AIOps在携程的践行 | 活动通知
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AIOps在携程的践行 | 活动通知相关的知识,希望对你有一定的参考价值。
作者简介
徐新龙,携程技术保障中心应用管理团队高级工程师,负责多个AIOps项目的设计与研发。信号处理专业硕士毕业,对人工智能、机器学习、神经网络及数学有浓厚的兴趣,对人工智能技术结合运维场景的实践有深入研究。
随着人工智能时代的到来,携程生产环境运维进入了新的运维时代——AIOps。通过两年多时间的技术投入与实践,AIOps在效率提升、可用性保障、成本优化等运维场景取得了显著的成果。
本文选取了几种典型的运维场景对AIOps在携程的践行展开了介绍,首先让我们从概念认识下AIOps。
一、AIOps的概念
2016年3月,AlphaGo与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜,人工智能技术又重新进入大众视野,备受关注。
通常人工智能技术分为“弱人工智能”和“强人工智能”,其中弱人工智能是能够和人一样,甚至比人更好地执行特定任务的技术;强人工智除了更好的执行特定任务之外,有着人类所有的感知和理性思考(甚至比人类更多)。目前我们提到的人工智能技术都是弱人工智能。
人工智能技术从概念落地到实践需要具备三个必要条件,即算法、算力和数据。
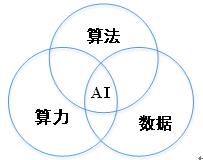
其中算法和算力,随着机器学习算法理论和工程技术体系的成熟,已经得到很好的攻克,关键点在于数据和应用场景。有过算法经验的人应该都知道,算法效果的上限取决于数据质量。
运维行业因为积累了大量生产环境数据,其中包括各种指标的监控数据、告警数据等,特别是对于携程这样体量庞大的网站,这些数据每分钟正以惊人的速度在不断增长,具备了AI技术落地得天独厚的条件。
