北邮AIOps新作:连续区间多类型KPI异常检测
Posted 智能运维前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了北邮AIOps新作:连续区间多类型KPI异常检测相关的知识,希望对你有一定的参考价值。
作者|王敬宇、靖宇涵等
编辑|Vicky
1. 背景
AIOps(Artificial Intelligence for IT Operations, 智能运维)将机器学习的方法运用到运维领域以提升运维工作的自动化和智能化程度。在运维过程中,KPI(Key Performance Indicator,关键性能指标)是衡量网络服务工作状态的重要指标,而KPI异常检测也是AIOPs的一个重要方向。异常检测方法,如ALSR,在AIOps中的应用如图1所示。
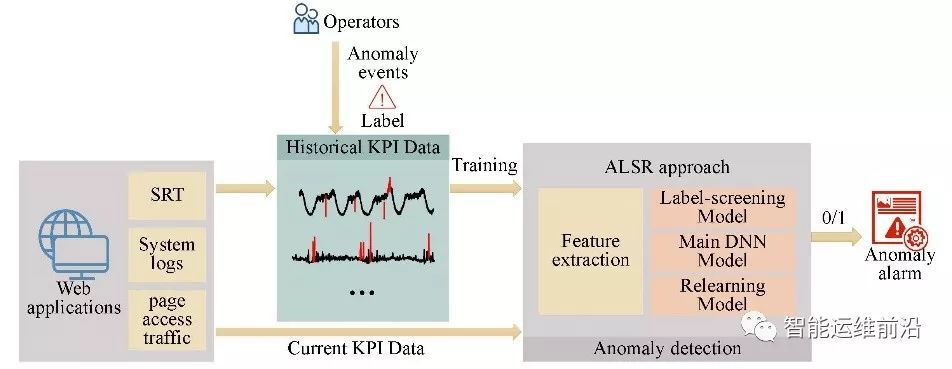
图 1 ALSR在AIOps中的应用
1.1多类型KPI
KPI时间序列数据可以从页面访问流量、在线人数、点击量等不同指标中获得。服务和指标的特性不同,获得的KPI也就具有不同的变化模式。本文所讨论的KPI主要具有如图2所示三种典型的变化模式,其中的异常由红色标出:
a) 强周期型KPI:这一类KPI具有非常明显的周期性,而噪声相对于周期性变化来说比较小。
b) 稳定型KPI:这一类KPI大多数时候保持不变或者存在很小的噪声。
c) 波动型KPI:这一类KPI的值处于明显的不断波动中,噪声对值的影响很大。
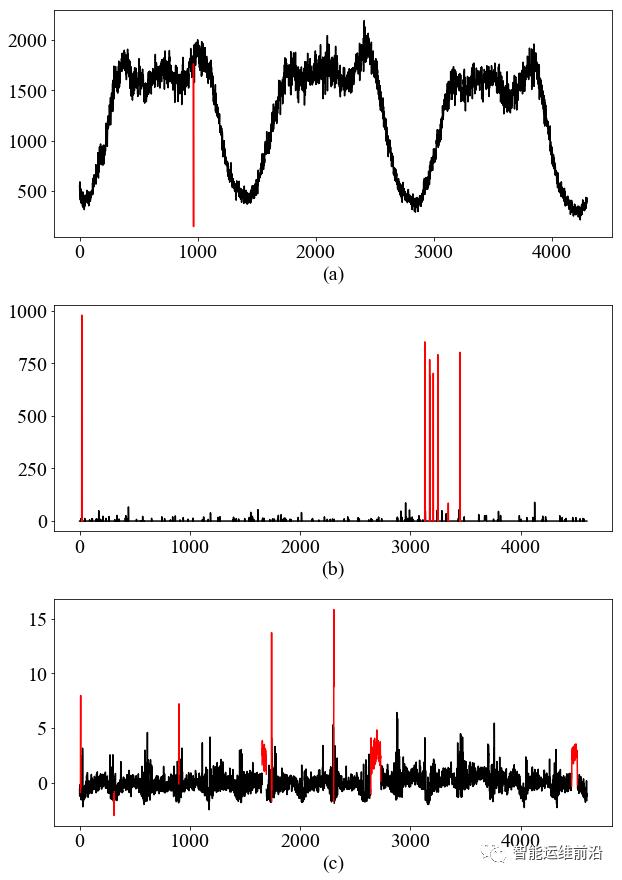
图 2 强周期性、稳定型和波动型KPI
在这几种类型的KPI中,发生的异常具有一定的相似性,比如:
• 当异常出现时,KPI值的大小、变化率等特征发生了明显的变化。
• 异常是以连续区间的形式出现的,这也与实际运维中发生的异常通常持续一段时间相符合。
1.2 面向区间的异常检测
