AIOps 平台的误解,挑战及建议
Posted IT运营公社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AIOps 平台的误解,挑战及建议相关的知识,希望对你有一定的参考价值。
本文是根据个人理解,尝试从现实的角度,去谈AIOps 在落地过程中容易产生的误解,挑战以及一些建议。

让我们回到2013年,著名的 Buzz word (时髦用语) 制造商 Gartner 在一份报告中提及了ITOA,当时的定义是,IT运营分析(IT Operations Analytics), 通过技术与服务手段,采集、存储、展现海量的IT运维数据,并进行有效的推理与归纳得出分析结论。
而随着时间推移,在2016年,Gartner 将ITOA 概念升级为了 AIOps,原本的含义基于算法的IT运维(Algorithmic IT Operations),即,平台利用大数据,现代的机器学习技术和其他高级分析技术,通过主动,个性化和动态的洞察力直接或间接地,持续地增强IT操作(监控,自动化和服务台)功能。 AIOps平台可以同时使用多个数据源,多种数据收集方法,实时分析技术,深层分析技术以及展示技术。
随着AI在多个领域越来越火爆,Gartner终于按捺不住了,在它的2017年年中一份报告中,顺应民意将AIOps的含义定义为了,Artificial Intelligence for IT Operations, 也就是现在大家都在说的智能运维。
在短短的不到1年时间中,伴随着AI的热炒,以及在各个领域的落地,运维界的同仁基本上把AIOps 看成是未来解决运维问题的必然方向。
个人认为,在企业内部构建AIOps,通过融合IT数据,真正打破数据烟囱,对监控,自动化,服务台进行支持,使得IT能够更好的支撑业务,利用大数据技术以及机器学习技术,回答以前很多单从业务口径,或者单从IT口径无法回答的问题。如,联通,电信,移动,电信的用户,哪种用户转化率较高。AIOps以创造商业价值为导向,对IT 运营以及业务运营产生持续洞察,为DevOps 提供持续反馈,加快企业在竞争日趋激烈市场环境中,数字化转型的步伐。
因此,Gartner 预测到2022年,大型企业中的的40%将会部署AIOps平台。
具体关于AIOps的概念,价值,Gartner 很多都已经说的很清楚,不是本文的重点,本文是根据我的理解,尝试从现实的角度,去谈AIOps 在落地过程中容易产生的误解,挑战以及一些建议。
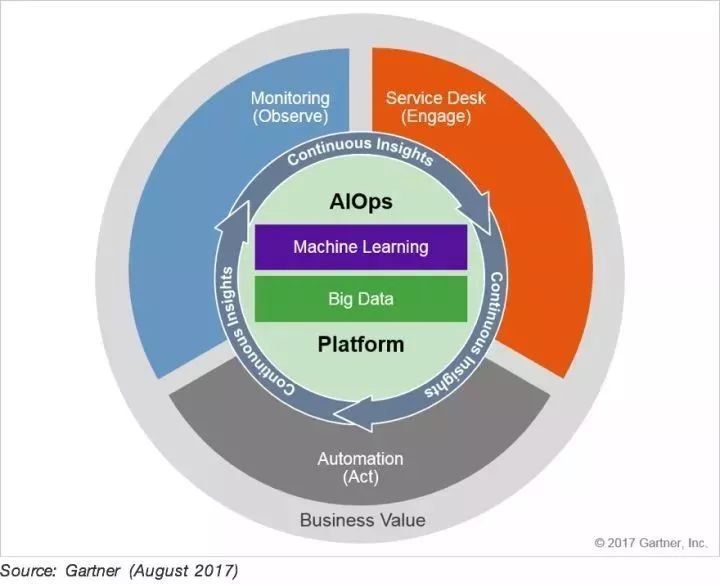
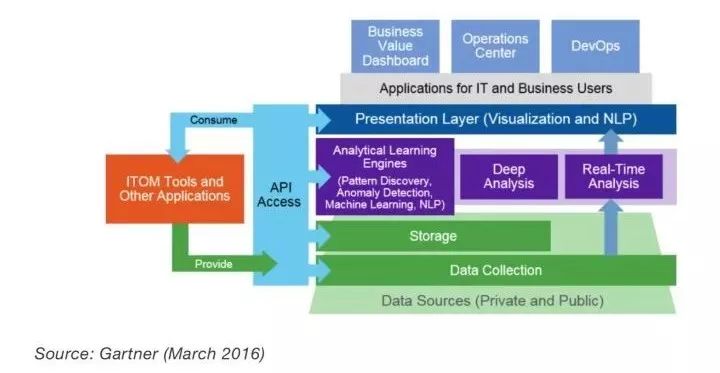
个人认为,AIOps,本质上是ITOA 的升级版,让我们来看一下 Garnter 在2015年对ITOA 的所应该有的能力定义。
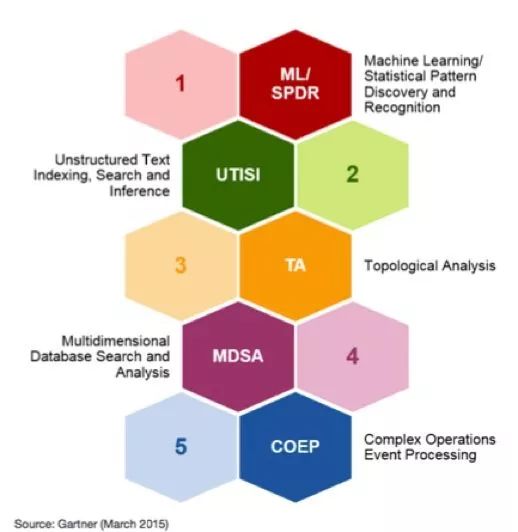
ML/SPDR: 机器学习/统计模式发现与识别
UTISI: 非结构化文本索引,搜索以及推断
Topological Analysis: 拓扑分析
Multi-dimensional Database Search and Analysis:多维数据库搜索与分析
Complex Operations Event Processing: 复杂运维事件处理