2016年Gartner报告中提出了AIOps概念,也就是Algorithmic IT Operations—基于算法的IT运维,主要指用大数据、机器学习驱动自动化、服务台、监控场景下的能力提升。
从某种意义上讲,AIOps也可以称之为数据运维。
AIOps人员组成上由三大主体构成,即运维工程师、运维开发工程师和运维AI工程师。
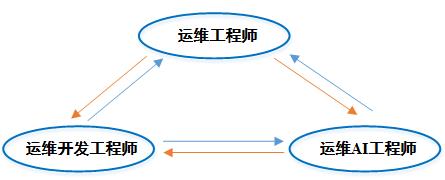
运维工程师作为最前线的人员,对生产运维场景了如指掌,提炼出相应的需求点;运维开发工程师则是协助运维工程师,将其提出的需求加以自动化实现,从而避免重复性手动劳动,解放双手;随着运维规模和场景变的越来越复杂,仅仅靠以往的经验知识已经难以应对,于是AIOps应运而生,用基于统计、学习替代传统的基于规则,而代表这种生产力的就是运维AI工程师。
二、携程AIOps几种典型应用场景介绍

目前AIOps在业界还属于应用探索阶段,其比较成熟的场景主要包括以下两个领域:
可用性保障:异常指标检测、故障智能诊断、故障预测、故障自动修复等;
成本优化:容量规划、资源利用率提升、性能优化等。
接下来介绍下携程在这两个领域下的部分典型场景,以及相关算法简介;
1、应用异常指标检测
应用的埋点信息是最能反映应用健康状况的指标,这些埋点指标被监控系统采集并设置一定的告警规则(一般为固定的阈值),一旦某个指标连续达到设定的阈值时,就会通知相应的负责人处理。传统基于固定阈值的告警技术存在以下的问题:
1)固定阈值的设定依赖人为经验,和实际情况可能存在较大的偏差;
2)一旦设置不合理,即存在大量的漏报误报;
3)无法检测异常序列的冒烟特征,例如缓慢爬升等;
4)携程应用成千上万,数量众多,为每个应用维护固定阈值,成本极高;
