GPU学习DL系列:Tensorflow 简明原理
Posted 景略集智
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPU学习DL系列:Tensorflow 简明原理相关的知识,希望对你有一定的参考价值。
这是《GPU学习深度学习》系列文章的第二篇,主要介绍了 Tensorflow 的原理,以及如何用最简单的Python代码进行功能实现。本系列文章主要介绍如何使用 腾讯云 GPU 服务器进行深度学习运算,前面主要介绍原理部分,后期则以实践为主。
本文所有出现的代码,均可通过点击阅读原文前往集智主站原贴内运行,欢迎来试试~
往期内容:
1. 神经网络原理
神经网络模型,是上一章节提到的典型的监督学习问题,即我们有一组输入以及对应的目标输出,求最优模型。通过最优模型,当我们有新的输入时,可以得到一个近似真实的预测输出。
我们先看一下如何实现这样一个简单的神经网络:
输入 x = [1,2,3],
目标输出 y = [-0.85, 0.72]
中间使用一个包含四个单元的隐藏层。
-
结构如图:
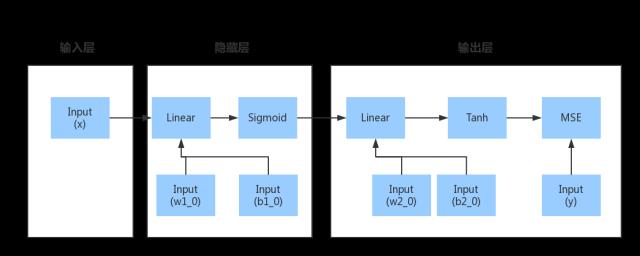
求所需参数 w1_0 w2_0 b1_0 b2_0, 使得给定输入 x 下得到的输出 ,和目标输出 y^ 之间的平均均方误差 (Mean Square Errors, MSE) 最小化 。
我们首先需要思考,有几个参数?由于是两层神经网络,结构如下图,其中输入层为 3,中间层为 4,输出层是 2:
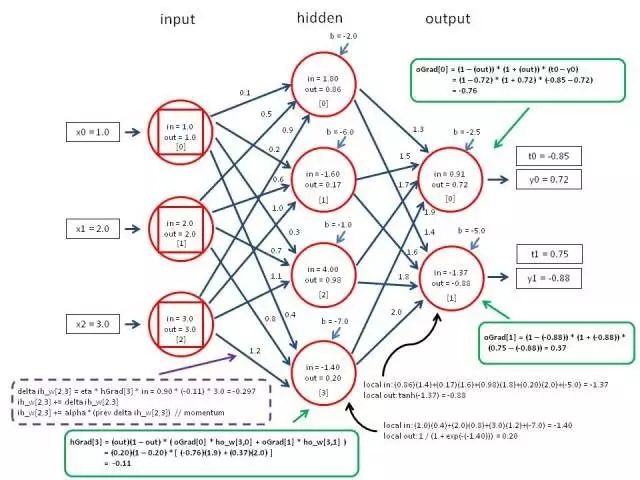
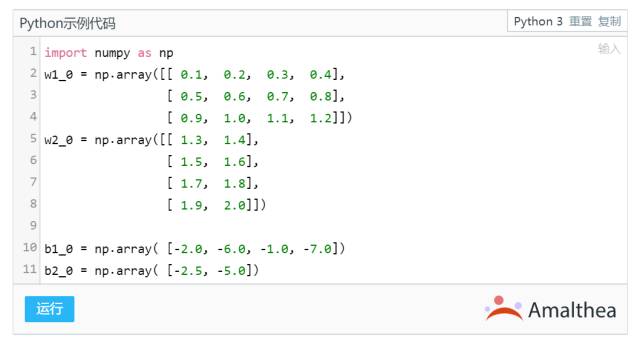
因此,其中总共包含 (3x4+4) + (4*2+2) = 26 个参数需要训练。我们可以如图初始化参数。参数可以随机初始化,也可以随便指定:
我们进行一次正向传播:
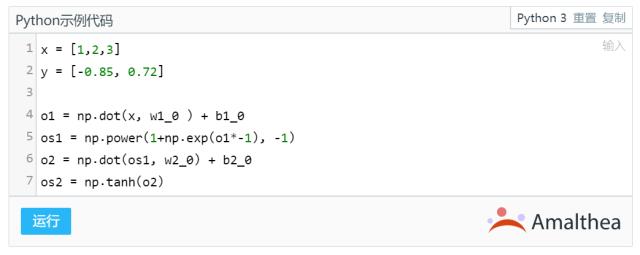
再进行一次反向传播:
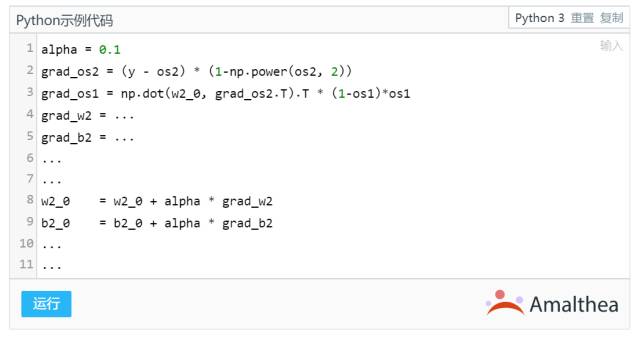
如此反复多次,直到最终误差收敛。进行反向传播时,需要将所有参数的求导结果都写上去,然后根据求导结果更新参数。我这里就没有写全,因为一层一层推导实在是太过麻烦。更重要的是,当我们需要训练新的神经网络结构时,这些都需要重新推导一次,费时费力。
