新浪微博王辉:OpenResty 构建一站式应用网关实践
Posted 又拍云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新浪微博王辉:OpenResty 构建一站式应用网关实践相关的知识,希望对你有一定的参考价值。
2019 年 3 月 23 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·北京站,新浪微博产品部移动高级开发工程师王辉在活动上做了《 OpenResty 构建一站式应用网关实践》的分享。
OpenResty x Open Talk 全国巡回沙龙是由 OpenResty 社区、又拍云发起,邀请业内资深的 OpenResty 技术专家,分享 OpenResty 实战经验,增进 OpenResty 使用者的交流与学习,推动 OpenResty 开源项目的发展。2019 年已在深圳、北京两地举办,未来将陆续在武汉、上海、广州、杭州、成都等地举办。
 王辉, 新浪微博产品部移动高级开发工程师,专注新浪微博后端业务,微博移动应用后端网关负责人,曾负责过视频直播、消息下推等系统。
王辉, 新浪微博产品部移动高级开发工程师,专注新浪微博后端业务,微博移动应用后端网关负责人,曾负责过视频直播、消息下推等系统。
以下是分享全文:
大家下午好,我是新浪微博后端开发工程师王辉,见证了新浪网关服务从无到有的过程。我今天分享的主题是《OpenResty 构建一站式应用网关的实践分享》,目前接入服务的有微博极速版和微博国际版。
今天的分享内容有以下三个部分:
网关概论,网关涉及的主要技术和业务流程。
开发过程中遇到的问题和解决方案。
对项目现状的总结以及对 OpenResty 的反思。
网关概述
新浪微博构建了一个包含了上行请求和下行推送的一站式应用服务器。基于长链接,1 台设备对应 1TCP 连接,上面跑私有协议,同时提供上行请求和下行推送。目前上行请求是重心,具体业务内容包括“代理 + 聚合”,处理客户端常规业务请求;同时提供的下行推送,对外提供接口,主动推送数据。目前我们的服务支持 TCP、TLS、HTTP、HTTPS、QUIC 五个协议通道传输数据。
我们的初衷想做网络链路层的优化,为了确认效果,我们寻找了接入方。一开始只是为国际版以及主版本部分功能做网络链路接入,后来给微博极速版做后端业务支持。制约现状的因素有很多,产品和业务多样化,服务性能要好,基于以往经验,该系统还要能够快速维护。我们团队三个人,中期还离职了一位,当时的处境非常艰难,总之就是人员少任务重。
为什么是 OpenResty?