5)牺牲告警及时性换取有效性,出现应用告警滞后于订单告警。
下图给出某个应用的一段监控指标(已经脱敏),其中A、B两条换黄线之间存在异常,如采用固定阈值就可能造成:使用红线2作为阈值可以发现异常点,但造成了大量的误报(黄线B的有部分);使用红线1作为阈值虽然减少了误告,但无法检测出异常时序。
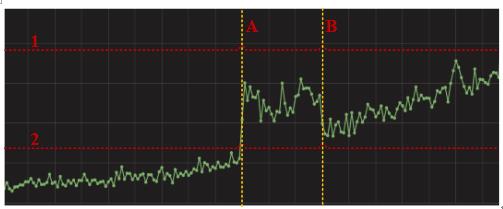
AB之间存在异常的某段时间序列
为了解决以上存在的问题,通过对时间序列建立ARMA模型,利用时序的统计特性、时频分析,再结合工业常用的3sigma准则确定动态阈值,自动识别时序中的异常点。同时根据告警时序之间的相关性、专家知识库等区分告警类型。相比传统告警规则,智能告警系统在准确率和召回率都有巨大的提升。针对应用异常指标检测这种场景,抽取一定的样本统计,在基于专家经验标注下的准确率可达到90%以上,召回率接近100%。
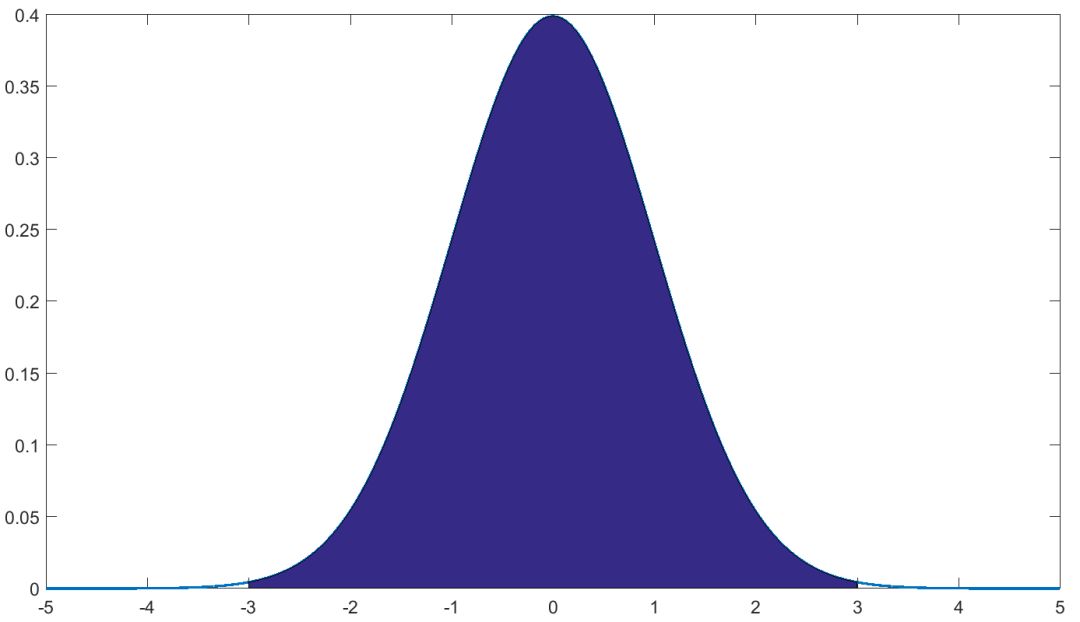
对正态分布而言,样本99.74%都分布在中心位置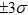 之处
之处
针对应用异常指标检测这个场景,为了更具体说明算法步骤,我们使用动态阈值告警和周期性检测来进一步阐述。
动态阈值告警:
在创建ARMA模型之后,利用频域特性设计模型参数,待模型参数调节得当后,对原始时间序列进行平滑滤波,确定时序每一时刻的统计中心,中心位置确定后,再结合3sigma准则给出时序每一时刻的上限,以此达到动态阈值的功能。
以下示例为生产某个应用一段包含异常情况的监控时间序列,黄色曲线代表了原始时序数据,绿色的曲线为ARMA平滑滤波的输出,红色曲线是在绿色曲线基础上叠加3sigma之后的动态阈值(根据实际数据的统计特性,如果满足超高斯分布,则可选择2sigma或更小;对于亚高斯分布,可选择5sigma或更大等)。借助动态阈值,异常点(离群较远的监控点)很容易被识别出来。
