马蜂窝李培:OpenResty在马蜂窝的一些业务场景应用探索丨OpenResty × Open Talk 武汉
Posted 又拍云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了马蜂窝李培:OpenResty在马蜂窝的一些业务场景应用探索丨OpenResty × Open Talk 武汉相关的知识,希望对你有一定的参考价值。
2019 年 5 月 11 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙武汉站,马蜂窝基础平台技术专家李培在活动上做了《 OpenResty 在马蜂窝的一些业务场景应用和探索》的分享。
OpenResty x Open Talk 全国巡回沙龙是由 OpenResty 社区、又拍云发起,邀请业内资深的 OpenResty 技术专家,分享 OpenResty 实战经验,增进 OpenResty 使用者的交流与学习,推动 OpenResty 开源项目的发展。活动已先后在深圳、北京、武汉举办,后续还将陆续在上海、广州、杭州等城市巡回举办。

李培,马蜂窝基础平台技术专家,专注高并发、高可用的基础服务架构设计,“全沾”工程师曾先后负责电商 App,机票、火车票等业务,推崇合适的开源技术帮助业务。
以下是分享全文:
大家下午好,我是来自马蜂窝的李培,今天主要从业务场景选型、业务实践、未来规划三个方面介绍马蜂窝怎么使用 OpenResty。
马蜂窝业务场景选型
首先,技术最重要的就是场景选型,合适的场景做合适的事情,并采用合适的技术。马蜂窝采用 OpenResty 做业务应用服务选型,主要考虑以下几个特点:
跨语言和平台。马蜂窝现在的主要技术栈语言有 php、JAVA,GO,Python。平台有 Linux、Windows,ios,android,微信小程序,Web H5 等;中台的基础服务和组件需要对跨语言和跨平台的支持;
性能损耗小。高效是选择基于 OpenResty 开发应用的核心因素;
健壮、高可用。 基础服务要保证容灾、自动降级和预警,而 OpenResty 配合 Lua 能很灵活高效的实现这些功能;
上游服务之前,可以实现非接口形式。在上游服务之前透传一些公共的标识、属性、参数,避免基础服务需要维护多个 sdk 且需要保持一致性的弊端;
轻量非阻塞。OpenResty 的特点之一是同步非阻塞,所以在 OpenResty 主要的业务应用一定是非阻塞的,马蜂窝一些业务会根据需求自己实现异步但是逻辑不会特别多比较轻量级;
数据有限集合。单个 LuaVM 最大内存是 1G,可以做的事和存储是有限的,毕竟它是基于内存,如果业务有大量的数据去查库,不太适合这些场景,需要评估数据量和 QPS。