在实际的异常报警中,运维人员可能更加关注每一个异常事件(连续异常区间)的检出,而非每一个异常点的检出。在这种需求下,衍生出了一种对于面向区间的异常检测标准(见第一届AIOps比赛评价指标[1]),使用如下方式计算异常检测中的TP、TN、FP和FN:
• 对于一段标记的连续异常区间:如果异常检测算法在该连续异常区间开始后的不晚于T 个时间点内检测到了该连续异常区间,则认为此异常检测算法成功地检测到了整段连续异常区间,因此该异常区间内的每一个异常点都算作一次true positive(TP);否则,该连续异常区间内的每一个异常点都算作一次false negative(FN)。
• 对于一个没有标记异常的时间点:如果异常检测算法输出了异常,计做一次false positive (FP);否则,计做一次true negative (TN)。
而异常检测的效果分数可以使用F-score来计算:

公式中的下标io表示面向区间的(interval-oriented)评价指标。
1.3 传统异常检测的训练方案
传统的使用时间序列预测的异常检测方案中,存在两种常见的训练方式,一种是孤立使用每一个时间点或时间窗口进行训练,另一种是变点异常检测,即尝试检出一段异常的起点和终点。变点异常检测完全忽略了异常区间内部的点,当应用到机器学习中时,会由于人工标注的成本原因而导致能够使用的训练样本过少。因此,对于使用机器学习的AIOps来说,一般的做法仍是使用孤立的时间点或时间窗口进行训练,这种做法缺少针对异常区间内不同点的特点进行的进一步处理,对于异常区间标签的利用率不够高。
2. ALSR的设计和结构
2.1 总体设计
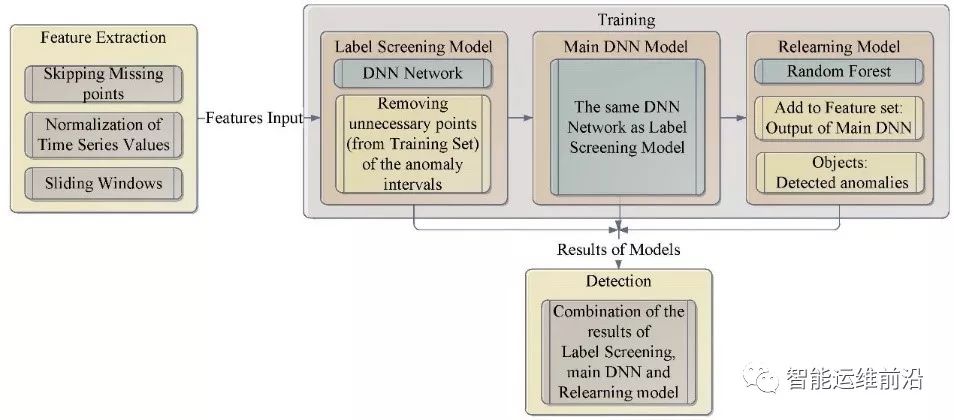
图 3 ALSR的结构
基于对连续区间异常检测的思考,文章提出了自适应的标签筛选与再学习异常检测方案(ALSR)。ALSR是一种分阶段的异常检测方案,它的训练和检测过程主要分三个部分:标签筛选模型、基础DNN模型以及再学习模型。其中,标签筛选模型主要针对连续异常区间的特点,将异常区间中少部分不能展现出异常特征的点移除,使得后续模型对于区间内的异常特征有更准确的识别。基础DNN模型则使用基于深度神经网络设计的全连接结构,负责进行正常/异常点的分类工作。最后的再学习模型则是在小范围内对上一步被检出的异常做进一步的筛查,以便去除可能存在的少量假正例。