某段包含异常的时间序列检测,红色竖直虚线位置为检测到的异常点
周期性检测:
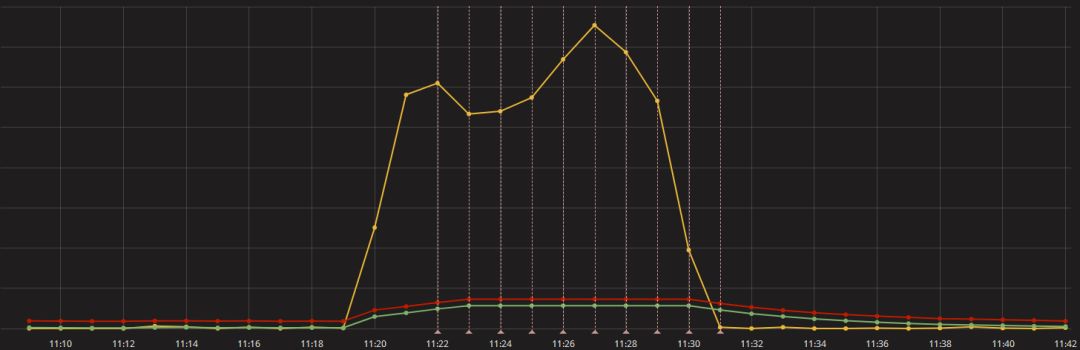
自动周期发现主要是通过对监控指标一段时间的观察,找出其中蕴含的规律信息,例如检查网站是否存在定期的爬虫抓取房价、票价现象,自动发现某些监控指标的季节性指数等场景。通常的办法是将时间域的时序信号经过傅里叶变换映射到频率域加以分析。以下示例是对生产某个应用一段监控时间序列先做自相关降噪,滤波器剔除高频干扰,然后借助快速傅里叶变换FFT确定时序周期的场景。
自上而下分为原始时序、自相关函数输出、滤波器滤波后的时序及FFT变换之后的幅频响应,从最下面一幅图可以清楚的看到一条谱线,通过适当的变换即可得出该时序发生的周期
2、故障智能诊断
便随着携程业务的不断扩大,网站架构也在朝着越来越复杂的结构演化。一旦出现订单或应用异常,靠人力已经很难快速定位到故障根源,即便是经验丰富的资深运维人员很多时候也需要花费很长时间来定位。对携程这样一个在OTA行业的领军企业来说,长时间的网站不可用,损失的不仅仅是收入,更是用户体验和社会信任,因而能够快速定位故障源和止损,至关重要。
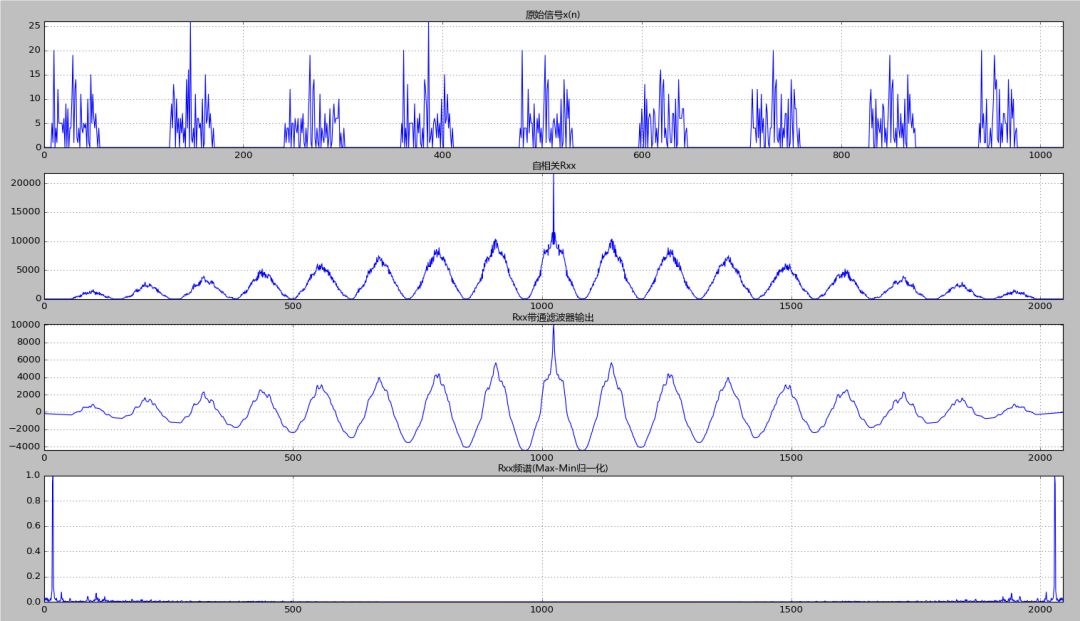
 实际的网站架构拓扑更加复杂
实际的网站架构拓扑更加复杂
正因网站架构非常复杂,故障点就可能存在于网络线路、路由器、交换机、机架、服务器、负载均衡设备、代理、DNS、CDN、数据库、Redis、应用程序、外部供应商接口等各个环节。
而且对于大部分的网站故障,往往环节相扣。例如,上游的故障源,通过调用链,一层层传遍所有依赖方,即使每个环节都有着非常完善的监控告警系统,但面对大量的告警风暴,定位故障根源绝非易事。另外,定位到故障根源之后,也需要手动恢复,如此一来也是增加了网站恢复的总时间。
