K8S集群容量规划: 容量规划系列2
Posted 大魏分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8S集群容量规划: 容量规划系列2相关的知识,希望对你有一定的参考价值。
文章较长,先说结论:
结论:
K8S集群中,所有pod都应该设置request数值。否则资源利用率统计很不准。
资源不够的时候,没有设置request和limit的pod最先被驱逐,其次是request<limit的pod被驱逐,最后是request=limit的pod被驱逐。
集群在使用中,有的资源允许压缩使用,有的不成。CPU、网络I/O可以;内存和磁盘空间不建议。但很多时候pod并不是同时使用,因此稍有有一些超额分配是可以的,可以在limitrange中的maxLimitRequestRatio设置百分比。当然,这个百分比要通过测试实现。也就是说,当资源不够的时候,pod会被驱逐,根据你能接受的驱逐pod的频率,设置评定当时的超分率。当然,超额使用的设置还和每个namespace的qouta的设置有关。从集群角度看,K8S整体的qouta可以大于整体的可提资源。
K8S节点会预留资源,主要分为两部分Kube-reserved, system-reserved。当资源利用率超过的可分配资源时(开始侵占预留资源),K8S开始驱逐内存。K8S驱逐pod的阈值可以设置,也就是说,当节点的资源少于多少的时候,开始驱逐pod。
容量规划主要是对比request资源和实际使用率。根据实际使用率的上浮下浮20%,我们设定资源的上限、下限预估值。低估造成资源不够,高估造成资源浪费。如果出现高估,可以减少request,limit不变,让request< limit。如果出现了低估,那降低limit,让request=limit。
在集群规模的评估时,如果资源使用率超过80%,则建议增加K8S集群的节点。如果资源利用率低于40%,并且在公有云上,可以考虑缩减集群规模。但在私有云的生产环境则没有必要这样做。
在正式介绍K8S集群容量规划准则之前,我们需要介绍介绍K8S节点资源过度承诺(NODE OVERCOMMITMENT)以及带来的的危害。
过度承诺
过度承诺,本质上是一个节点上运行pod的limits总和,大于节点可分配资源,说简单点就是Limits设置的太大,大于节点可分配的资源。
下图显示了在CPU上过度使用的节点,我们看到CPU limits总和是节点可分配CPU的四倍。
过度承诺本身并不是一件坏事。实际上,它使您可以更密集地打包工作负载。它的工作原理是,并非所有的Pod都会在同一时间索取所有可用资源 。
那么,正确的问题是:我们应该超额使用多少?
用户将必须找到正确的超额使用水平。建议使用谨慎的策略来识别它。例如,您可以逐步增加超额使用水平并观察您的工作量。当驱逐机的速率开始变得不可接受时,这就是给定工作负载的正确超负荷水平。也就是说,当节点由于资源不足开始驱逐pod时,并且这个驱逐的频率开始无法接受了,那就说明超额使用的比率不能再增加了。
定义过量使用策略后,您可以在namespace级别或群集级别执行它。
在每个namespace级别,您可以使用LimitRange对象的maxLimitRequestRation。如下所示:
https://docs.openshift.com/container-platform/4.6/nodes/clusters/nodes-cluster-limit-ranges.html
apiVersion: "v1"kind: "LimitRange"metadata:name: "resource-limits"spec:limits:- type: "Container"max:cpu: "2"memory: "1Gi"min:cpu: "100m"memory: "4Mi"default:cpu: "300m"memory: "200Mi"defaultRequest:cpu: "200m"memory: "100Mi"maxLimitRequestRatio:cpu: "10"
如果要在集群级别设置此比率,则可以使用ClusterResourceOverride配置对象中的memoryRequestToLimitPercent和cpuRequestToLimitPercent,可以在主配置文件中指定该对象。
建议:定义并执行您的超额使用政策。
建议:开发具有使用节点及其承诺级别创建报告的功能。
建议:如果节点超额使用超出了超额使用策略中定义的范围,则创建警报以通知您。