之前我们团队一直使用 Erlang,对其性能非常满意,但是一直面临着“招人难,学习成本高”的问题,因此最终放弃了它。我们没有用 Java 和 Go 的原因,一是团队当中没有几个人会,二是业务复杂性需要我们有快速开发的能力,所以开发效率很棒的 Lua 就成为了首选。
OpenResty 是一个基于 nginx 与 Lua 的 Web 平台,其内部集成了 Nginx 的核心、大量精良的 Lua 库、第三方模块以及它们的大多数依赖项。Nginx 是一个高性能的 HTTP 和反向代理的服务器,看家本领就是速度快,而 Lua 是一个小巧的嵌入式的语言,其拿手好戏亦是速度,这两者的结合在速度上无疑是有基因优势的。OpenResty 充分利用了 Nginx 的事件模型来进行 I/O 多路复用通信,不仅仅是和 HTTP 客户端间的网络通信是非阻塞的,与 mysql、Memcached 以及 Redis 等众多后端之间的通信也是非阻塞的,自带 work 级别的缓存 lru cache 和多 work 共享的缓存 share dict,而且还有很多优秀的第三方库。
在工程中用 OpenResty,可以让你不花费巨大的精力,就轻松完成一个高性能的 Web 服务,只需要专心写好业务逻辑就可以了。Lua 与其他语言对比其库函数是较少的,大大降低了学习成本,同时也能够应对复杂业务快速开发的特性,新手经过 1-2 个月的学习,开发出来的 API 就可以达到接近于 Nginx C 模块的性能,而且代码量大大减少,方便调试。已知的在使用 OpenResty 的有我们公司的新浪新闻、微博广告、天气通等各个业务部门,以及如 360、京东、百度、魅族知乎、优酷等公司也在使用。
因为我们业务上行请求较为频繁,OpenResty 针对这种代理聚合特性表现抢眼,同时支持 TCP 和 HTTP,相比而言还是 OpenResty 最为适合。一般 OP 对 Nginx 比较熟悉,基于 Nginx 的 OpenResty 与其运作方式相似,自然不会为后续的运维增加多少难度。
业务架构及流程
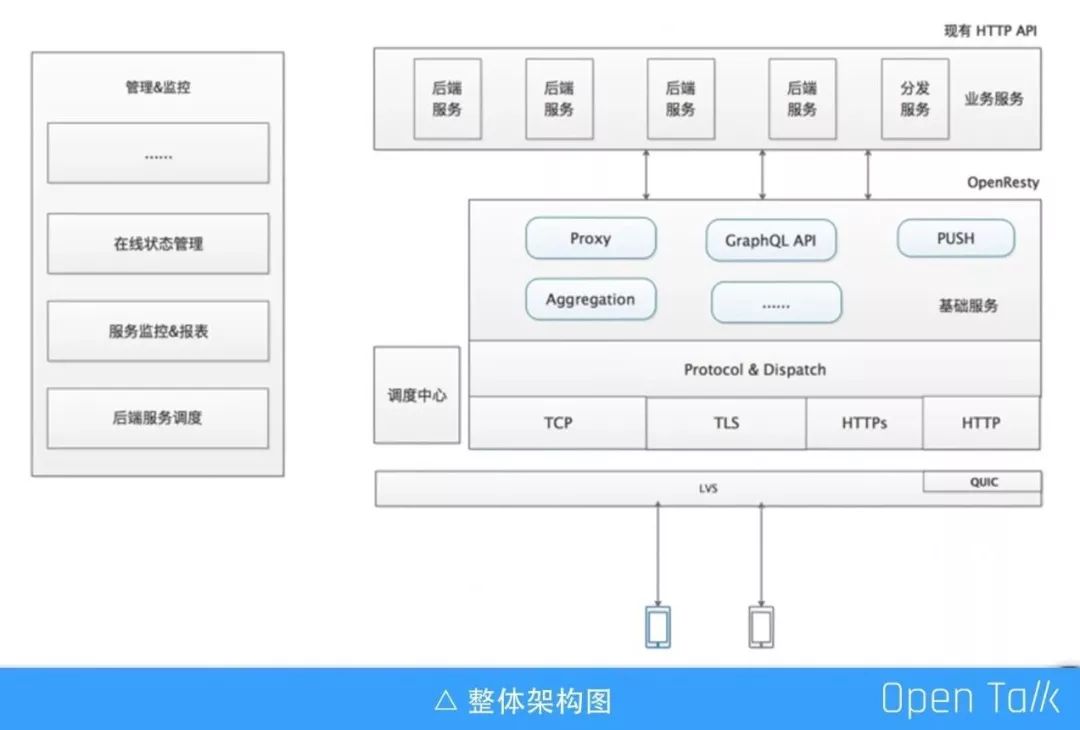
上图是整体架构图,系统对外一共提供了 TCP、TLS、HTTP、HTTPS、QUIC 五大连接通道,所有通道传输的统一的自定义协议数据,这些通道都位于 LVS 后面;架构主要分为数据接入层、协议层、业务处理层,另外还有调度中心 kylin_dispatch、在线状态管理、服务监控 & 报表等功能进行辅助,这些都是基于 OpenResty 实现的。
我们针对 QUIC 通道优化了建连握手流程。相比 SSL 5 次握手的漫长建连,QUIC 一般情况下只需要 1 RTT,一旦连接成功,在若干小时内再次连接就会变成 0 RTT。
