机器学习之从logistic到神经网络算法
Posted 机器学习与大数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之从logistic到神经网络算法相关的知识,希望对你有一定的参考价值。
阅读本文大约需要8分钟
上节介绍过logistic回归与分类算法,并对线性与非线性数据集分别进行分类实验。Logistic采用的是一层向量权值求和的方式进行映射,所以本质上只能对线性分类问题效果较好(实验也可以看到),
其模型如下所示:
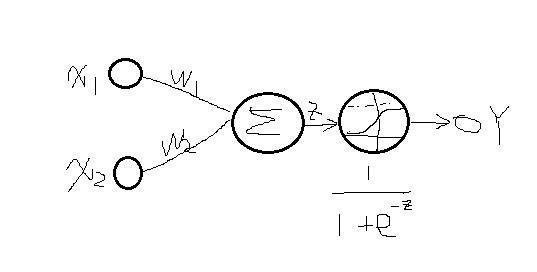
既然如此,我们可不可以在Y出来之前在多进行几次映射呢?答案是可以的,这就引出了多层网络,每层网络的输出后再进行sigmod映射到0-1之间,那么它就是神经网络系统了。比如上面的多加几层就可以表示为:
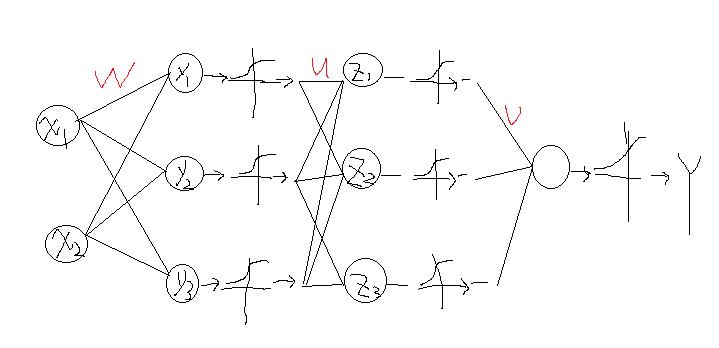
同样样本的输入从最左端开始,通过权值w矩阵计算得到第一层y值,得到的结果分别进行sigmod函数映射作为第二层的输入,然后经过权值矩阵u得到z,在进行映射,依次类推最终得到输出Y,那么这个多层网络和上面的单层相比有哪些不同?
首先可以看到最终输出Y和输入(x1,x2)已经不再是简单的权值相乘再映射了,而是权值相乘后映射,然后再权值相乘映射,再相乘映射最终得到Y,那么Y与(x1,x2)的关系在网络前后早已经不再是线性关系了,是什么关系,谁知道了。
可能会说,像这样的网络,为什么多加了两层?不是还可以继续增加吗?每层里面为什么是3个节点?不是还可以增加吗?没错,上述的层数以及每层的个数都可以增加,这就是神经网络的需要设计之处,每增加一层以及每层的节点数,网络的关系就会发生变化,至于变成什么样子,不用管,至于究竟用多少层多少个节点,那就看实际效果。这就涉及到神经网络的深层讨论范畴。
先说该网络,在一个网络确定后(什么叫确定?就是网络上的所有权值系数都知道)显然Y与(x1,x2)是一种非线性关系,可以简单的看到,上述y1,y2,y3分别与(x1,x2)有关,z1,z2,z3分别于y1,y2,y3有关,而最终的Y又分别与z1,z2,z3有关,在多层迭代后,Y就可以用(x1,x2)的非线性复合关系表示出来了。一般来说,这个网络是可以表示任意的非线性关系的。
在已知这样一个网络的所有参数以后,那么给定一个输入,得到输出是非常快的,就是一直正向计算,而计算机做这件事很轻松,所以说训练好的神经网络是一种非常快的分类方法。然而这个网络参数的训练过程却并不是那么轻松愉快。
经过上述的说明,我们已经知道神经网络的强大(表示任意的非线性关系的)。那么下面的问题就是如何训练这个网络。
在logistic分类算法中,我们知道,那样一个一层网络权值参数是通过结果与预测结果的误差值,通过梯度下降法不断调整权值参数的。那么这个多层网络呢?同样采用这种方法来实现,不同的是,这里需要一层一层的计算。
