HTTP协议与R语言爬虫 | R语千寻
Posted 狗熊会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTP协议与R语言爬虫 | R语千寻相关的知识,希望对你有一定的参考价值。

如果要使用R语言从网络抓取数据,就必须对R语言进行设置,使得R具备与服务器及Web服务进行通信的能力。而互联网中进行网络通信的通用语言就是HTTP(Hypter Text Transfer Protocol),即所谓超文本传输协议。
超文本协议是一种用于分布式、协作式和超媒体信息系统的应用层协议,是一个客户端终端(用户)和服务器终端(网站)请求和应答的标准(TCP)。通过使用网页浏览器、网络爬虫或者其他工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80),即可获取网络资源。即HTTP就是浏览器或者爬虫工具接收网页html的口令。
实际生活中,当我们坐在电脑前,用浏览器访问淘宝进行购物时,其间我们基本上不会与HTTP打交道。创建和发送HTTP请求,以及处理服务器端返回的HTTP响应都是由浏览器一手搞定,试想如果大家每次用淘宝购物都需要手动构建类似“用HTTP协议把www.taobao.com网页下的某个商品链接传递给我”这样的请求,岂不是非常麻烦?R语言在爬取数据时正是模拟浏览器的行为。为了了解这个爬取过程,必须深入学习一下网络中文件传输协议并准确构建请求。
01
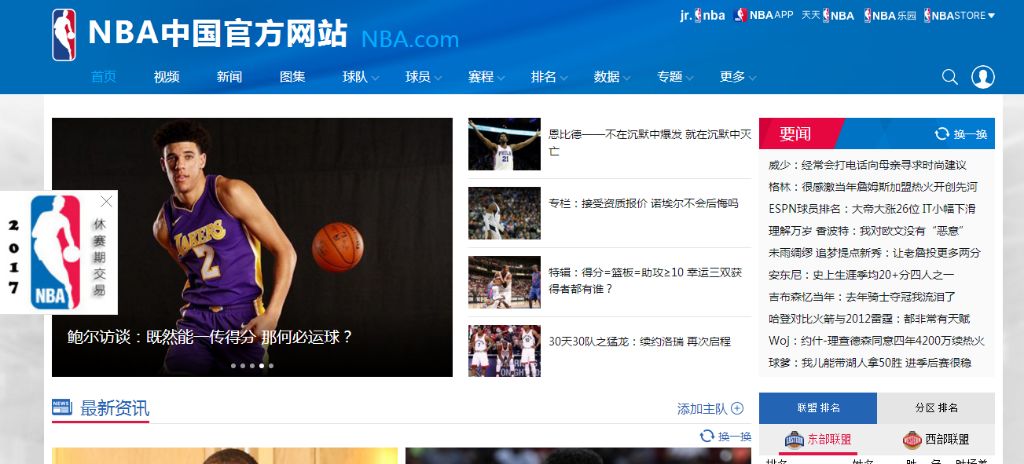
图1 NBA中国官方网站