翻译结果过度承诺本身并不是一件坏事。实际上,它使您可以更密集地打包工作负载。它的工作原理是,并非所有的Pod都会在同一时间索取所有可用资源(这是银行工作的相同原则:他们假设并非所有客户都希望同时提取所有资金) 。那么,正确的问题是:我们应该超额使用多少?而且,我们如何执行该价值?组织将必须找到正确的超额使用水平。我建议使用谨慎的策略来识别它。例如,您可以逐步增加超额使用水平并观察您的工作量。当驱逐机的速率开始变得不可接受时,这就是给定工作负载的正确超负荷水平。一旦定义了过量使用策略,就可以在项目级别或集群级别执行它。在每个项目级别,您可以使用LimitRange对象的maxLimitRequestRation。如果要在集群级别设置此比率,则可以使用ClusterResourceOverride配置对象中的memoryRequestToLimitPercent和cpuRequestToLimitPercent,可以在主配置文件中指定该对象。建议:定义并执行您的超额使用政策。建议:开发具有使用节点及其承诺级别创建报告的功能。建议:如果节点超额使用超出了超额使用策略中定义的范围,则创建警报以通知您。
资源类型
就资源压力下的行为而言,有两种类型的资源:
可压缩资源:只要您有时间等待它们,这些资源就永远不会耗尽。在给定的时间内,您可能会使用有限数量的它们,但是如果您愿意/能够等待,则可以无限量使用它们。此类资源的示例是CPU,块I/O和网络I/ O。
不可压缩的资源:有限的资源,当您用尽它们时,您的应用程序将无法再使用它们。此类资源的示例是内存和磁盘空间。
在配置资源设置时,请记住这一区别,这一点很重要。某些类型的工作负载可能对另一种更为敏感。如果未正确设置内存和其他不可压缩的资源,则可能会杀死Pod。另一方面,如果未正确设置CPU和其他可压缩资源,则工作负载可能会饿死。
在重大压力下保护节点
正如我们所讨论的,如果节点过量使用,则可能会耗尽资源。这种情况称为资源压力。如果节点服务意识到它处于资源压力之下,则它将停止接受新的Pod,并且如果资源存在问题是不可压缩的,则它将开始尝试通过逐出(即杀死)pod来解决这种情况。选择要驱逐的Pod来满足Pod的QoS。
Pod的服务质量
以下服务质量(QoS)存在于OpenShift中,并由Pod上定义请求和限制的方式确定:
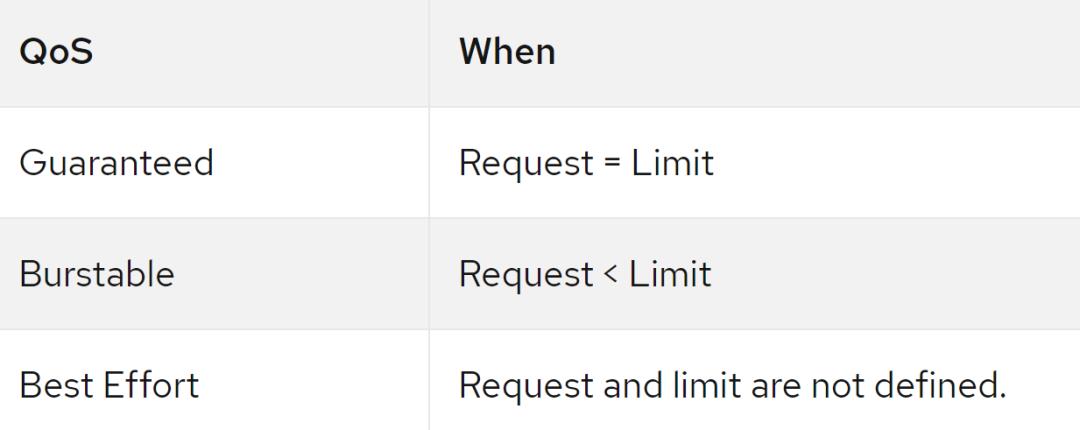
当给定资源超过驱逐阈值时,将开始驱逐Pod。可以立即驱逐Pod( hard eviction threshold),也可以给Pod适当的关闭时间(soft eviction threshold)。软驱逐阈值还允许您定义一个观察周期,该观察周期将在资源使用量超过阈值时触发。如果在观察期结束时资源使用量仍高于阈值,则开始逐出。
当节点资源不足时Pod 按照下面的顺序被驱逐(QOS):
BestEffort:消耗最多紧缺资源的 Pod 最先驱逐。
Burstable:请求(request)最多紧缺资源的 Pod 被驱逐,如果没有 Pod 超出他们的request,会驱逐资源消耗量最大的 Pod。
Guaranteed:请求(request)最多紧缺资源的 Pod 被驱逐,如果没有 Pod 超出他们的请求,会驱逐资源消耗量最大的 Pod。
当前,可以为以下不可压缩资源定义逐出阈值:内存,节点文件系统,映像文件系统(这是docker存储)。
建议:至少为内存配置硬驱逐阈值。例如:
kubeletArguments:
eviction-hard:
- memory.available<500Mi
除了定义驱逐阈值之外,还可以通过在节点服务中配置以下内容,专门为节点服务和其他OS级服务保留资源:
kubeletArguments:
kube-reserved:
- "cpu=<cpu>,memory=<mem>"
system-reserved:
- "cpu=<cpu>,memory=<mem>"Kube-reserved: :为Kubelet服务保留资源
System-reserved:为所有其他非Pod进程保留资源(不包括Kubelet服务)
Kube-reserved, system-reserved和eviction threshold 共同确定可分配级别。下图显示了最终可分配资源的计算方式:

建议:始终使用kube-reserved和system-reserved的Kubelet参数为OS服务保留一些资源。
注意:您可以为内存和CPU保留资源,但是可以仅为内存定义驱逐阈值.