然而仔细想一想,这个推导的过程也并非无规律可循。即上一级的神经网络梯度输出,会被用作下一级计算梯度的输入,同时下一级计算梯度的输出,会被作为上一级神经网络的输入。于是我们就思考能否将这一过程抽象化,做成一个可以自动求导的框架?OK,以 Tensorflow 为代表的一系列深度学习框架,正是根据这一思路诞生的。
2.深度学习框架
近几年最火的深度学习框架是什么?毫无疑问,Tensorflow 高票当选。
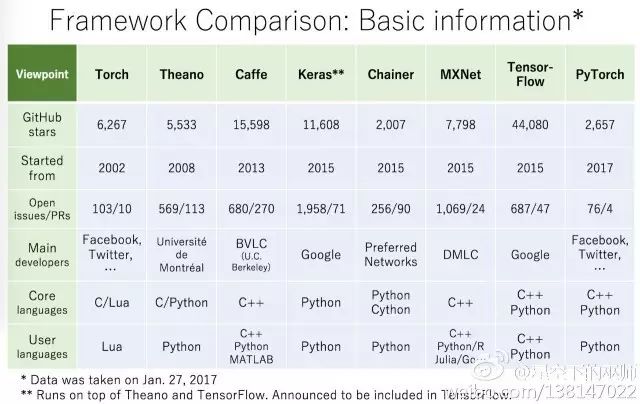
但实际上,这些深度学习框架都具有一些普遍特征。Gokula Krishnan Santhanam认为,大部分深度学习框架都包含以下五个核心组件:
张量(Tensor)
基于张量的各种操作
计算图(Computation Graph)
自动微分(Automatic Differentiation)工具
BLAS、cuBLAS、cuDNN等拓展包
其中,张量 Tensor 可以理解为任意维度的数组——比如一维数组被称作向量(Vector),二维的被称作矩阵(Matrix),这些都属于张量。有了张量,就有对应的基本操作,如取某行某列的值,张量乘以常数等。运用拓展包其实就相当于使用底层计算软件加速运算。
我们今天重点介绍的,就是计算图模型,以及自动微分两部分。首先介绍以 Torch 框架为例,谈谈如何实现自动求导,然后再用最简单的方法,实现这两部分。
2.1. 深度学习框架如何实现自动求导
诸如 Tensorflow 这样的深度学习框架的入门,网上有大量的 几行代码、几分钟入门这样的资料,可以快速实现手写数字识别等简单任务。但如果想深入了解 Tensorflow 的背后原理,可能就不是这么容易的事情了。这里我们简单的谈一谈这一部分。
我们知道,当我们拿到数据、训练神经网络时,网络中的所有参数都是 变量。训练模型的过程,就是如何得到一组最佳变量,使预测最准确的过程。这个过程实际上就是,输入数据经过 正向传播,变成预测,然后预测与实际情况的误差 反向传播 误差回来,更新变量。如此反复多次,得到最优的参数。这里就会遇到一个问题,神经网络这么多层,如何保证正向、反向传播都可以正确运行?