客户端 SDK,完成私有协议编解码、协议通道选择以及数据传输。
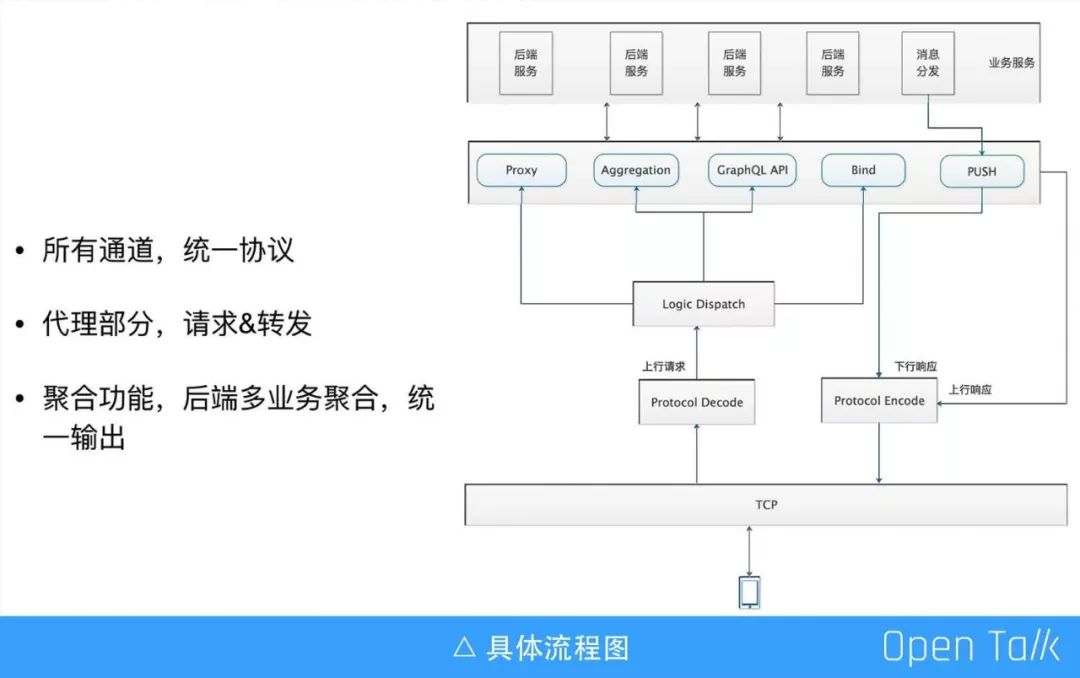
下面从一个具体的请求,介绍我们的业务流程。极速版用户想要刷新热门流,请求数据在客户端 SDK 处被编码成私有协议,服务器端接收后,首先进行解码,然后根据协议类型进行分发到具体 Lua 模块。这些模块有些去请求平台的接口,有的要去访问 MAPI 的接口等。上行请求处理完毕之后,将经过协议编码,然后发送给客户端,这就是上行请求的完整过程。
基于此处理流程,我们可以对外提供若干具体业务:比如透传形式的代理功能,针对实际业务多个接口进行聚合的功能,以及 GraphQL API 模块。线上的 GraphQL API 接口相比传统的 HTTP API 请求,针对客户端一般可降低 50% 的流量。
下面介绍一下推送数据的流程,我们对外提供 push 数据接口,业务方调用接口,将 push 的数据和接收的设备信息塞给我们,我们先判断接收方是否在线,如果接收方不在线就直接写到离线队列中,如果接收方在线就直接发送,把数据丢给它后等待 ack ,一段时间后没接到 ack 会尝试重发,尝试若干次以后还是不能成功接到 ack ,也会把数据写到离线队列中。
客户端 TCP 建立连接后,做的第一件事就是 Bind,Bind 会做以下的事情:第一,会记录用户的一些数据,可以根据数据是否存在来判断接收方在线状态;第二,检查离线队列中是否有数据,有数据发送给端上;第三,在线状态发送 push 的时候,记录的数据可以让我们能找到它。
问题 & 解决方案
接下来主要分享开发过程中遇到的问题和解决方式。
1、TCP 不支持 Lua Semaphore API
OpenResty 只提供了 HTTP 版本的 semaphore 信号量 API,TCP 通道是不支持的,默认情况下是使用长连接推送,只能够借助于较为低效的定时休眠手段了。
我们通过阅读代码,封装了一个 TCP 版本的信号量 API,打开即可看到完整的 Lua 代码。
链接:https://github.com/openresty/lua-resty-core/issues/94
2、CJSON-大数
开发过程中,我们使用 CJSON 进行 json 的编解码,一般情况下,CJSON 完全够用了。在使用的过程中还是碰到了以下几个问题:一是大数的问题,微博的 API 中一些字段的类型为 64 位的正整数,当前所依赖的 LUA 5.1.* 系列版本只支持 48 位的正整数,大整数会被自动修理成科学计数法,在实际中会造成数字失真的问题,我们将大整数自动转换为字符串类型,也算是折中的一种方案。