2.2 特征提取
文章使用长度为W的滑动窗口进行特征提取。并主要提取以下四类特征:
值:KPI的原始值
统计特征:均值、方差、一阶差分等
时间序列预测特征:EWMA,AR预测
小波分析特征:DB2小波
2.3 基础DNN模型
基础DNN模型是一个三层的全连接网络,它是文章中的基本分类器,位置处于三个分类阶段的中间。该模型具有适当和深度和较好的泛化性能。在上文所述的特征集上能够取得较好的分类效果。
2.4 标签筛选模型
文章中提出了一种基于分类的标签筛选模型,该模型主要针对连续异常区间的特点,对同一个异常区间内具有不同特点的数据点进行区分处理。
标签筛选是ALSR分类器的第一个步骤。它利用提取的特征集先进行一次训练和分类,并在训练集上将分类结果分为TPpo、FPpo、TNpo、FNpo四类。下标”po”代表这种对结果分类是面向点的而非面区间的。
在标签筛选模型的训练之后,被认为是区间中非必要的异常点将会被从训练集中移除。
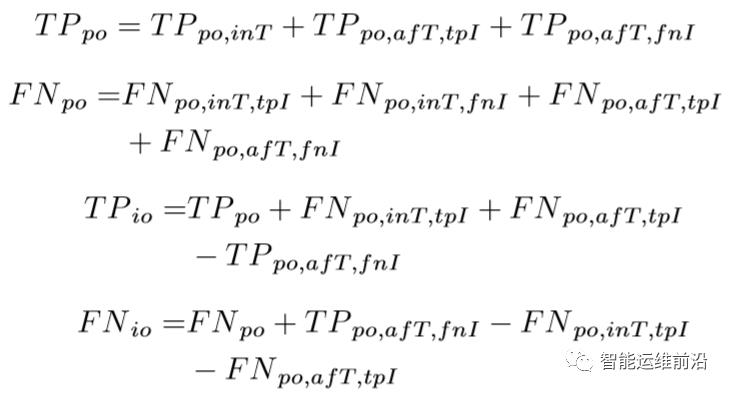
上述公式分析了面向区间和面向点的判断标准中,TP以及FN的不同。其中,下标“inT”和“afT”分别表示在异常区间开始的T个点之内/之外的点。而”tpI”和”fnI”则分别代表该点所在的异常区间包含/不包含TPpo,inT点。
而FP和TN点在两种评价标准中代表相同的含义。
FNpo,inT,tpI 和FNpo,afT,tpI点在面向点的评价标准中被分类为FNpo,但在面向区间的评价标注中被分类为TPio。标签筛选模型具有和基础DNN模型相同的网络结构,作为一个实际的正常/异常分类器,它本身具有不错的分类能力,只会误分类一些本身比较模糊的异常点。文章采取了以下两种措施来处理这种误分类。