然后, 我们对比一下,Gartner 对AIOps 的能力定义:
Historical data management 历史数据管理
Streaming data management 流数据管理
Log data ingestion 日志数据整合
Wire data ingestion 网络数据整合
Metric data ingestion 指标数据整合
Document text ingestion 文本数据整合
Automated pattern discovery and prediction 自动化模式发现和预测
Anomaly detection 异常检测
Root cause determination 根因分析
On-premises delivery 提供私有化部署
Software as a service 提供SaaS服务
除去最后两个的交付方式,对比下来,我认为AIOps 比起原来的ITOA 有以下的进化:
强调历史数据的管理:
允许采集,索引和持续存储日志数据,网络数据,指标以及文档数据,数据大部分是非结构化或者半结构化的,而且数据量累积速度很快,格式多样,非常符合大数据的特征。总所周知,在新一轮以CNN , RNN 算法为代表的算法中,都需要大量有标准的数据来进行训练,因此, 对历史数据的管理,成了智能运维的第一重点。
强调实时的流数据管理:
以Kafka Streams,Flink,Storm,Spark Streaming 为代表的流计算处理技术,已经成为了各大数据平台的必备组件,而面对IT 数据中海量的实时流式数据,某些场景里头,在数据进行持久化前,进行实时分析,查询,集合,处理,降低数据库(SQL or Nosql)的负载,成为了非常合理且常规的选择,因此AIOps平台中,含有数据流,非常合理。
强调多种数据源的整合:
我认为,这个是AIOps平台最大的价值点,因为Gartner第一次将多种数据源整合的能力,带入了ITOM 管理的领域,我们搞运维监控那么多年,终于第一次可以以大数据的视角,数据驱动的视角,去思考运维监控这个传统的行当。
Gartner 这里提及到了四种数据,Log Data, Wire Data, Metirc data,Document text。 这样的分类,我是个人持有保留意见,感觉很奇怪,特别是 Document text 的那块,需要用到NLP,主要是用于打通ITSM 产品,分析ITSM 工单。我对这个场景存在必要性,以及实现的ROI 表示怀疑。具体原因我可能稍后会写一篇文章,进行更详细的解释。
我认为,如果从宏观的类型来划分,应该这样划分:
机器数据(Machine Data)
是IT系统自己产生的数据,包括客户端、服务器、网络设备、安全设备、应用程序、传感器产生的日志,及 SNMP、WMI,监控脚本等时间序列事件数据(含CPU 内存变化的程度),这些数据都带有时间戳。这里要强调, Machine Data 不等于Log Data ,因为指标数据包含。在通常的业界实践中,这些数据通常通过运行在主机上的一个Agent程序,如LogStash, File beat,Zabbix agent 等获得。
网络数据(Wire Data)