业务实践案例
A/B testing 实践
OpenResty 在蚂蜂窝的一个比较重要的业务实践是 A/B Testing 基础组件。选用 OpenResty 主要基于以下几点:

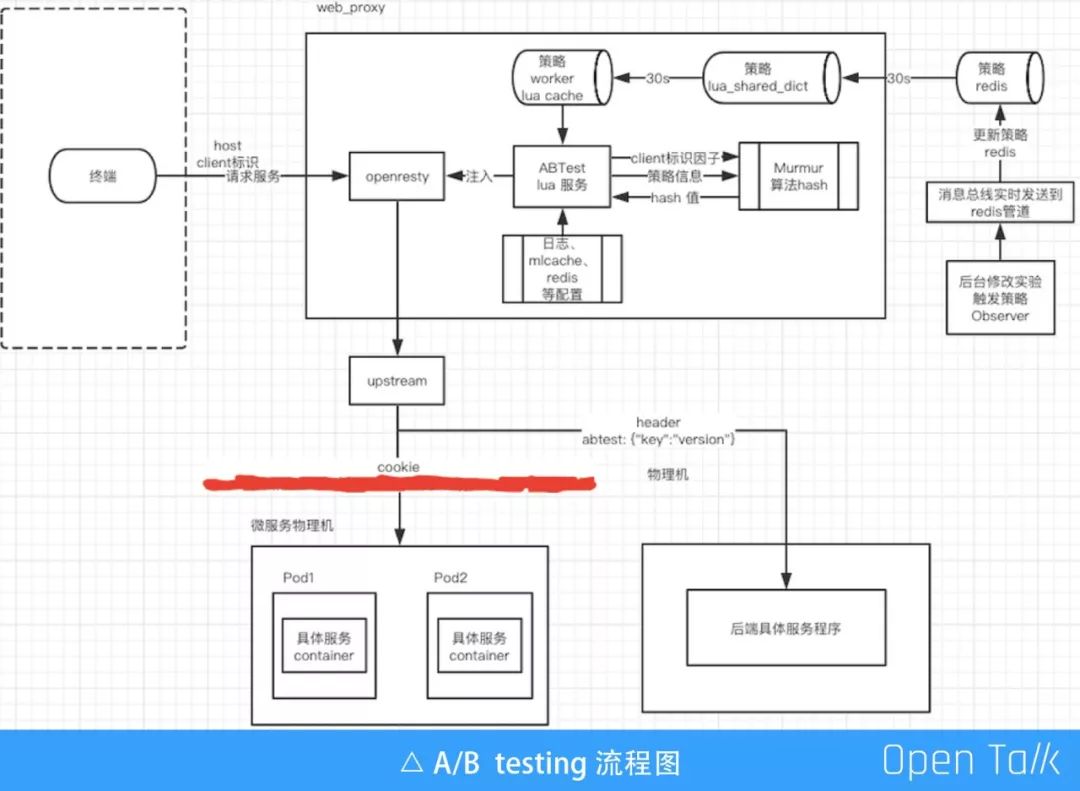
以下是 A/B Testing 使用 OpenResty 的流程图:
A/B 发布
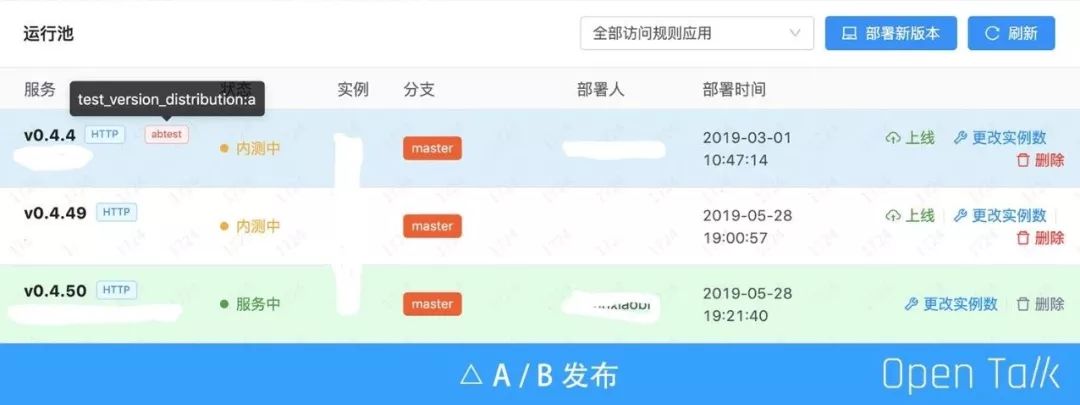
常规 A/B 发布主要由 API 网关来做,当面临的业务需求比较复杂时比如针对 App 版本、用户画像比如性别、是否有订单等, A/B 发布通过与与微服务交互的方式,来开放更复杂维度的 A/B 发布能力。
业务 AB
除了 A/B 发布,马蜂窝 AB 更偏向于业务侧。产品、运营、技术等不同角色不同业务权限可以在后台配置 A/B 实验的策略。策略池 observer 观察到策略变动通过消息总线 MQ 同步到 Redis L3 回源缓存。
用户终端请求要做 AB 的服务时根据三要素(终端唯一标识、请求资源、AB 策略)由OpenResty AB 应用进行逻辑处理,经 murmur 算法 hash 找到当前匹配的 AB 实验和版本后传给 upstream,upstream 通过自定义header 协议透传(物理 Web)和自定义 cookie 协议传递(微服务)。
