分享 | 百度智能运维实践(AIOps)
Posted IT运营公社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分享 | 百度智能运维实践(AIOps)相关的知识,希望对你有一定的参考价值。
本文整理了作者在 DevOpsDays 2017 北京站关于 AIOps 的演讲,很多人会有疑问,甚至可能是第一次听说 AIOps 这个词,那么 AIOps 是什么?它和 DevOps 的不同之处?它是如何产生发展的?它又将何去何从?带着这些疑问且听作者慢慢分解。

作者简介

前言
今天跟大家分享的内容分为四个部分,第一部分跟大家讲一下百度对于运维包括DevOps未来的一些考虑,我们下一幕是 AIOps;第二部分跟大家介绍一下百度 AIOps 整个的框架;第三部分会讲我们百度在最近这几年,我们对 AIOps 具体的实践,我们做了什么,里面产生了什么样的效果;最后一部分是在新的运维时代下,很多人跟我的一些讨论,这里拿出来跟大家分享一下。
1. AIOps
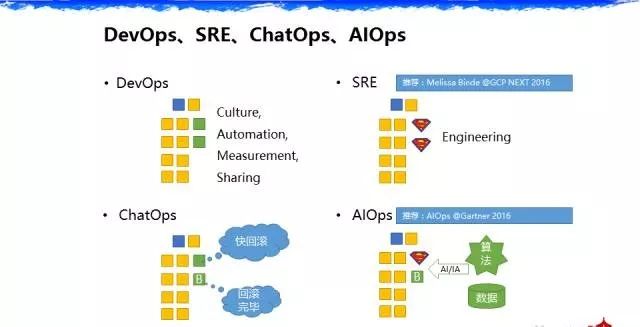
DevOps
有四个词大家可能都听说过,很多人在问我它的概念是什么。比如第一个词,DevOps,刚才 DevOps之父也解释了,DevOps 可能是我们最终文化、自动化、分享、可测量。整个的思路,黄色这边代表研发和测试,绿色代表运维,把大家聚在一起,很快的去迭代去做事情。早期 DevOps这边大家会谈得比较多的是交付,实际上在整个Ops过程当中不仅仅是交付,还有容量管理、故障管理,这块大家谈得比较少。谁谈得比较多呢? SRE。
SRE
这两年特别是去年,SRE中文版的书,SRE网站可用性工程。我改了一下,这里强调Ops具备非常强的工程能力,是一个超人。SRE还有另一种翻译,Facebook 总监在前年说可以翻译成超人拯救地球(Superman Rescure Earth),就是运维人员的自身能力是要提升的。特别推荐谷歌的存储系统的总监,之前也跟他聊过,在去年GCP大会上讲的一个主题,讲得非常好。里面讲了很多SRE书中没有的问题。举两个例子,他在讲到SRE和 DevOps 的问题的时候,讲到SRE更多是在谷歌具体的实践,具体的做事方法,第二个,里面也提到一些问题,我们的运维人员跟研发人员在谷歌一定是分属在两个VP的,如果不在两个VP下,这种一定程度上的制衡可能会达不到效果。比如说研发人员说我明天就要做一个上线,运维人员可能就听从研发人员上线,即使存在很多问题。他讲到,运维人员不是一只猴子。这里强调的是在一定程度上运维人员是需要去控制可用性的。
ChatOps&AIOps