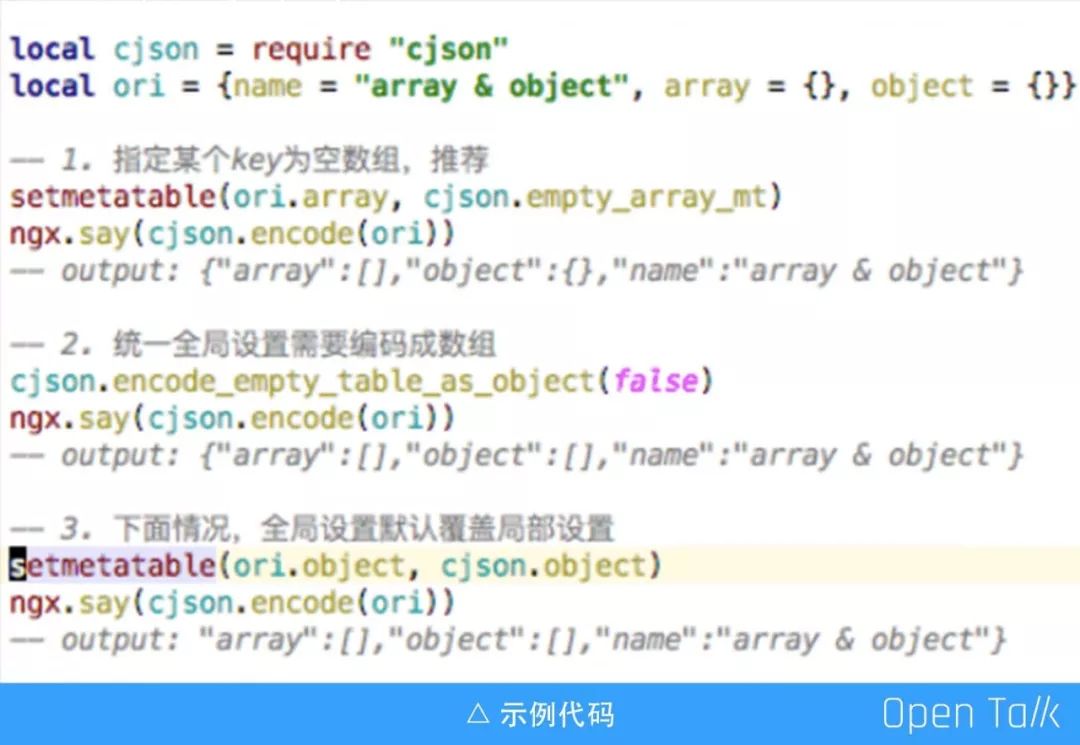 在 Lua 中,数组和对象都是使用 table 这种数据结构进行表示,当空 table 需要转换成 JSON 时,有时需要呈现空数组,有时需要呈现空对象,有时两者都需要呈现。如上图的代码,首先我们定义了一个 cjson 对象和一个 table,它包含三个字段,name 一个字符串,array 和 object 都是空的 table。第一段代码指定某个 key 值为空数组;第二段代码,统一全局设置编码成数据,输出和我们预料的一样全变成了数组,这是 OpenResty 中空数组与空对象转换的俩种方法;第三段代码,这时我想把 object 转化成空对象,看输出 object 并没有变化,我们查阅资料发现全局设置会覆盖局部设置,因此我们推荐用第一种方法,力度更细,更灵活方便不会被覆盖。
在 Lua 中,数组和对象都是使用 table 这种数据结构进行表示,当空 table 需要转换成 JSON 时,有时需要呈现空数组,有时需要呈现空对象,有时两者都需要呈现。如上图的代码,首先我们定义了一个 cjson 对象和一个 table,它包含三个字段,name 一个字符串,array 和 object 都是空的 table。第一段代码指定某个 key 值为空数组;第二段代码,统一全局设置编码成数据,输出和我们预料的一样全变成了数组,这是 OpenResty 中空数组与空对象转换的俩种方法;第三段代码,这时我想把 object 转化成空对象,看输出 object 并没有变化,我们查阅资料发现全局设置会覆盖局部设置,因此我们推荐用第一种方法,力度更细,更灵活方便不会被覆盖。
这两个问题在实际的开发过程中就能碰到,下面我们看看其性能方面的问题。
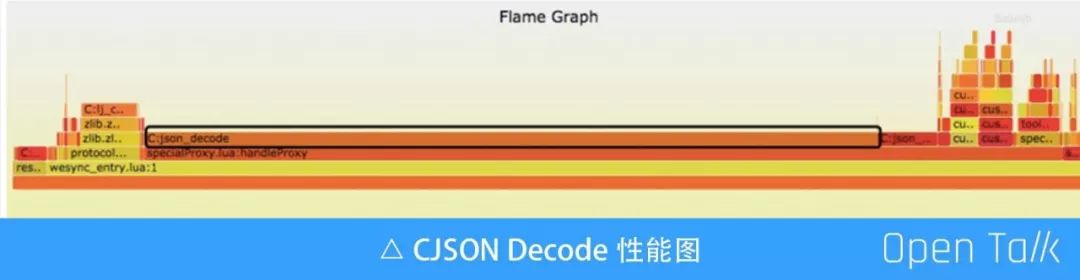 这是在压力测试时生成的火焰图,cjson 的 decode 已经呈现出 CPU 占用过高的问题。目前线上流量的还不构成这样的压力,但我们准备着手使用 cloudflare 公司开源的 lua-resty-json 进行替换,现在还没有具体信息分享。
这是在压力测试时生成的火焰图,cjson 的 decode 已经呈现出 CPU 占用过高的问题。目前线上流量的还不构成这样的压力,但我们准备着手使用 cloudflare 公司开源的 lua-resty-json 进行替换,现在还没有具体信息分享。
3、日志传输
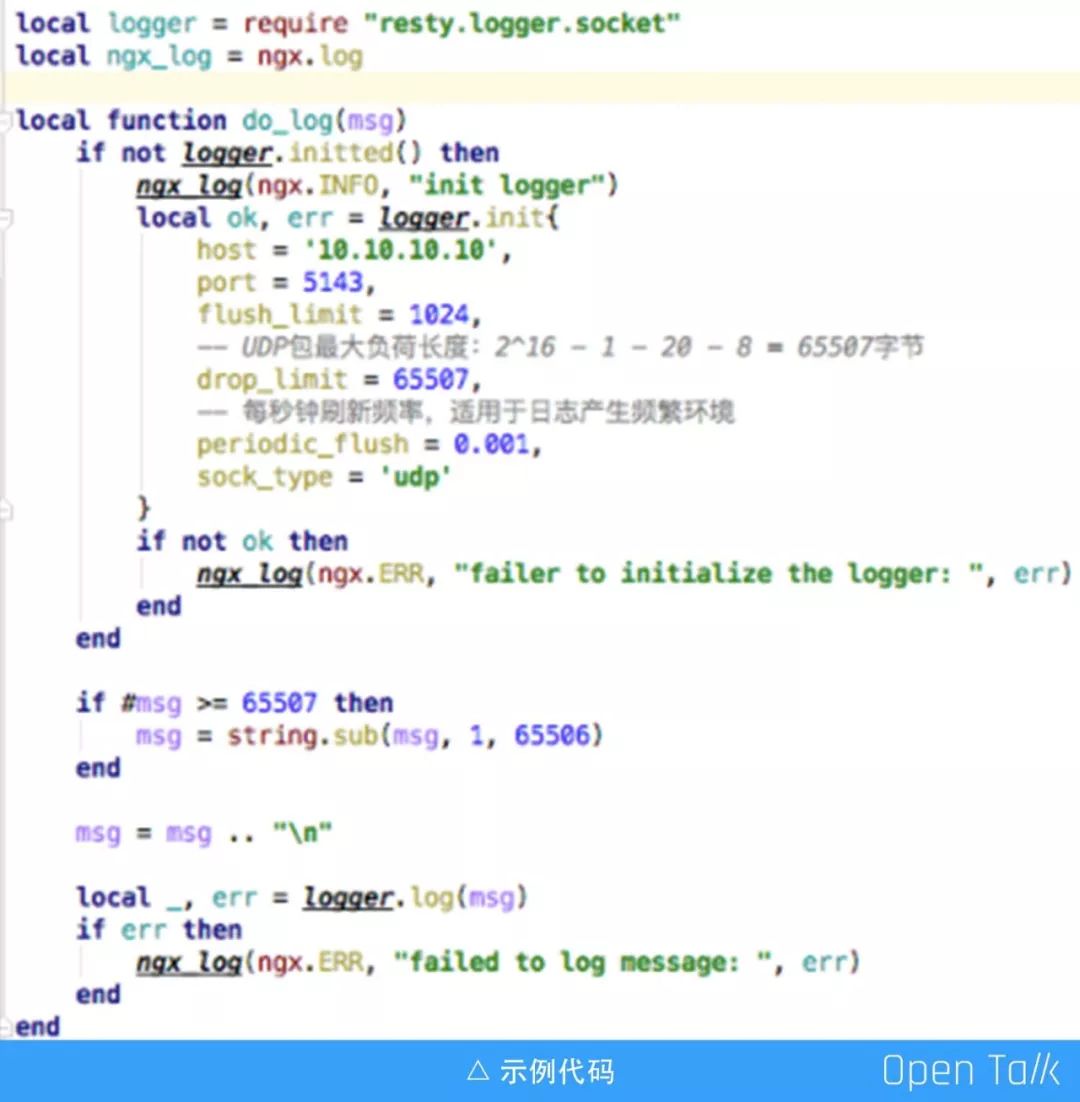
