节约亿级成本的阿里AIOps案例:群体强化学习助力容器调度
Posted 智能运维前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了节约亿级成本的阿里AIOps案例:群体强化学习助力容器调度相关的知识,希望对你有一定的参考价值。
2018 年“双 11”的交易额又达到了一个历史新高度 2135 亿。相比十年前,我们的交易额增长了 360 多倍,而交易峰值增长了 1200 多倍。相对应的,系统数呈现爆发式增长。系统在支撑“双 11”过程中的复杂度和难度呈现指数级形式上升趋势。
作为阿里巴巴全集团范围的容器调度系统,Sigma 在“双11”期间成功支撑了全集团所有容器(交易线中间件、数据库、广告等 20 多个业务)的调配,是阿⾥巴巴运维系统重要的底层基础设施。Sigma 已经是阿里全网所有机房在线服务管控的核心角色,管控的宿主机资源达到百万级,重要程度不言而喻,其算法的优劣程度影响了集团整体的业务稳定性,资源利用率。本文将简要介绍群体增强学习算法在调度策略优化中的应用
王孟昌 达摩院机器智能技术算法专家
韩堂 阿里巴巴集团技术专家
王孟昌 达摩院机器智能技术算法专家
韩堂 阿里巴巴集团技术专家
计算资源调度及在线策略
当用户向 Sigma 申请容器所需的计算资源(如 CPU、Memory、磁盘等)时,调度器负责挑选出满足各项规格要求的物理机来部署这些容器。通常,满足各项要求的物理机并非唯一,且水位各不相同,不同的分配方式最终得到的分配率存在差异,因此,调度器的一项核心任务就是按照某一策略从众多候选机器中挑出最合适的物理机。
