前端 | 老司机带你了解 HTTP 协议
Posted 唐山程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端 | 老司机带你了解 HTTP 协议相关的知识,希望对你有一定的参考价值。
身为开发人员除了应该对我们所写的项目需求要了解,以及基本的语言知识,对于HTTP协议也是应该了解一下的,因为这些东西与我们是密不可分的,每天都在和HTTP打交道然而却不知道它到底是什么?这样说出去是不是很可悲?简直可歌可泣有没有...
HTTP是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII码形式给出;而消息内容则具有一个类似MIME的格式。这个简单模型是早期Web成功的有功之臣,因为它使得开发和部署是那么的直截了当。超文本传输协议(HTTP)是用于传输诸如html的超媒体文档的应用层协议。它被设计用于Web浏览器和Web服务器之间的通信,但它也可以用于其他目的。HTTP遵循经典的客户端-服务端模型,客户端打开一个连接以发出请求,然后等待它收到服务器端响应。 —— 百度百科
HTTP是无状态协议,意味着服务器不会在两个请求之间保留任何数据(状态)。在同一个连接中,两个执行成功的请求之间是没有关系的。这就带来了一个问题,用户没有办法在同一个网站中进行连续的交互,比如在一个电商网站里,用户把某个商品加入到购物车,切换一个页面后再次添加了商品,这两次添加商品的请求之间没有关联,浏览器无法知道用户最终选择了哪些商品。而使用HTTP的头部扩展,HTTP Cookies就可以解决这个问题。把Cookies添加到头部中,创建一个会话让每次请求都能共享相同的上下文信息,达成相同的状态。通过上述得出结论,http特点是:无状态,无连接,简单快速。
一个连接是由传输层来控制的,这从根本上不属于HTTP的范围。HTTP并不需要其底层的传输层协议是面向连接的,只需要它是可靠的,或不丢失消息的(至少返回错误)。在互联网中,有两个最常用的传输层协议:TCP是可靠的,而UDP不是。因此,HTTP依赖于面向连接的TCP进行消息传递,但连接并不是必须的。
UDP:是无连接的,即发送数据之前不需要建立连接
关于TCP和UDP这里不做多余赘述,如果想要深入了解两者之间的优缺点以及区别的话,有时间再详细的介绍一下。
其实HTTP交互流程就是基于TCP连接进行消息传递的,然而这个连接可有可无,具体交互流程如下图:
结合上图详细说明经历的过程:
打开一个TCP连接:TCP连接被用来发送一条或多条请求,以及接受响应消息。客户端可能打开一条新的连接,或重用一个已经存在的连接,或者也可能开几个新的TCP连接连向服务端
发送一个HTTP报文:HTTP报文(在HTTP/2之前)是语义可读的。在HTTP/2中,这些简单的消息被封装在了帧中,这使得报文不能被直接读取,但是原理仍是相同的
读取服务端返回的报文信息,服务器端接收到请求后,进行处理,然后将处理结果响应客户端(HTTP协议)
关闭连接或者为后续请求重用连接,关闭客户端和服务器端的连接(HTTP1.1后不会立即关闭)
当HTTP流水线启动时,后续请求都可以不用等待第一个请求的成功响应就被发送。然而HTTP流水线已被证明很难在现有的网络中实现,因为现有网络中有很多老旧的软件与现代版本的软件共存。因此,HTTP流水线已被在有多请求下表现得更稳健的HTTP/2的帧所取代。
在Linux系统下有一个curl指令可以通过这个命令来观测一下HTTP的请求过程。
curl -v https://segmentfault.com/输入完之后回车就会看到下面这些信息:
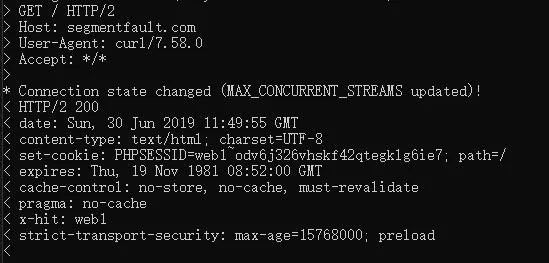
图中>开始的是客服端发送给服务端的信息,以<开始的为服务端返回给客户端的一些信息。当客户端发起一个Ajax请求时,浏览器会携带一些信息发送给服务端,HTTP请求头提供了关于请求,响应或者其他的发送实体的信息。请求报文分为以下几个部分:
General(请求行)
Response Headers(请求头)
Request Headers(响应头)
这三个部分分别承载了服务端以及客户端所需要的信息,在浏览器中中NetWork中可以查看到其信息内容,接下来就一一介绍一下:

# General
这部分主要提供的是一些公用的请求头信息:
Request URL: https://segmentfault.com/search?q=searchRequest Method: GETStatus Code: 200Remote Address: 112.126.83.219:443Referrer Policy: no-referrer-when-downgrade
Request Method:请求方式
Status Code:状态码
Referrer Policy: 过滤 Referrer 报头内容
像前面几个应该都比较熟悉也通俗易懂,当看到的这的时候心里有一些些的小疑惑Remote Address是什么?Referrer Policy过滤报头的规则有哪些?
