科普丨神经网络算法Batch Normalization的分析与展望
Posted 人工智能新时代
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了科普丨神经网络算法Batch Normalization的分析与展望相关的知识,希望对你有一定的参考价值。
作者罗恒,地平线技术资深算法研究员。2011年博士毕业于上海交通大学,后随Yoshua Bengio从事博士后研究,2014年加入百度深度学习实验室,参与深度学习在搜索中应用、PaddlePaddle研发等工作。2016年加入地平线机器人公司,负责深度学习模型压缩与加速。

训练更深的近年来一直是深度学习领域的重要趋势之一,2015年初Google提出的Batch Normalization 算法使得深层神经网络训练更加稳定,加快了收敛的速度,甚至同时起到了正则化的作用。本期罗老师将为大家分析Batch Normalization背后的动机和原理,以及后续的发展。
1.引言
现在正是神经网络的第三次研究的热潮,与之前两次不同,这次神经网络(深度学习)在很多实际问题上取得了巨大的成功,吸引了越来越多的人投身其中。
Batch Normalization [1] 是近年来最火爆的tricks之一,几乎成了前向神经网络的标配。在我看来,BN主要做的比较好的是在恰当的地方做标准化(Normalization),在矩阵乘之后,在激活之前;BN的参数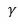 和
和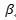 使得输出仍旧保持一定的灵活性;为什么这两方面比较重要下面我会做些分析。最后我会简单讨论一些把BN应用到RNN的工作。
使得输出仍旧保持一定的灵活性;为什么这两方面比较重要下面我会做些分析。最后我会简单讨论一些把BN应用到RNN的工作。
2. 升降桌和中心极限定理

我现在试用的电动升降桌,前面的数字是桌面的高度,精确到毫米,那两个三角可以调节升还是降,但是经常调完了之后出现“78.3”、“77.9”之类的数字,而我更喜欢整数“78”,我最常用的策略就是当接近78的时候,交替地(为了对符号均匀采样)快速地按(力争每次按击独立)上升、下降,很快数字就会停到了78。这是因为按照中心极限定理,我压了一堆均值接近0的随机数(+0.1, -0.2, +0.3之类的),那么这些随机数的累加和(桌子的最终高度)会服从正态分布,我会很大概率见到0,也就是整数的高度。这里也就引出了今天介绍Batch Normalization的一个角度,一些随机数的累加和很可能服从正态分布(Normal distribution),中心极限定理。
3. 神经网络训练困难的一个例子
神经网络很多年了,一个很大的困难在于比较难训练。比较难训练的一个可能原因在于,神经网络高度冗余,同一个函数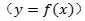 我们可以找到很多很多参数不同的网络来确切的等价于这个函数,而这些不同参数的网络有的优化起来很容易,有的则非常困难。比如这样一个函数,
我们可以找到很多很多参数不同的网络来确切的等价于这个函数,而这些不同参数的网络有的优化起来很容易,有的则非常困难。比如这样一个函数,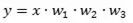
(这是个线性函数,里面没有非线性变换,主要是为了简单。不过当我们用ReLU作为激活函数,当都是正的,当输入也是正的,下面的分析也都可以保持正确),我们发现,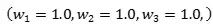 和
和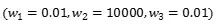 表达的函数完全一样,但是当我们做sgd的时候后者的优化会变得十分困难。假如些X=1,损失函数传来的梯度是
表达的函数完全一样,但是当我们做sgd的时候后者的优化会变得十分困难。假如些X=1,损失函数传来的梯度是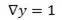 (损失函数希望网络能输出个小的y),对于第二组参数代表的网络求得的梯度为
(损失函数希望网络能输出个小的y),对于第二组参数代表的网络求得的梯度为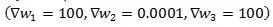 ,如果拿这个去更新第二组参数,那么数值小的参数改变巨大,大的参数则几乎不变,训练过程将会变得非常不稳定。
,如果拿这个去更新第二组参数,那么数值小的参数改变巨大,大的参数则几乎不变,训练过程将会变得非常不稳定。
4. BN的动机和成功的原因
训练神经网络,通常是用反向传播算法(BP)+随机梯度下降(SGD),具体到一个具体的第L层连接神经元i和神经元j的参数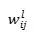 的更新就是
的更新就是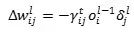 ,通常我们会希望这个更新比较稳定。因此,首先有很多的工作在于选择自适应的学习率