在文献中,计算资源调度一般被表述为矢量装箱问题(vector bin packing problem),如果各应用的容器数量事先已知(如大促场景),调度器可一次性为所有容器生成优化的排布方案,此时问题可以表述为整数规划,可使用通用求解器或专门开发的算法来求解;
如果各应用的请求陆续到达 Sigma (如日常场景),调度器需要在每次请求到达时即时(在线)生成部署决策,此时问题可表述为马尔可夫决策过程 (Markov Decision Process, MDP),原则上可以通过值迭代或策略迭代求得最优策略。
最常用的调度策略包括 First-Fit (FF) 和 Best-Fit (BF)。如果使用 First-Fit 算法,调度器会将容器部署到遍历中碰到的第一个满足所有要求的物理机上;而 Best-Fit 算法则会在满足要求的物理机中挑选分配水位最高的机器来部署容器。对于经典的 bin packing 问题(即一维矢量装箱问题),First-Fit 和 Best-Fit 的近似比均为 1.7,即二者都可保证所使用的机器数不超出最优方案的 170%;对于 2 维及以上的矢量装箱问题,理论上不存在有着明确近似比保证的多项式算法。
当物理机的某个资源维度明显为瓶颈而导致其它资源维度普遍有剩余时,其有效维度可视为 1,使用 First-Fit 或 Best-Fit 一般可以取得不错的分配率;而一旦瓶颈并未集中体现在同一维度,两种策略的效果就要大打问号了。