我们的日志系统使用 cloudflare 的 lua-resty-logger-socket 日志组件来实现的,采用 UDP 传输, 使用 UDP 是因为:第一,UDP 需要资源少,不会抢占主业务资源,在有大量日志生成的同时也能保证主业务的健康运行;第二,我们的日志都是在网络比较好的内网之间传输;第三,我们对传输中少量丢包并不敏感。平时很难发现什么问题,在流量上来的时候,有些小症状就暴露出来了。
众所周知,UDP datagram 数据报的长度上限为 65535 个字节,若日志输出超出此限制,这条消息就会被丢弃,发送失败。针对消息进行裁剪,单条消息不应该过大,需要裁剪,避免超载。
我们可能会收到这样的一条警告 logger buffer is full, this log message will be dropped,提示日志记录器缓冲区满了,这个日志消息将被删除。因此我们开启了自动刷新,每 0.001s 去检查缓冲区,加大对缓冲区的消费能力,减少日志被丢弃的现象。日志发送过去是粘连的,我们在每条日志后面加了一个换行符。
当压力过大或 CPU 使用率过高时,UDP 一样会面临传输不过来的问题,就出现创建的 timer 不够使用了。这时我们做了下面的事情:
设置成 syslog 方式传递,极可能的保证不丢失;
舍弃低等级日志,减少日志输出量;
重要日志合并,减少输出次数等。
4、TCP Server glibc 内存不释放
当启用 ngx_lua 模块时,会强制 glibc 的 malloc 使用 mmap 来分配内存。glibc 对于 mmap 分配的块会缓存 free 掉的内存,这部分内存实际上被 glibc 基础系统库缓存了起来。这是一个已知的 OpenResty 内存问题,通过在 nginx.conf 文件 HTTP 节点下配置 lua_malloc_trim 属性,进行设置当前多少个 HTTP 请求后,会自动调用 glibc 库 malloc_trim 函数进行清理掉已释放的内存。默认 TCP 通道是没有这项支持的,不过我们可以增加一个 HTTP 节点,配置一个简单的 HTTP 请求,就可以主动进行释放这部分缓存起来的的内存。

这是一个实际测试的示范,TCP 压测之后内存占用,RES 物理内存为 382 M,一直不释放,主动调用 HTTP 接口后,RES 物理内存为 164 M,清理掉了缓存起来的内存,效果显著。
因为简单的几个 HTTP 请求不一定会均匀的落到所有 worker 进程上。其实,我们还可以根据 LuaJIT 的 FFI 机制进行定时释放:
1、加载 FFI 库,它是 LuaJIT 中最重要的一个扩展库,它允许从纯 Lua 代码调用外部 C 函数,使用 C 数据结构;
2、 为 malloc_trim 增加一个函数声明,标准的 C 语法;
3、进行 glibc.malloc_trim(1) 调用。