,通常我们会希望这个更新比较稳定。因此,首先有很多的工作在于选择自适应的学习率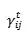 ,对于上面的例子如果我们能够找到非常适合的各个参数大小不同的学习率,训练过程依旧可以变得很稳定;其次,也有些tricks可以看做稳定从网络上层回传的错误
,对于上面的例子如果我们能够找到非常适合的各个参数大小不同的学习率,训练过程依旧可以变得很稳定;其次,也有些tricks可以看做稳定从网络上层回传的错误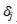 ,比如随机shuffle训练数据,当样本不均衡时做些采样;第三类工作则是稳定
,比如随机shuffle训练数据,当样本不均衡时做些采样;第三类工作则是稳定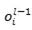 (其中
(其中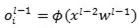 ,
,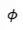 是某个非线性函数)。之前有过工作直接对来标准化,效果有限。BN的结果之所以更好,可能作对了两个地方,第一,正像我们之前讲的,一堆随机数的和(
是某个非线性函数)。之前有过工作直接对来标准化,效果有限。BN的结果之所以更好,可能作对了两个地方,第一,正像我们之前讲的,一堆随机数的和(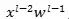 )更接近一个正态分布,在这个和上来做标准化更加容易使得
)更接近一个正态分布,在这个和上来做标准化更加容易使得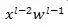 通过非线性之后依然保持稳定,对于使用sigmoid非线性的时候,对于一个mini batch而言大概接近68%的值在[0.27 0.73]之间,95%的值在[0.12 0.88]之间,这当然很好,基本都在sigmoid函数的线性部分,不会出现饱和的情况(这里的梯度不会接近0),这样的好处就是训练在一开始可以变得很快,如下图。但是问题在于假如
通过非线性之后依然保持稳定,对于使用sigmoid非线性的时候,对于一个mini batch而言大概接近68%的值在[0.27 0.73]之间,95%的值在[0.12 0.88]之间,这当然很好,基本都在sigmoid函数的线性部分,不会出现饱和的情况(这里的梯度不会接近0),这样的好处就是训练在一开始可以变得很快,如下图。但是问题在于假如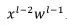 真的始终是接正态分布,那么这些神经元就很难达到它的饱和区域。
真的始终是接正态分布,那么这些神经元就很难达到它的饱和区域。
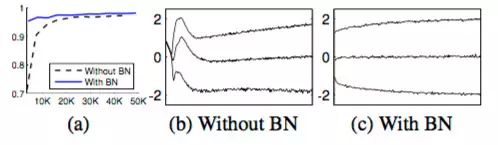
BN的作者引入的可能是为了解决这个问题,但是我觉得可能很难,从的梯度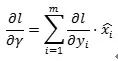 可以看出,这个梯度可能会在一个mini batch内相互抵消,从而变得很小(有兴趣的同学可以做实验看看是不是会比较小)。当然也可能通过在开始初始化的时候把直接设成比较适合的值,不过这就是另一个问题了。从上图也可以看出,似乎模型的在MNIST上也是underfitting,是否是上面说的原因呢?
可以看出,这个梯度可能会在一个mini batch内相互抵消,从而变得很小(有兴趣的同学可以做实验看看是不是会比较小)。当然也可能通过在开始初始化的时候把直接设成比较适合的值,不过这就是另一个问题了。从上图也可以看出,似乎模型的在MNIST上也是underfitting,是否是上面说的原因呢?
不过BN的设计的背景本身就是为了很深的网络+ReLU这类激活函数。换句话说是如何使得深层ReLU网络在较大学习率的情况下训练保持稳定。那么我们在ReLU的情况下继续讨论,假设来自正态分布,标准化之后(0均值1方差),那么总会有一半左右的数据通过ReLU之后为0,也就是说当前这个神经元对于后续的计算不在起作用了(但是还是会有关于这些样本的梯度传回)。BN的作者引入的可能是为了解决这个问题,从的梯度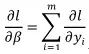 可以看出,如果有更多的错误传来,则会变小,从而允许更多的样本向上传递非零的信号。在训练过程中把神经元的平均的非零可视化出来可能也会比较有意思。从这里的分析,也可以看出来,BN网络相对而言更加需要全局的彻底的随机shuffle,如果没有彻底的shuffle,几条样本总是出现在同一个mini batch中,那么很可能有些样本对于在经过标准化之后,在很多神经元的输出总是零,从而难以将信号传递到顶层。这可能就是为什么[1]提到增加了shuffle之后,结果在验证集上有所变好。同时这也可能为什么当使用了BN+随机shuffle之后dropout的作用在下降的一个原因,因为数据随机的组合,利用mini batch统计量标准化之后,对于特定样本的特定神经元可能随机地为0,那么和dropout的机制有类似的地方。但是如果使用很大的mini batch又会如何呢?