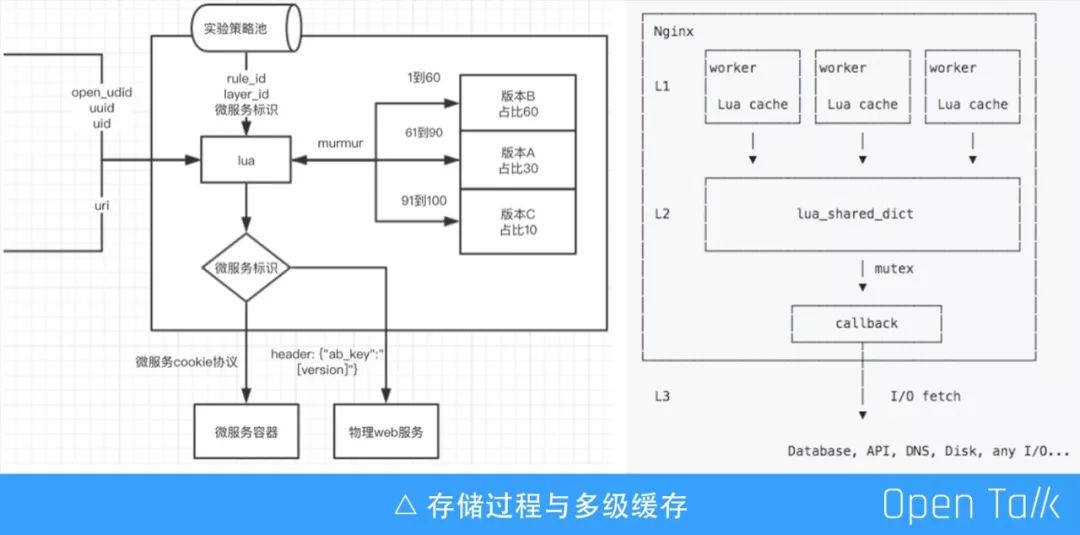
多级缓存
重点提一下三级缓存设计。
第一层 lrucache,是一个简单高效的缓存。它的特点是伴随着 nginx worker 进程的生命周期存在,worker 独占,十分高效。由于独占的特性,每一份缓存都会在每个 worker 进程中存在,所以它会占用较多的内存。
第二层 lua_shared_dict,这个缓存是 OpenResty 比较重要的一个特点,可以跨 worker 共享。当 Nginx reload 时它的数据也会不丢失,只有当 restart 的时候才会丢失。为了安全读写,实现了 mutex 互斥锁。所以在某些极端情况下可能会存在性能问题。
第三层 Redis,回源。
虽然采用了多级缓存,但仍然存在着一定的风险,就是当我们的 L1、L2 缓存都失效的时候(比如 Nginx restart),可能会因为流量太大让 Redis 面临“裸奔”的风险,所以我们这里用到了 lua-resty-lock,在缓存失效时只有拿到锁的这部分请求才可以进行回源,这样就保证了 Redis 的压力不会那么大。 我们在缓存 30s 的情况下对线上数据的进行统计。第一级缓存命中率在 99% 以上,第二级缓存命中率在 5‰,回源到 Redis 的请求只有万分之三。
