重磅:构建AIOps的MNIST
Posted AIOps智能运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重磅:构建AIOps的MNIST相关的知识,希望对你有一定的参考价值。
作者简介
运小聪 百度高级研发工程师
负责监控数据分析、数据可视化等相关工作,致力于降低异常发现、故障定位的时间和人力成本,让自动化系统的眼睛更加明亮。
前文回顾
干货概览
我们在一文中提到,运维操作一般可以分为感知、决策、执行三部分,而在感知阶段我们通过识别服务指标数据中不符合预期的模式来发现服务异常,即监控数据的异常检测。
很多时候,大家手中的异常检测是一条拍脑袋想出来的规则,或者根据经验大致估算的阈值。这样的异常检测常常存在较多误报、漏报、效果不佳的情况。而上线前基于标注数据的效果评估是提高效果最重要的手段。为了获取大量、准确的标注数据来评估算法效果,我们进行了一系列探索。
本文将主要介绍在监控数据异常标注实践中遇到的问题和解决方案,并给出一个当前由百度智能运维团队与清华大学Netman实验室合作研发的辅助标注工具原型 https://github.com/baidu/Curve ,欢迎大家一起探讨。
时序数据异常标注
在监测服务的收入、流量、可用性、性能等指标时,通常会对数据进行流式的采集和汇聚,每个数据点反映的是某段时间内的服务状态,这些时间序列数据简称时序数据。
在异常检测方面大家或多或少都有过类似经历:针对一次故障设置了报警规则,其中的阈值根据这次故障设置。上线后不断发生误报,因此调低阈值。阈值调低后误报减少,但在一次新故障发生时发生漏报,又调高阈值。如此往复,在误报与漏报之间徘徊。这是因为以bad case(误报、漏报)驱动的阈值调整常常会以偏概全、前后矛盾,导致整体的准确率和召回率很低。解决问题的最佳办法是在上线前使用标注数据对报警规则进行系统地评估。
另一方面,对于复杂场景的异常检测,大量准确的标注数据也是使用统计方法或机器学习方法建模的必要条件。