还有第三个词:ChatOps,这个主要源于 github。我这边的理解,ChatOps 是对 DevOps 的一个变化,之前 DevOps 是人在一个组织在进行协作,ChatOps 的问题就来了,有一个机器,有一个会说话的角色出现了,在 DevOps 里多了一个角色。这个角色怎么去协作,这是一个问题。百度在做什么,百度的总结我们把它称之为 AIOps(Algorithmic IT operations platforms),其实主要源于去年在 Gartner 的报告中他提出了一个词—-AIOps:A是算法,I是IT系统,O是 operation,P是 platform。百度在这里面的思考是什么,我们在整个研发和运维一体化里加了四个要素,第一个要素是我们的数据,我们强调数据的重要性。刚刚 DevOps 之父也讲了我们在 DevOps 上的高层次是要为公司的 account 还有市场占有率产生价值,所以数据是这个价值产生最重要的环节。
第二个要素是算法,随着人工智能和增强智能的出现,我们发现很多人工智能的技术可以运用到运维工作中使做得更好。这个思路也是百度这十年的运维过程当中的一个变化。
2. 百度基础运维平台
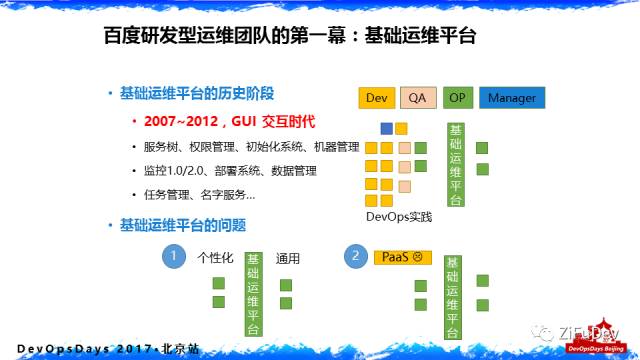
定位
百度运维的第一幕是什么哪,就是我们的基础运维平台。这个大概在2007年整个百度运维部成立时我们就明确的一个目标,”DevOps” 这个词还没有出现的时候,我们就在想研发运维是一体化的。那个时候百度的搜索引擎的RD(研发)和OP(运维)就在一个团队,汇报关系上可能不是一个团队,但是我们的协作模式是一直以来在一个团队里面做。当时的状态,比如图里面的RD、OP、QA(Qualtiy Assurance)在一起的时候,我们每一个RD要进行改造,高级的RD工程师就会说这个总体设计没有运维人员去审核是不可以做详细设计的,所以在整个 Service design 环境,Ops 就参与进去了。
GUI 交互时代
但是有一个问题,在早期五年的实践中,我们把运维人员分成两部分—-平台运维研发和应用运维研发,这个分法带来的问题是中间有一层隔膜。我们的运维系统当时在2007年开始做到2012年,这五年里我们都是基于 GUI 界面,这个带来一个什么问题哪,有两个问题。
第一个问题:绿色框的问题,做研发运维平台的同学追求通用,但是做应用运维的同学追求个性化,在线系统和离线系统,搜索系统和广告系统,都是不一样的。这里面很麻烦,就会发现一堆的 features 给到研发运维平台的同学的时候,他们做不过来。
第二个问题:在2010年左右整个互联网兴起了 PaaS 系统,百度也做起了自己的在线和离线的 PaaS 系统,这个 PaaS 系统的问题是它跟 GUI 没法交互,当时有两个选择,第一: 把五年做过的东西重做一遍,第二:无解,PaaS 系统无法去跟 GUI 交互。
API 交互时代