直接使用共享缓存在某些极端场景下可能会有问题的,例如在并发量较高时,writing 数会不断上涨。我们在测试的时候设置为 10M,如果数据量过大会遇到一些性能上的问题,大家可以稍微注意一下。
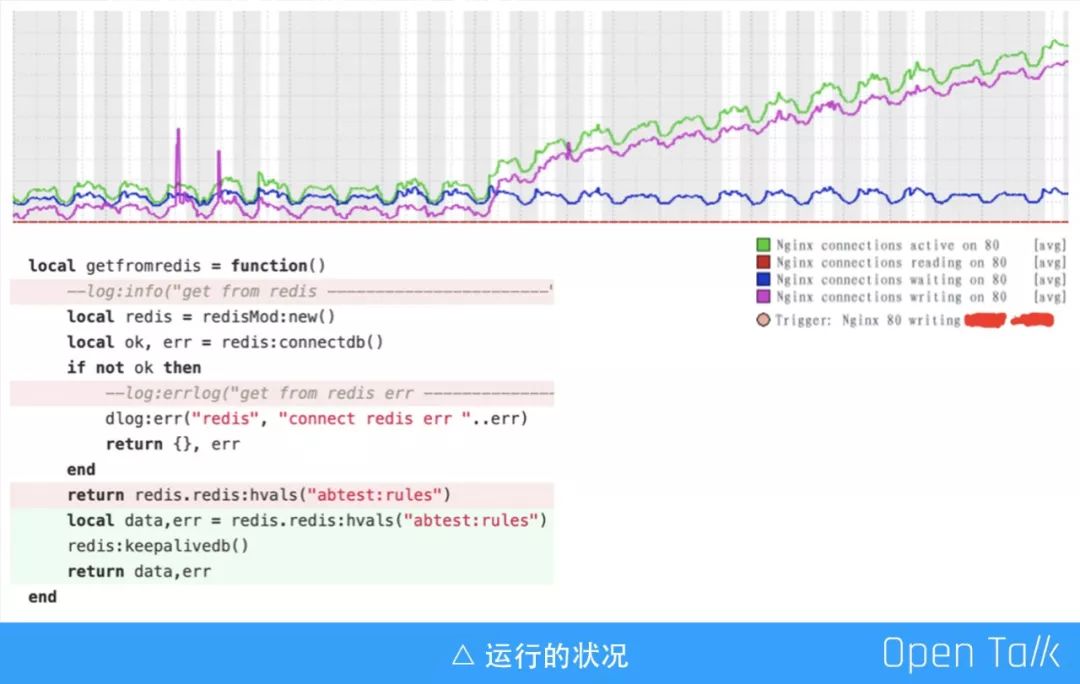
上图是是监控运行一个月之后的结果,上线当天没有发现异常,但是后来它的 Nginx writing 数值一直在上涨。我们发现是直接使用 Redis 导致的,如果涉及到使用数据缓存,尽量使用长连接,回源如果不是长连接,在流量并发较大时可能会把 Nginx connections 拖高。
测试结果
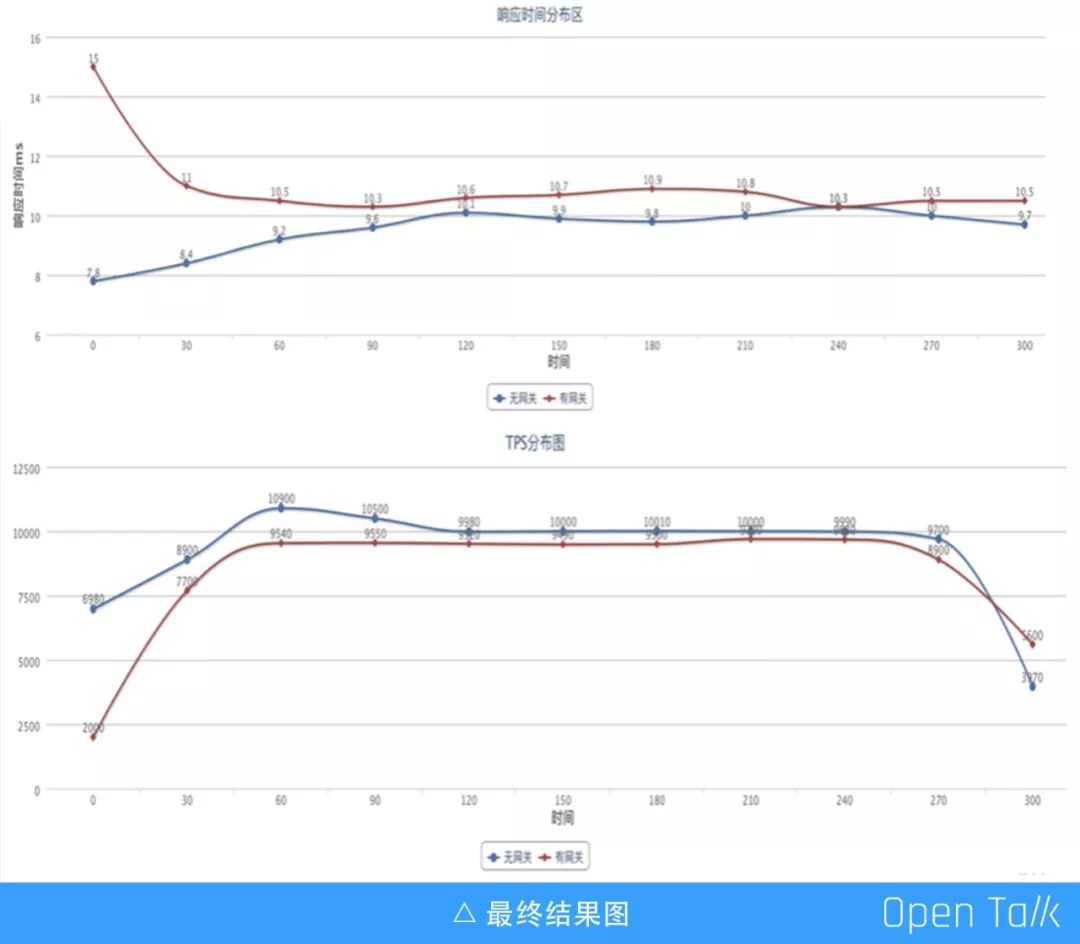
如图蓝线的是没有加 OpenResty 和 Lua 代码的运行曲线,红线是加了 OpenResty 和 Lua 代码之后的运行曲线,蓝色纵坐标维持在 8 - 10ms,红色是 9 - 11ms。从响应时间来看,除了刚开始的时候请求偏离值比较大,之后平均在 1 - 2ms,消耗比较小这里就不放火焰图了。开始的时候差距比较大的原因是多级缓存里面没有数据,只要不 restart 就不会出现这个趋势。总体上来看,随着 TPS 的上涨,响应时间没有明显的变化。