系统之间2~7层网络通信协议的数据,可通过网络端口镜像流量,进行深度包检测 DPI(Deep Packet Inspection)、包头取样 Netflow 等技术分析。一个10Gbps端口一天产生的数据可达100TB,包含的信息非常多,但一些性能、安全、业务分析的数据未必通过网络传输,一些事件的发生也未被触发网络通信,从而无法获得。
代理数据(Agent Data)
是在 .NET、php、Java 字节码里插入代理程序,从字节码里统计函数调用、堆栈使用等信息,从而进行代码级别的监控。
探针数据(Probe Data)
也就是所谓的拨测,是模拟用户请求,对系统进行检测获得的数据,如 ICMP ping、HTTP GET等,能够从不同地点模拟客户端发起,进行包括网络和服务器的端到端全路径检测,及时发现问题。
因为IT 监控技术发展实在是太庞杂,以上的划分不一定对,但是应该没有显著的遗漏。
但如果从微观技术的角度来看,不考虑数据的来源,只考虑数据本身的属性特点,我们可以这样划分:
指标数据( Metrics Data )
描述具体某个对象某个时间点这个就不用多说了, CPU 百分比等等,指标数据等等。
日志数据 ( Logging Data )
描述某个对象的是离散的事情,例如有个应用出错,抛出了NullPointerExcepction,个人认为Logging Data 大约等同于 Event Data,所以告警信息在我认为,也是一种Logging Data。
调用链数据( Tracing Data ):
Tracing Data这词貌似现在还没有一个权威的翻译范式,有人翻译成跟踪数据,有人翻译成调用数据,我尽量用Tracing 这个词。 Tracing的特点就是,它在单次请求的范围内,处理信息。 任何的数据、元数据信息都被绑定到系统中的单个事务上。 例如:一次调用远程服务的RPC执行过程;一次实际的SQL查询语句;一次HTTP请求的业务性ID。 通过对Tracing 信息进行还原,我们可以得到调用链 Call Chain 调用链,或者是 Call Tree 调用数。

官方OpenTracing 中的Call Tree例子
在实践的过程中,很多的日志,都会有流水号,Trace ID, span ID, ChildOf, FollowsFrom 等相关的信息,如果通过技术手段,将其串联在一起,也可以将这些日志视为Tracing 。
Tracing信息越来越被重视,因为在一个分布式环境中,进行故障定位,Tracing Data 是必不可少的。
由于Tracing 相对于Logging 以及 Metircs 相对比较复杂一点,想深入了解的话,可以参考 :《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》 (http://bigbully.github.io/Dapper-translation/)。Opentracing 的技术规范文档: https://github.com/opentracing/specification 。
如果我们将以上数据类型做成一个矩阵看看,我们可以得到这样一个表格,比较好的说清楚了相关关系。
回到Gartner 的AIOps 能力定义, 居然没有把 Tracing Data 纳入到数据整合的范围之中,个人认为不太合理,因为要去做根因分析,如果不知道服务和指标之间的关联关系,其实是比较难做到故障的根本定位的。
算法部分