除了资源维度上的要求,实际调度中还有容灾和干扰隔离上的考虑:比如同一应用的容器不允许全部部署到同一台物理机上,很多应用甚至每台机器上只允许有一个实例;某些应用之间还存在互斥关系(如资源争抢),严重影响应用的性能,因此也不允许它们被部署到同一物理机上。这些限制条件的引入,使得常用策略越发水土不服了。通过人肉反复试错,勉强扛住了多次大促建站的压力。然而,随着各业务的扩张,线上容器的规模越来越大,资源变得越来越紧张,人肉调参的效率渐渐力不从心。
为了把调度同学从调参中解放出来,让有限的资源扛住更大的压力,达摩院机器智能技术实验室(M.I.T.)的决策智能算法团队和 Sigma 调度团队展开了紧密合作,对在线调度策略问题进行了研究,并开发了基于群体增强学习(SwarmRL)的算法。
在线调度模型
记当前待部署容器的规格为向量 p∈P ,为其分配资源时集群状态为向量 s∈S,候选物理机的集合为 A⊆A,策略可表示为函数 π:S×P→A(π∈Π)。当按策略 π 选择物理机 a=π(s,p) 来部署该容器时,该选择的即时成本为 r(a),集群的新状态 s′ 由状态量 s 、p 以及动作 a 共同决定,记为 s′=L(s,p,a);记后续到达的容器规格 p′, 对于在线调度,p′ 为随机量。引入折扣系数 γ∈[0,1],系统的 Bellman 方程为:
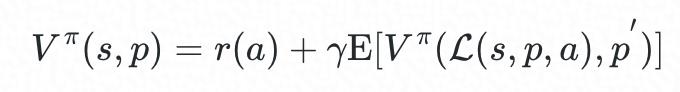
最优调度策略可表示为:
