一位运维眼中的AIOps
Posted 智能运维社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一位运维眼中的AIOps相关的知识,希望对你有一定的参考价值。

AI 时代,AIOps 热炒,运维应该关心的是什么:
AIOps 到底是什么?
AI 和 Ops 究竟是什么关系?
AIOps 到底会带来哪些改变(颠覆 or 提升)?
按照 Gartner 的定义,AIOps 是 Algorithmic IT Operations,但是在人工智能时代,可能很多的人会把 AI 理解成 Artificial Intelligence,不去纠结定义,本质上,想要表达的意思是一样的,就是让运维具备机器学习和算法的能力。
如果直观的理解 AI 和 Ops 的关系,类比到人,AI 相当于人的大脑,我们手脚和躯干是执行系统,大脑负责决策判断,手脚躯干负责完成大脑下发的动作指令。
我们可以稍微停顿再思考一个场景,无人驾驶是怎么样的?
不难得到答案,AI 更多的是根据路况做决策判断,然后将这些指令下发给汽车自身的驾驶系统(如左转、右转、倒车、油门、刹车等)。在一定条件下(如完善的交通规则、良好的公民素质等),基于海量的数据和优秀的算法,机器学习做出的判断会比人更加高效和准确(至少机器不会因为疲惫而造成反应迟钝等等)。
解释到这里,以此类推,就不难理解 AI 和 Ops 的关系了。
“基于专家经验”到“基于机器学习”的转变
前面提到,AI 发挥的作用是,动态变化场景的复杂条件下,能够做出高效准确的决策判断。回到运维上来,我们现在常看到的监控告警、根因分析、日志异常检测、报警聚合、容量预测、故障预测等等,这些都是要基于海量的线上运行时数据,做出分析判断的,所以在这一块,我们会看到大量的跟 AI 结合的 AIOps 的解决方案,特别是智能监控。
而对于一些静态化的配置(CMDB、应用配置管理等),或者按照标准的流程规范,按部就班就可以完成的事情,比如持续集成、发布和部署等等,这些其实就没有必要硬跟 AI 本身扯上什么关系了,但是不是也完全没有任何关系呢?也不一定,后面会看到。
下面以智能监控方面的例子来说明一下,我理解的一整套的 AIOps 应该是什么样子。
参考说明:以下参考 http://www.infoq.com/cn/,搜“赵宇辰”
发现问题—机器学习算法在异常检测中的应用