为了进行正常数据建模和算法效果评估,我们需要获取大量准确的标注数据,通常时序数据可以从监控系统中方便地获得,标注则需要人工完成。在数据标注过程中主要有两类问题:
准确性:标注人员通常对异常认识不清晰,随着标注进度的推进,判断标准很容易发生漂移。
标注效率:异常数据占比很小,标注时大量的时间耗费在检查正常数据上,效率较低。
经过一系列调研,我们发现已有的时序数据标注工具较少,功能也比较简单,仅提供了趋势图展示、异常时段标注、简单参考线(天同比/周同比)等功能,对于解决标注过程中的准确性和效率问题帮助有限。
这里,我们给出了一种基于自动异常检测的辅助标注方法:在标注开始前,自动分析疑似异常区间,高亮提醒标注人员关注,减少检查正常数据耗费的精力;在标注过程中,提供异常区间对比功能,协助标注人员认识异常,避免判断标准的漂移,减少标注数据前后矛盾的情况。
时序数据标注工具
我们着手研发了一款时序数据异常标注工具,辅助标注人员更快更准确地进行时序数据标注,为正常数据建模和异常检测评估提供足量准确的标注数据集。
当前的标注工具以一个 Web 的形式呈现,提供数据上传、标注、下载功能,辅助标注的主要算法逻辑由 Python 实现,可以方便地借助相关科学计算模组进行修改。
可视化和标注功能
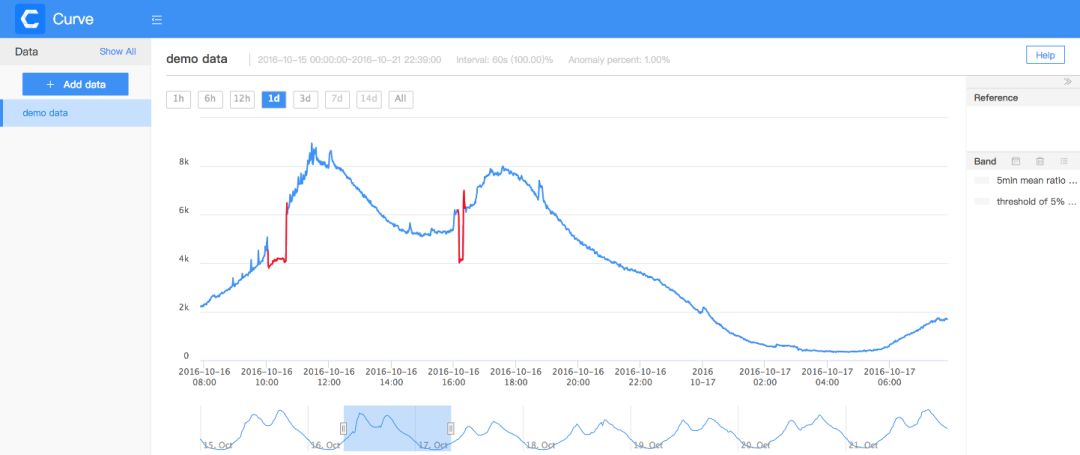
一般的时序数据标注工具都会提供一些基本的可视化和标注功能,包括通过拖动、快捷按钮等方式设置x轴和y轴的显示区间以控制曲线的缩放,通过拖动等方式标注异常数据等。除了这些基本的功能之外,我们针对标注场景作了专门的优化。
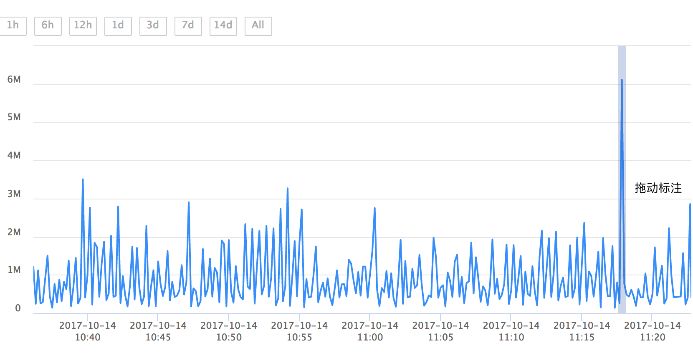
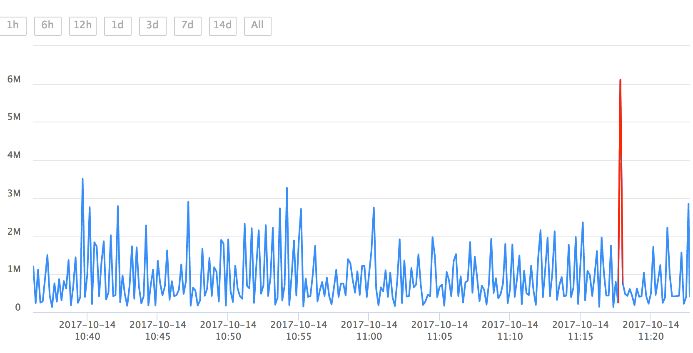
有时少数异常数据的值与正常值相比差别巨大,可能有数量级的差别。直接展示这些数据会导致整条曲线被压扁变平,掩盖曲线上其他的波动。这时用户往往需要先手工设置曲线的y轴区间才能开始正常标注。如果用户每次载入曲线都要设置一次y轴区间,无疑是很麻烦的。针对这种问题,我们在工具中添加了离群点自动判断功能,排除离群点之后,我们就能找到合适的y值区间,让用户看到合理的曲线形态。