值得思考的是,这两种传播方式,都具有 管道传播 的特征。正向传播一层一层算就可以了,上一层网络的结果作为下一层的输入。而反向传播过程可以利用 链式求导法则,从后往前,不断将误差分摊到每一个参数的头上。
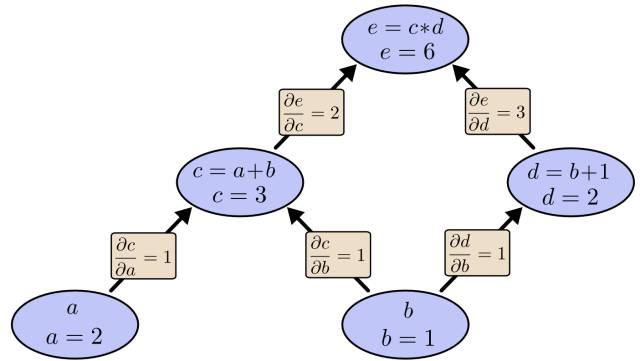
进过抽象化后,我们发现,深度学习框架中的 每一个模块都需要两个函数,一个连接正向,一个连接反向。这里的正向和反向,如同武侠小说中的 任督二脉。而训练模型的过程,数据通过正向传播生成预测结果,进而将误差反向传回更新参数,就如同让真气通过任督二脉在体内游走,随着训练误差逐渐缩小收敛,深度神经网络也将打通任督二脉。
接下来,我们将首先审视一下 Torch 框架的源码如何实现这两部分内容,其次我们通过 Python 直接编写一个最简单的深度学习框架。

举 Torch 的 nn 项目的例子是因为Torch 的代码文件结构比较简单,Tensorflow 的规律和Torch比较近似,但文件结构相对更加复杂,有兴趣的可以仔细读读相关文章。
Torch nn 模块Github 源码 这个目录下的几乎所有 .lua 文件,都有这两个函数:

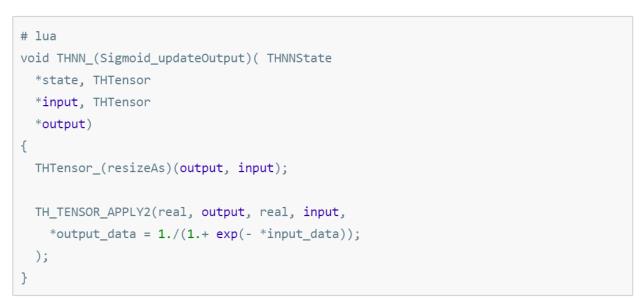
这里其实是相当于留了两个方法的定义,没有写具体功能。具体功能的代码,在 ./lib/THNN/generic 目录 中用 C 实现实现,具体以 Sigmoid 函数举例。
我们知道 Sigmoid 函数的形式是:
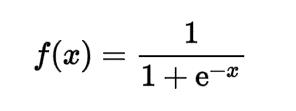
代码实现起来是这样:
Sigmoid 函数求导变成:
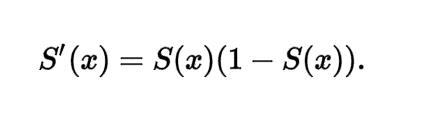
所以这里在实现的时候就是:
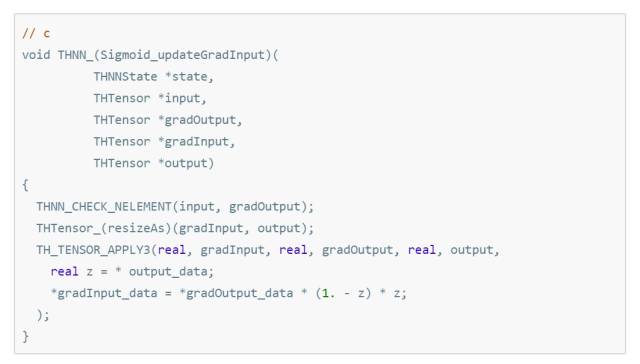
大家应该注意到了一点, updateOutput 函数, output_data 在等号左边, input_data 在等号右边。 而 updateGradInput 函数, gradInput_data 在等号左边, gradOutput_data 在等号右边。 这里,output = f(input) 对应的是 正向传播 input = f(output) 对应的是 反向传播。
2.2 用 Python 直接编写一个最简单的深度学习框架