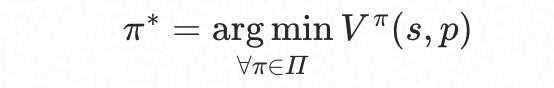
理论上,通过随机梯度下降,我们可以在策略空间 ∏ 中搜索较优的策略,但想要更进一步地优化,甚至得到全局最优策略,则需要借助其它方法,特别是当最优策略可能是 multi-modal 形式。
群体增强学习 SwarmRL
为防止策略的优化陷入较差的局部最优解,同时拥有较快的收敛速度,我们基于群体增加学习的框架来设计算法。与传统的增强学习方法相比,算法使用多个 agent 来探索问题的策略空间,且多个 agent 之间存在互相学习机制,这使得算法有了跳出局部陷阱的能力。为获取各状态值(Vπ)的估计,一个准确的 Sigma 模拟器必不可少,在此鸣谢团队同学基于 Sigma 的调度器开发了“完全保真”的模拟器 Cerebro。
算法首先随机初始化一群 agent 的策略,针对每个策略,通过模拟器获取相应的的状态值估计,记录当前全局最佳策略。在后续的每次迭代中,各个 agent 不断更新自身的局部最佳策略,并参照局部最佳策略与群体当前全局最佳策略,对 agent 自身的当前策略进行更新,再进行模拟,获取新策略的状态值估计,更新全局最佳策略。如此循环,直到满足收敛条件。
在各个 agent 状态值的估计中,样本(多个随机抽取的集群快照和扩容请求序列)和各 agent 的当前策略被输入模拟器 Cerebro,追踪模拟时集群状态的轨迹,即可得到该轨迹的总成本;基于多个样本的轨迹总成本求平均,即得到相应策略下的状态估计值。

