爬虫学习之HTTP协议初步了解
Posted 分享电脑学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习之HTTP协议初步了解相关的知识,希望对你有一定的参考价值。
HTTP协议简介
尽量使用谷歌/火狐/360极速浏览器
在Web应用中,服务器把网页传给浏览器,实际上就是把html代码发给浏览器,让浏览器显示出来,而浏览器和服务器之间的传输协议就是HTTP
HTML是一种定义网页的文本
HTTP是在网络上传输HTML的协议,用于通信
在Chrome中下面的位置中或者ctrl+shift+i快捷键:
打开后的界面
我们打开网络调试助手
进入界面
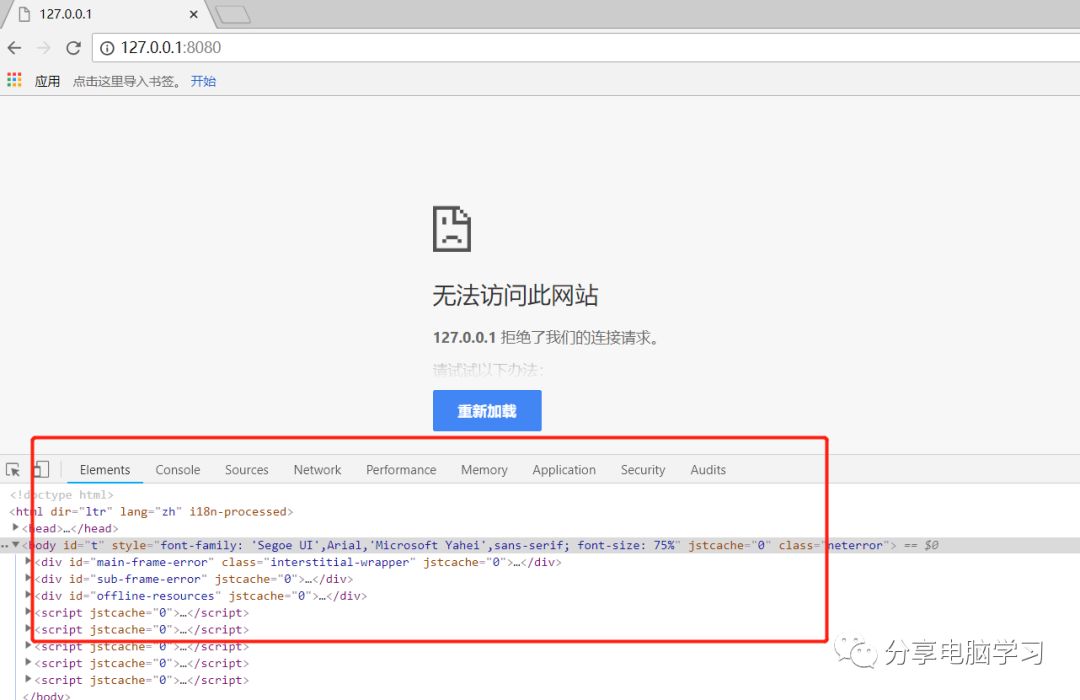
接下来我们用Chrome访问我们本地服务
先启动服务,此时我们就模拟了服务器
然后在浏览器中访问服务器,输入以下内容,点击回车
浏览器会进入请求状态
我们在模拟服务器中也会提取到信息
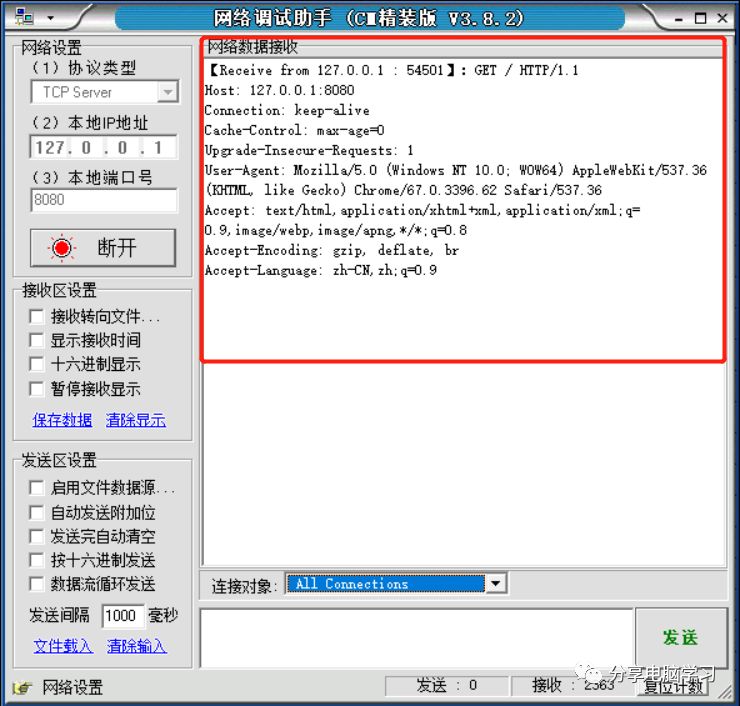
这些内容就是HTTP协议中的一部分内容