我们很难为这些设置提供一个很好的默认值(您应该分析系统的行为,以找到适合您的安装的理想设置);但是,这是一个适用于小型节点的公式:
Kube-reserved cpu: 5m x max number of pods per node
Kube-reserved memory: 5M x max number of pods per node
System-reserved cpu: 5m x max number of pods per node
System-reserved memory: 10M x max number of pods per node
在上面的公式中,CPU m指的是ms。一个CPU Core =100ms。比如说一个节点上有200个pod,那么5m*200=1000ms,也就是kube-reserved cpu就会是一个core。
请注意,默认情况下,每个vCPU最多分给10个Pod。这个数值可以调整。
内存的其他注意事项
对于内存,还有一个附加的防御机制:如果节点服务无法识别内存压力情况,例如,由于内存高峰太突然了,节点服务没有时间注册它,那么OOM内核服务将终止运行。
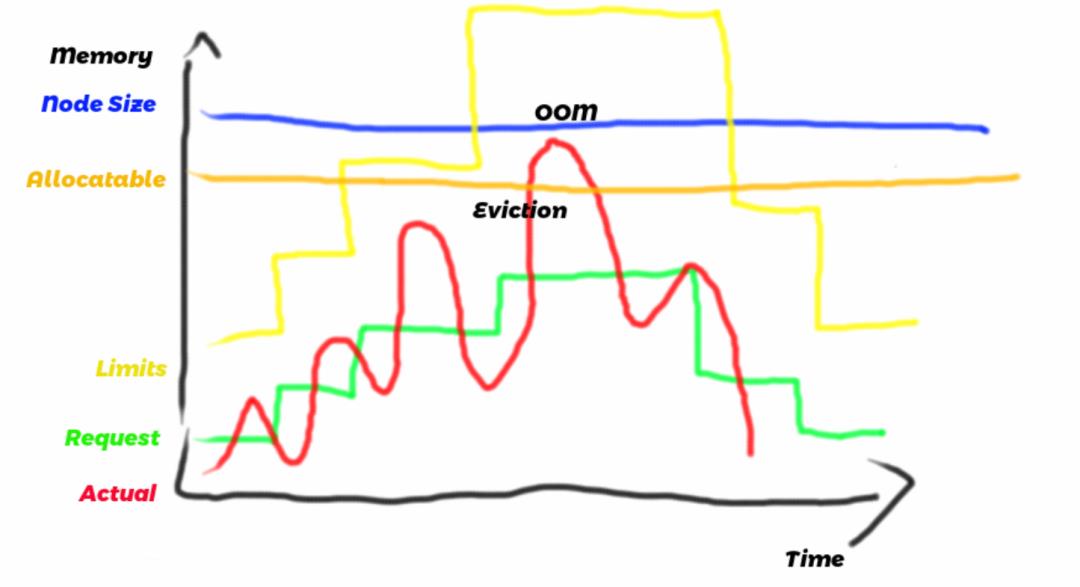
在上图中:
蓝线和橙线分别表示内存总量和可分配的内存(如上所述计算)。这两个量度的值是恒定的。
绿线表示分配给该节点的Pod的请求总和。调度程序将确保此度量值始终低于可分配的内存量。
红线是节点上的实际内存使用情况,包括所有Pod的总和以及节点守护程序保留的内存量。取决于几个因素,例如应用程序的编写方式和当前负载,此度量的波动幅度大于请求的总和。当红线超过allocatable线时,节点开始驱逐pod。
黄线表示的最终度量是限制的总和。根据cgroup的组织方式,实际的内存使用量将始终低于限制的总和。但是,如果工作负载是突发性的,则限制的总和可能变得大于可分配的节点。如我们所见,在这种情况下,该节点变得过量使用。
CPU的其他注意事项
构建了一些OpenShift集群以专门针对可爆发的工作负载。例如,通常大数据,机器学习或简单的批处理和异步集成数据科学类型的工作负载本质上都是突发性的。