在 SwarmRL 中,策略的演进方向与步长用“速度” (v) 来表示,速度的变化涉及局部最佳策略 (πL) 和群体全局最佳策略 (πG) 与 agent 当前策略 (π) 的差异,并受策略惯性因子 w、本地学习因子 C1(self-learning)、群体学习因子
C2 (social-learning) 等参数的调控:
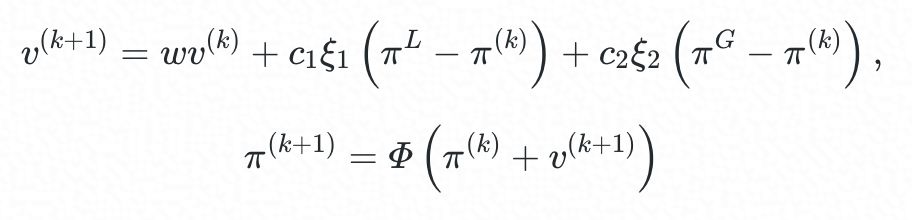
其中 ξ1,ξ2∈[0,1] 为随机量,Φ 为可行性保持映射,用于将逸出可行域的 agent 重新“拉回”可行域。在迭代中,局部最佳策略 (πL) 和群体全局最佳策略 (πG) 不断更新:

算法应用
下面我们先用一个随机生成的小算例来对比一下算法的效果。算例中涉及 30 个应用(见下表),其容器规格主要为 4c8g 与 8c16g,所用宿主机的规格均为 96c512g。
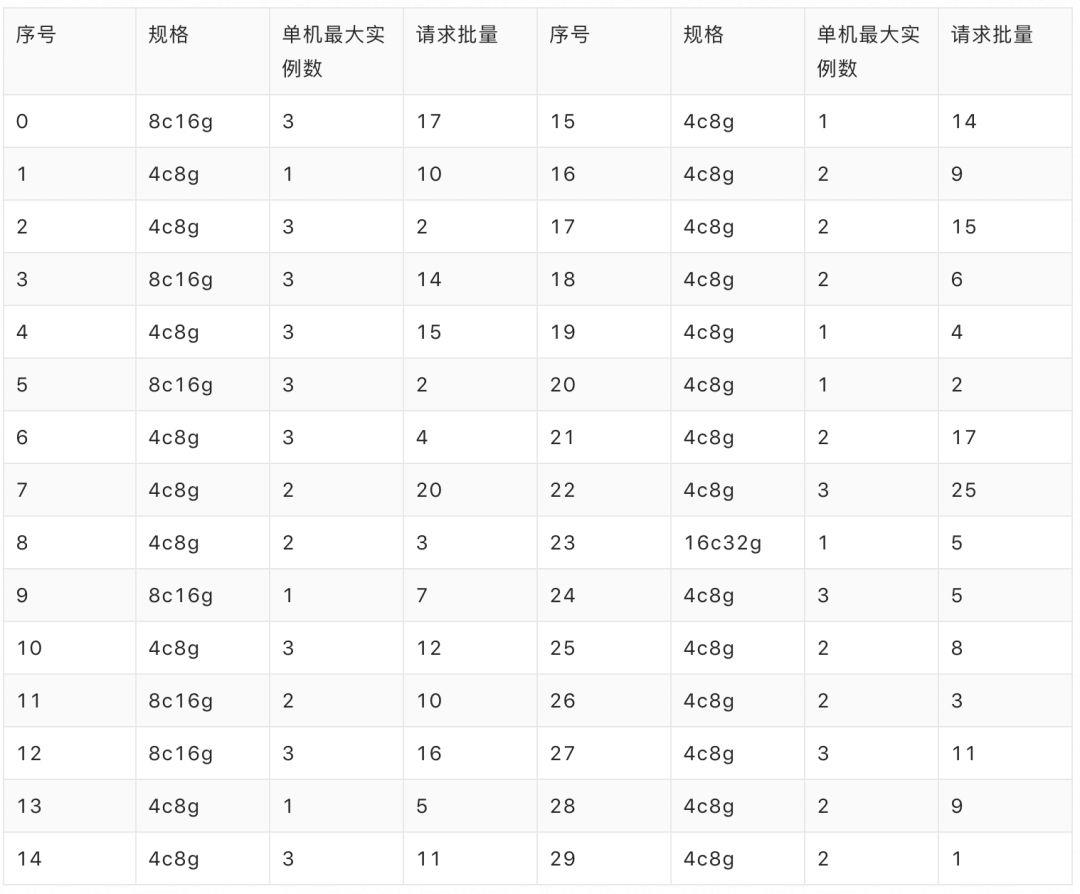
若在调度时,请求的顺序和数量均为已知(“上帝视角”),即进行事后排布,使用整数规划求得的最优解对应的分配率为 94.44 % (这也是所有调度策略在该算例上所得分配率的上界),共启用 15 台宿主机,具体排布方案为:
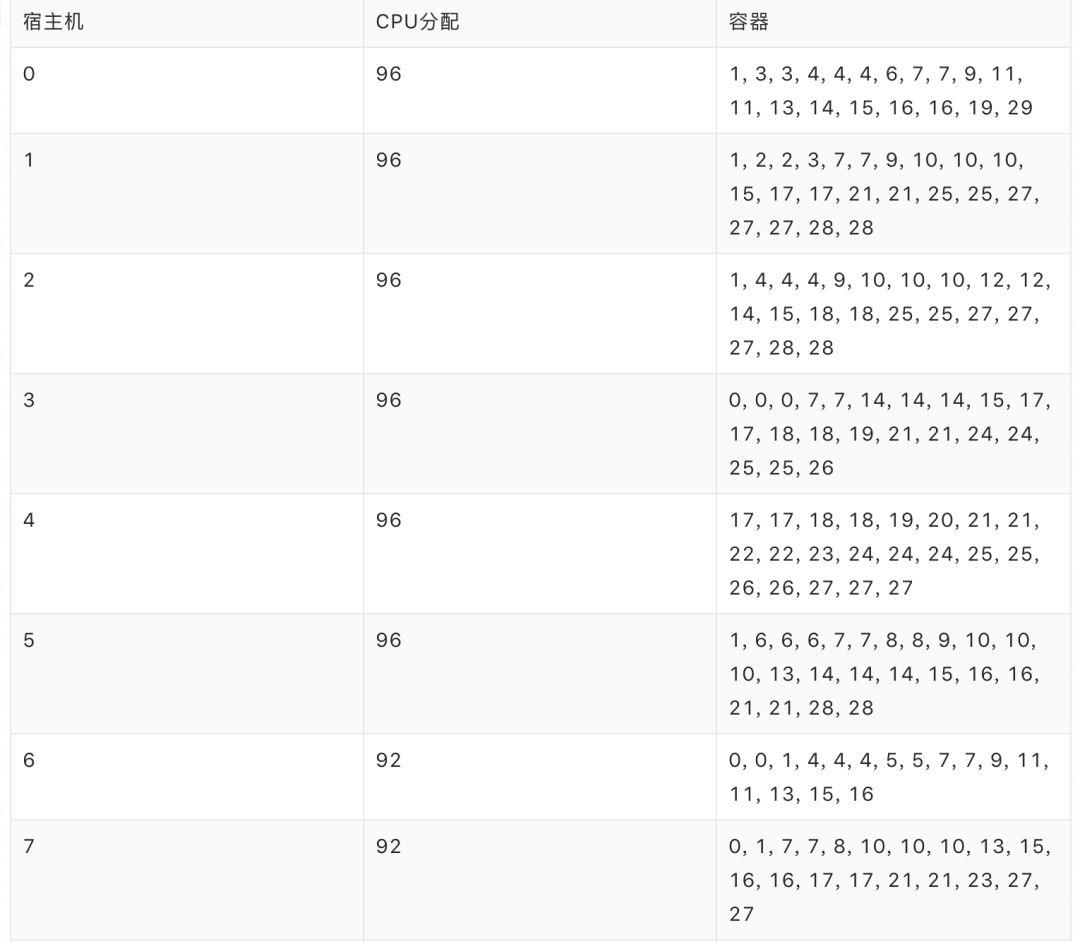
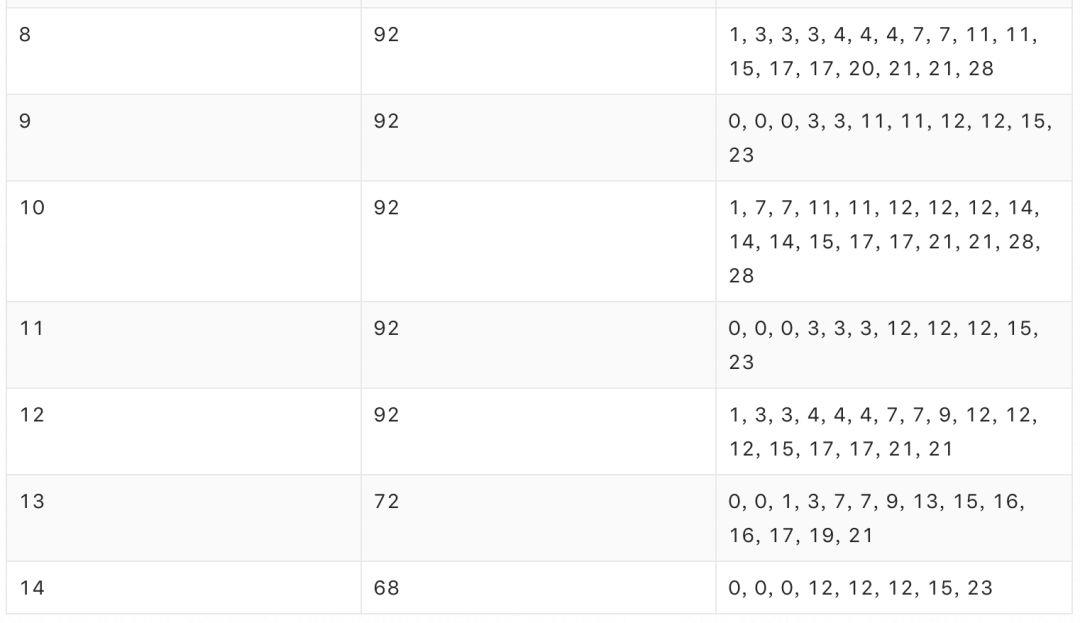