那我们就应该学习亚马逊。所以在2012年左右我们重点做了什么哪,我们把所有的运维平台 Service 化和 API 化。我们觉得未来的发展不是说让OP去点鼠标,而是让系统、让OP去编程,去写代码,让它能够 work 起来。
在这个阶段我们进行了组织的调整,这个组织里面大家看到一些变化。
第一个变化,基础运维平台变成开放运维平台;第二个变化,我们引入了PaaS系统;第三个变化,当年百度运维部的TC,就是2012年他就给我们带来了谷歌 SRE 先进的理念。当时我们在2012年决定我们整个运维部的发展是走研发型的道路,我们需要培养的运维工程师各个都是研发能力非常强而且是设计架构能力非常强;第四个变化,在局部我们尝试了 ChatOps 的产品线去辅助它。
开发运维平台的问题
垂直场景重复造轮子
大家觉得这个东西完美吗,一直到2014年,整个组织结构和系统结构大概是这么一个模型。还是有问题的,第一个问题,应用运维研发这边,他去用这些API,对照自己的应用场景解决问题的时候,比如我要做容量管理,我发现各个产品线做了重复的事情。有一些模型基本上是大同小异的,而且大家看不见互相的工作,因为我们几百号人,导致的情况是我们听到项目重复会比较多。
分散的数据和运维知识
第二个问题,当时的数据层是没有统一的。遇到一个问题,在这个平台上大家用自己的API获取到的数据都存在自己的本地,导致的问题是,一个同学离职了,接他的同学不知道怎么办。一个同学我们轮岗到别的团队去做 DevOps 的实践,没有文档,这块是有缺失的。
不够智能
第三个问题,早期我们在做 DevOps 实践过程当中,侧重的是执行上的自动化,我们的自动化更多考虑执行,叫做运算智能,部署、扩容全是自动化做的。但是我们在感知和认知上,整个百度的智能性是比较低的。举个例子,我们会有同学盯着监控系统看流量,有人盯着去看上线过程,所以这个问题是感知。其实有的时候人看五秒钟就知道是不是异常。我们后面的讨论是在运维工作中有两类场景是可以被人工智能取代的,第一类场景是高频的、非常简单的,人花五秒钟就能解决的事情。第二种就像 AlphaGo 一样,下围棋是非常难的事情,人可能搞不定,但是机器可以搞定。举个例子,比如定位,当有故障发生的时候,有可能有很多事件发生,到底哪个是根因,它的寻找是非常痛苦的,机器就可以做好。对这两类场景,一种是非常简单快速的场景,一种是非常难的场景,其实往往用人工智能的方法可以做得更好。

去年我在做微软 DevOps 实践的表格,在第二个阶段里,其实微软在做 DevOps 实践的时候很有意思,我觉得他们的结果跟百度一模一样。百度DevOps 的时候在标红的两个框都做得很好,我们的发布和监控都做得很好,但是我们的容量管理,我们的故障管理,我们的服务设计,还有最后服务管理,包括在 Service Design一颗星都没有,大家在谈DevOps实践的时候都会倾向于谈红色的地方,我们的部署、交付。百度从2014年开始,我们就更多关注 DevOps 的其他方面,我也希望大家在自己的工作中先把部署交付做好之后,其他的方面是 DevOps 接下来会花很多精力去解决的问题。