首先我们设定好隐含层以及每层的节点数,然后构造一个权值随机的网络,对于训练样本的每一个样本输入就会有一个输出值o,那么这个o与实际的值t会有一个误差e(既然是训练样本,一定会有一个目标分类结果t的),根据上图的结果可以看到,这个e将直接与最后一层的输入z’(sigmod出来的值)以及权值v相关,这样我们可以通过这个e来更新v,同时我们可以将这个误差e按照输入z’和权值v的大小分别分配到上一层的误差,也就是系统经过z后出来的误差值e1,e2,e3。(这个e1,e2,e3可以通过e、z、v计算出来)。这样我们可以根据e1,e2,e3来更新权值u,同理再上一层y层,我们同样会有一组误差e4,e5,e6,而e4,e5,e6又可以通过其后面网络的值来表示,这样再更新权值w,如果还有,再继续往前面传播。对于权值的更新以及误差,这种通过后面网络的结果往前面传播的方法,就是神经网络中的反向传播算法。
下面来简单说说关于误差怎么往后面传播的,同时权值的计算公式是怎么更新的。这部分一本书 《机器学习》(https://download.csdn.net/download/cser04/400323)的P74-P75上有详细的推导过程可以看看(考虑到两页公式,编辑公式实属不易就省了吧)。这里只给出最终的权值更新结果:
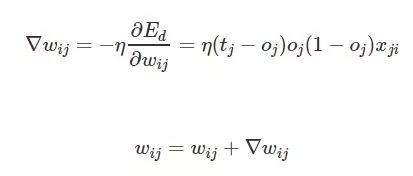
其中n(itea)一个步长系数,t是对应该层的输出,o是对应该层的目标值,x是对应该层的输入。那么对每一层网络用此公式进行权值更新,更新完后将新的权值再进行迭代算网络输出误差,并将这个误差再反向传播,更新权值,一直这样下去即可,下面是算法的伪代码(只是两层网络的结构,多层的话还得增加循环):

说了这么多可以进行实验了。实验之前首先是样本选择,这里人为产生两组数据集:线性与非线性,画出来就如下(每类100个样本,两类):
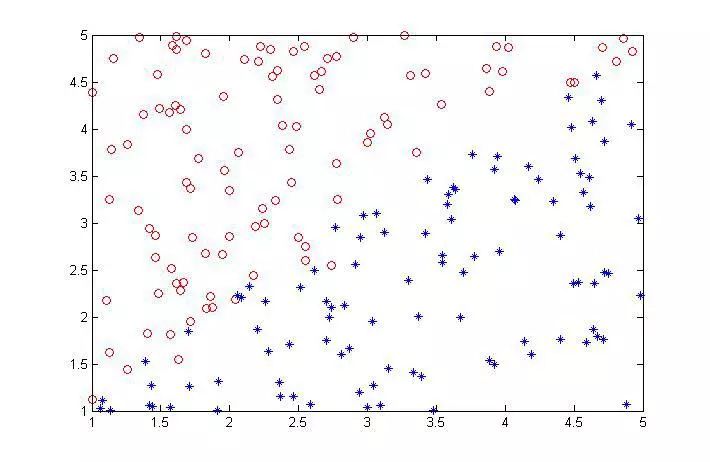
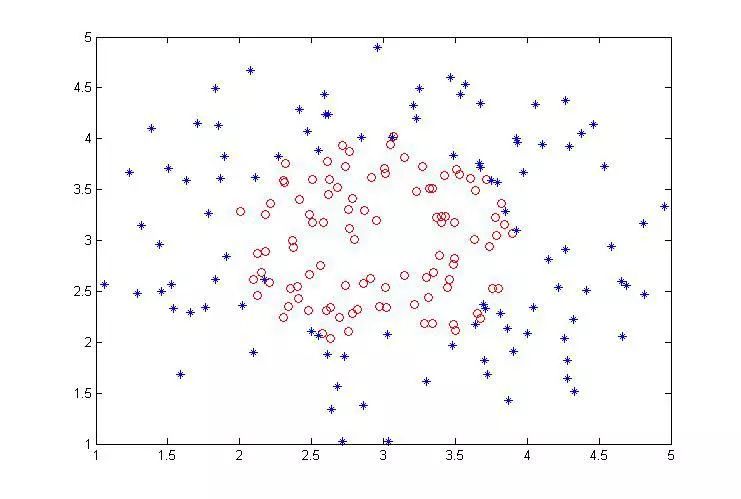
可以看到,线性与非线性里面的两类分界面人为设置了一些重叠(这些重叠是一般是不可能划出来的)。
下面构造网络,网络就采用最前面的那个含有2个隐含层、每层3个节点的网络,输入是二维数据正好,输出是一维数据(分类标签,也正好)。
代码如下:
%%
% * 神经网络分类设计
% * 简单0-1两类分类--线性与非线性分类
%
%%
clc
clear
close all
%% Load data
% * 数据预处理--分两类情况
% 并将标签重新设置为0与1,方便sigmod函数应用
data = load('data_test1.mat');
data = data.data';
%标签设置0,1
data(:,3) = data(:,3) - 1;
%选择训练样本个数
num_train = 50;
%构造随机选择序列
choose = randperm(length(data));
train_data = data(choose(1:num_train),:);
gscatter(train_data(:,1),train_data(:,2),train_data(:,3));
label_train = train_data(:,end);
test_data = data(choose(num_train+1:end),:);
label_test = test_data(:,end);