为了解决这个难题,我们收集来自各个告警系统、发布系统、变更系统、配置中心等多个数据源的消息,包括网络告警、基础系统告警、应用告警、DB告警、Redis告警、代理告警、应用发布、变更、配置修改等,通过因子分析、相关性分析、决策树分析、马尔科夫链分析、调用链分析(面积算法)、专家知识库分析等方法,对每个候选的故障、发布或变更利用相关系数或贝叶斯公式给出一定的分数(分数代表了可信度),分数最高的确定为故障源。
通过不断地实践优化,未来花费在排障中的时间将大大减少,由原来数十分钟、乃至小时级别的排障时间缩短至分钟级,智能故障诊断将成为提升网站可用性最重要的保障之一。
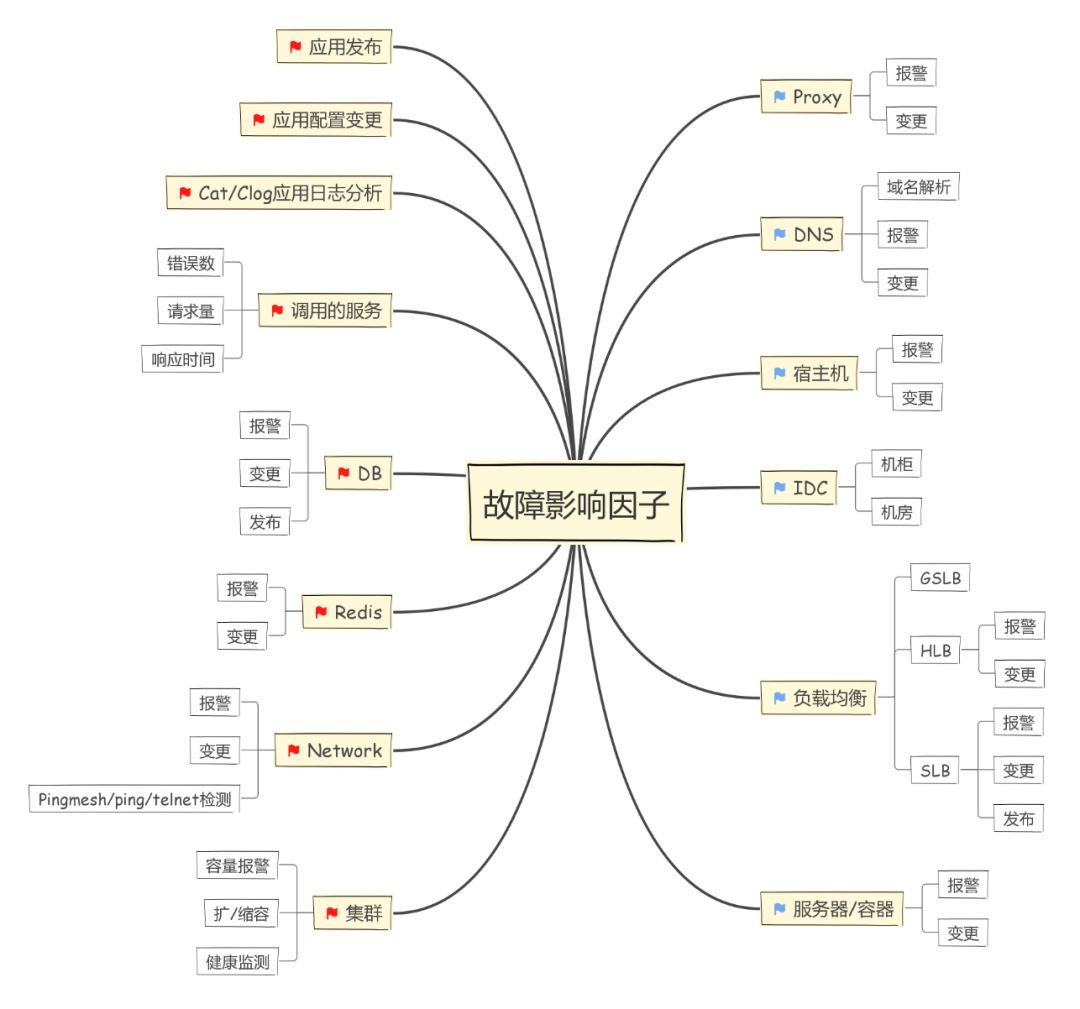
所有潜在故障因子展示
选取其中调用链故障诊断的部分逻辑做算法说明。
故障应用相关性诊断:
所谓牵一发而动全身,某个应用发生异常时,往往会殃及到整个调用链。故障期间如果可以归类这些相关联的告警,对于收敛告警或判断是否大面积故障,将变得非常有帮助。在众多判断相关性算法中,最简单的相关系数是一个不错的衡量标准。计算两个告警时序之间的皮尔逊相关系数,再结合应用之间的调用关系,即可给出故障应用相关性的诊断报告。
以下是某个时间点的故障应用相关性部分诊断报告内容,通过这个报告,可以比较快速的判断出是局部异常还是全局故障。如果仅为调用链上的相关告警,则认为是局部异常;反之则可能为全局或大面积故障导致。
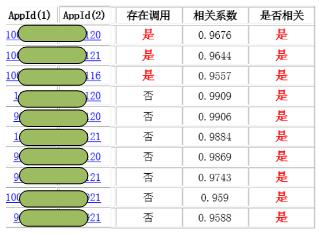
告警时序相关性分析显示应该为工具组件或大面积异常导致
3、资源利用率提升