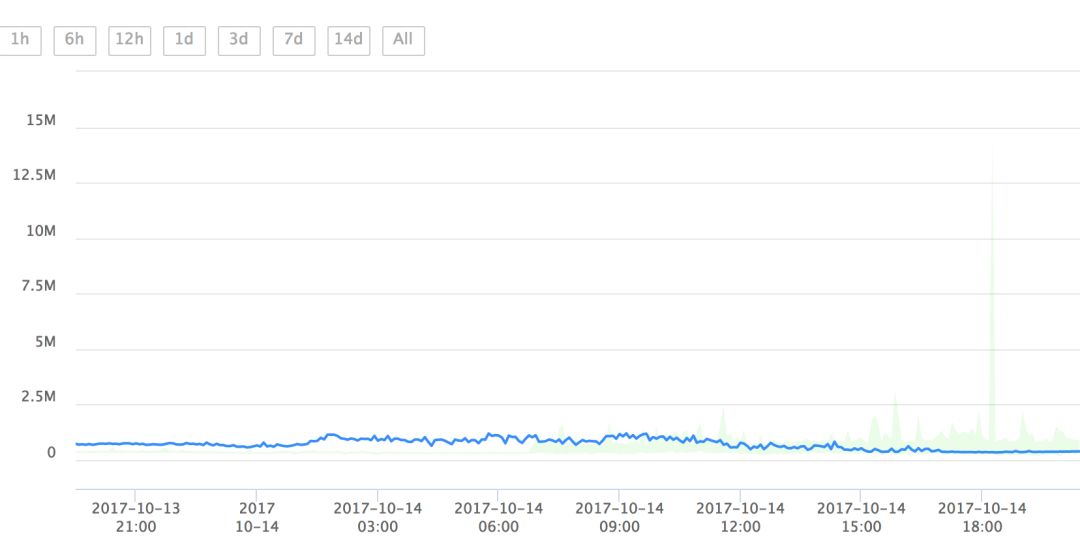
默认 Y 轴取值范围
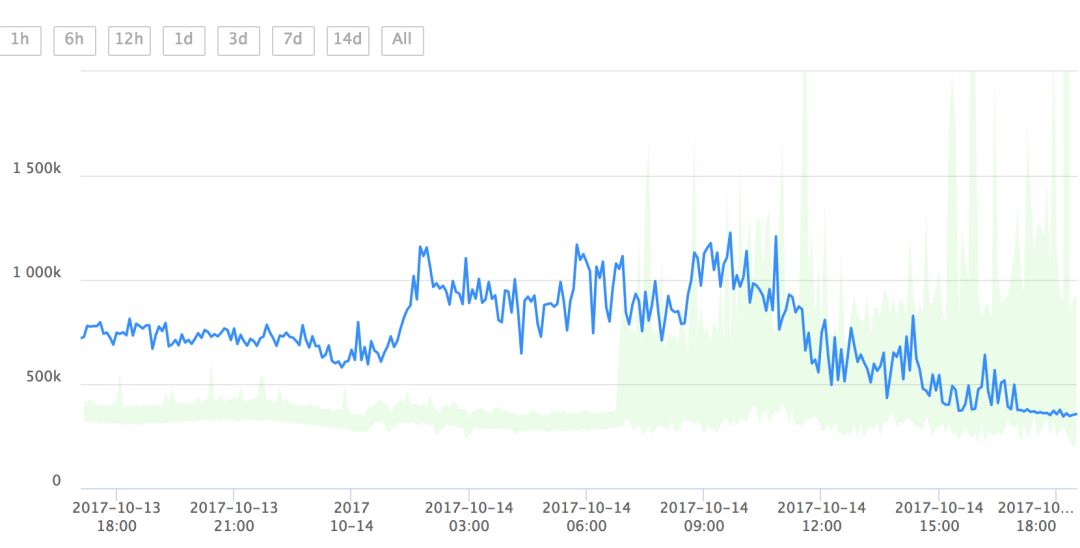
基于离群点检测的 Y 轴取值范围
我们标注时通常会先浏览数据来初步了解数据的分布,标注时也常常先寻找大致的异常区间再仔细标注。这种浏览的尺度比较大,由于屏幕分辨率远低于数据点数,不可避免地要进行采样或聚合,常用的均值方法会平滑周期内的尖峰和低谷,降低异常幅度,影响标注工作。针对这种问题,我们在工具中提供了最大值、最小值采样方法,可以适应上溢、下溢异常场景,在标注时暴露出完整的异常幅度,解决采样带来的失真问题。
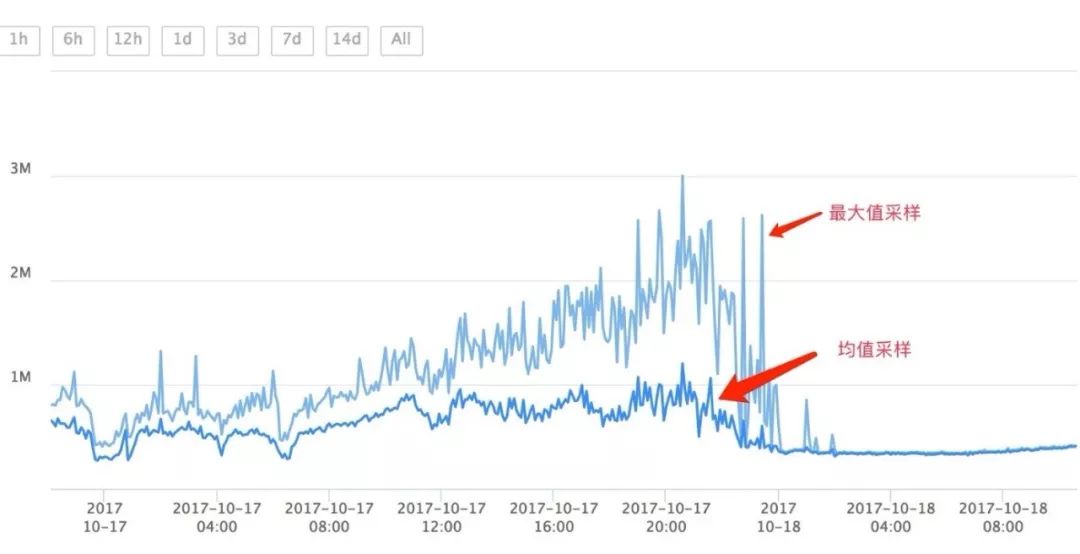
辅助标注功能
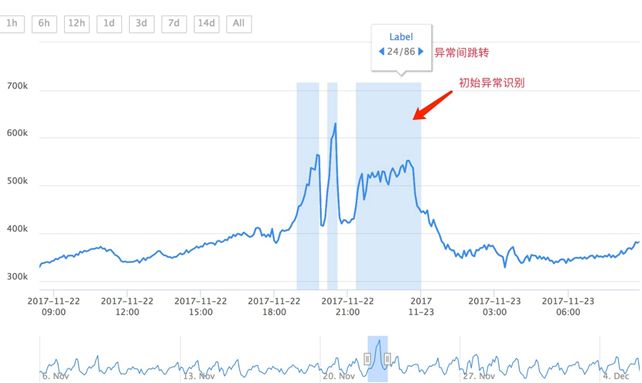
在其他时序数据异常标注工具中,通常提供了天同比、周同比参考线或恒定阈值线,这些参考线在一定程度上满足了标定人员参照历史数据的需求,但是面对单调上升指标(如用户数量)、预期内突增(如活动流量)等个性化场景提供的帮助比较有限。针对这个问题,我们开放了参考线生成功能,可以根据场景自行编写插件添加参考线。除此之外,还在标注工具上尝试了初始异常识别和异常区间对比两个辅助标注功能。
在标注以外的时间,我们通常不会持续关注一个指标的变化过程,这样,在标注过程中接收到的数据会远多于平时的观察,受到已标注数据潜移默化地影响,标注人员的判断标准会发生一定程度的偏移,影响标注准确性。针对这种问题,在数据初始化阶段我们使用异常检测算法对数据进行检测,确定疑似异常区间,用高亮的方式提示给标注人员,这种标准一致的提醒可以在一定程度上减轻标注人员受到的影响。
同时,由于使用了较宽松的阈值,轻微的异常也会被识别出来,这样,标注人员可以重点检查高亮区域,降低检查正常数据的消耗,提高标注速度。
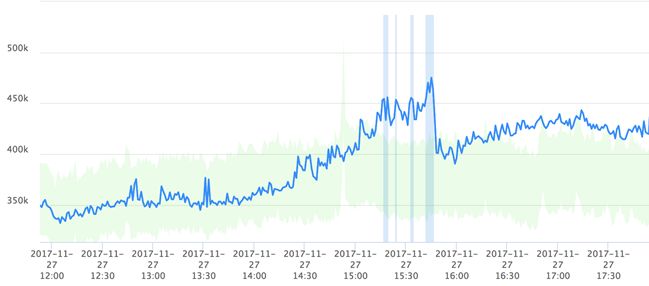