其实可以看到,Gartner 在ITOA 定义的算法部分,如模式发现,机器学习等技术定义,都被比较顺滑的过渡到AIOPS 中来,一个方面可以看出Gartner 在定义ITOA 的时候有足够的前瞻性,另外一个方面可以看到,相关的算法问题,解决及演进的速度,是相对于基础大数据架构相对要慢上不少。
小结
AIOPS 概念与 ITOA 概念相比,在大数据技术部分进行了更细,更有指导性的阐述,所以我认为,AIOps 首先是大数据,然后才是算法。
1、AIOps 等于可以减少人力资源的投入
AIOps 不等于无人值守
AIOps 不等于 NoOps
AIOps 不等于可以减少人专家的参与
AIOps 可以降低人力成本
AIOps 在现阶段不等于可以省钱
AI 的确是一个非常性感的词汇,大家认为只要实现了智能化,就能够轻轻松松,不需要人的干预,这当然是一个非常理想的状况,但是,在短时间内,这个不能实现。这个的实现难度,个人认为,与自动无人驾驶,能实现第五等级是同样的难度,也就说,可能起码需要10年左右的时间,甚至可能更长时间。
AIOps平台本质上还是一个工具,在构建后,仍然需要人的参与,而且在目前的探索发展的投入阶段,有大量的工需要去做,需要运维专家,大数据工程师,算法科学家,业务专家,暂时看不到能削减人力成本的可能性,而且相关的投入可能需要多年的时间。
在平台建立后,在持续改进的情况下,仍然需要专家或者分析师,从不同的维度,从不同的业务口径,组合合适的可视化技术,机器学习技术,大数据分析技术,制定分析场景,平台才能够为IT运维,业务分析产生持续的洞察,提供商业价值。
所以,AIOps 不能取代人,在现阶段不可能减少人力投入,但在未来可能能促进部分运维人员转型为通晓业务,掌握运维知识的数据分析师。
2、算法和智能化是AIOps最重要的事情
算法很重要,但是我个人认为,在此阶段,大部分企业不应该以算法为第一着眼点。
这个应该是比较有争议,或者,或者说大家认知不太一致的部分。以下这张图是Gartnert 在 AIOps还在叫ITOA 时候,给定义的四个阶段:
Data ingestion, indexing, storage and access
Visualization and basic statistical summary
Pattern discovery and anomaly detection
True causal path discovery
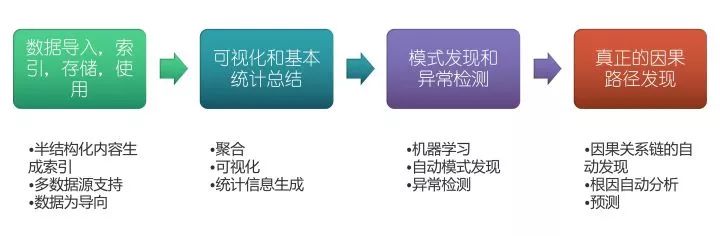
来源: Gartner Report “Organizations Must Sequentially Implement the Four Phases of ITOA to Maximize Investment ” 2015.2.18
Gartner 在报告中强调,掌握后面阶段的前提是拥有前一阶段的能力,如果不拥有充分的前一阶段能力,将会影响ITOA 的落地效果。因此这四个阶段必须一个步一脚印,第三以及第四部时,才显著地引入了机器算法,或者AI的必要。
大家都知道,所谓的机器学习算法,统计算法,深度学习算法这些AI 的分类,其实是高度依赖于数据的。没有多种数据源,数据的采集,数据存储,数据统计,数据可视化,一切都只是空中楼梯。
因此,AIOps的平台的建设首先应该是着眼点应该是大数据,然后才是算法,从而实现持续洞察和改进的目标。
3、一定要上深度学习才叫AIOps