示范代码 lua_malloc_trim.lua 已放入github,可以采用每一个 worker 进程定时触发来主动释放内存。
5、GraphQL API
GraphQL 是一种 API 查询语言,客户端能够精确的定义接口的返回数据。以往多次 REST 请求才能拿到的数据,通过 GraphQL 只需要一次请求就可以获得,并且毫无冗余。
只需要三个步骤,第一步:定义数据结构,第二步,请求需要的内容,第三步得到结果。一般来讲,一个较重的 HTTP API 接口返回的内容,大部分内容客户端都是使用不到,白白浪费流量。而 GraphQL API 只返回客户端感兴趣的数据。
GraphQL 的 Lua 版本库目前版本是存在的不足,我们修改了若干 bug 以及进行了定制,定制主要着眼于增加 GraphQL API Client 兼容性,方便客户端开发随时调试。调试通顺了,才能够放心的在业务代码中直接调用。学会了 GraphQL 客户端调试技巧之后,会大大降低了沟通成本。
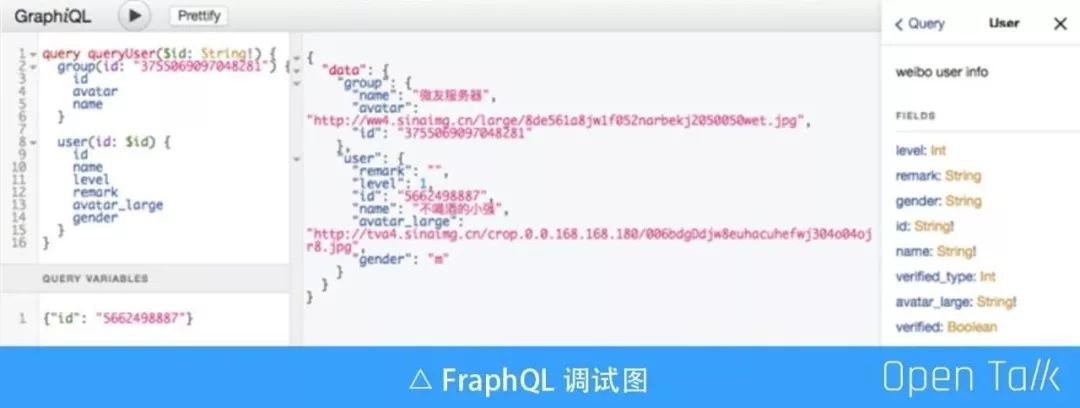
上图是开发过程中客户端同学在谷歌浏览器的 GraphIQL Feen ,工具进行调试接口一个截图,十分方便,左右边是查询语句,中间是执行结果,右边是该 user 对象所包含属性。文档和调试紧密结合到了一起,节省开发同学的不少时间和精力,分布式协作的首选。
6、CPU 过高
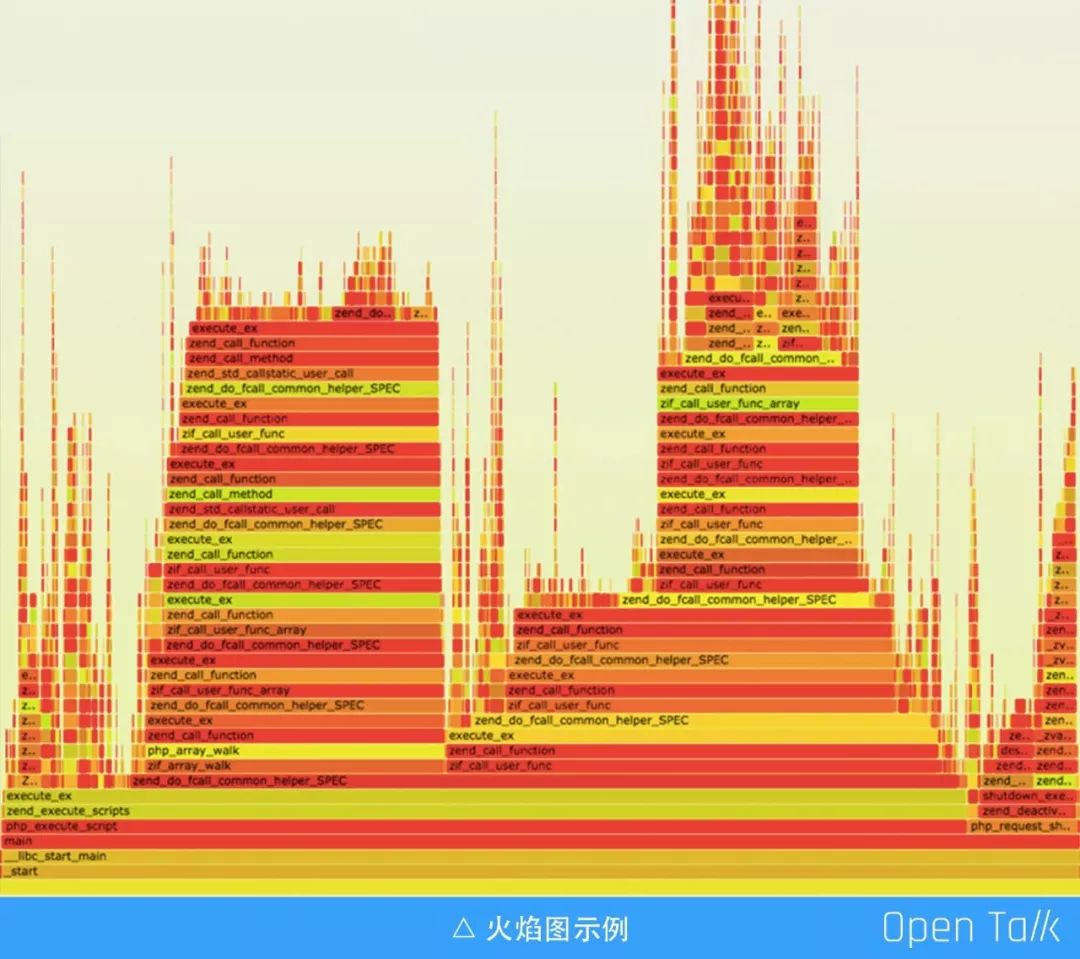
业务处理低效,导致性能出现问题,CPU 使用率过高,大家可能都碰到过这种令人头痛的问题,依靠主观臆断来猜测可不是什么好方法。下面介绍一下我们团队使用的工具 — CPU 火焰图。整个图形看一起来像一团火焰,这也是名字的由来,颜色是随机的没有特殊含义。纵向表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数,横向表示抽样数,如果一个函数在横向占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。一般来说一个正常的火焰图看起来像一座座连绵起伏的山峰,而一个异常的火焰图看起来像一座平顶山。
再次强调下,纵向表示调用栈的深度,横向表示消耗的时间,这是判断火焰图中哪个函数有问题的主要依据。火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"( plateaus ),就表示该函数可能存在性能问题。
火焰图介绍:http://www.ruanyifeng.com/blog/2017/09/flame-graph.html
附加:https://huoding.com/2016/08/18/531