%% initial parameter
% 输入-输出的数据维度
num_in = size(train_data,2) - 1;
num_out = 1;%输出只有标签--1维
% 网络的权值参数
m = 2;%定义隐含网络层数
n = 3;%定义每层隐含网络节点
inta = 0.1;%学习步长
%% 初始化随机赋值网络权值
for i = 1:m+1
if i == 1 %输入层
w{i} = rand(n,num_in);
continue;
end
if i == m+1 %输出层
w{i} = rand(num_out,n);
continue;
end
w{i} = rand(n,n);
end
%% 训练网络
for gen = 1:1000
for i = 1:length(train_data)
%% 正向计算各个层节点的输出值
data_simple = train_data(i,1:end-1);
net1 = data_simple*w{1}';%第一层隐层各节点输入
h1 = 1./(1+exp(-net1));%得到隐层各节点输出
net2 = h1*w{2}';%第而层隐层各节点输入
h2 = 1./(1+exp(-net2));%得到隐层各节点输出
net3 = h2*w{3}';%输出层各节点输入
z = 1./(1+exp(-net3));
%% 反向计算各个输出层的误差delta
delta3 = (label_train(i) - z)*z*(1-z);%输出层的误差
for j = 1:3
delta2(j)=(delta3*w{3}(j))*h2(j)*(1-h2(j));
end
for j = 1:3
delta1(j)=(delta2*w{2}(:,j))*h1(j)*(1-h1(j));
end
%% 逐次更新网络的权值
% 第二层到输出层权值
for j = 1:3
w{3}(j) = w{3}(j) + inta*delta3*h2(j);
end
% 第1层到第2层权值
for j = 1:3
for k = 1:3
w{2}(j,k) = w{2}(j,k) + inta*delta2(j)*h1(k);
end
end
% 输入层到第1层权值
for j = 1:3
for k = 1:num_in
w{1}(j,k) = w{1}(j,k) + inta*delta1(j)*data_simple(k);
end
end
end%得到输出层各节点输出
end
%% 预测分类结果
predict = zeros(1,length(test_data));
for i = 1:length(test_data)
% 正向计算各个层节点的输出值
data_simple = test_data(i,1:end-1);
net1 = data_simple*w{1}';%第一层隐层各节点输入
h1 = 1./(1+exp(-net1));%得到隐层各节点输出
net2 = h1*w{2}';%第而层隐层各节点输入
h2 = 1./(1+exp(-net2));%得到隐层各节点输出
net3 = h2*w{3}';%输出层各节点输入