如何在满足业务需求、安全的前提下,更加经济的运营网站是每个互联网公司都在不断探索的课题。降低网站成本一个很不错的主意就是提升对资源的利用率。接下来通过应用画像、Online/Offline混部以及智能弹性扩缩容来展示携程在提升资源利用率方面借助机器学习算法的成功实践。
应用画像
作为国内最大的在线旅游OTA,携程拥有成千上万的应用,每个应用对资源的使用情况也各不相同,哪些是CPU计算型应用、哪些是内存消耗型应用、哪些是高IO应用等,为了提高应用对资源的整体利用率,需要我们有能力对其进行区分。
针对这个问题,我们设计了应用画像,通过利用K-means、EM等聚类算法对应用基础监控的各项监控指标、应用监控指标、发布历史数据做分类,区分出:CPU密集型、内存密集型、网络IO密集型、请求耗时型、频繁发布型等应用,同时给出每个应用属于某个标签的置信度。
对比以往宿主机上随机分配应用的资源,借助应用画像,将亲和性高的应用部署在同一宿主机上可以有效提高整体资源的利用率。
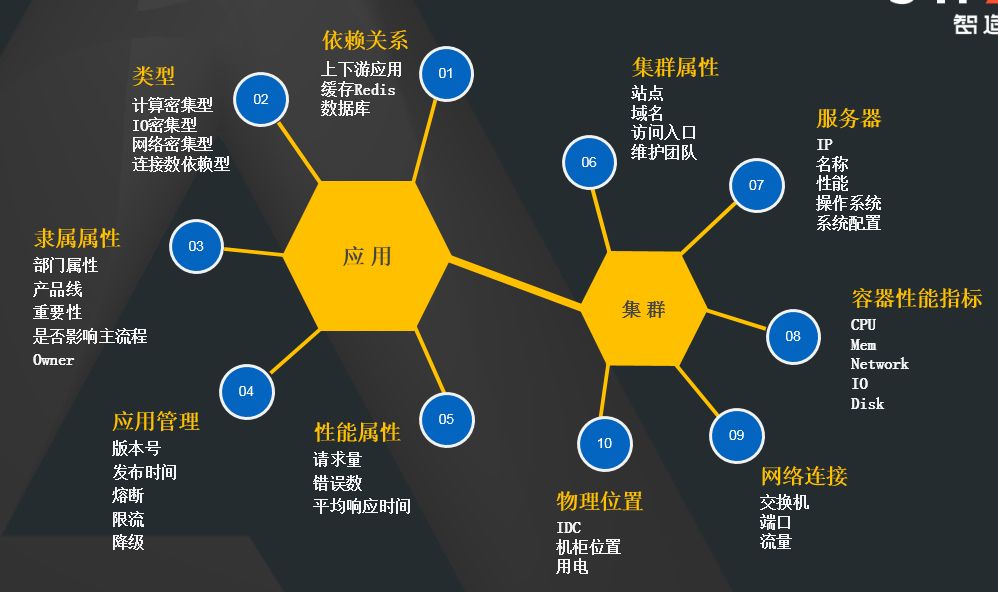
应用画像各个维度标签展示,除帮助提升资源利用率外,在其他场景也有广泛使用
Online/Offline混部
携程的业务特点决定了大部分的Online应用资源在夜间非常的空闲,而Offline的一些Hadoop、Spark作业在这段时间对资源的利用率又非常高。
借助应用画像筛选合适的Online应用资源,在其利用率低峰期间部署实例调度Offline作业使用,即填补了Online资源利用率的低谷,又为Offline作业减少了离线资源采购(离线资源采购费用非常昂贵)。Online/Offline混部在提升数倍资源利用率、分担Offline作业的同时,也提供了一种对资源互补使用的常态调度模式。
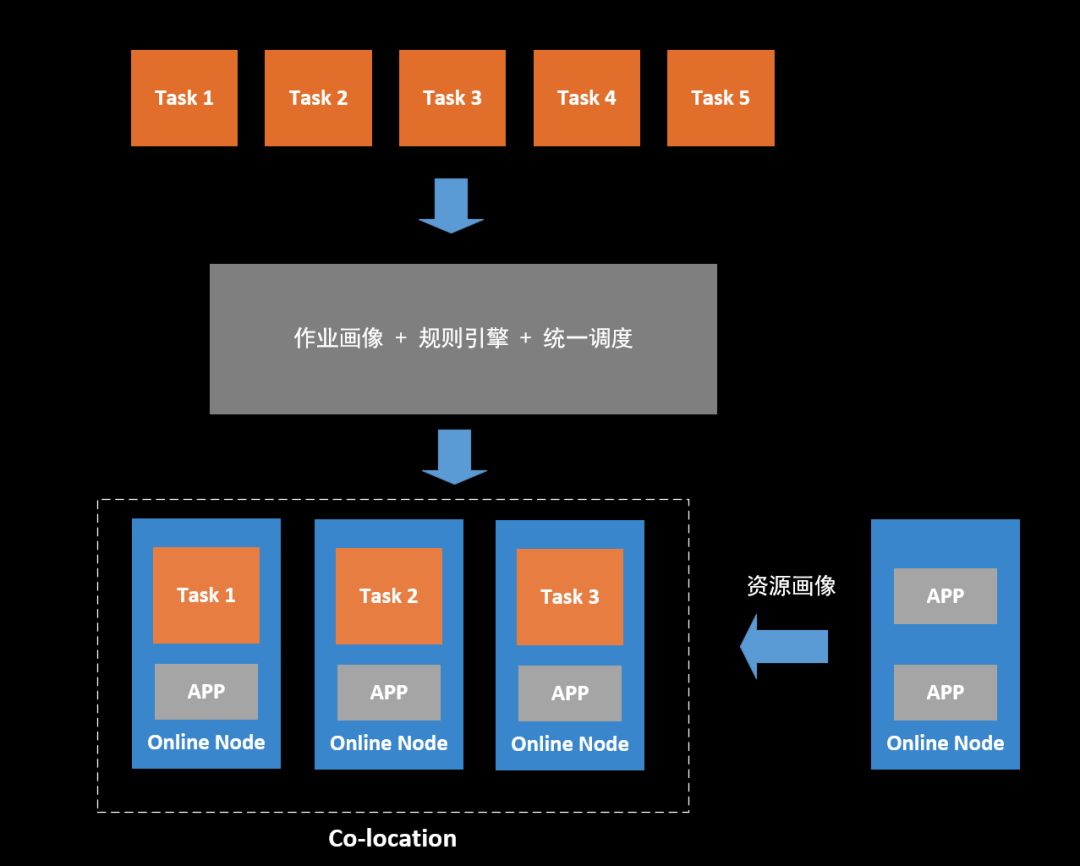
Offline作业调度到Online计算节点
智能弹性扩缩容