这意味着这些进程可以在指定的CPU请求下运行,但是如果有可用资源,它们将消耗更多,达到其限制并提前终止。
可以禁用对CPU的限制。这将使可爆发进程消耗所有可用资源。如果两个进程在争用相同的CPU资源,则仍然可以保证公平的调度,因为它是根据请求值计算的。
我们可以禁用强制执行CPU限制的方法:
kubeletArguments:
cpu-cfs-quota:
- "false"
总之,我们要防止节点过度分配。实施这些做法将提高群集的整体稳定性。
容量规划
容器云容量规划很重要的一点是:对比容器的实际资源使用总量和request总量。如下图所示,usage大于request。这是正常的,如下图所示,需要指出的是,本文展示的利用率,都是在集群视角的整体利用率,而不是一个pod的利用率。
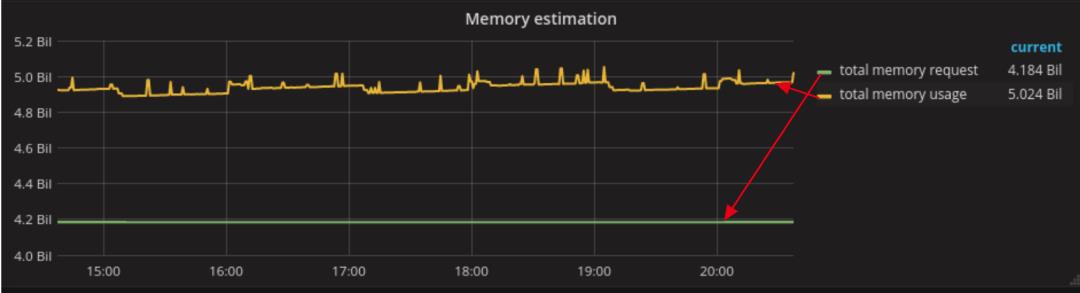
我们以实际使用量为基准,分别设置下限值和上限阈值,以20%为范围。
需要注意的是:我们不要被下图的英文单词搞晕:underestimate的线在overestimate线上面的原因是:actual usage相对于underestimate thread是低估20%之内;actual usage相对于overestimate thread是高估20%之内。所以under和over的主语是actual usage。
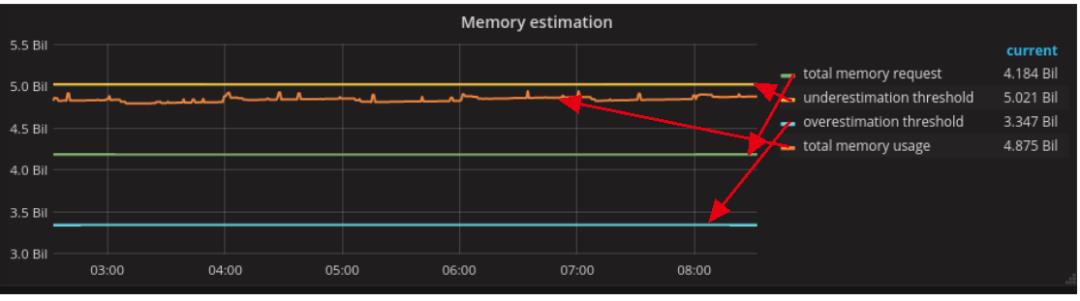
高估
如果估算值明显高于实际值,则我们高估了pod所需的资源。
多少是太多了?这取决于您对浪费资源的容忍度。再次使用20%作为我们的容限阈值,下图显示了被高估的工作量,在下图中,underestimate thread是actual usage的两倍:
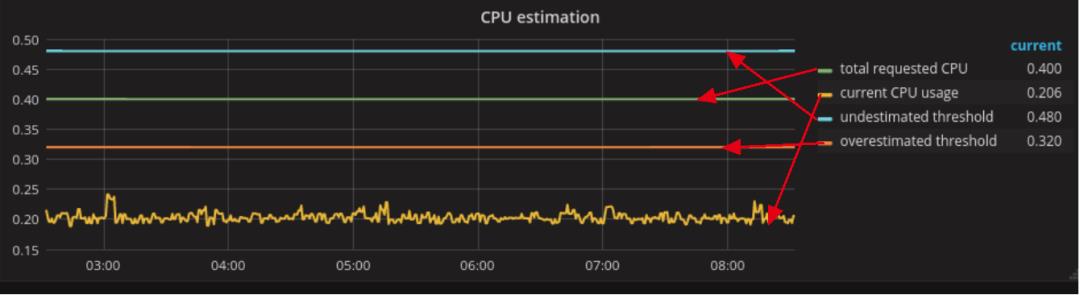
如果最终遇到这种情况,我们应该继续分析,找到资源利用率最高的pod,看这些pod的是否可以做一些调整或者优化。如果这些Pod正在使用保证的服务质量(QoS),则考虑将这些Pod更改为Burstable,也就是减少request,limit不变。让request< limit。