z = 1./(1+exp(-net3));
if z > 0.5
predict(i) = 1;
else
predict(i) = 0;
end
end
%% 显示结果
figure;
index1 = find(predict==0);
data1 = (test_data(index1,:))';
plot(data1(1,:),data1(2,:),'or');
hold on
index2 = find(predict==1);
data2 = (test_data(index2,:))';
plot(data2(1,:),data2(2,:),'*');
hold on
indexw = find(predict'~=(label_test));
dataw = (test_data(indexw,:))';
plot(dataw(1,:),dataw(2,:),'+g','LineWidth',3);
accuracy = length(find(predict'==label_test))/length(test_data);
title(['predict the training data and the accuracy is :',num2str(accuracy)]);神经网络的反向传播过程直接代码实现,没有使用到工具箱,可以对比公式理解。
相关的注释在程序中,更新迭代部分可能要对照公式(伪代码)才能理解是什么意思。
好了首先加载线性数据结果:
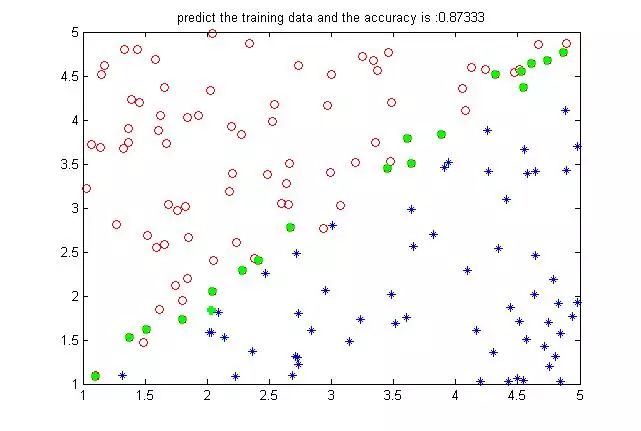
绿色的表示分错了。可以看到神经网络对于线性很轻松,设置1000此迭代足以。至于为什么还有分错的,我们说过,我在构造数据的时候特意在分界面上下设置了一些混杂数据,这些数据一般来说不可能分出来的。
下面进行非线性实验:
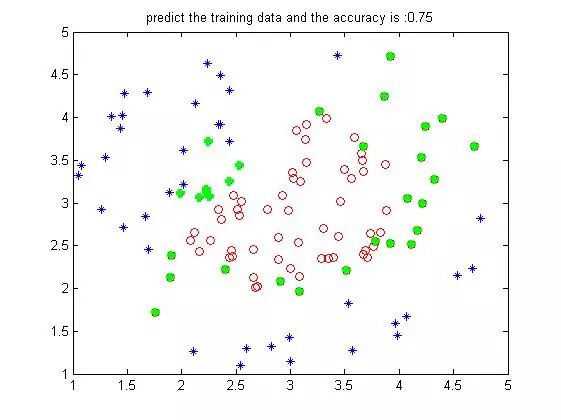
这是50个训练下150个测试样本在迭代10000次后的结果,结果的好坏与训练样本的个数,权值学习步长,迭代次数有很大的关系。说实话这个结果并不不是很理想,但是起码非线性的效果有了。我调整过参数,也增加了迭代次数,始终没有把准确率弄到80%以上。我觉得可能的原因是
首先这个程序是最简单基础的神经网络,学习步长是定值,权值更新无记忆性,这些都可以进一步的优化,就拿学习步长,迭代初期学习步长可以大点,后期,学习步长可以小点。权值更新也可以再加一个记忆性,就是将上一次的结果以一定的比例加到这一次的结果中。
还有一点就是关于样本输出值的问题,可以看到最终的输出值也是经过了sigmod函数变为0-1之间的,也就是说如果事先你的所有样本的目标值不在0-1之间,网络就不会有正负反馈的(要么都是正反馈,要么都是负反馈),不可能找到正确的网络参数。当然我这里样本目标输出是变化到0,1,也就是类标签,很极限,不知道有没有这个原因导致结果的准确性,其实我感觉理想结果是分类面会出来一个圆的,虽然是基础神经网络,但是毕竟是神经网络,至于为什么差了那么一点,你知道原因吗?
往期精彩资料分享:
扫描加入交流群
以上是关于机器学习之从logistic到神经网络算法的主要内容,如果未能解决你的问题,请参考以下文章