图2 客户端会话信息
建立连接之后,服务器会等待请求,浏览器会向服务器发送如图3所示的HTTP请求。
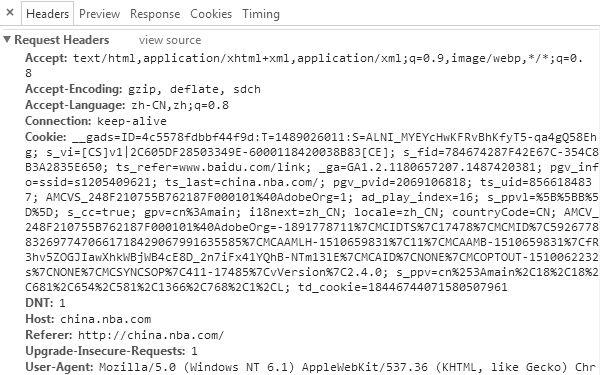
图3 NBA中文网请求信息
然后就是服务器该如何响应浏览器的请求(见图4)。
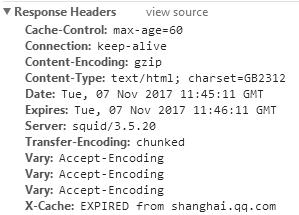
图4 浏览器对于请求的响应
在接受了所有数据之后,连接会被浏览器再次关闭(Closing connection #0),一次访问就算结束了。
2
所谓URL,就是平常所说的网址,全称为统一资源定位符(Uniform Resource Locators)。虽然URL不是HTTP的一部分,但通常能够通过URL直观地进行HTTP和其他协议的通信。总体的URL例子可以表示为:scheme://hostname:port/path?querystring#fragment。对应到NBA中文网的实例为:http://nbachina.qq.com/a/20170914/004815.htm。
Scheme表示URL的模式,它定义了浏览器和服务器之间通信所采用的协议,NBA主页的例子中采用的模式就是HTTP。紧随其后的是主机名hostname和端口号port,主机名提供了存放我们感兴趣资源的服务器的名字,它是一个服务器的唯一识别符。端口号一般默认为80,主机名和端口号组合起来就等于说是告诉浏览器要去敲哪一扇门才能访问请求的资源。主机名和端口号之后的路径用来确定被请求的资源在服务器上的位置,跟文件系统类似,也是用“/”符号来分段的。
另外,在多数情形下,URL的路径里会提供很多补充信息,用来帮助服务器正确地处理一些复杂的请求,比如说通过类似“name=value”这样的查询字符串来获取更多的信息,或者用“#”符号来指向网页中特定的部分也是常见的补充方法。
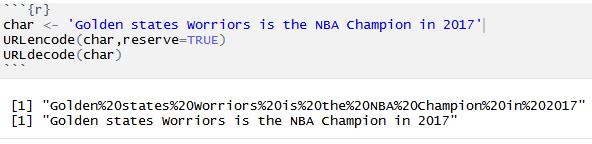
最后需要说明的是,URL是通过ASCⅡ字符集来实现编码的,所有不在128个字符集里面的字符和特殊字符串都需要转义编码为标准的表示法,URL编码也被称为百分号编码,这是因为每个这样的编码都是以“%”开头的。在R语言中,可以通过基础函数URLencode()和URLdecode()函数来对字符串进行编码或者解码。
3
网络爬虫需要掌握的另外一个知识点是HTTP消息。简单而言,HTTP消息就是与服务器通讯的“语言”,了解HTTP消息才能够用正确的“语言”与服务器交流,并获得反馈。一般而言,HTTP消息主要分为请求消息(即对服务器的请求)及响应消息(即服务器做出的反馈)。在数据爬取中,需要掌握的核心是请求消息。下面重点介绍HTTP消息中的请求消息,了解如何对服务器提出“要求”。
一般来说,HTTP消息一般由起始行(start line)、标头(headers)(也叫消息报头)和正文(body)三部分组成。以请求消息为例,起始行(每个HTTP消息的第一行)定义了请求使用的方法,以及所请求资源的路径和浏览器能够处理的HTTP最高版本。起始行之后的标头为浏览器和服务器提供了元信息,以“名字-取值”的形式表示一套标头字段。正文部分包含纯文本或者二进制数据,这由标头信息中的content-type声明决定。然后是MIME(多用途互联网邮件扩展)类型声明,这个声明的作用是告诉浏览器或服务器传输过来的是哪种类型的数据。起始行、标头和正文分开需要用到换行符(CRLF)。
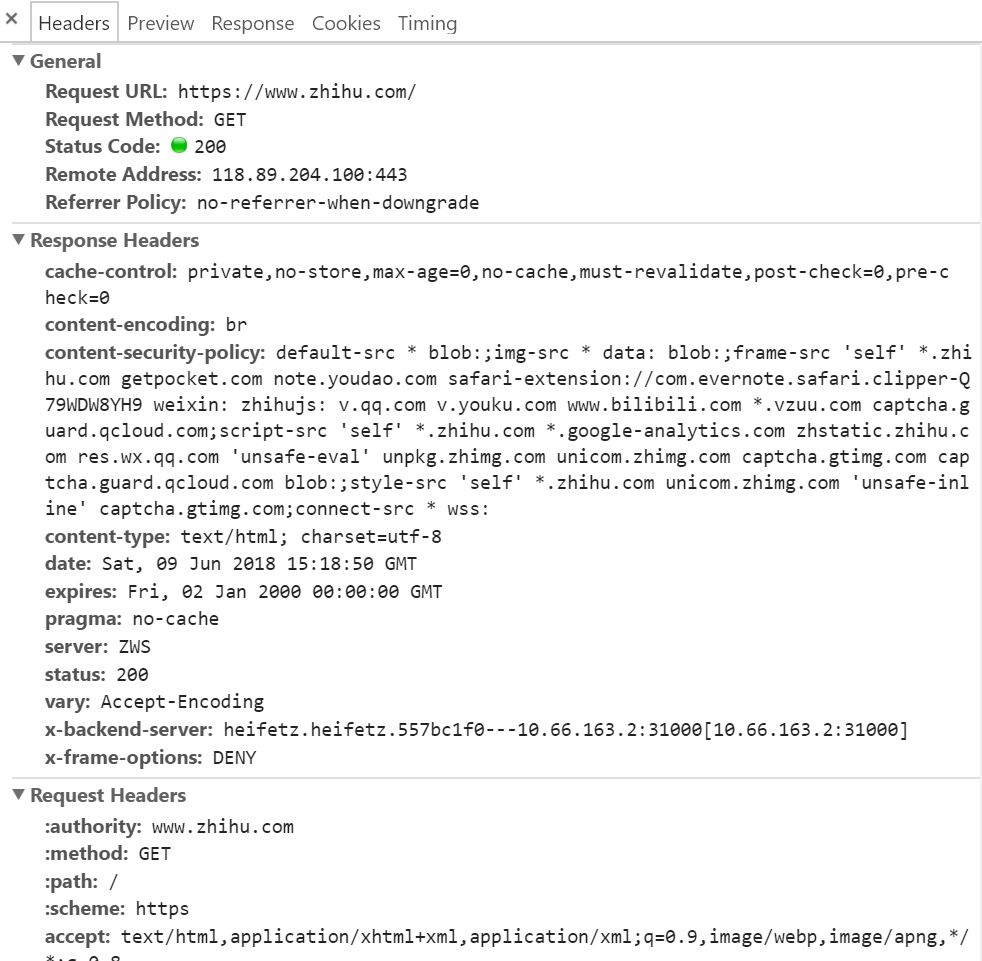
图5 HTTP消息
在请求模式中,最常用的请求方法是GET和POST方法,在爬虫过程中至关重要。这两个方法都是从服务器请求一个资源,但是在正文的使用上有所不同。GET方法是网络请求最通用方法,可理解为直接请求。POST则有所区别,需要提交表单信息才能请求到信息,比如说拉勾网招聘首页需要用户输入地点、薪资范围等信息才能请求到匹配的网页界面。
GET请求如下:
GET/form.html HTTP/1.1(CRLF)
在R中,RCurl包提供了一些高级函数来执行GET请求从Web服务器上获取某个资源,最常用的函数为getForm(),这个函数会自动确定主机、端口以及请求的资源。实际操作中,只需要把URL传给这个函数,也可以手动指定HTML表单参数:
getForm(http://china.nba.com/)
POST请求如下:
POST/greetings.html HTTP/1.1
在R中执行POST请求,无需手动构建,而是可以使用postForm()函数:
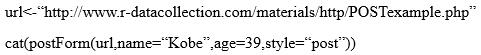
在将预先声明的参数填充到表单中去的时候,需要注意利用style参数预先显式声明一下其可接受的方式。常见的HTTP请求方法如表1所示。
表1 常见的HTTP请求方法