从“基于专家(人)经验”演化成“基于机器学习”的判断和分析模式,举个监控告警规则设定的例子。
通常处理一个问题,抽象出来就是以下三个环节,我们就从这三个环节一步步分析我们要做的具体的事情:
a、传统模式下基于人的经验,是基于固定阈值的设定,比如 CPU 高于 80% 就告警,Load 超过 Core 的 2 倍就告警等等,而这个 80% 和 2 倍,就是基于人的经验设定的,说的高端一些是专家经验。而这种经验的适配性其实是很差的,不同的应用和场景的阈值可能又不一样,大量个性化的配置就出现了,当达到一定规模时,人工基本是不可维护的。
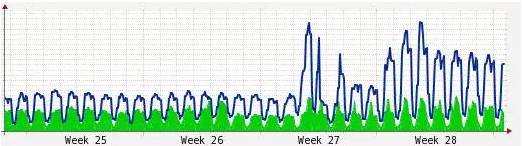
b、发现了这种适配性不好,可以采用动态阈值判断,比如 3-sigma,或者分段 3-sigma,这个时候算法可以根据正态分布的概率,自动的调整告警阈值。但是,这样的算法容易忽略周期性和趋势,比如大促时的各项监控值一定是非常高的,而春节等假期又是非常低的,这时的监控点的分布极有可能是在正态分布之外的,如下图的个别节点就很难识别是否异常。
c、继续改进,到这个阶段,就可以引入一些机器学习算法了,比如基于指数平滑的二次平滑、三次平滑算法,基于分解的傅里叶分解、小波分解算法等,基于深度学习的前馈神经网络、循环神经网络 RNN 算法等,还有其它算法等等,这个时候,算法就需要通过大量的线上历史数据进行训练,以便得出相对准确的告警策略。
d、如此多的算法,到底应该选择那个?这个时候又引入了一类机器学习算法,自动模型选取的分类算法。多个算法同时进行训练,针对不同的场景,每一种算法的效果会不同,这时根据与历史结果的对比,调整每个算法的权重,最终得出一个共同决策结果。如下图所示:
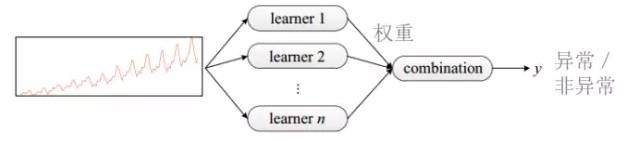
在 c 和 d 阶段,已经可以引入机器学习的算法,并会通过大量历史数据的训练,让算法能够相对准确的进行异常检测,自动生成告警策略。
分析问题—RCA 根因分析
第一个阶段是发现问题,这个阶段是针对单个异常信息的,比如单个的 meric 异常、单个应用进程异常、单个应用日志信息的异常等。但是实际情况下,通常一个部件发生异常,有可能会导致周边依赖的部件会同时异常,而且会同时导致 N 个的指标异常和告警。
比如,DB 一条慢 SQL 超时,DB 会告警、依赖 DB 的应用因为连接阻塞也会告警,RT 告警、QPS 异常告警、Load 告警,JVM 告警等等多个指标异常,而且有可能一整个集群都在告警,收告警的人也很多,DBA、PE、开发、SA 等等,再复杂一点,同一时间点,可能还有线上变更操作,如应用在做发布、DB 在执行 DDL、DML 等等。
这个时候,在一个分布式系统里,我们发现了问题,但是问题根因在哪里,就变得十分重要了,这个确认不了,就没法进行止损和故障消除。而且这个定位过程一般是非常非常痛苦的,越漫长越痛苦,但凡处理过故障的同学都会有深刻的切身体会。之前我们通常只是说要做告警收敛,简单和常见场景下靠人的经验是容易判断的,但是复杂情况下,还是得借助机器学习相关的算法,且系统越庞大、越复杂,靠人和专家会越来越无力。
这个时候就需要一套根因分析 RCA 框架来帮我们做这方面的分析工作,宇辰老师给出的建议是 Monitor Everything,然后根据相关性和决策树方面的算法进行根因分析,这块从分享内容看,在业界也是有比较成熟的分析算法。下面给出我的理解,直接看下图:
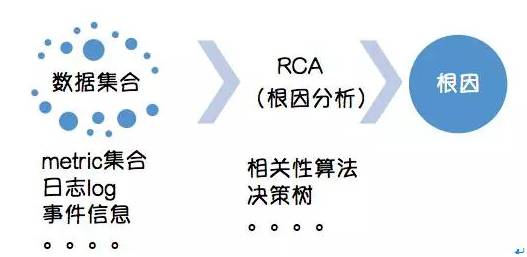
推荐阅读:清华大学裴丹老师的《基于机器学习的智能运维》
解决问题—通过运维体系和场景去执行动作
上面两个部分,我们更加精准的发现和分析了问题,那接下来,我们就该解决问题了,准确的说是做解决问题的动作,这个动作谁来做呢,当然是 Ops 运维体系发挥作用了,比如:
a、容量不足,要做扩容动作,或者降级或限流动作
b、发现某台或部分机器 CPU 或内存异常,那做下线动作
c、有慢 SQL,那要尽快执行 Kill 动作
d、代码有 bug?赶紧回滚,或者重新发布修改 bug 的代码
e、。。。。。
如果说前面的两个阶段要看算法的效率和准确度是不是高,到了这个阶段,就看解决问题的动作执行是快是慢了,这个取决于啥呢?当然 取决于我们的整个运维和稳定性体系是否高度自动化,是否高度完善。如果高度完善,在第二步分析问题发现根因后,应该可以跟一个运维的预案场景关联,自动触发预案的执行。做的再好一点,可以做到 AI 的预测,提前识别出可能会发生的问题,提前将预案执行完成。如果能做到这个程度,我想也算是很牛 x 的 AIOps 体系了。
当然,在发现问题和分析问题阶段,也会依赖基础的运维体系,比如日志采集、全链路跟踪、CMDB 和应用配置管理的元数据信息等等。
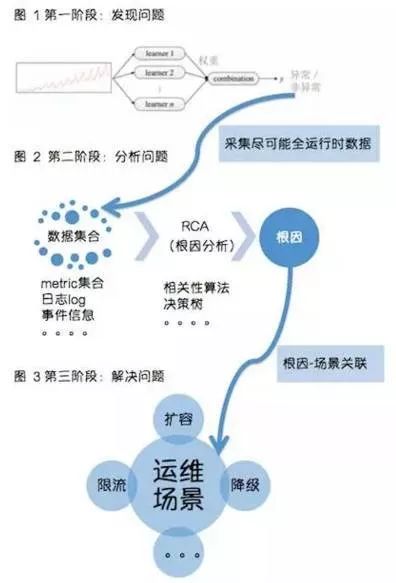
下面一张图完整说明下我对 AIOps 体系的理解:
建议
1、AIOps 的发展一定是一个长期演进的过程,AI 是 Ops 的有力补充,进一步降低运维的工作强度和压力,但是 AIOps 一定建设在高度自动化和完善的运维体系之上的,是一个演进的过程,不会是一个跳跃性的过程,产生一个完全颠覆性的 AIOps 模式,将现有的 Ops 体系替代掉。
2、从公司的角度,先集中精力建设好运维自动化体系,效率的问题解决了,再考虑更高层次的建设,就好比先解决温饱问题,再追求小资生活,这一点前两天毕玄大师的文章也表达了这个观点,我是灰常认同的。当然如果人力、精力有富余,做一些前期的预研和投入是没问题的,但不要本末倒置。至于大厂,人家早就投入 N 多年开始研究了,其中百度做的绝对是标杆。
3、从个人角度,机器学习和 AI 的知识和技术还是要花一些个人精力去学习的,凡是会让我们的生活变得更美好的技术必然会有极强的生命力,也必然代表着未来技术发展趋势,AI 就是其中之一。

以上是关于一位运维眼中的AIOps的主要内容,如果未能解决你的问题,请参考以下文章