Remote Address
Referrer Policy
Referrer-Policy的作用就是为了控制请求头中referrer的内容,目前是一个候选标准,不过已经有部分浏览器支持该标准。目前Referrer-Policy只包含以下几种值:
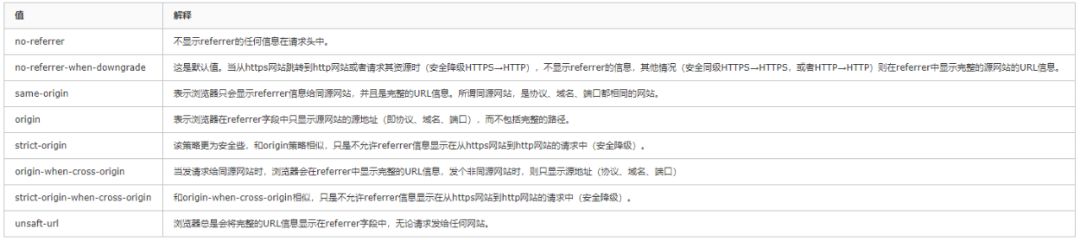
(图片可点击放大)
Referrer-Policy值不是固定不变的,而是可是通过程序手动设置,一般都会不会去手动更改除非网页中不存在一些敏感信息,那就默认使用no-referrer-when-downgrade。这里就多说了,如果有兴趣的可以调研一下。
# Response Headers
这部分存储的是响应头信息,当服务端接受到请求,并处理完成之后需要向客户端做出应答。
cache-control: no-store, no-cache, must-revalidatecontent-encoding: gzipcontent-type: text/html; charset=UTF-8date: Fri, 28 Jun 2019 09:32:09 GMTexpires: Thu, 19 Nov 1981 08:52:00 GMTpragma: no-cachestatus: 200strict-transport-security: max-age=15768000; preloadx-hit: web1
cache-control:响应输出到客户端后,服务端通过该报文头告诉客户端如何控制响应内容的缓存
content-encoding:文档编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型
content-type:文档类型
date:当前的GMT时间,可以用setDateHeader来设置
expires:文档过期时间,文档到期后则不再缓存
pragma:设置消息头,(no-cache)强制清除缓存
status:服务器响应状态码
strict-transport-security:安全功能,它告诉浏览器只能通过HTTPS访问当前资源,而不是HTTP
# Request Headers
这部分承载的是请求头的信息,当客户端向服务端发送请求时,需要传递给服务端的信息内容。
:authority: segmentfault.com:method: GET:path: /search?q=1:scheme: httpsaccept: text/html,application/xhtml+xml,application/xml;accept-encoding: gzip, deflate, braccept-language: zh-CN,zh;q=0.9cookie: e23800c454aa573c0ccb16b52665ac26=1561712973referer: https://segmentfault.com/user-agent: Chrome/75.0.3770.100 Safari/537.