A. 只有FNpo,afT点被认为是异常区间中非必要的点并将被从原始的训练集中移除。这是因为在异常区间的前T个点之内的点对于判断异常区间的开始比较重要。
B. 筛选过的训练集将会被用于基础DNN模型的训练。但是标签筛选模型的分类结果也同样会被保留。两项结果被综合在一起,以保证标签筛选的有效性、并且尽量有效利用有限的异常点。
标签筛选的算法如下所示:

2.5 再学习模型
标签筛选模型和基础DNN模型都是正常/异常分类器。与此不同,再学习的对象是基础DNN模型检出的异常点。这些检出的异常大部分都对应真实的异常,但其中仍然有一些不应该出现的假正例点,这就为使用再学习算法提供了可能。
ALSR中的再学习主要使用基础DNN模型分类之后获得的TPpo和FPpo点进行学习,也就是说它是一个假正例/真正例的分类器。理想情况下,再学习模型应该能够检出所有的FNpo点,并且不影响任何的TPpo点。但是实际上,这种再分类仍然会导致一定的错误,即FNpo点的增加。这个问题在面向区间的异常检测中是被最小化的,因为除了FNpo,inT,fnT点之外,其他的FNpo点并不影响对于连续异常区间的判断。事实上,FNpo,inT,tpI和FNpo,afT,tpI点在面向区间的异常检测中都被分类为TPio点。
对于再学习模型使用的训练集的获取,存在关于数据量的问题,因为对于不同的KPI,基础DNN分类得到的TPpo和FPpo的数量和比例都不确定。为了解决这个问题,文章将再学习模型训练集采样到一个特定的数组,并且在其中加入少量的TNpo点作为辅助类,以获得更好的表现效果。再学习模型的训练集按照以下进行采样。
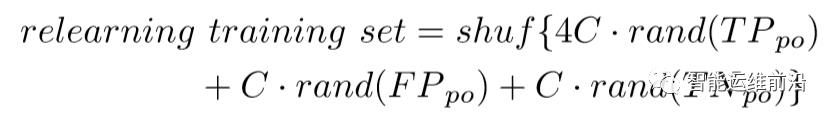
经过实验,再学习模型使用随机森林(random forest, RF)算法,这种算法在实验中具有运算速度快,准确度高的优点。
3. 效果评估
3.1 总体表现
文章使用F-score和AUCPR两种标准来衡量检测效果,并使用如下的分类器作为对比:
支持向量机模型(Support Vector Machine, SVM),长短期记忆网络(Long Short-Term Memory, LSTM),随机森林算法,以及Opprentice[2],一种使用14类基础分类器提取特征并使用随机森林进行分类的算法。
实验在强周期型KPI、稳定型KPI和波动型KPI上进行。PR曲线如图4所示。
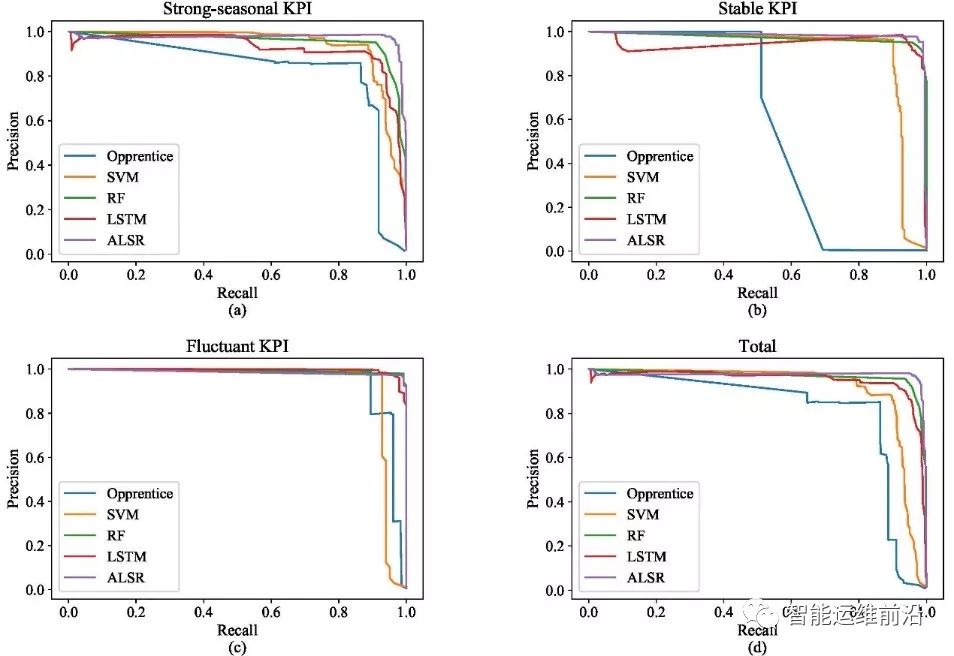
图 4 Opprentice, SVM, RF, LSTM和ALSR的PR曲线
可以看到,ALSR在强周期型和稳定型KPI上的PR曲线更接近右上角,而LSTM和RF在波动型KPI上的表现稍微占优。这证明了ALSR与对比实验相比,通常能够达到更好或至少接近相等的表现效果,考虑到多类别KPI的检测,ALSR具有更好的稳定性。
F-score和AUCPR的对比如图5和图6所示。ALSR在总体数据集上的F-score是0.965,AUCPR是0.978,均优于其他几种算法。
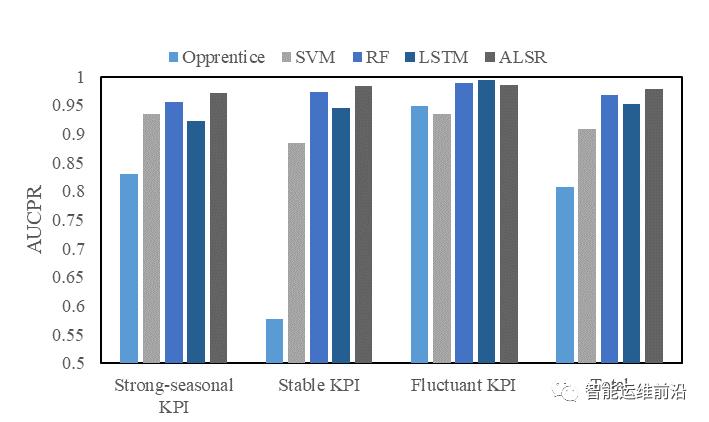
图 5 对比实验的AUCPR
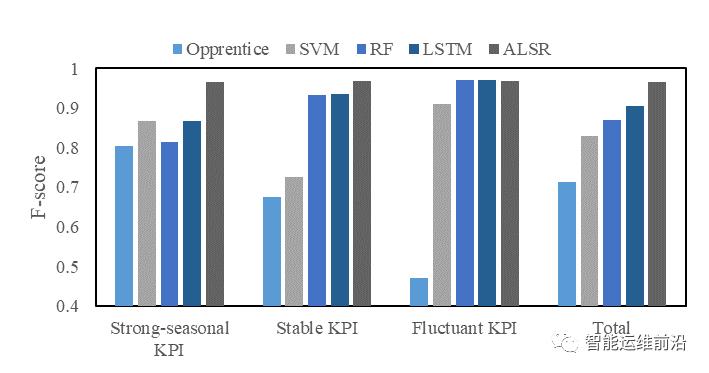
图 6对比实验的F-score
3.2 特征提取
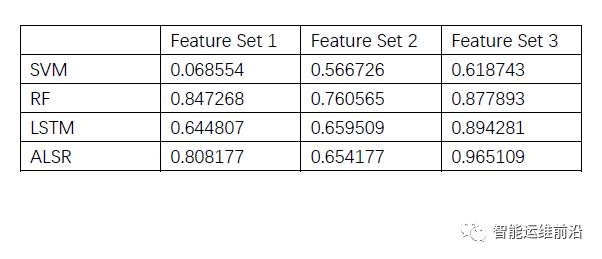
ALSR中使用的12项特征被作为特征集3,与滑动窗口直接获得的值(特征集1)和[3]中使用的特征集(特征集2)进行了对比,如图7所示。其中A、B、C分别代表强周期型、稳定型和波动型KPI。可以看到,特征集1和2对于某些KPI不能起到很好的提取特征效果,并且获得了很低的F-score,而ALSR则在全部KPI上有比较稳定的表现效果。三个特征集在SVM,RF,LSTM和ALSR上的表现也在表1中进行了对比。
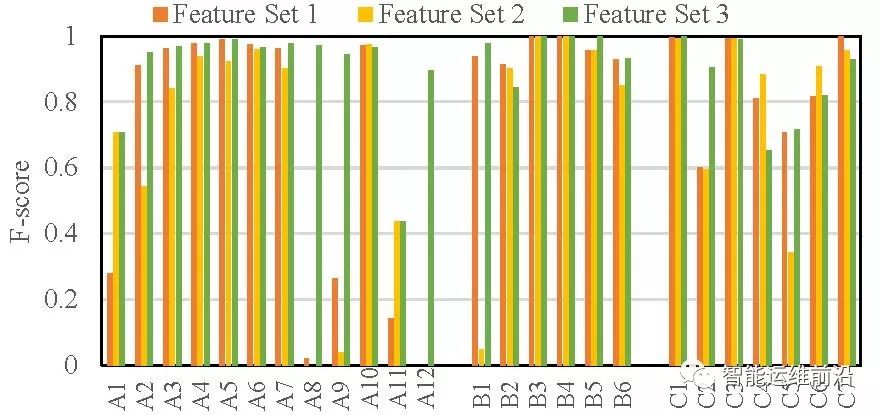