建议:使用一段时间的平均值作为评估的依据。
低估
相反,如果实际值高于估算值,则我们低估了pod的利用率。
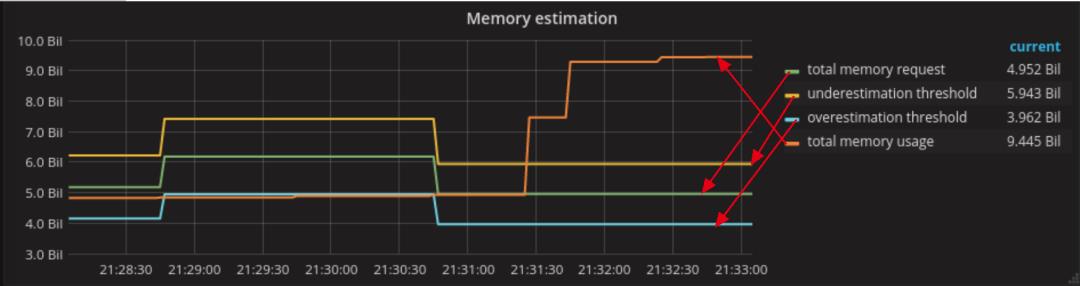
请注意,只有当某些Pod的limit大于其request时,才会发生这种情况。
这是更危险的情况。实际上,在这种情况下,我们的一个或多个节点可能会被过量使用。
通过此图,我们需要找出使用了比其request更多资源的Pod列表。可能需要考虑将这些Pod从Burstable转移到Guaranteed QoS,也就是说,让request=limit。
集群规模
一旦我们确信我们的工作量被估计为最佳,就可以开始对集群大小进行推理了。
实际情况是无法预测的,因为它们很大程度上取决于pod当前服务的负载。通常,我们将比较工作负载估计值与集群容量和两个规模阈值,定义如下:
集群Scale Up的阈值设置在集群资源利用率的80%
集群Scale Down的阈值设置在集群资源利用率的40%
使用这些阈值,以下是正确大小的群集的图片:
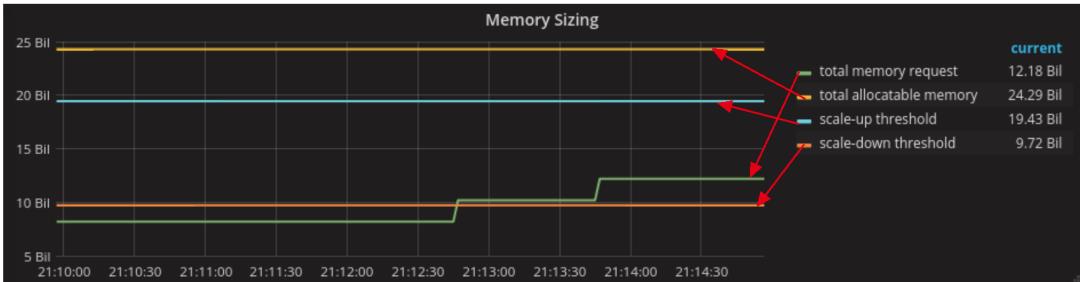
不足的集群
下图显示了一个较小的群集:
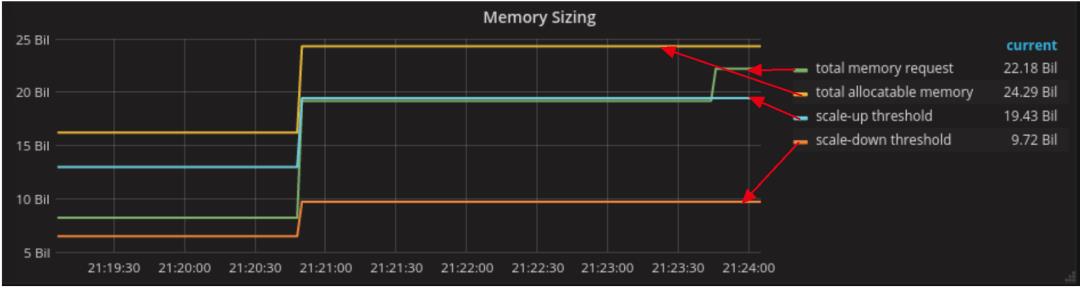
此图显示了request值超过了Scale Up阈值。我们应该收到此事件的通知,并开始添加节点。
建议:当估算值达到您的向上扩展阈值时创建警报。
集群过大
相反,这些图像显示了一个超大的群集:
我们在此处定义了按比例缩小的阈值,占总容量的40%。图中request memory远远小于scale down阈值。这时会出现资源闲置。但生产上没必要缩减集群。
集群承诺级别
集群的承诺级别=total quotas / total allocatable。
下图这是过量使用40%的群集的示意图。
如果承诺级别大于1,则集群被过度授权。同样,这本身并不是一件坏事。实际上,我认为对于集群级别的承诺,运行超额使用50%到100%的集群是完全正常的。
为了以这种方式计算集群承诺,应该使所有namesapces都处于配额之下(按照本系列第一部分的建议),并且所有配额都应在资源request 中设置(而不是limit)。