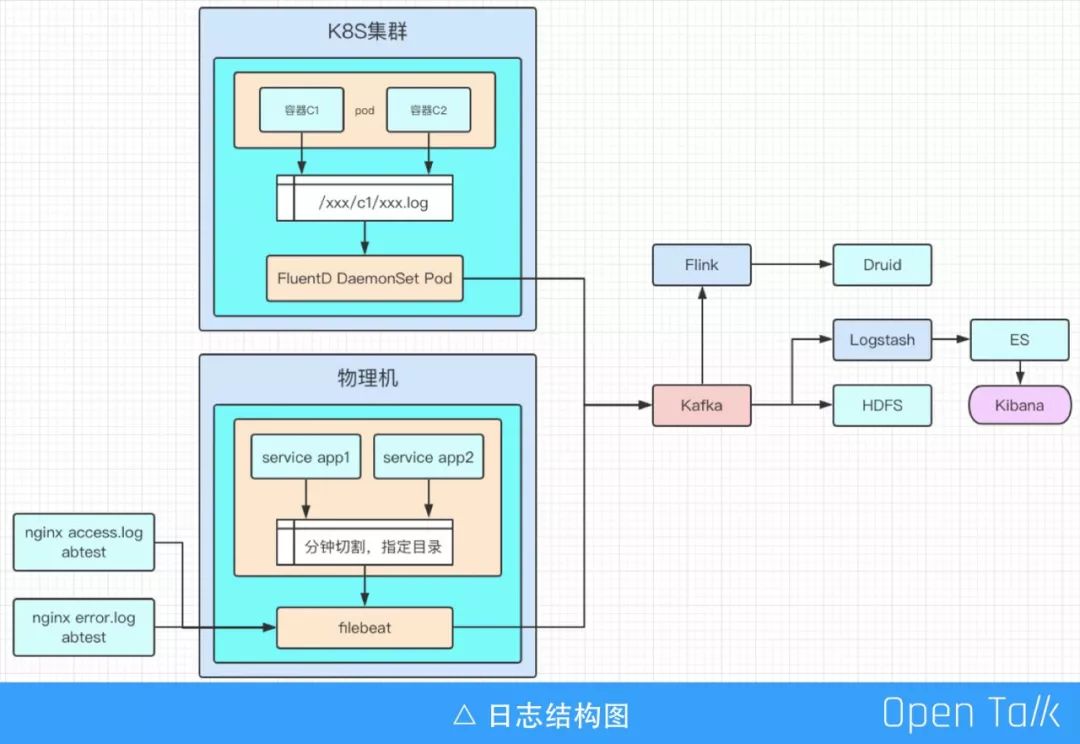
日志
即时通讯实践
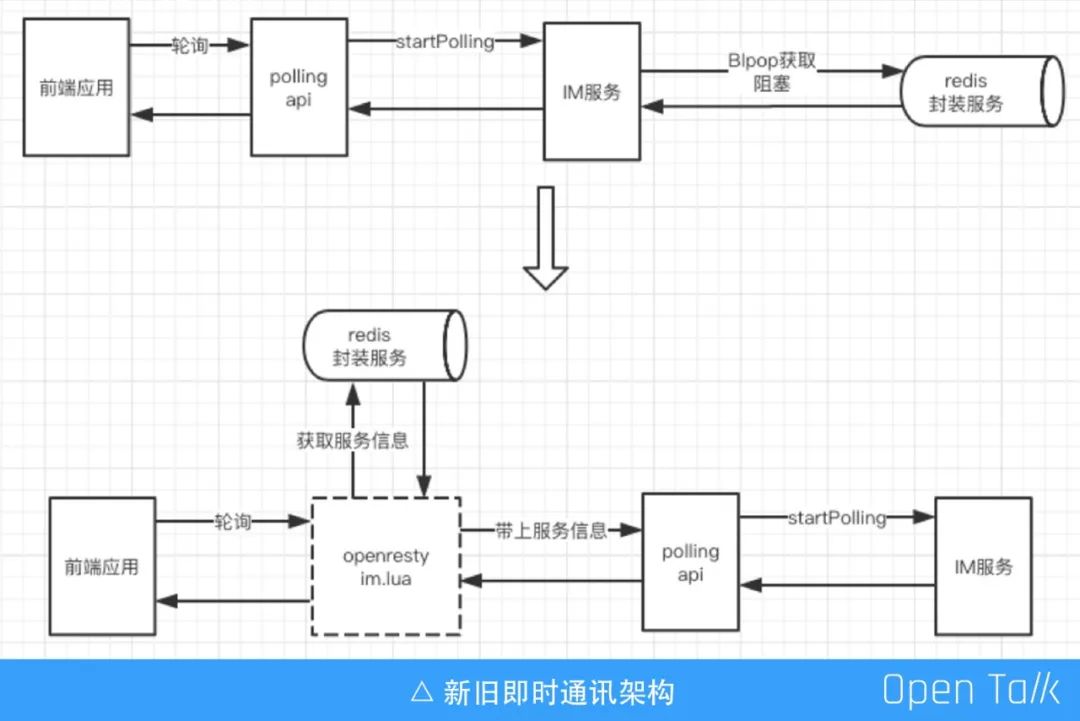
原:请求 php polling 服务接口,使用 Blpop 阻塞获取 Redis 服务应用数据(业务需求),导致 php 进程挂起 php-fpm 一直处于占用状态,大量消耗服务器资源
现:通过 Lua 协程来接管必要的长连接,释放 php-fpm 去做其它事情,节省服务器资源
结果:优化前需要 3 台还不足以应对峰值;优化后只需要一台资源即可负载 polling 请求。

这是我们的改造历程,基于 OpenResty 和 Lua,这之后用 GO 取代了原来的 PHP 做的后端服务。Lua 更多是做前置标记的透传,比如咨询供应商、咨询店家、看用户是不是有订单、多少订单以及成交量是多少等。
用 Openresty 做业务基础服务时有几个注意点:
lua_shared_dict 的 mutex 其实是自旋锁+互斥锁的混合锁,在一些极端条件下需要注意。