这部分内容属于“造轮子”,并且借用了优达学城的一个小型项目 MiniFlow。
数据结构部分
首先,我们实现一个父类 Node,然后基于这个父类,依次实现 Input Linear Sigmoid 等模块。这里运用了简单的 Python Class 继承。这些模块中,需要将 forward 和 backward 两个方法针对每个模块分别重写。
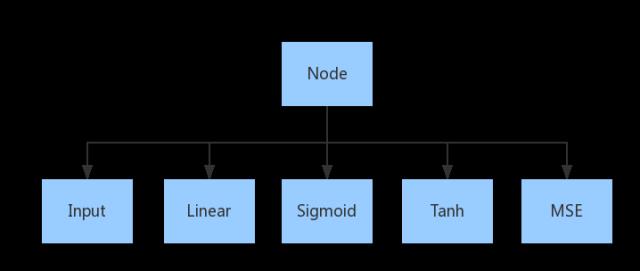
代码如下:

调度算法与优化部分
优化部分则会在以后的系列中单独详细说明。这里主要将简单讲一下图计算的算法调度。就是实际上Tensorflow的各个模块会生成一个有向无环图,如下图:

在计算过程中,几个模块存在着相互依赖关系,比如要计算模块1,就必须完成模块3和模块4,而要完成模块3,就需要在之前顺次完成模块5、2;因此这里可以使用 Kahn 算法作为调度算法(下面的 topological_sort 函数),从计算图中,推导出类似 5->2->3->4->1 的计算顺序。

使用模型
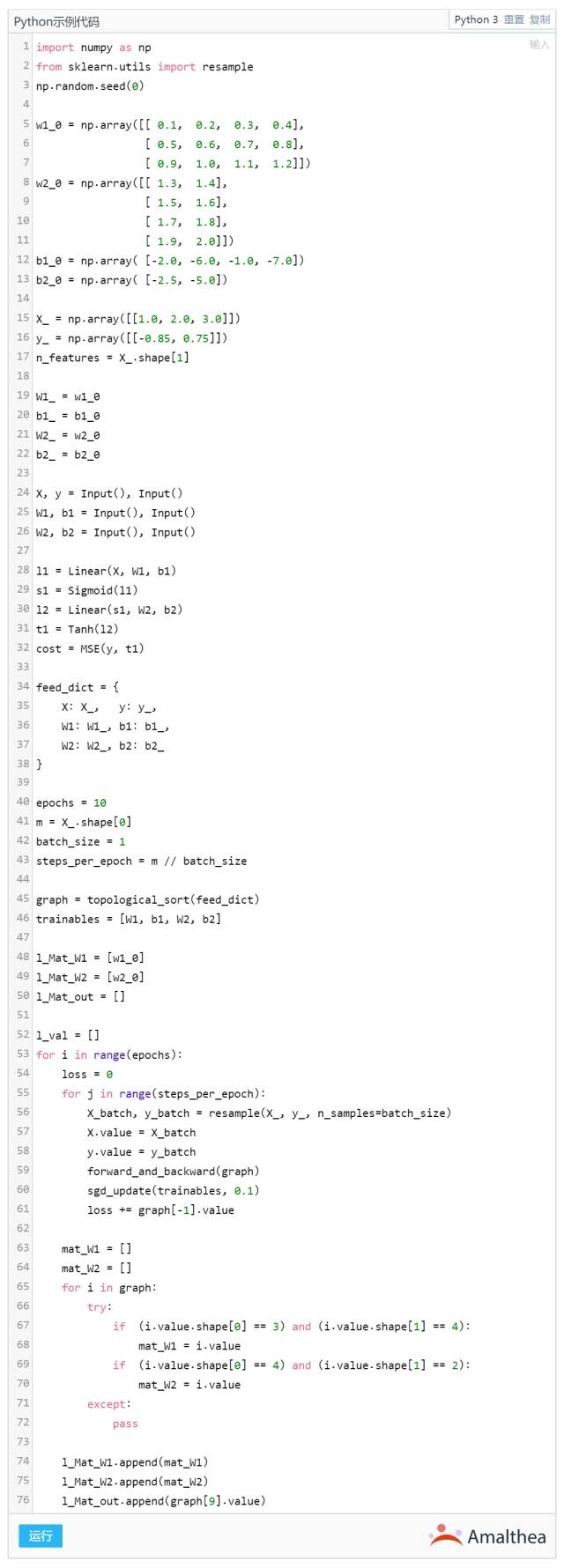
来观察一下。当然还有更高级的可视化方法:可视化的神经网络

我们注意到,随着训练轮数 Epoch 不断增多, Output 值从最初的 [0.72, -0.88] 不断接近 y = [-0.85, 0.72], 其背后的原因,是模型参数不断的从初始化的值变化、更新,如图中的 w1 w2 两个矩阵。
好了,最简单的轮子已经造好了。 我们的轮子,实现了 Input Linear Sigmoid Tanh 以及 MSE 这几个模块。 接下来的内容,我们将基于现在最火的轮子 Tensorflow,详细介绍一下更多的模块。
最后,本篇只是造了个最基本的轮子,我们集智的知乎专栏上,有一个系列文章,正在介绍如何在Matlab上手写深度学习框架,欢迎大家围观。
目前腾讯云 GPU 服务器的内测阶段已经结束了,后续文章的重点是深度学习,计算量大大增加,因此推荐大家租用 云GPU服务器 来执行代码。服务器的租用方式,以及 Python 编程环境的搭建,我们将以腾讯云 GPU 为例,在接下来的内容中和大家详细介绍。
拓展阅读:
官方微博:@景略集智
商务合作:chenyang@jizhi.im
投稿转载:kexiyang@jizhi.im
以上是关于GPU学习DL系列:Tensorflow 简明原理的主要内容,如果未能解决你的问题,请参考以下文章