3.百度 AIOps

百度运维的下一步就是 AIOps,我们不光是要解决部署和变更的问题,还要解决故障的问题,容量的问题,还有服务咨询。不知道在座各位有没有遇到这样的场景:你每天上班之后会有一堆人问你,无论你用钉钉也好,QQ也好,还是其他的也好,Ops 一天很大的精力耗费在交流上。
三个核心
我们这边提出了三个核心,第一个核心要有知识库,第二个是一套开发框架,不仅仅是API,避免他们重复的场景,第三个是需要给大家介绍的是提供算法的 SaaS 服务,比如:异常检测。
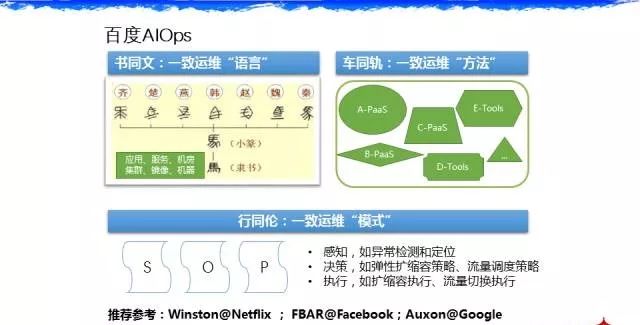
这个框架跟大家讲一下,有三个理念。第一个理念,比如知识库这边需要统一一个运维语言,我们在做知识库项目的时候发现一个问题,大家的运维语言不一样。举个例子,比如一个C的 Service 程序,有的人叫它模块,有的人叫它服务,有的人叫它微服务,有的人叫它程序,到底叫什么,在沟通中,语言是非常重要的,这是我们第一个工作的定义,大家在说话的时候多用的是同一个词汇。
第二个很重要的理念是———统一方法。在前五年百度的实践中,开发了一堆的工具,导致的问题是大家无论设计服务,还是运维对象可能都有差别,最后我们在公司级别做一个抽象,我们根据前面统一的运维对象再进行一次抽象封装。以后一个同学从A部门轮岗到B部门去做他的事情的时候,你会发现他的运维对象和运维方向是一样的,他的每一个运维对象重启、暂停、发布等,在他看来是一样的。之前发现不同产品线做的时候是五花八门,每个人做成了自己的 DevOps,别的团队的人要融入这个团队去的时候,他的学习成本是比较高的。
第三个是SOP——标准的运维手册。为什么不把它加到代码中。这里有几个推荐系统大家可以看一下,第一个是 Netflix 的 Winston,还有 Facebook 的 FBAR,还有谷歌的 Auxon,Auxon 系统是 SRE 书里面能够体现谷歌50%开发的非常重要的系统。
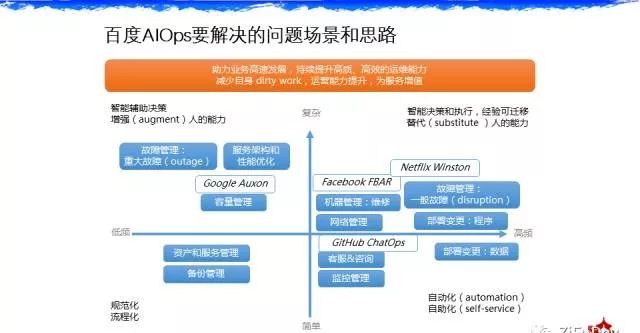
要解决的问题场景和思路
百度在做这件事情的时候,对于我们要解决问题,我们在2015年底做了一个全面的统计,我们收集了所有部门里面几百号人的工作,统计出来有50%的工作都是基础运维。百度这边大概运维工程师有50%的时间花在服务设计和开发上,有50%的时间花在基础运维上。谷歌的这个数字是33%,他们做的一个调查大概是33%时间花在在基础运维上。我们做完这个调查后发现,按照频率和难度来说,可以分成这样的象限。对于高频的很难的事情我们希望用AI的方法把它替代掉,对于低频的非常难的事情,我们认为还是用IA增强智能的方法来辅助。大家看看平时的工作中是不是都是这些事情,占比大概分布是不是这样,可能我觉得整个互联网应该都是这样一个比例。
