AIOps 为什么不温不火?
Posted 架构头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AIOps 为什么不温不火?相关的知识,希望对你有一定的参考价值。
骨感的现实中,如何找到丰满的解决答案,今天我们就来和阿里云资深技术专家周琦老师聊聊,他是如何理解 AIOps 不温不火的原因的。
我从高中开始学习编程,第一门语言是 PASCAL(主要是用来参加竞赛),之后学习 C、VC++ 等语言,编写过各种应用端(IDE、MFC)和 Web 的程序(ASP、php 等)。在高中阶段帮餐饮公司开发过账务管理系统,音乐公司的宣传网站等。
后来步入大学,开始慢慢正规化学习计算机编程,这些年的经历总的概括起来可以分为这四个时间段:
软件工程时代:关注应用逻辑正确性,发展过程中沉淀了大量的框架和最佳实践,例如 Spring、TDD 方法(Test Driven Development),重构(Refactor)等,研发工作从个人行为转为一个可以提升的专业能力;
Web 服务时代:2008 年末 ios + android 诞生使得移动互联网在继 WAP 后真正成形,研发的技术点也逐步从功能关注转为如何构建一个高扩展的架构,例如 Hadoop、NoSQL 等就是该时代的产物;
O2O 业务开花:新的业态大量诞生铸造了敏捷开发的模式,更快产品迭代速度对上线发布提出更高要求;
云原生时代:在混合云(线上、线上)过度中,如何保证系统架构稳定性,弹性伸缩,如何快速适配业务逻辑。
从这几个时代的发展来看,能够看到三个趋势:
专业程度很高:分工更细了,前端、后端,应用层开发,对 DevOps 而言需要管理部分也越来越多;
更快发布速度:在过去一个版本发布需要漫长过程,但目前业务发展很快,开发速度更快,如何能够又快又不出错是一个很高业务要求;
更高可用性:异构环境下,业务 7*24 要求对可用性越来越高。
对 DevOps 而言,承载的职责范围变大,业务压力变高了,并且需要更高的稳定性要求。好比你在驾驶一辆坐着很多人(前端、服务端、应用开发)的汽车,在更高速度行驶,并且要保证不能有差错。因此需要你对汽车的速度、油耗、运行状况能有更好的感知,对行驶的路况有提前判断的能力,更安全的驾驶行为。
大部分时间在做产品设计和技术选型工作,也仍在做一些基础开发。因为我们平时都在做面向 DevOps 的工作,必须能够对问题有感觉,所以离不开基础研发工作。
从个人经历来看,5 年前曾有一个比较大的转变,慢慢从做纯技术转为面向产品的技术,来服务技术人员,具体有亮点:
让自己从纯技术思维中跳出来,考虑如何通过产品来解决用户的问题,要考虑如何把问题能够抽象和组合,而不是解决一个表面问题;