虽然携程已经具备了虚拟机分钟级交付、容器秒级交付的能力,但在传统运维中,资源的申请与回收均需要有相关人员手动触发才可以完成。
如遇到突发流量飙升造成的容量不足,且相关人员不能及时就位,就可能引发生产故障;另外,因业务逻辑下线但服务器并未下线时,长此以往就会堆积大量的空闲服务器,造成了对资源的浪费以及网站成本的增加。
针对这个场景,设计资源的利用率模型,使用SVM(支撑向量机)等算法对CPU、内存、网络IO等多个维度加以训练,定期扫描生产资源,产出容量富裕和不足的容量报告。针对这些容量报告,通过携程内部的弹簧系统(Spring,弹性扩缩容平台)对资源补给和裁剪。整个过程不需要人工干预,在节省人力成本的同事,大大提高了资源的利用率,降低了运营成本。
三、结束语
Dev和Ops的碰撞,产生了DevOps,DevOps的出现避免了重复性的工作,减少了人力成本,显著地提升了运维效率;AI和Ops的邂逅,诞生了AIOps,作为DevOps更高阶的实现,以机器学习、统计替代基于规则的传统运维模式,通过对海量运维数据的分析,更加智能的做出分析、决策。AIOps目前还属于不断完善和探索阶段,未来会有更多的场景被挖掘和应用。可以预见,面对未来越来越复杂的运维场景和挑战,非AIOps而不能胜任。

徐新龙,携程技术保障中心资深运维AI工程师,毕业于复旦大学信号处理专业,硕士学位。负责携程多个 AIOps 项目的设计与研发,对人工智能、机器学习、神经网络及数学有浓厚的兴趣,对人工智能技术结合运维场景的实践有深入研究。
9月 GOPS 上海站,徐新龙老师将会带来携程 AIOps 的精彩分享,感兴趣的技术人员千万不要错过!
点击可查看高清大图
GOPS 2018 · 上海站 最新视频震撼来袭!
点击阅读原文,更多惊喜
以上是关于AIOps在携程的践行 | 活动通知的主要内容,如果未能解决你的问题,请参考以下文章