在不能确定一段数据是否异常时,我们通常会和已标注为异常的数据进行对比,这种对比由于异常数据占比较小变得非常麻烦,需要先在比较大的尺度上找到异常区间,然后再放缩到与待标注区间相同的比例尺才能进行对比。针对这种问题,我们提供了异常区间跳转和异常概览两个功能,可以方便得跳转到上一个、下一个异常区间进行对比,也可以在标注结束后把所有异常区间放在一起进行对比。
正在路上…
除了上述已有功能,一大波更新正在路上,接下来还会有:
更快的加载速度,标注过程更加流畅:在原型实现中,包括数据库、网络交互在内的诸多工程细节都没有进行针对性优化,导致标注中会出现轻微卡顿情况,这些卡顿将在下一版完整修复。
在线的标注工具,打开即用:在前期试用中发现,对于标注人员,从源代码开始部署一个服务比较麻烦。为了让使用者更加方便,我们会在收集足够意见反馈后整合出一个SaaS化的标注平台,让标注人员即开即用。
拉一大波标注数据出来祭天:在调研时发现,时序数据异常检测领域缺少一个类似 MNIST 的标准数据集,虽然有部分高校给出了一些数据集(如石溪大学的http://odds.cs.stonybrook.edu/),但是这些数据集过小,难以用于统计方法和机器学习方法建模。为了让更多有想法但是接触不到数据的同学有条件参与相关探索,我们将公开部分标注数据,和大家一起建设一个公共的标准数据集。
INVITATIONS
上文中提到的各种基础功能优化和辅助功能均通过插件的形式实现,大家可以参照给出的样例方便地编写适合自己场景的插件。
考虑到标注数据的应用场景多种多样,仅凭一两个团队遇到的场景、总结的解决方案是有限的,所以我们还邀请了阿里、滴滴等公司的同仁一起合作进行时序数据异常标注方面的探索。
在这里,也诚邀各位一起参与讨论(https://github.com/baidu/Curve/issues),对于有建设性意见或者代码、标注数据贡献的同学,有精美礼品相送。在时序数据预测、异常标注、异常检测方面,不管是想法还是吐槽,代码还是数据,统统欢迎。
相关文章
↓↓↓ 点击"阅读原文" 【了解更多精彩内容】
以上是关于重磅:构建AIOps的MNIST的主要内容,如果未能解决你的问题,请参考以下文章