能够清楚核心能力是什么,如何从下往上逐步触达。以汽车自动驾驶为例,其定义 L1-L5 的层次,使得大家能有阶段性的目标来达成。
工作中在 AIOps 领域的数据处理、建模、异常检测、故障诊断、知识图谱等有实践经验,也正推进在业务场景的落地。从个人角度来看,AIOps 本质和自动驾驶是类似的,目的是为了提升 IT 系统安全性、稳定性和可用性,减少人力和硬件上的投入。
同时我们可以把自动驾驶与 AIOps 整个技术体系做一个类比,也是类似的效果。为了达到 L4 终极目标,有如下横向工作需要建立:
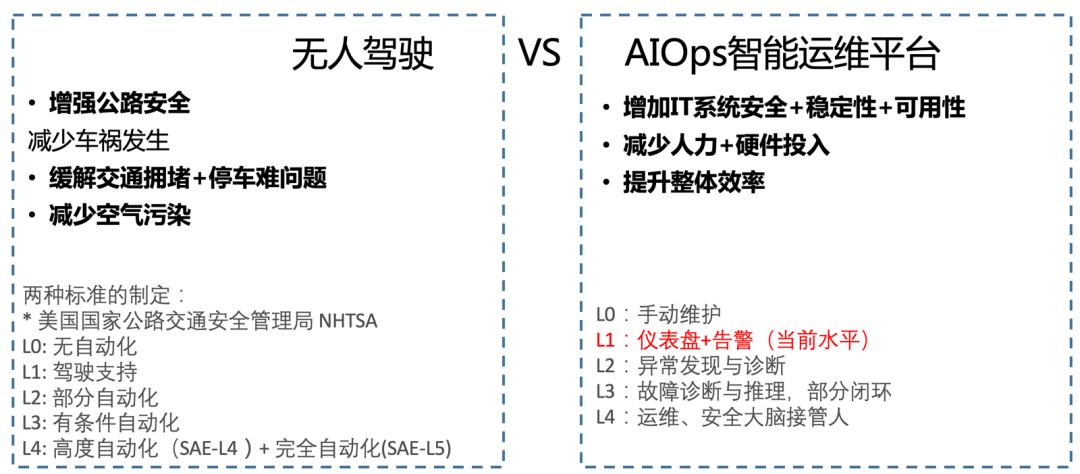
传感技术:如何使用可观察性数据(例如 CNCF 中 OpenTelemetry)来构建一套完整的运行数据观察体系,越多数据意味着掌握更多情况;
感知:通过数据处理、加工计算等技术,实时地从传感数据中计算出运行状态,并加以建模;
高精度地图:通过知识图谱和数据挖掘描述出对象之间的关系和影响;
决策层:根据多维的实时数据进行计算并获得结果,发现其中的异常并进行规模和处理。
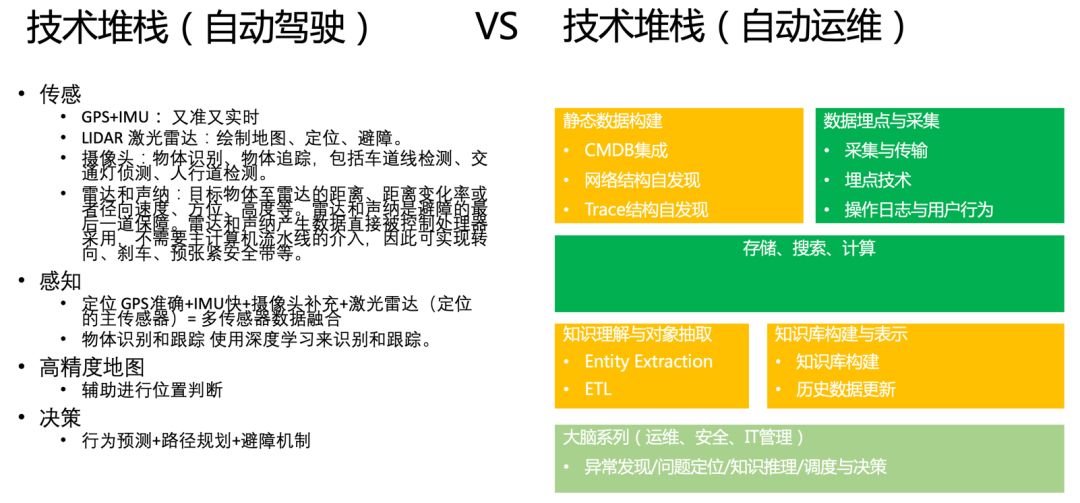
例如右半部分“自动运维技术堆栈”主要分为四个部分:动态数据采集层,能够从各个系统中获得运行数据,例如 Log,Metric 和 Tracing 等。可以认为是自动驾驶的摄像头、激光雷达等感知设备。静态数据采集层:将 IT 架构的型号、上下游依赖等进行构建,以确定上下文。类似自动驾驶的静态地图。处理层(包括数据存储、搜索、计算等工作):把采集到的数据运行各种规则,以形成可以被分析的数据。类似自动驾驶中对其他车辆、人、交通信号等进行建模,以判断对应的速度、区域、方向等。决策层:最重要的部分,根据计算后的数据对关联的对象行为进行预测、分析、推理等,以确定风险和下一步的行为,类似自动驾驶中的大脑。
自动化运维是一个基于规则的工作,例如我们定义出创建的状态和处理的规则,当某某条件发生后,会进行下一步操作。
而智能化运维会面向很多不确定性的工作,需要去执行预测、推理、分析等任务,并且能够通过建模等适配新的场景进行泛化。因此智能化运维能够承载更多、更具挑战的工作。
从技术采用生命周期模型来看,任何技术在大规模运用之前,都需要跨过鸿沟,有一个从爬坡到下降最后持续爬坡过程,AI 是如此(想想 70 年代的 AI 技术),AIOps 也一样。Gartner 最新《Hype Cycle for ICT in China 2019》中对 AIOps 的评价比较客观:该技术处于从一项创新(Innovation Trigger)到万众期待顶点(Peak of Inflated Expectation)过程中,之后还会经历一个低谷期(Trough of Disillusionment)直到最终成果。但 AIOps 目前在国内已经被各行各业逐步认可,普遍被认为该技术在接下来 2~5 年内会产生较高收益,是值得投入的方向。
