URL与HTTP协议
Posted Young的编程日记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了URL与HTTP协议相关的知识,希望对你有一定的参考价值。
URL
本来是要学习requests库的,但是看了几分钟,发现有必要学习下URL和HTTP协议等基础知识,爬虫其实本质上就是模拟浏览器进行HTTP请求获取数据。
先看下URL,URL全名是统一资源定位器,至于他和URI、URN的关系、差异这些内容我们先都不用管,只要知道它是用来标示资源、是网址就行了。
先来看个URL,一个一个分析它的组成
http://www.aspxfans.com:80/news/index.asp?boardID=5&ID=24618&page=1#name
http:协议部分,必须要有,网络传输协议有很多种,HTTP/HTTPS/FTP,他这里用的是http
80:端口部分,http默认的端口就是80,可以省略,端口和域名用
:分隔news:目录部分,从第一个
/到最后一个/之间的都是虚拟目录部分,虚拟目录部分也是非必须的index.asp:文件名部分,从最后一个
/到#为止,如果没有#则是到?为止,如果都没有,则是到/到末尾,文件名部分也是非必须的,如果省略的话,则是使用默认的文件名锚部分,从
#到最后参数部分,从
?到#部分,没有#的话则是到最后,参数之间用&分隔
现在我们再来看URL就清晰很多了,再来看几个例子来分析
http://class.dxy.cn/clazz/course/208?sr=1&nm=pyj&pt=2&dt=20180826&pd=class
http:协议部分
clas.dxy.cn:域名
/clazz/course:目录
208:文件名
sr=1&nm=pyj&pt=2&dt=20180826&pd=class:参数
https://www.zhihu.com/people/piaoma/activities
https:协议部分
www.zhihu.com:域名
/people/piaoma/:目录
activities:文件名
HTTP协议
HTTP协议是指浏览器与服务器之间进行数据通信的一种协议,我们平常在浏览器中或者在什么有道云笔记中打开一个超链接,这时候就会客户端就会通过HTTP协议向服务器发起一个请求消息,不管你是打开网页还是上传文件还是修改或删除文件,服务器都会响应处理这个请求并且返回响应消息。
HTTP协议规定只能有客户端发起请求,服务器接受并返回响应结果
HTTP协议是无连接的,也就是每次链接只处理一个请求,服务器处理完请求后就会断开连接,这样可以节省传输时间
HTTP是无状态的,也就是协议本身并不会记录客户端的历史记录
客户端请求消息结构:
请求消息由请求行、请求头部、空行、请求体(请求数据)四部分组成,其中空行是为了区分请求体与请求头部
请求行中是请求的方法(你想获取信息还是删减、修改信息等)、请求资源的路径、协议版本。请求头部中是客户端的一些属性信息。请求体中则是你想提交的数据,比如你想上传一个文件、图片、发送一句话,这种实质信息都在请求体中。
具体格式:
来看个实例,我们打开用chrome浏览器打开百度的首页,然后打开开发者工具,就可以查看客户端的请求消息与服务器的响应消息了。
下图是打开百度首页时,客户端发送的请求消息:
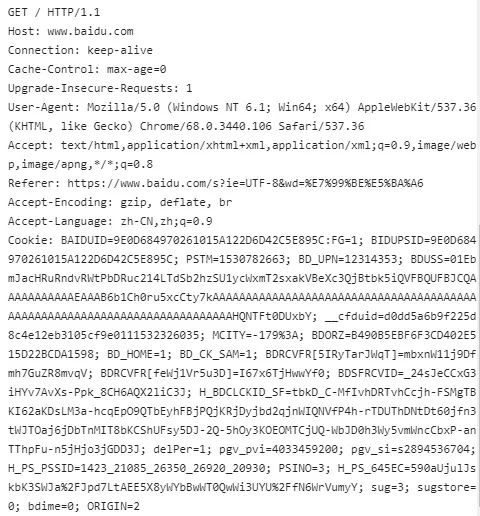
第一行是请求行,我们看到是 GET方法,也就是请求指定页面的信息,返回页面的源代码,然后浏览器进行渲染,最后就成了我们看到的页面了。他这里没有路径,应该是百度首页的路径就是www.baidu.com根目录。
后面的都是请求头部分,我们看到了很多请求属性,比如
Host:请求的服务器网址。
Connection:表示是否需要持久力连接(我们在百度首页搜索框输入时,没有点击enter或搜索键,但它会实时的返回搜索结果,说明他是keep-alive)
Cache-control:制定请求和响应遵循的缓存机制(如一个请求希望响应返回的内容在客户端要被缓存一年,或不希望被缓存就可以通过这个报文头达到目的。 )
User-Agent:用户代理,使得服务器能识别客户端的操作系统及版本、CPU类型、浏览器类型及版本、渲染引......
Accept:浏览器能接受的内容类型
Accept-language:浏览器支持的语言类型
Accept-Encoding:浏览器有能力解码的编码类型
Cookie:用于会话跟踪(这个我也不知道具体指什么) ......
由于我们是打开百度首页,所以是GET方法,GET方法是没有请求体的,所以我们再这里找不到请求体。
请求方法
我们之前说了,请求行中第一个就是请求方法,不同的方法对应不同的需求,服务器返回的响应消息也不同
HTTP一共有8种方法,最常用的就是 GET和 POST方法,90%的爬虫都是基于 GET方法来获取数据,下面看下常见方法的具体功能:
GET:获取指定页面信息,我们一般浏览网页都是
GET方法,GET只是获取数据,也不影响资源的状态,原则上对一个资源多次使用GET方法返回的结果是一样的。POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。比如我们上传文件、登录页面输入表单、论坛回帖应该都是
POST方法,POST方法是会修改服务器上的资源的。HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头,(应该是只返回响应信息的报头)
PUT:从客户端向服务器传送的数据取代指定的文档的内容。
DELETE:请求服务器删除指定的页面
响应信息结构
服务器响应的信息结构和请求信息基本一样,由状态行、消息报头、空行、响应正文组成。
我们来看下打开百度首页的响应信息:
第一行是状态行,返回HTTP协议版本,状态码200以及对状态码的原因描述。
状态码有很多种,200代表请求成功,404代表(资源)网页不存在,其他的还有几种,用的少,pass!
后面的是响应信息的报头(response head),和请求头部类似,用于对响应内容的补充,在首部里面可以告知客户端响应体的数据类型是什么?响应内容返回的时间是什么时候,响应体是否压缩了,响应体最后一次修改的时间。
后面就是响应正文了,本来是有很多的,就是百度首页的前端代码全部作为响应信息返回给客户端,这里我截图省略了,只剩一个html标志了,服务器返回的实质信息都在响应正文中。
以上是关于URL与HTTP协议的主要内容,如果未能解决你的问题,请参考以下文章