7、内存火焰图
CPU 火焰图很轻松可以找到问题所在,但内存火焰图,就不是那么容易了。可以通过多次采样进行对比的方法,比如一次采样输出 300 秒,一次采样 500 秒,然后对比内存火焰图,寻找变化异常的部分,可能就是内存泄露的地方。仅仅作为参考,不是很保准。另外,谨慎寻找异样输出的蛛丝马迹。
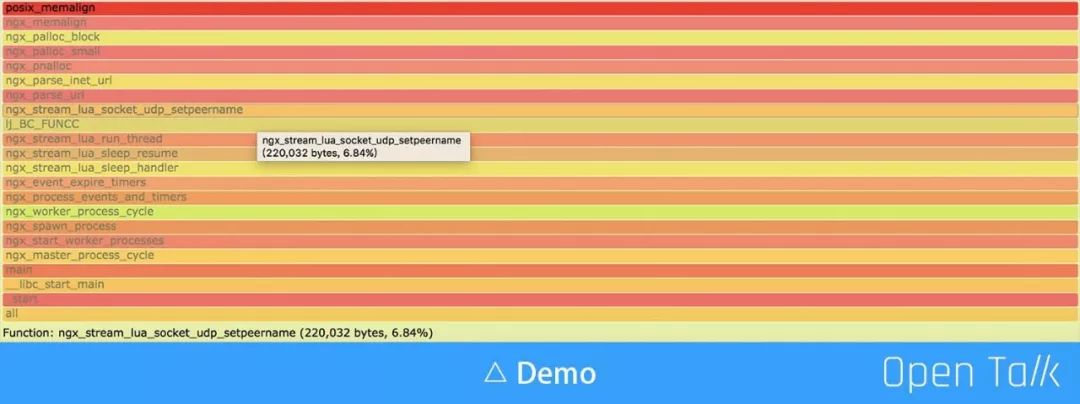
上图是一个示例,ngx_stream_lua_socket_udp_setpeername 在多次采样对比中我们发现 UDP相关业务内存增长较为异常,隐藏很深,根据项目情况,只有在传输日志时才会使用到 UDP,阅读并修正代码,线上进行灰度测试,证实了修改版本的 UDP 传输模块确实存在较为严重的内存溢出问题。
8、调试依赖和压力测试辅助

以上清单是调试中使用工具以及依赖,针对 CentOS 6 系列而言,以上都需要安装或下载。而 CentOS 7 默认的 GCC 就是 4.8 版本 ,不用额外安装。后面三个是 OpenResty 提供的工具套装,一般通过 git clone 形式直接安装。一个一个安装,相当麻烦,若是想随时随地进行调试,则还得需要做些努力。
我们的目的就是简化所有操作,项目成员在发现问题时,一个脚本可以直接呈现问题所在:
可以直接安装 linux 内核开发调试包,包含调试符号的 glibc 依赖库,systemtap 和 gdb 等软件等,OpenResty 工具集等。另外,还提供分析 CPU、内存资源占用情况的脚本工具,运行一个脚本,然后等待出结果,在浏览器直接查看火焰图,进行数据分析。这些工具,已应用在我们线上调试中。
9、压力测试辅助
调试可以跟踪一些常规问题,但有些问题是在有了压力之后才暴露出来的,或者进行容量评估,或通过性能测试寻找瓶颈,这时我们要找一个靠谱压力测试工具了。
HTTP 可选择的压力测试工具很多,比如 ab、wrk、webbeach 等。但 TCP 的就不是很多了,可以选择 Tsung,能够模拟较为复杂的流量来源。借助于压力测试工具,加压的同时,跟踪&诊断 CPU 和内存等问题,方便提前发现隐患。
总结 & 反思
网关的数据传输是基于 TCP 的,连接复用,较主版本减少频繁建连过程。另外,对外开放唯一入口,进行 API 接口收缩,降低认知成本。简单梳理网关的提升点:
关注流这个接口为例,以极速版平均耗时比主版本减少 36.7% 的耗时;以广告接口为例,经由网关的广告接口成功率提升了 0.6%。微博极速版和主版本在阿里云上跑的数据对比,其中数据最明显的一项就是流量消耗,一分钟内相比于主版本,极速版节省了 72.34% 的消耗。