我们可以先看看AI , Machine Learning , Deep Learning 的关系,他们的关系大概如下图。
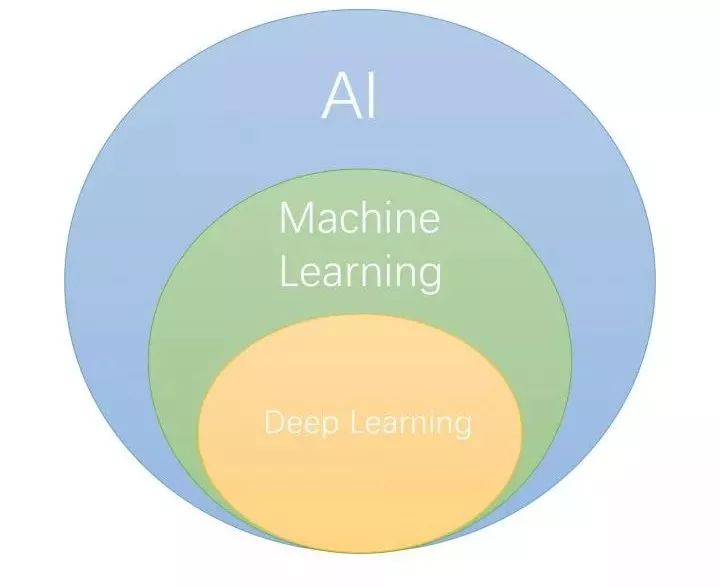
学术界有不少学者,在探索部分深度学习算法智能运维中的应用,如犹他州大学的《DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning》 中利用 Long Short-Term Memory (LSTM)来实现日志模式的发现,从而实现异常检测。但是,其实智能运维所需要的大部分算法,决策树学习(decision tree learning)、聚类(clustering)、SVM(Support Vector Machine)和贝叶斯网络(Bayesian networks)等等算法,均是属于传统的机器学习范畴的,因此,我们不应该将深度学习与AIOps 挂上必然的联系。
甚至于,我们不用拘泥于概念,从解决问题的角度出发,在特定的场景,利用传统的规则集,设定一些规则,降低了运维人员的工作强度,提高了效率,也能叫智能运维。甚至在Gartner 的报告中,对AIOps 落地的第一步,是统计分析,可视化,而不是任何的机器学习算法。
4、它适合现阶段所有有规模的用户
这个比较好理解,就目前来看,AIOps 只适合大型的客户,原因如下:
中小型的客户缺乏多种数据源
中小型客户业务需求没有那么复杂
很多算法,其实是为了大规模运维的时候才用的上的,在规模小的时候,难以产生效果
5、运维自动化是智能运维的前提
我看到过不少的文章,将运维分成了四个阶段,将自动化运维放在智能运维的前一个阶段,把智能,又或者在智能运维这个体系里头,硬是塞了很多自动化运维,批量操作,批量规划的功能在里头,我觉得都是不对的。自动化运维更像是手,智能运维更像是眼镜及大脑,有了更全面数据,更充满的分析后,大脑能更好的指挥手进行操作。

因此,企业应该将自动化运维和智能化运维看成了两个有关联的体系,但是不应该混一谈,造成更多的误解。
挑战1:超越当前技术水平的期望
以下是其中一例,当用户期望超越当前技术水平的一个典型的例子,车毁人亡。

美国加州湾区高速上的一起致命车祸,。一辆价值$79,500的Tesla Model X,在行驶至山景城段101和85高速交界时,突然撞上隔离带,随后爆炸起火。
对此,遇难华裔司机的遗孀Sevonne Huang(下文简称Sevonne)首次公开发声透露,丈夫生前曾抱怨过,特斯拉的自动导航仪,好几次让车子开向冲上防撞栏。Sevonne说,将起诉特斯拉。
自动驾驶的安全性问题,再次把特斯拉推到风口浪尖上。然而事后,虽然特斯拉发声明称,抱歉发生这样的悲剧,但同时也将责任指向了死者,“车辆再三发出警告,提醒司机操控车子,但事发前,司机并没有把手放在方向盘上。自动驾驶仪并不能避免任何事故。”
司机对于特斯拉的AutoPilot 过度相信,最终导致了悲剧了发生。
虽然目前的智能运维,所造成的结果可能不会那么严重,但是按照Gartner 技术成熟度曲线来看,AIOps 还处于非常初期的阶段(左下角),超越现阶段的期望,是AIOps最大的风险。
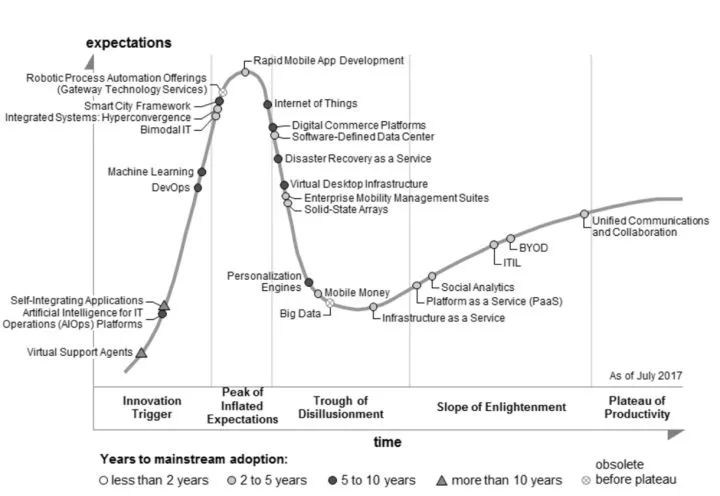
中国的企业用户往往有大而全的建设方案,如何从企业的实际情况出发,制定节奏合适的规划,我认为是一个很大的挑战。