:authority:请求权限(HTTP2.0)
:method:请求方式(HTTP2.0)
:scheme:请求协议(HTTP2.0)
accept:指定客户端可以接受的内容类型,比如文本,图片,应用等等,内容的先后排序表示客户端接收的先后次序,每种类型之间用逗号隔开。
accept-encoding:客户端接收编码类型,一些网络压缩格式:Accept-Encoding: gzip, deflate, sdch。相对来说,deflate是一种过时的压缩格式,现在常用的是gzip
accept-language:客户端可以接受的语⾔言类型,参数值规范和 accept的很像。一般就接收中文和英文,有其他语言需求自行添加。
cookie:同样是一个比较关键的字段,Cookie是 client 请求服务器时,服务器会返回一个键值对样的数据给浏览器,下一次浏览器再访问这个域名下的网页时,就需要携带这些键值对数据在 Cookie中,用来跟踪浏览器用户的访问前后路径。
referer:浏览器上次访问的网页url,uri。由于http协议的无记忆性,服务器可从这里了解到客户端访问的前后路径,并做一些判断,如果一次访问的 url 不能从前一次访问的页面上跳转获得, 在一定程度上说明了请求头有可能伪造。
user-agent:中文名用户代理,服务器从此处知道客户端的操作系统类型和版本,电脑CPU类型,浏览器 种类版本,浏览器渲染引擎,等等。
ccept-language共分为下列几种:
zh-CN:中文简体大陆zh:其他中文en-US:英语美语en:其他英语
Cookie就是存储在客户端的一小段文本,因为cookie是存储在客户端浏览器中的,Cookie不能作为代码执行,也不会传送病毒,且为你所专有,并只能由提供它的服务器来读取。保存的信息片断以名/值对(name-value)的形式储存,一个名/值对仅仅是一条命名的数据。一个网站只能取得它放在你的电脑中的信息,它无法从其它的cookie文件中取得信息,也无法得到你的电脑上的其它任何东西。
const express = require('express');const cookieParser = require('cookie-parser');var app = express();app.use(cookieParser('sign'));app.get('/set', function(req, res) {res.cookie('name', 'TracyYu', {maxAge: 9999999, httpOnly: true, signed: true});res.send('cookie设置成功');})app.get('/get', function(req, res) {console.log(req.signedCookies);res.send('success')})app.listen('3000', function() {console.log('3000成功');})
通过上面代码中对cookie进行设置之后,用户访问/set路由的是时候已经把cookie设置到了浏览器的头部,当用户访问/get路由的时候,由于在浏览器中已经设置好cookie,在同属于一个服务的情况下是可以直接获取到cookie的。当然除了上述所说,通过document也是可以手动设置cookie的,在客户端设置的cookie在服务端同样是也可以获取到的。
document.cookie="userId=929";这样就将名为userId的cookie值设置为了929,现在访问/get同样就能拿到在客户端设置的cookie值了。
http中经常用的到的就是get和post两种,在开发过程中会遵循RESTful接口风格,这是一种现在比较流行的接口风格,使用这种接口风格需要用到一些其他的请求方式,http请求方式一共有8种。

(图片可点击放大)
HTTP定义了与服务器交互的不同方法,最基本的方法是GET和POST(开发关心的只有GET请求和POST请求)。
GET和 POST长度的限制问题

(图片可点击放大)
其实这里有一个很大的误区,http协议并未规定GET和POST的长度限制,GET的最大长度限制是因为浏览器和web服务器限制了URL的长度,不同的浏览器和web服务器,限制的最大长度不一样,要支持IE,则最大长度为2083byte,若支持Chrome,则最大长度8182byte,首先即使GET有长度限制,也是限制的整个URL的长度,而不仅仅是参数值数据长度。
GET和 POST的安全性
1.GET是通过URL方式请求,可以直接看到,明文传输
2.POST是通过请求header请求,可以开发者工具或者抓包可以看到,同样也是明文的
3.GET请求会保存在浏览器历史记录中,还可能会保存在Web的日志中
GET请求指定资源的表示形式。注意,GET不应该用于产生副作用的操作,比如在web应用程序中使用它执行操作。原因之一是GET可能被机器人或爬行器任意使用,它们不需要考虑请求应该引起的副作用。POST将要处理的数据(例如,从HTML表单)提交给标识的资源。数据包含在请求体中。这可能会导致创建新资源或更新现有资源,或者两者兼而有之。使用HTTP协议的服务不应该使用基于GET的表单来提交敏感数据,因为这会导致这些数据在Request-URI中编码。许多现有服务器,代理和用户代理会将请求URI记录在第三方可能看到的某个位置。服务器可以使用基于POST的表单提交。
GET与 POST请求过程
POST请求的过程:
1.浏览器请求tcp连接(第一次握手)
2.服务器答应进行tcp连接(第二次握手)
3.浏览器确认,并发送post请求头(第三次握手,这个报文比较小,所以http会在此时进行第一次数据发送)
4.服务器返回100 Continue响应
5.浏览器发送数据
6.服务器返回200 OK响应
GET请求的过程:
1.浏览器请求tcp连接(第一次握手)
2.服务器答应进行tcp连接(第二次握手)
3.浏览器确认,并发送get请求头和数据(第三次握手,这个报文比较小,所以http会在此时进行第一次数据发送)
4.服务器返回200OK响应



以上是关于前端 | 老司机带你了解 HTTP 协议的主要内容,如果未能解决你的问题,请参考以下文章