百度AIOps框架
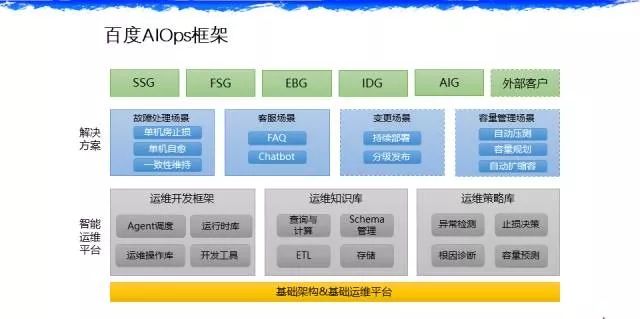
运维策略库
架构层,我们大概有这么一个架构,在底层分为三个方面。首先是算法平台,大概目前有四大算法,第一个是比较重要的——异常检测,其实有很多公司就是派人在那盯着屏幕看,而且我们最后发现机器比人更靠谱。第二个,当出现大故障的时候自动流量调度和止损。第三个是非常难的——根因诊断。第四个是——容量预测。
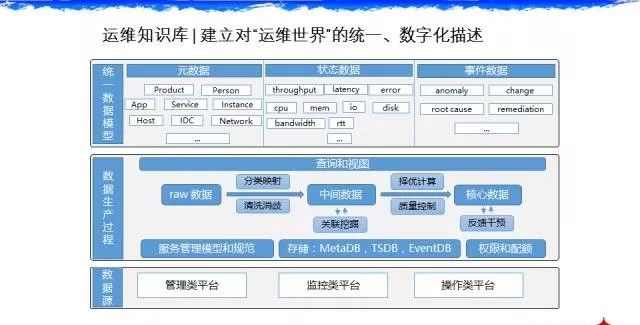
运维知识库和开发框架
然后是运维知识库和运维开发框架。大家看这一页 PPT 上面是场景,面向公司内部客户和公有云的客户都可以去支持。再说细点,在这里面比较重要的是大数据的加工技术,在做知识库的时候,我们复用百度搜索引擎架构的能力,我们把运维知识库也这样去建设。这里面会有一些消歧,原始数据的时候,可能它们代表同一个意思,最后需要去消歧。第一部分类似于 ITIL 的 CMBD,第二部分是状态数据,第三部分是事件的数据。这三部分对于运维的未来支持业务包括运营是非常有价值的。在搭建这套系统的时候,整个运维部自然而然就建成了一套大数据架构,就是我们的流式计算,我们的分布式存储,还有计算系统。目前这套架构的能力是支持我们每天大概40多T的监控数据的存储和处理。这就是所谓的 AIOps—— 强调数据和算法,你只有基于大量的数据才可以为公司去做运营决策和可用性的保障。
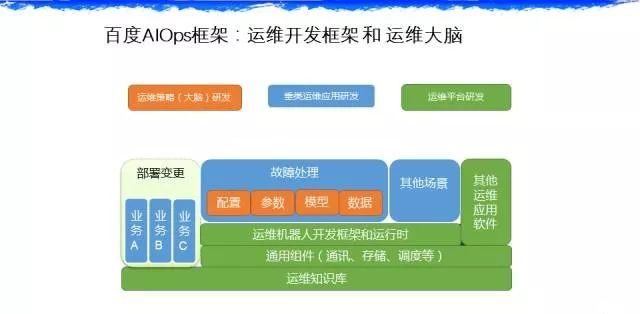
百度AIOps实践
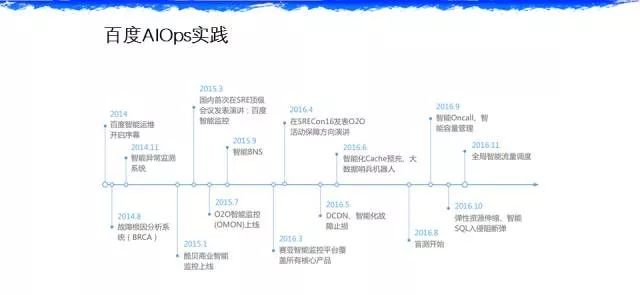
这块是算法层的细节,我们尽量让它配置化和参数化,这里不多讲,百度很多算法在过去两年国际会议和 Top 上我们都公布了,所以今天不会细讲我们在智能定位和算法上的工作,在异常检测或者定位上,可能对现在正在做这个方向的同行有一些价值,这里我重点说下。我们2014年开始智能运维,在2014年我们在异常检测这个方向上,当时遇到一个问题,大家都在质疑说机器会比人靠谱吗,我派一个人盯着那个曲线看它的异常,和你写一个机器相比,很多人不相信程序会比人靠谱。怎么解决这些疑虑,两个方法,第一,我们在检测的时候是异常检测的机器学习的方法+最低的阈值的底线保底。最后我们发现的状态是什么,我们的算法能够提前去预测故障,人可能要看到波谷。但是我们的机器学习算法可以提前去捕获到这种可能性,其实比人更快。最后我们证明在什么地方,在上线这套算法的时候,在我们的搜索系统和广告系统上线的时候,我们发现没有漏报,因为还有个保底。