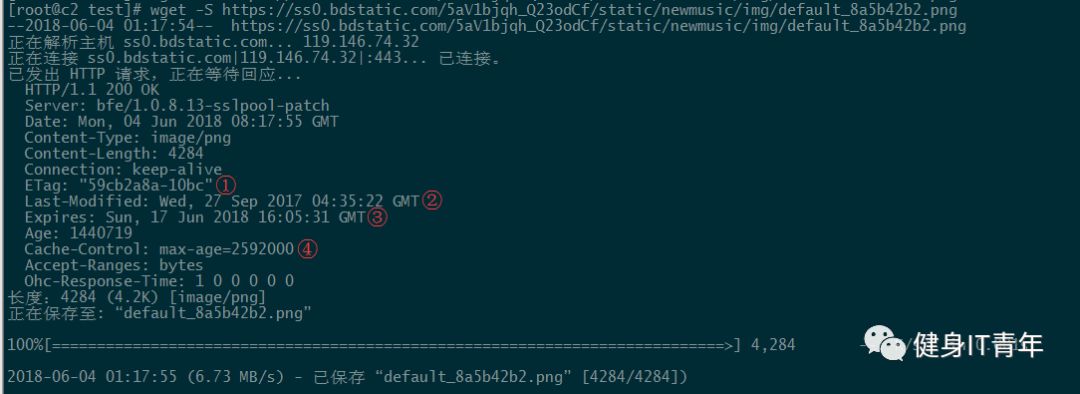
在该实例中,服务器端使用到了4个指令(图示标签)来控制缓存。
相当于该静态资源的身份ID,在nginx中是基于文件时间戳和大小计算出来的。客户端再次访问该资源时,通过
If-None-Match: "59cb2a8a-10bc"确认该资源是否发生变化。表示该文件的最后修改时间。这是为了让客户端再次请求该资源时核对服务端的资源文件是否发生改变。可以用以下命令来验证。
服务器端通知客户端在该时间之前需要获该资源时,不必再发起HTTP请求,直接使用这个缓存文件即可。
服务器端通知客户端,自收到文件起 2592000 秒内,都可以放心使用,不必再重复请求这个URL。这跟③是一个意思,但是由于客户端和服务端可能存在时间不同步,所以使用相对时间比较好,故max-age优先起作用。
最佳实践3:配置和优化Squid
了解下:Squid是对HTTP协议遵从性最好的缓存软件。
配置Squid的建议
使用大内存服务器。
对于热点文件,Squid使用内存进行缓存,(高速内存缓存机制)避免了从磁盘读入缓存内容。
每个磁盘独立使用
对于过大的文件或者非经常访问的文件,Squid使用基于磁盘的缓存,创建磁盘缓存时不需要组成磁盘阵列,通过cache_dir配置直接使用每个独立磁盘进行缓存以提高磁盘iops。
禁用atime更新
这样不会在读取磁盘缓存时更新相应的inode访问时间,在/etc/fstab下配置 /dev/sdb1 /mnt/sdb1 ext3 noatime,nodiratime 0 0
配置Squid多实例
问:为什么要配置多实例?
Squid以单线程运行,不能重复利用多CPU处理器处理的高性能。
问:怎么实现对Squid多实例进行调度?
参考之前的CDN节点图,对Squid多实例进行负载均衡时,使用URL哈希方法。好处是:
相同的URL访问到同一个Squid实例上,增加缓存命中率。
可以实现不同的Squid上缓存不同的文件,避免Squid上缓存文件的重复。
优化Squid
禁用缓存间通信协议
缓存间通信协议的设计初衷是为了架构缓存集群,尽量减少对源站的访问。这会导致缓存响应的延时,也不利于问题的排查。
架构二级缓存
了解下:什么是一级、二级缓存?
一级缓存节点指的是最边缘的缓存节点,直接服务于终端用户的节点。
二级缓存节点在架构上实际被一级缓存节点认为是源站。
一级缓存节点和二级缓存节点之间,并不适用缓存间通信协议,而是直接使用HTTP进行内容获取或者缓存内容验证。
优化HTTP Range
HTTP Range方法提供了允许客户端只获取某个静态文件部分内容的能力。比如下面的Range请求的头部信息截取图:表示客户端希望获取文件从1025字节到2048字节的内容(这在多线程下载器如迅雷、Flashget比较常见,相当于通过多个线程分别获取同一个URL的不同部分然后组合起来,提高下载速度)
在实践中,建议配置range_offset_limit 3MB以平衡Range请求和缓存整个文件之间效率问题,这样配置后,如果用户请求的Range字节在3MB以外,Squid也会使用Range向后端请求,但文件不会被缓存。
建议细节阅读原著《Linux运维最佳实践》
以上是关于HTTP协议的缓存控制和Squid的配置迅雷为什优化(这里有关于迅雷为什么下的快的原因)的主要内容,如果未能解决你的问题,请参考以下文章