现实场景中,每个请求所处顺序和容器数量仅在其到达 Sigma 时才揭晓,若采用 Best-Fit 进行动态调度,所得分配率为 70.83%,共启用 20 台宿主机,具体排布如下:
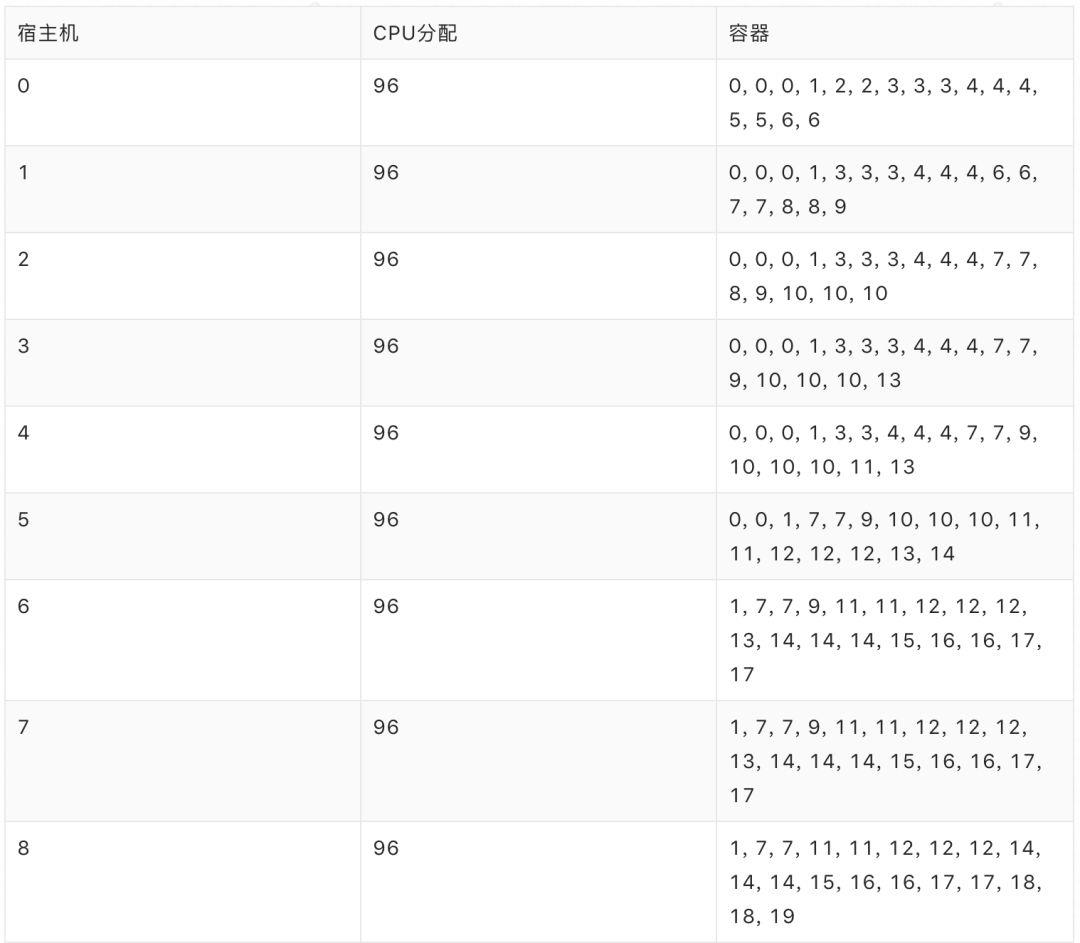
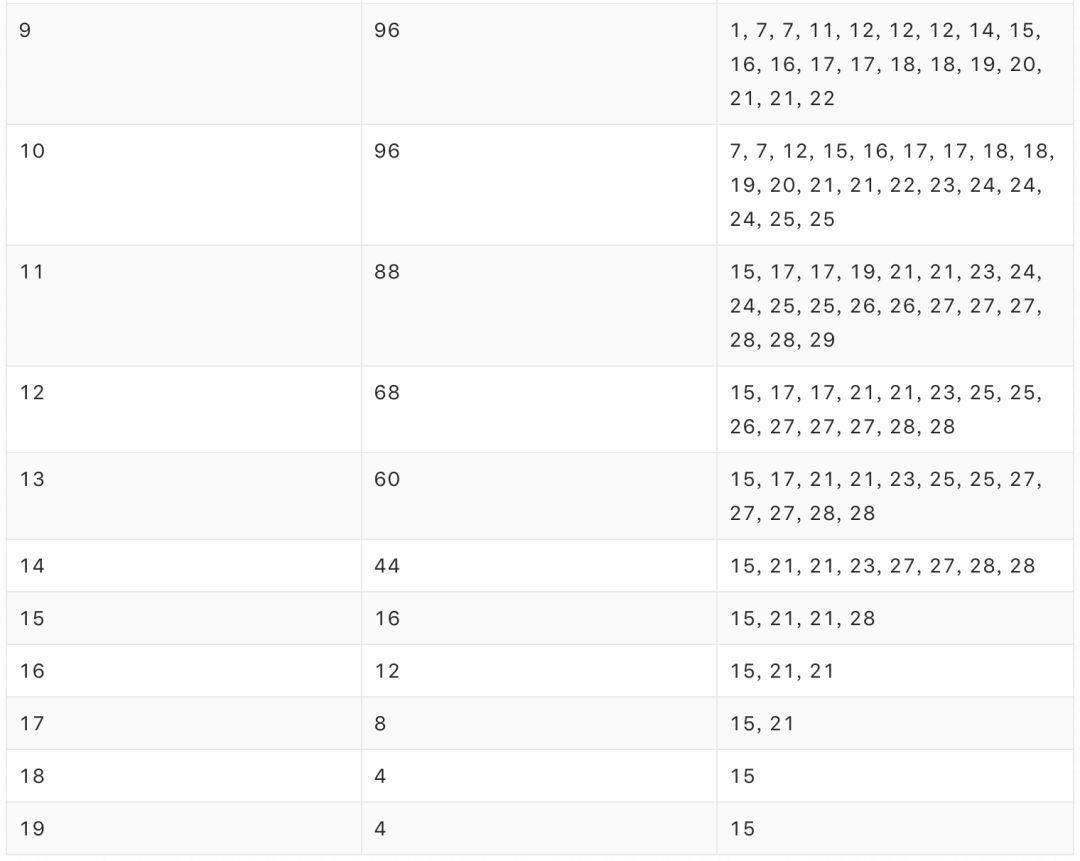
若采用 SwarmRL 学习所得策略进行动态分配,分配率为 94.44%,共启用 15 台宿主机,最终容器排布如下:
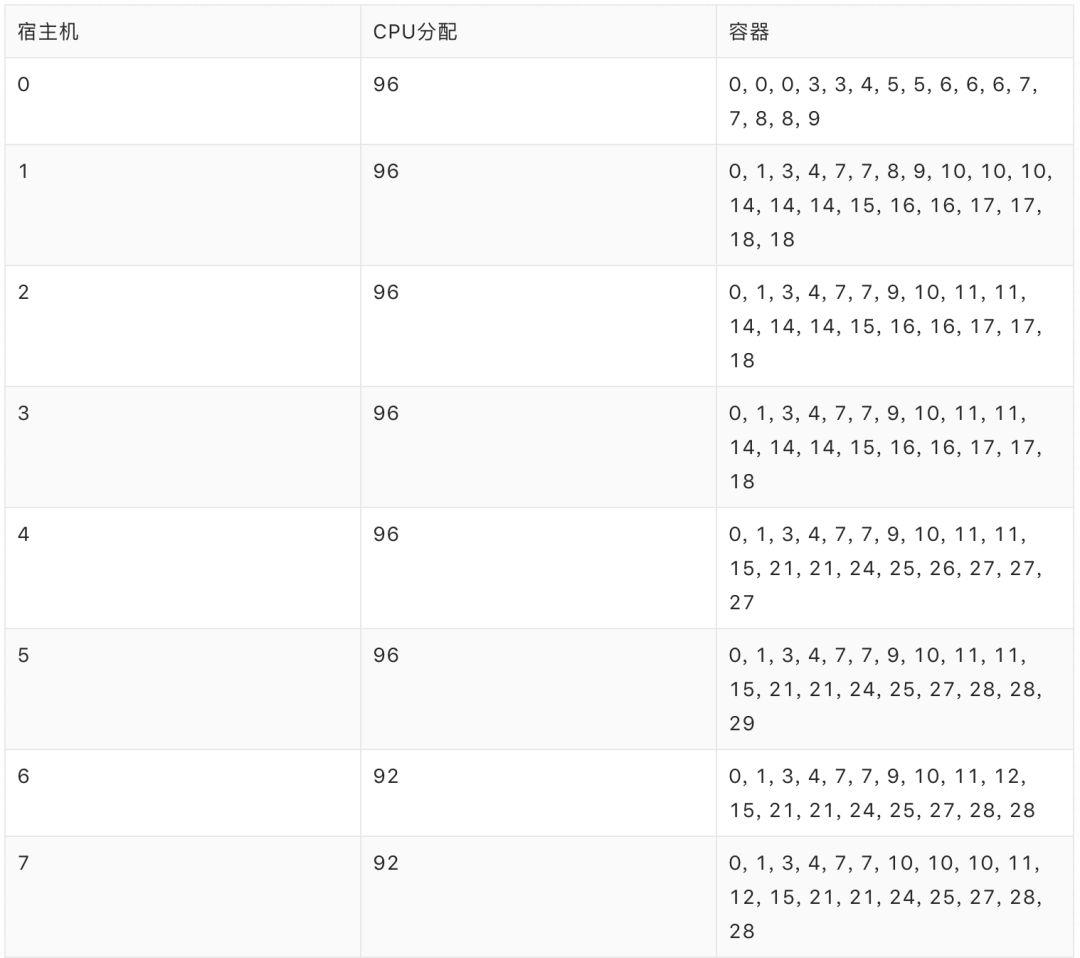
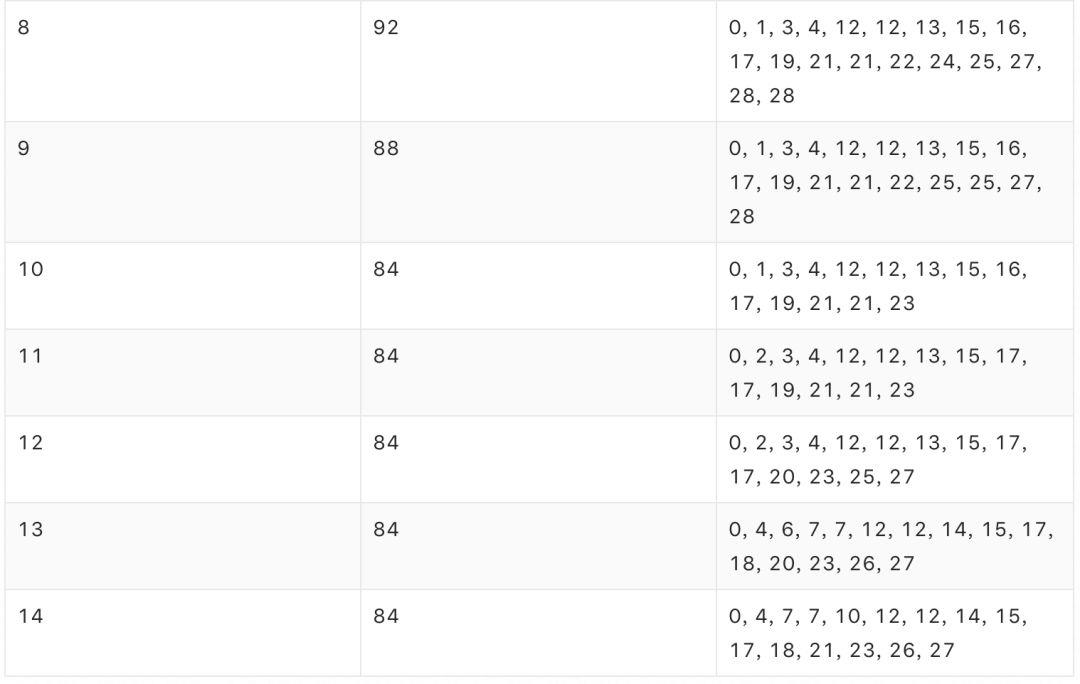
在该算例中,SwarmRL 学习所得策略的表现(94.44%)与“上帝视角”下最优排布的表现(上界)一致,明显优于 Best-Fit 的表现(70.83%),改进幅度达 23.61%。
我们再随机生成规模较大的请求数据:共计 3k 个请求,5k 个容器,其规格分布如下图:

由于该场景下整数规划模型的变量规模太大,已经无法在短时间内直接求取“上帝视角”的最优解。对比 Best-Fit (以及人肉策略),算法所得新策略的效果如下:

相对于 Best-Fit,新策略节约宿主机 13 台(4.48%),分配率提升 4.30%;相对于人肉策略,新策略节约 7 台(2.46%)宿主机,分配率改进 2.36%。
考虑到实际场景中应用请求到达顺序的随机性,我们随机打乱请求生成多个不同的请求顺序,再分别应用三个策略按不同的请求顺序进行动态分配:
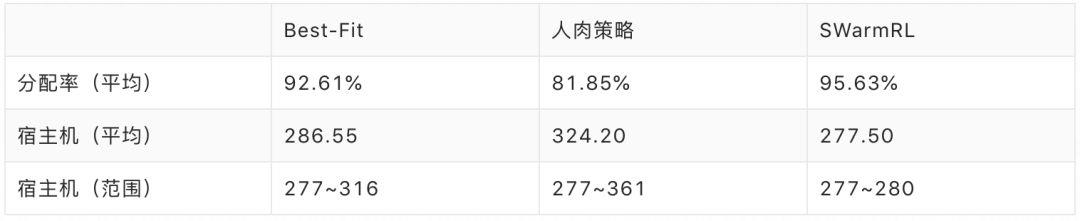
Best-Fit 在不同请求顺序下宿主机数量的极差为 39 台,相对人肉策略的 84 台而言,表现相对稳定,其波动幅度约为人肉策略的一半;人肉策略的平均分配率低至 81.85%,对比原顺序下的 93.44%,可见人肉策略的性能并不稳定,表现出较剧烈的波动。而学习所得新策略的表现则相当稳定,其宿主机数量的极差仅为 3 台,波动幅度约为人肉策略的 30 分之一;新策略的分配率平均比人肉策略的分配率高 13.78%,比 Best-Fit 的高 3.02%。
总结与展望
从提升分配率、节省资源的角度来看,SwarmRL 算法可以产生出优于常用(以及人肉)的策略,并且有着较为稳定的表现。算法部署到线上环境后,公共资源池的分配率峰值与之前相比有了明显的提升。
随着 cpu share 和混部的铺开,除分配率外,新的场景将涉及更多目标,比如打散、负载均衡等,这些目标甚至还有互相矛盾的地方,而 SwarmRL 的运行机制天然适合具有多个目标的策略优化问题,可以十分方便地在策略空间中构造 Pareto Front,因而,后续我们将继续研究新场景下的在线调度策略问题,充分挖掘 SwarmRL 的潜力,进一步提升 Sigma 的调度能力。
参考文献
[1]David Simchi-Levi, Xin Chen and Julien Bramel (2014). The Logic of Logistics: Theory, Algorithms, and Applications for Logistics Management (3rd ed). Springer
[2]Richard S. Sutton and Andrew G. Barto (2017). Reinforcement Learning: An Introduction. The MIT Press
[3]Hitoshi Iima, Yasuaki Kuroe and Kazuo Emoto (2011). Swarm reinforcement learning methods for problems with continuous state-action space, IEEE ICSMC
[4]Yossi Azar, Ilan R. Cohen, Amos Fiat and Alan Roytman (2016). Packing small vectors. SODA'16
[5]Yossi Azar, Ilan R. Cohen, Seny Kamara and Bruce Shepherd (2013). Tight bounds for online vector bin packing. STOC‘13
介绍世界范围内智能运维的前沿进展
推动智能运维算法在实践中落地和普世化
以上是关于节约亿级成本的阿里AIOps案例:群体强化学习助力容器调度的主要内容,如果未能解决你的问题,请参考以下文章
完爆 Best Fit,看阿里如何优化 Sigma 在线调度策略节约亿级成本