图 7 使用特征集1, 2, 3的ALSR在25条KPI上的对比实验
表 1 SVM, RF, LSTM和ALSR分别使用特征集1, 2, 3的表现
3.3 标签筛选和再学习技术的效果
文章ALSR中使用的两种技术:标签筛选和再学习方案也进行了实验。基础DNN与不同技术相结合的效果如图8所示。
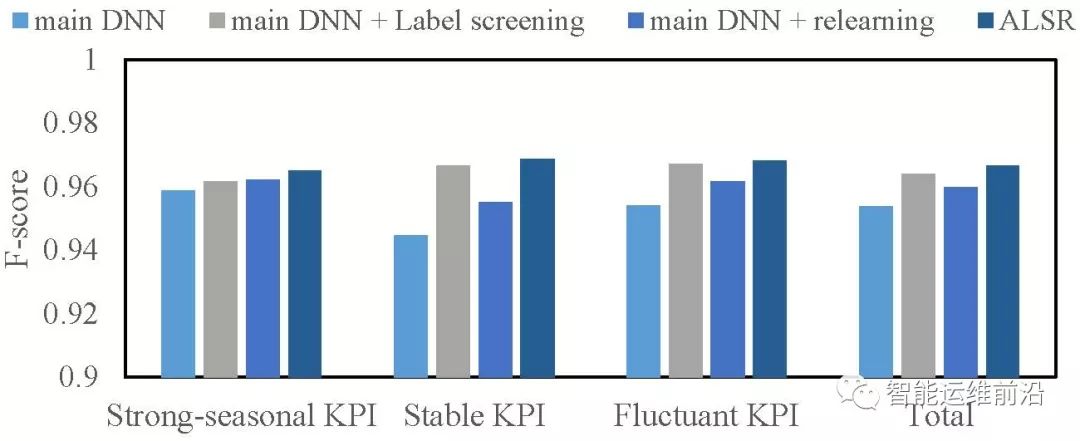
图 8 不同ALSR技术组合的表现
其中,标签筛选技术获得了更多的表现提升,而稳定型KPI是受到影响最大,可能因为其中存在着更多的较长KPI区间,而标签筛选自然地去除了长异常中大量无用的异常点,因而获得了更好的表现效果。
再学习模型的表现提升稍少,这是由于它工作在更小的范围上,从而影响的范围也更小。但是这种轻量级的增强方案能够使用很小的开销在存在TPio和FPio的环境中稳定提供一定的效果提升。
两种技术能够在ALSR中被有效结合在一起使用。
3.4 滑动窗口长度W和时延T的选择
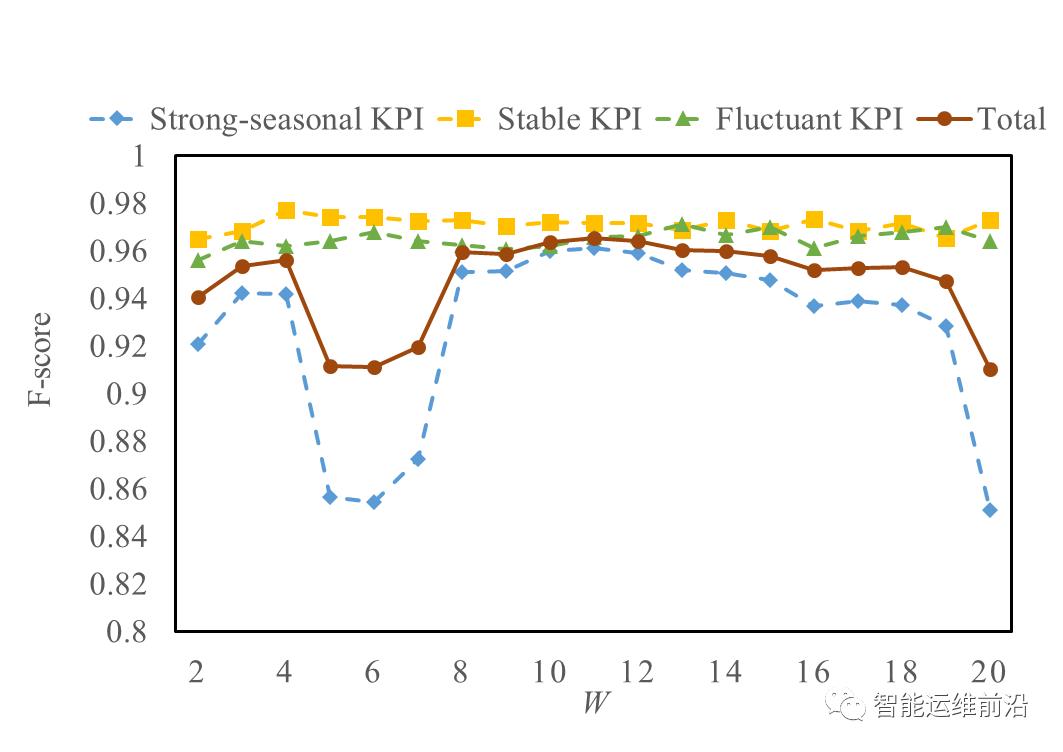
图 9 F-score随滑动窗口长度W的变化
图 10 F-score随异常检测准许时延T的变化
4. 结论
论文信息:
Jingyu Wang, Yuhan Jing, Qi Qi, Tongtong Feng, Jianxin Liao, ALSR: An Adaptive Label Screening and Relearning Approach for Interval-Oriented Anomaly Detection, Expert Systems With Applications. 136: 94-104, (2019).
个人主页:
https://teacher.bupt.edu.cn/wangjingyu
介绍世界范围内智能运维的前沿进展
推动智能运维算法在实践中落地和普世化
以上是关于北邮AIOps新作:连续区间多类型KPI异常检测的主要内容,如果未能解决你的问题,请参考以下文章