GET / HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
其中GET后面是/了,但是如果我们在浏览器访问中加访问内容的话它就会变化了,比如下面就不会是/了,这个GET就向服务器“要东西”。这就是协议中的意义,是有规定目的的。
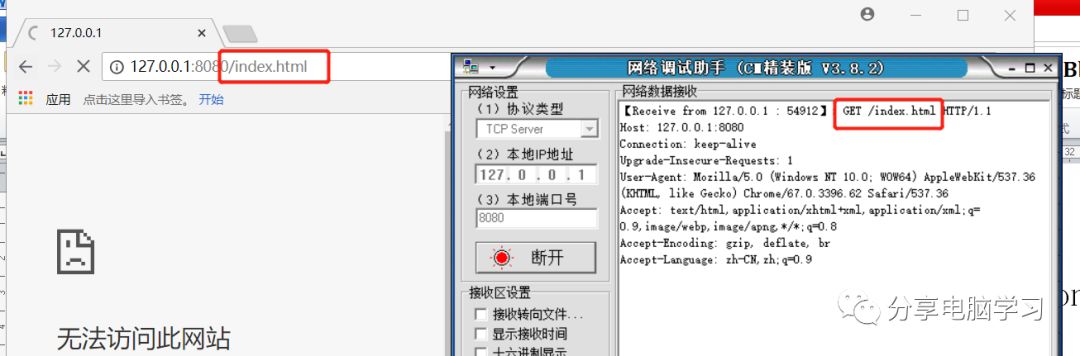
Connection: keep-alive 表示长连接,先记下。
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 表示能接收的格式。
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36 表示浏览器的访问版本。这个可以练习下,用市面上常见的浏览器访问下,看下浏览器访问版本。
那么我们现在知道浏览器向服务器访问的格式,那么服务器返回给浏览器我们该怎么看呢?
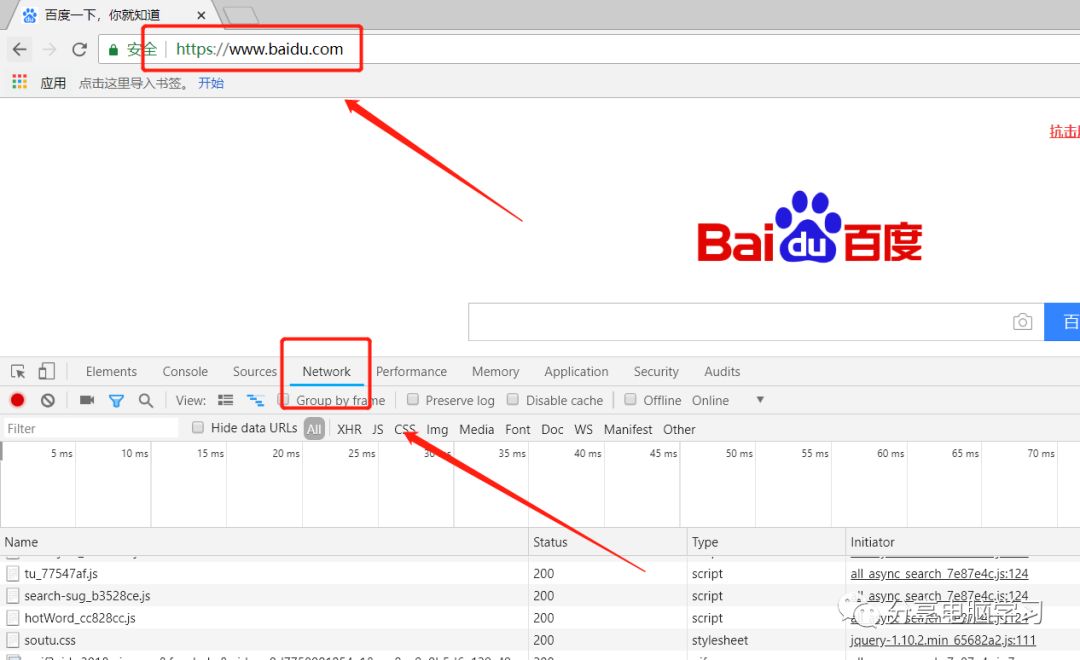
比如我们访问www.baidu.com,看看返回什么?