可以看出,如果有更多的错误传来,则会变小,从而允许更多的样本向上传递非零的信号。在训练过程中把神经元的平均的非零可视化出来可能也会比较有意思。从这里的分析,也可以看出来,BN网络相对而言更加需要全局的彻底的随机shuffle,如果没有彻底的shuffle,几条样本总是出现在同一个mini batch中,那么很可能有些样本对于在经过标准化之后,在很多神经元的输出总是零,从而难以将信号传递到顶层。这可能就是为什么[1]提到增加了shuffle之后,结果在验证集上有所变好。同时这也可能为什么当使用了BN+随机shuffle之后dropout的作用在下降的一个原因,因为数据随机的组合,利用mini batch统计量标准化之后,对于特定样本的特定神经元可能随机地为0,那么和dropout的机制有类似的地方。但是如果使用很大的mini batch又会如何呢?
除了上面提到的在适合的地方做标准化、使用和保持灵活性之外,BN把均值和方差的计算也看作整个运算的一部分(参与梯度的计算),从而避免了反向过程中梯度试图改变均值和方差,然而前向过程的BN层又会取消梯度的这些企图。
5. 应用BN到RNN的一些工作
BN之后,很快就开始有一些工作尝试在RNN中加入BN。首先我们来看RNN,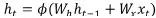 ,其中的激活函数常用的tanh。在[2]中先尝试了直接加入BN,
,其中的激活函数常用的tanh。在[2]中先尝试了直接加入BN,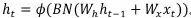 ,结果不好,即使是在训练集也会略差(直接加入BN后模型的优化、拟合都出了问题)。[2]又改为
,结果不好,即使是在训练集也会略差(直接加入BN后模型的优化、拟合都出了问题)。[2]又改为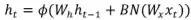 ,overfitting(训练集好,验证集差)。我的理解在于
,overfitting(训练集好,验证集差)。我的理解在于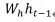 和
和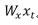 可能是很不同的正态分布,他们求和之后再做标准化,可能会有害处。[3]中进一步做了如下调整,
可能是很不同的正态分布,他们求和之后再做标准化,可能会有害处。[3]中进一步做了如下调整,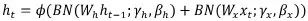 ,这样将两个不同的正态分布分别标准化再相加就合理多了。同时[3]中还有两个tricks,第一,不再初始化为1而是初始化为比较小的数,如0.1。我估计这个可能和LSTM中大量的sigmoid和tanh有关(有兴趣的同学可以自己分析看看);第二,不同的时间步t各自统计自己的mean和std,这个可能对于之前overfitting的一个回应,就是说工作[2]中overfitting的原因在于训练的时候用来做标准化的统计量(每层每个mini batch计算得到)和测试的过程中使用的统计量(使用训练中各层共享的、不断地做moving avearge的统计量)显著不同。
,这样将两个不同的正态分布分别标准化再相加就合理多了。同时[3]中还有两个tricks,第一,不再初始化为1而是初始化为比较小的数,如0.1。我估计这个可能和LSTM中大量的sigmoid和tanh有关(有兴趣的同学可以自己分析看看);第二,不同的时间步t各自统计自己的mean和std,这个可能对于之前overfitting的一个回应,就是说工作[2]中overfitting的原因在于训练的时候用来做标准化的统计量(每层每个mini batch计算得到)和测试的过程中使用的统计量(使用训练中各层共享的、不断地做moving avearge的统计量)显著不同。
另外一个在RNN中做Normalization比较重要的工作是[4]。Layer Normalization与BN的机制似乎不太相同,这里不展开分析了。LN除了可以作用在RNN之外,也可以用于前向全连接的网络,论文也也给出了比较试验,如下图,
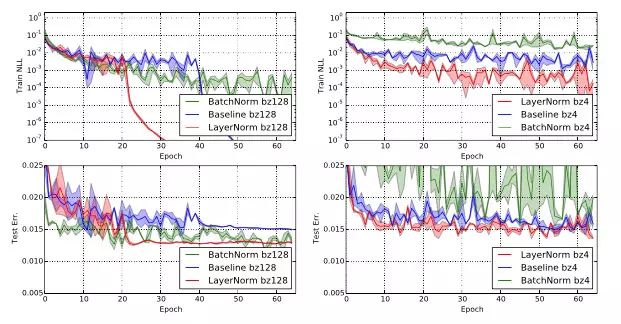
从右边的图可以看出太小的mini batch对于BN无论是在训练的过程和测试过程中使用训练过程统计的统计量都造成了危害。从左边的图则可以看出,由于LN是对每条样本做标准化从而失去了上面讨论的BN带来的正则化效果。
以上是关于科普丨神经网络算法Batch Normalization的分析与展望的主要内容,如果未能解决你的问题,请参考以下文章