我们应该关注集群的承诺水平,但是我不认为这应该是决定是否扩展集群的主要标准。主要标准仍然应该是估计数与可用资源之间的比率。
但是,某些公司在向群集添加新容量时可能会花费很长的采购时间(例如,因为必须配置新的物理硬件),因此它们无法快速做出反应。在这些情况下,配额可以是比需求更好的长期趋势指标。
结论:
K8S集群中,所有pod都应该设置request数值。否则资源利用率统计很不准。
资源不够的时候,没有设置request和limit的pod最先被驱逐,其次是request<limit的pod被驱逐,最后是request=limit的pod被驱逐。
集群在使用中,有的资源允许压缩使用,有的不成。一般情况下,CPU、网络I/O可以;内存和磁盘空间不建议。但很多时候pod并不是同时使用,因此稍有有一些超额分配是可以的,可以在limitrange中的maxLimitRequestRatio设置百分比。当然,这个百分比要通过测试实现。也就是说,当资源不够的时候,pod会被驱逐,根据你能接受的驱逐pod的频率,设置评定当时的超分率。当然,超额使用的设置还和每个namespace的qouta的设置有关。从集群角度看,开群整体的qouta可以大于整体的可提资源。
K8S节点会预留资源,主要分为两部分Kube-reserved, system-reserved。当资源利用率超过的可分配资源时(开始侵占预留资源),K8S开始驱逐内存。
容量规划主要是对比request资源和实际使用率。根据实际使用率的上浮下浮20%,我们设定资源的上限、下限预估值。低估造成资源不够,高估造成资源浪费。如果出现高估,可以减少request,limit不变,让request< limit。如果出现了低估,那降低limit,让request=limit。
在集群规模的评估时,如果资源使用率超过80%,则建议增加K8S集群的节点。如果资源利用率低于40%,并且在公有云上,可以考虑缩减集群规模。但在私有云的生产环境和则没有必要这样做。
以上是关于K8S集群容量规划: 容量规划系列2的主要内容,如果未能解决你的问题,请参考以下文章