restart 会清除 shared_dict 的缓存数据,对于运维没有什么影响,但是对实际业务开发是有一些问题的。前面提到的用户画像的参数,如果本来是有的,现在突然没有了,这段时间的数据都是对不上的,会因为某功能导致当前用户咨询后,但是没下单的比例变高,所以一定要注意 reload 之后 ops 操作对 dev 业务的影响。
Nginx ingress 在 restart 后注意各种配置是否有持久化存储,还有热更新怎么生效。
未来规划
JWT 通用服务
软 WAF
链路追踪
更多符合技术场景选型的基础服务
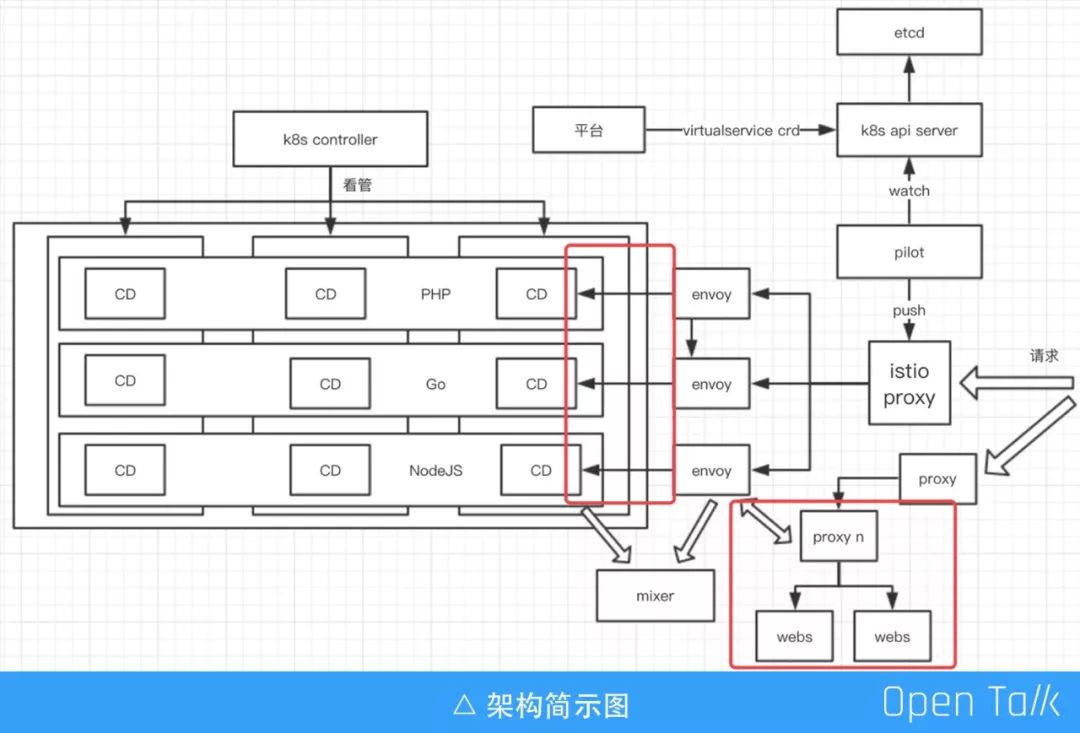
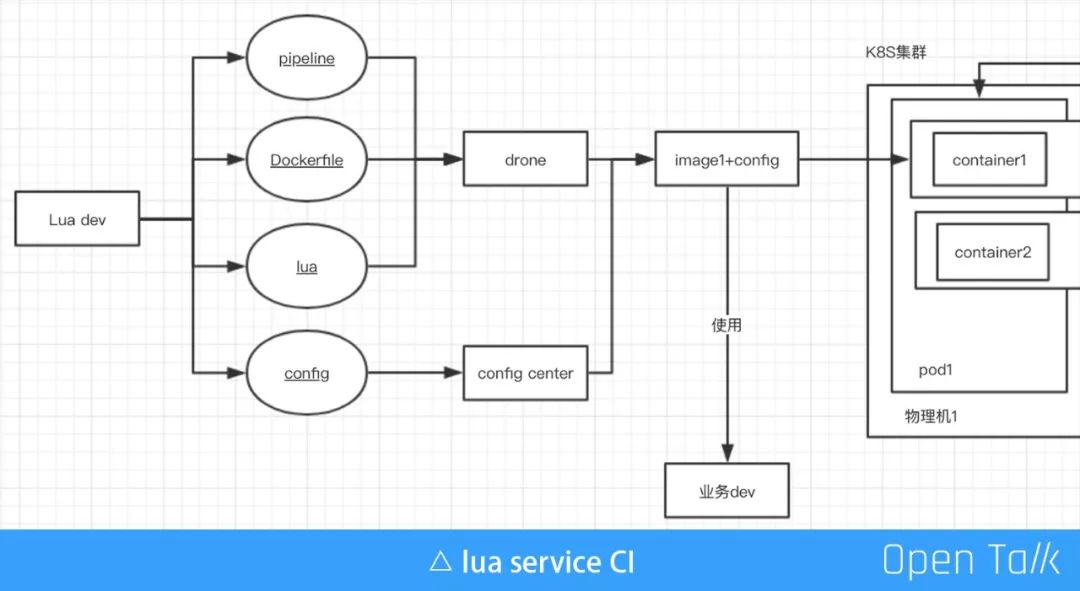
Openresty 的应用实践 更多的在红框标注区域进行,并且更多的关注 Lua 使用规范、日志、监控。(最新稳定版的已经正式 release,希望OpenResty 和 Nginx 更新频次能更高社区更活跃一点)
未来需要改进的地方还有很多,我们也将持续探索,期待和大家一起交流。以上是我今天的全部分享,谢谢大家!
观看视频和 ppt 下载,请点击阅读原文!
快 来 找 又 小 拍
推 荐 阅 读
关于技术
•告 诉 大 家 你 “在 看” 这 篇 文 章 •
以上是关于马蜂窝李培:OpenResty在马蜂窝的一些业务场景应用探索丨OpenResty × Open Talk 武汉的主要内容,如果未能解决你的问题,请参考以下文章