挑战2:算法应用场景分散,成熟度不一致,通用性差,产品化,工程化困难,大部分场景距离实际应用有一定的距离
从目前来看,大家期望利用算法解决的场景包括:
单指标异常检测
多指标异常检测
日志模式异常检测(参照 Log Compare)
故障根因分析
容量预估
告警智能压缩 (基于根因,基于事件日志模式)
故障预测(较为常用的场景为硬盘的故障定位)
基于知识图谱(运维经验)故障定位
以上的每个智能场景,每个场景所需要用到的算法都不一样,而且成熟度也不一样。
以最为简单,但应用最为广泛,成熟度最高的单指标异常检测来举例,从学术的角度来看,如果你到Google里头去搜索,你会发现有大约60000多条的记录,时间跨度从上世纪90年代到几天前的都会有。
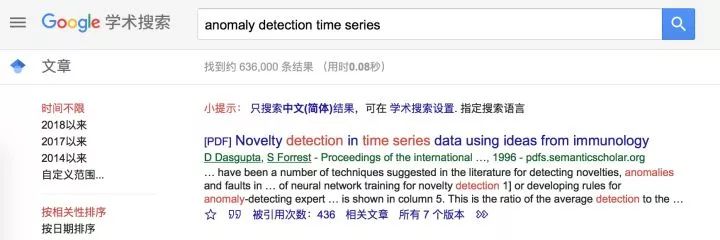
这已经是30年来,集合了那么多顶尖的智慧,所能达到的产品化程度最高,通用性最强的场景了。其他的场景,成熟度,或者通用性肯定是不如本场景。
例如故障预测,目前比较好的案例是预测硬盘故障,前提是你拥有大量同样型号,相同批次的硬盘,其中某一些硬盘出故障了,从S.M.A.R.T 信息中,你才能够获得训练集,然后利用模型去预测同一个批次的故障。这种前置条件,通常只会在特定的用户,例如腾讯,百度的数据中心,一次性购置上千块的,才能出现1到15块的故障硬盘 (据统计,硬盘的故障率在0.1%~1.5% 左右),而且就算有用户根据硬盘的情况,训练好的模型因为每个用户的机房,电压,温度都不一样,很可能没有办法进行复现,因此,此场景通用性极差。
如果要将用于预测硬盘故障的算法,用到某一个IT业务系统之上故障上,基本上也是不可能的,因为一个系统,相应的参数,变量,可能影响系统平稳运行因子太多,已经是没有办法套用到预测硬盘故障的算法里头来了。
还有,部分的算法,在实验室中的效果非常好,准确率和召回率都很高,但是,消耗资源巨大,实时性差,没有办法投入真正的生产使用的可能性。
因此,在算法上,我们应该先去落地成熟,ROI显著的场景。
挑战3:现有运维监控体系没有完善
在无人驾驶技术领域,最核心的一个组件是LiDar(激光雷达),一种运用雷达原理,采用光和激光作为主要传感器的汽车视觉系统,LiDAR传感器赋予了自动驾驶汽车能够看到周边环境的“双眼”。
世界上,几乎所有的汽车厂商( Tesla 除外,Tesla 用的是通过摄像头而实现视觉识别技术,所以我个人高度怀疑特斯拉的事故与此有关)在研发无人驾驶技术的时候,都会给车辆安装上激光雷达。
而类比到运维的场景,如果眼睛不够,数据不足,事情看不清楚,其实是很难做到明确的决策的,具体表现如下:
缺乏足够的数据源
有的客户,没有日志管理系统,也没有任何业务监控的手段,只有CPU 内存,硬盘等基础监控,这个时候,其实我个人上是不建议在现阶段做AIOps的
监控指标深度,专业程度不够
这个问题很多时候反应的数据库监控上,由于数据库专业化程度较高,因此对数据库的很多关键的指标未能识别,导致了关键信息的遗漏,可能会大大影响AIOps 的落地效果。
配置管理不完善
CMDB 缺乏维护, 无法获取系统间关系的描述,拓扑依赖,相关运维监控数据元数据缺乏管理,都会降低落地效果,特别是在故障根因定位中,缺乏关系描述所形成的有向无环图,就很难利用传播关系算法去帮助定位根因。当然,这个可以通过由APM ,或者NPM 工具,所生成的应用拓扑去部分弥补。