进入浏览器,先改下位置,这样比较舒服
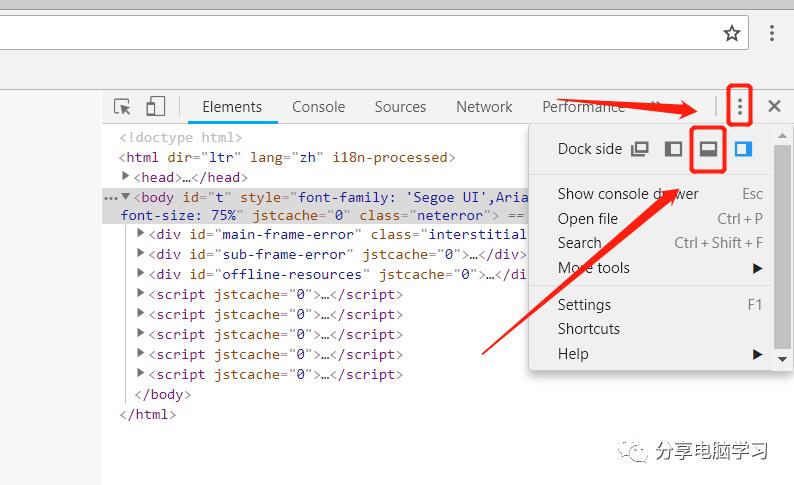
调试工具就到下面了
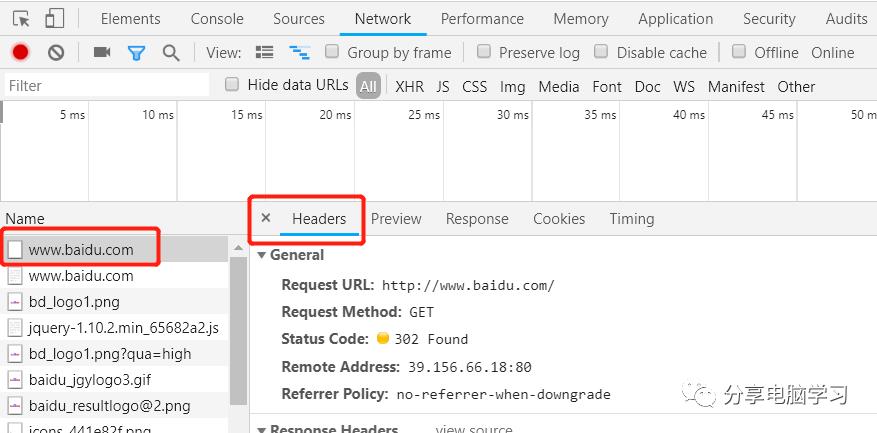
访问百度,我们看下面的地方
这里就是给浏览器的内容
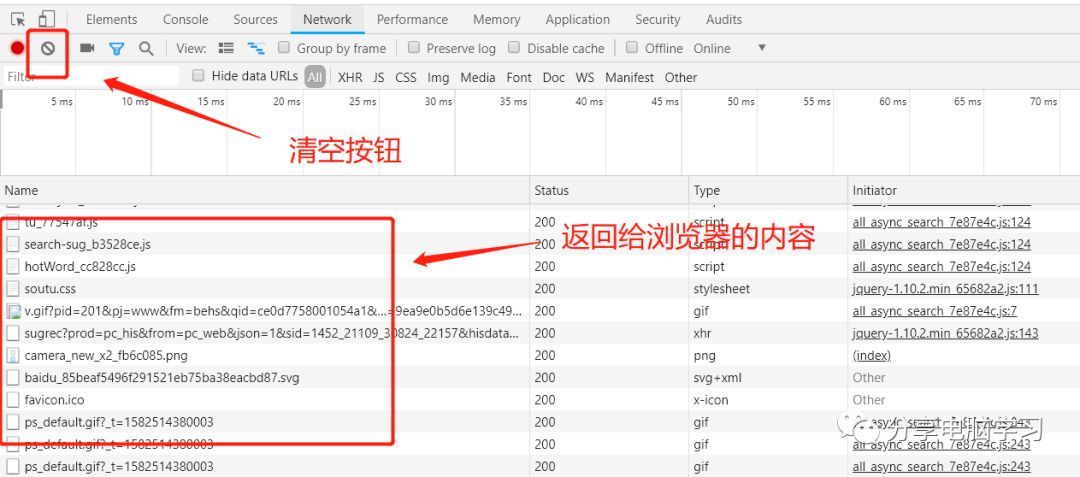
可以点击查看内容
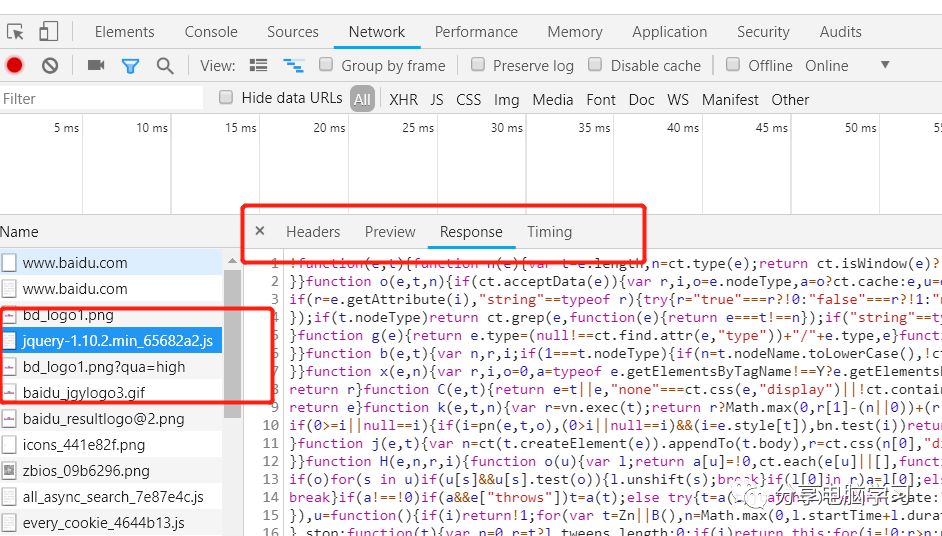