有误报,一开始在2014年的时候误报相对来说还是有一些,每天有三四个误报,让大家心里是不舒服的。但是到2015年下半年的时候,基本上误报可以做到一个月就几次或者是不存在,里面也是通过人工去标注,不断在这套系统用的时候,那个数据不断更新达到的效果。在2016年,我们觉得这个方向是可以做下去,然后更大踏步往前走,不光是在异常检测和定位上,我们聚焦在多个方面,比如说数据库阻断的入侵,我们用的是决策树的,还有全局的流量调度等,大概在这个领域上我们做了快三年。
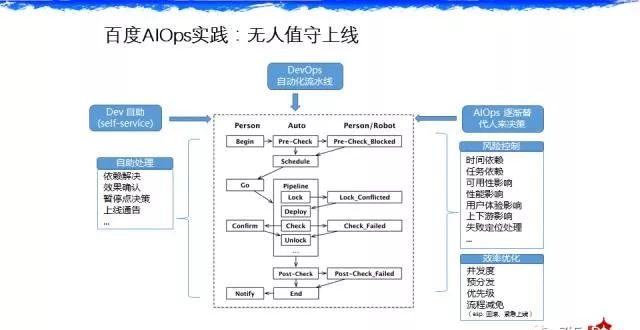
具体跟大家讲两个例子,第一个,我们的部署系统。刚才乔梁也说,百度在2012年的时候,我们的持续交付基本上做得差不多了,我们在2012年的时候做到差不多之后更多在考虑一个事情,为什么做了持续交付之后线上还是有问题,这个问题怎么反思,是在发布环节,第一个是测试环节,可能 QA 就是会漏测一些 BUG,即便是做持续集成,难免有一些 BUG 是没有测出来的。在部署环节,分级发布,我们发现有一些 case 实际上需要一些时间才能解决。分级发布的时候,等待的时间到底多久。还有的问题是早期我们在做持续交付的时候遇到的一个问题,有的产品线真的为了可用性考虑,他觉得就得晚上上线。那你去设计晚上这个时间点,另一个产品线会说这两个模块坚决不能同时上线,因为这个东西是现在一些软件系统还没有解决特别好的,你不要指望说现在任何一个互联网架构的任何一个模块无时无地都可以正常运行,可能现在就是有依赖关系。A模块在上线的时候,B模块坚决不能上线,这样一些互斥怎么解决。所以在2012年之后我们做了一个事情,抽象出来更高层次的跟服务相关的东西,还有可用性,新增到了持续交付系统中,让这套部署系统在检查上会做得更智能,就像一个人一样,在看各种日志、看各种指标,来确定有没有问题,要不要回滚。这块也是希望大家在做部署的时候多关注一些,检查环节。Netflix 做了一个系统他们自己做了一套系统,每一次部署的时候可以对这一次上线做评分,比如在测试环节发现60分,那就不要上线了。最后一个例子,我们做了一些用自然语言处理解决的地方,比如今天什么时候上线,我们用自然语言处理的方法。
4. 迎接AIOps新时代
我们百度在做事情的时候,内部有两部分人来问我,第一部分人问,我们以后是不是会失业,我说不会,我们是去开发这套系统。第二部分人问我说,我们接下来是不是很快就进入到下一步,可以做得很好很乐观,我说也不是,在到达那一天还长着呢,需要很多人持续投入。
*声明:推送内容与图片均源自公开互联网,版权属于作者所有,部分内容会有所改动,侵删。

以上是关于分享 | 百度智能运维实践(AIOps)的主要内容,如果未能解决你的问题,请参考以下文章