挑战4:大数据基础复杂,性能及多样性要求高,元数据管理
整个AIOps 平台最核心数据平台的部分,是要满足以下的需求:
高吞吐量,能实时处理海量,不同类型的数据(Metrics , Logging , Tracing);
具备强大的流式计算能力;
数据在插入后,能被准实时的检索,聚合;
数据变化多样,会不停地新增动态列,数据存储模型随时会改变;
超高的分析聚合计算性能,需要提供多维列式数据库的分析能力;
提供强大的实时搜索分析能力,可以通过关键字对事件信息进行检索;
具备一种或多种的数据查询DSL,便于实现不同的分析场景;
具备历史数据和近线数据的分别处理的能力;
数据存储能对接到多种的ML框架中,作为数据源,训练模型;
数据要能实现上卷预聚合,在进行长时间范围聚合的时候,如月报等逻辑时,可以节约计算时间;
大的查询进入到平台,平台要有自我保护机制,不会造成故障;
良好的元数据管理的能力,包括如果从那么多数据中,按照模型还原相应的指标,以及指标间的关联关系;
能够与在线的算法模块进行集成;
以上的描述,都是AIOps 的数据能力要求,往往需要多个大数据处理,存储组件,才能满足这种苛刻的要求,而且还需要无缝的整合起来,相应的工程技术难度非常大。
挑战5:人才匮乏
目前在国内,无论是算法人才,还是大数据人才,都是比较匮乏的及昂贵的,在人才招募,项目预算制定的时候,要充分考虑相关因素。
从人才的意愿来看,大部分的算法工程师及大数据工程师,更愿意去参与一些离变现比较容易的场景,如推荐系统,视觉识别系统等,如何吸引更多的人才,特别是算法科学家等,让他们感兴趣,加入到AIOps的场景中来,也同时获得较好的经济回报,是整个业界需要考虑的地方。
企业结合自身的情况,合理控制期望,分阶段进行演进,查漏补缺
建立一个完整的运维数据大数据体系是项目运维的关键,也是为智能化打下良好的基础
以将整合指标数据、日志数据作为切入点,落地逐步整合更多的数据源,产生更大的收益
智能化部分的落地场景优先聚焦在监控的异常检测,以及日志的智能聚类
立足运维,面向业务,将Operation的含义演绎为运营,为业务提供商业价值
AIOps 的确是一个非常革命性的概念框架,它从大数据和AI 的能力视角,去颠覆或者完善现在的 ITOM 运维体系,给学术界,工业界,最终用户,指明了一个明确,可持续高速发展5-10年的发展方向。可以预计,在未来5-10年内,大量关于AIOps 的新思想,新理论,新技术,将会像寒武纪生命大爆炸时,不断的涌现,创新源源不断,作为业界工作者,作为企业,作为厂商,如何在这次的周期中抓住属于自己的机会,这是一个很值得思考的命题。
AIOps 让运维部门一下成了公司层面拥有数据最多的部门,运维人如何自身进化,从运维到运营,对大部分运维人来说,都是一个巨大的机会及挑战。
虽然AIOps的确给我们带来很多的想象空间,但是我们还是要以实际落地,实际帮助企业产生效率为导向,要避免跳入AI 过热的炒作风,一步一脚印,直面挑战,持续演进,不断吸收世界先进的经验及思想,从而迎接未来这10年的黄金时代。
*声明:推送内容与图片均源自公开互联网,部分内容会有所改动,侵删。

以上是关于AIOps 平台的误解,挑战及建议的主要内容,如果未能解决你的问题,请参考以下文章
“2020国际AIOps挑战赛线上启动会”定于3月21日举行