个人觉得内在原因很简单,技术创新刚刚开始,需要 1-2 年时间逐步成熟并商用的过程。这是客观规律:任何技术短期内会被高估,而长期内是被低估的。
外在原因我认为有两方面:
IT 基础架构最近几年随着云计算、云原生、移动端等技术发展,变化非常大,开发与运维人员知识体系也在不停更新中,因此缺乏一个比较稳定场景让配套的 AIOps 技术能够诞生;
数据与算法平台缺乏:AIOps 本质上是 DataOps + Domain Knowledge,其中前者是一个工程问题,对于 AI 而言,首先需要有充足的“多维数据 + 配套的算力(实时性)”才能够达到真正驾驶上路的水平,试想神经网络算法 80 年代就有了,也是 2012 年后算力和数据丰富了,才提升了一个台阶。这点好在目前的“数据采集 + 大数据架构”已日渐成熟,这个问题会逐步消失。
目前 AIOps 落地和尝试主要集中在学术界和企业界,例如国内学术界领域比较有名的是清华大学裴丹老师,在学术会议上发表很多优秀文章,也组织了非常好的会议。其次是企业 DevOps 部门,例如国内各大互联网厂商,企业 IT 部门,使用 AI 技术解决运维、发布、供应链等场景上解决问题。最后就是 IT 软件厂商:例如 APM、SIEM、DevOps 等厂商等在技术堆栈上引入了 AI 元素,加深产品的功能和场景覆盖面等。
AIOps 是一个开放领域,目前工业界和学术界并没有严格定义,因此无论是异常发现、故障定位、知识管理、或面向场景的解决方案都是受欢迎的。但希望话题具备以下三个特质:
时代性:特别是在云原生、容器、移动端等场景下,如何应对环境的复杂性;
通用:能够解一个或多个通用问题,并且方法有一定的泛化能力,这些问题是业务的痛点,能够引起共鸣,能够具备一定的复制能力;
启发:方法的创新性,能够给同行工作带来一定启示,至少能够开阔思路。
希望参会者首先能听懂问题、有共鸣感、并且能够引发该场景的思考。用一句古话道:学而时习之,不亦说乎?
作者介绍
周琦(简志),阿里云资深技术专家。从 2009 年加入阿里云,曾负责分布式系统开发,并且负责其中监控、诊断等系统,也承担技术云化的重任。目前负责阿里集团 / 蚂蚁金服 / 阿里云日志处理、分析平台,同时也是 ArchSummit 全球架构师峰会(北京·2019 年 12 月)AIOps 专题出品人。很有幸采访到周琦老师,多年的技术积累,希望对运维领域的你有帮助。
欢迎关注 ArchSummit 全球架构师峰会,点击“阅读原文”查看官网。
以上是关于AIOps 为什么不温不火?的主要内容,如果未能解决你的问题,请参考以下文章