浏览器发送请求后,服务器需要对其进行响应,会在响应的起始行发回一个状态码,可能大家会不太明白状态码是什么,比如经常见到的“404”(见图6),404就是一个表示服务器无法找到资源的响应状态码。

图6 404:NOT FOUND
而正常情形的响应状态码为200(见图7)。
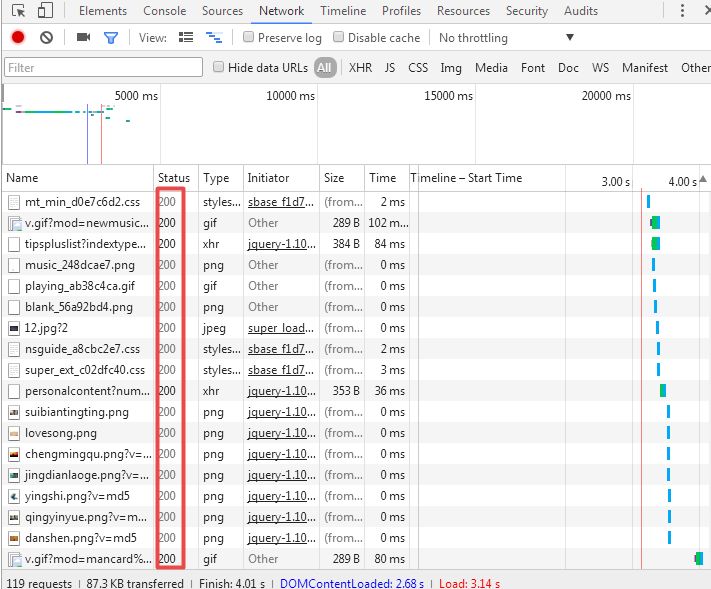
图7 状态码200:请求成功
常见的HTTP状态码如下所示:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见的200表示成功找到资源,404表示未找到资源,500表示服务器内部错误,502表示错误网关等。
有关爬虫基础部分的HTTP知识,本节暂不介绍,更深入的知识有待各位读者进一步探索和学习。

熊小编1分钟前
第一期:
第二期:

识别下方二维码成为狗熊会会员!
友情提示:
个人会员不提供数据、代码,
视频only!
个人会员网址:http://teach.xiong99.com.cn
以上是关于HTTP协议与R语言爬虫 | R语千寻的主要内容,如果未能解决你的问题,请参考以下文章