我们把以往的微博结构拆成更小的数据结构,粒度更细,灵活性更高,用服务端发送数据来控制端上渲染的。在微博极速版实际开发中服务器升级就可以改变微博的样式,而不需要客户端发版。
当然现状也是存在问题的,项目之初我们急于验证想法,还有就是人员太少,因此我们采用了单体应用架构设计,其优点是学习成本低,开发上手快,测试、部署、运维也比较方便,甚至一个人就可以完成服务的开发与部署。然而随着业务规模的不断扩大,团队开发人员的增加,单体应用架构就开始出现团队协作成本高、系统高可用性差等问题了,我们已经开始了网关与业务拆分,后续还会对业务进行拆分微服务化。
只要是语言,或框架,都有或多或少的局限性,了解这些局限,才能灵活运用,避免走入误区等。我们来简要梳理一下 OpenResty 需要注意的一些问题:
当前 OpenResty 提供 TCP Stream 组件支持 TCP 协议编程,但支持力度还是没有 HTTP 那样丰富;
UDP 协议编程方面,目前还不是很完善,进度比较缓慢;基于 UDP 的 QUIC 通道,目前还看不到希望,需要等很长一段时间;
基于 GLIBC 的内存管理,如前面论述过的,有可能不会及时释放给操作系统;
socket 文件句柄没法在多个轻量级线程之间共享:一个 cosocket 对象虽然是全双工,但也仅限于,一个轻量级线程负责专门读取,一个轻量级线程负责专门写入。但是你不能让两个轻线程对同一个 cosocket 对象同时进行读或同时写入操作,否则会得到一个类似于"socket busy reading" 的错误;
因为 Timer 数量总体受限,默认运行中的 timer 数量为 256,滥用会收到警告:“256 lua_max_running_timers are not enough”,这也是和 Java、Go、Erlang 不太一样的地方;
OpenResty 虽然是一柄利器,但要完全掌握它,需要学习的技术堆栈还是满多的,比如 Lua,LuaJIT,以及 Nginx 等,还有 SystemTap,GDB 等调试工具的使用。毫无疑问,这将推动我们不断前进。
点击「阅读原文」观看演讲视频和 PPT~
点击「阅读原文」观看演讲视频和 PPT~
快 来 找 又 小 拍
推 荐 阅 读
关于技术
•告 诉 大 家 你 “在 看” 这 篇 文 章 •
以上是关于新浪微博王辉:OpenResty 构建一站式应用网关实践的主要内容,如果未能解决你的问题,请参考以下文章
我想要把用户在文本框填写的内容分享到新浪微博、腾讯微博、QQ空间、人人网,js代码是怎样的?求帮助
用js怎么实现网页分享功能???如分享到:人人,开心网,新浪微博-------我用分享到
基于Qt下移动平台第三方接入-ShareSDK(新浪微博,微信朋友圈等分享登录)