下面这个就是我们请求的内容
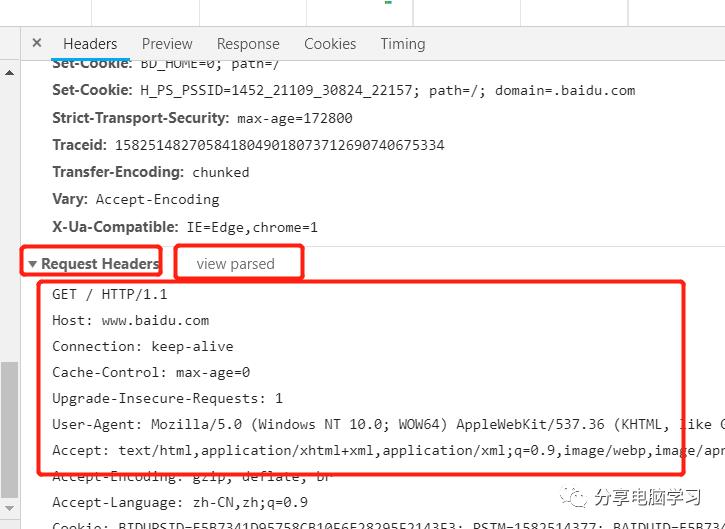
这个就是响应的概要内容,就可以针对性的查询协议内容
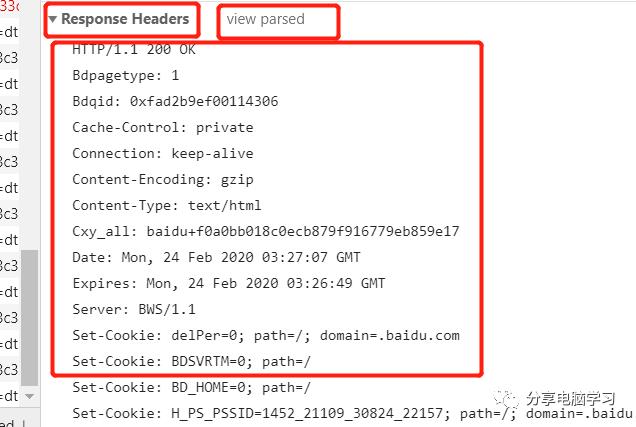
而主要内容是在这里:
我们利用调试助手模拟服务器向浏览器发送信息,就可以查看到信息
以上是关于爬虫学习之HTTP协议初步了解的主要内容,如果未能解决你的问题,请参考以下文章