CaffeTensorFlowMXnet三个开源库对比
Posted 炼数成金前沿推荐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CaffeTensorFlowMXnet三个开源库对比相关的知识,希望对你有一定的参考价值。
最近Google开源了他们内部使用的深度学习框架TensorFlow[1],结合之前开源的MXNet[2]和Caffe[3],对三个开源库做了一些讨论,其中只有Caffe比较仔细的看过源代码,其他的两个库仅阅读官方文档和一些研究者的评论博客有感,本文首先对三个库有个整体的比较,再针对一些三者设计的不同数据结构、计算方式、gpu的选择方式等方面做了比较详细的讨论。表格1是三者的一些基本情况的记录和比较。其中示例指的是官方给出的example是否易读易理解,因为TensorFlow直接安装python包,所以一开始没有去下源代码,从文档中找example不如另外两个下源码直接。实际上TensorFlow更加像一套独立的python接口,它不止能够完成CNN/RNN的功能,还见到过有人用它做Kmeans聚类。这个表主观因素比较明显,仅供参考。
1.基本数据结构

caffe的数据存储类blob,当把数据可以看成是一个N维的c数组,它们的存储空间连续。例如存储图片是4维(num, channel, height, width),变量(n,k,h,w)在数组中存储位置为((n*K+k)*H+h)*W+w。blob有以下三个特征[4]:
两块数据,一个是原始data,一个是求导值diff
两种内存分配方式,一种是分配在cpu上,一种是分配在gpu上,通过前缀cpu、gpu来区分
两种访问方式,一种是不能改变数据,一种能改变数据
Caffe最让我觉得精妙的地方在于一个blob保存前向和后向的数据。虽然就代码本身而言,前向数据是因为输入数据不同而改变,后向求导是因为求导不同而改变,根据SRP原则,在一个类里面因为两个原因而改变了数据这种是不合适的设计。但是从逻辑层面,前向数据的改变引起了反向求导的不同,它们实际上是一起在改变,本身应该是一个整体。所以我很喜欢这个设计,虽然基本上其他框架中都是将两个数据给分离出来,caffe2也不知是否保留。
MXNet的NDArray类似numpy.ndarray,也支持把数据分配在gpu或者cpu上进行运算。但是与numpy和caffe不同的是,当在操作NDArray,它能自动的将需要执行的数据分配到多台gpu和cpu上进行计算,从而完成高速并行。在调用者的眼中代码可能只是一个单线程的,数据只是分配到了一块内存中,但是背后执行的过程实际上是并行的。将指令(加减等)放入中间引擎,然后引擎来评估哪些数据有依赖关系,哪些能并行处理。定义好数据之后将它绑定到网络中就能处理它了。
TensorFlow的tensor,它相当于N维的array或者list,与MXNet类似,都是采用了以python调用的形式展现出来。某个定义好的tensor的数据类型是不变的,但是维数可以动态改变。用tensor rank和TensorShape来表示它的维数(例如rank为2可以看成矩阵,rank为1可以看成向量)。tensor是个比较中规中矩的类型。唯一特别的地方在于在TensorFlow构成的网络中,tensor是唯一能够传递的类型,而类似于array、list这种不能当成输入。
值得一提的是cuda-convnet采用的数据结构是NVMatrix,NV表示数据分配在gpu上,即将所有变量都当成矩阵来处理,它只有两维,它算是最早用cuda实现的深度学习框架,而上面三种框架都采用了多维可变维的思想,这种可变维在用矩阵做卷积运算的时候是很有效的。
2.网络实现方式
Caffe是典型的功能(过程)计算方式,它首先按照每一个大功能(可视化、损失函数、非线性激励、数据层)将功能分类并针对部分功能实现相应的父类,再将具体的功能实现成子类,或者直接继承Layer类,从而形成了XXXLayer的形式。然后将不同的layer组合起来就成了net。
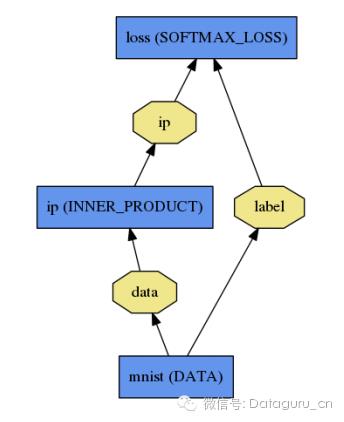
图1 caffe的网络结构
MXNet是符号计算和过程计算混合[5],它设计了Symbol大类,提供了很多符号运算的接口,每个symbol定义了对数据进行怎样的处理,symbol只是定义处理的方式,这步还并未真正的执行运算。其中一个需要注意的是symbol里面有Variable,它作为承载数据的符号,定义了需要传递什么样的数据给某个Variable,并在后续的操作中将数据绑定到Variable上。下面的代码是一个使用示例,它实现了将激励函数连接到前面定义好的net后面,并给出了这一个symbol的名字和激励函数类型,从而构造出net。下图左边部分是定义symbol的合集,中间将数据绑定到Variable上之后变成了右边真正的执行流程图。
net = mx.symbol.Activation(data=net, name='relu1', act_type="relu")
图2 MXNet的网络结构
TensorFlow选择的是符号计算方式,它的程序分为计算构造阶段和执行阶段,构造阶段是构造出computation graph,computation graph就是包含一系列符号操作Operation和Tensor数据对象的流程图,跟mxnet的symbol类似,它定义好了如何进行计算(加减乘除等)、数据通过不同计算的顺序(也就是flow,数据在符号操作之间流动的感觉)。但是暂时并不读取输入来计算获得输出,而是由后面的执行阶段启动session的run来执行已经定义好的graph。这样的方式跟mxnet很相似,应该都是借鉴了theano的想法。其中TensorFlow还引入了Variable类型,它不像mxnet的Variable属于symbol(tf的operation类似mxnet的symbol),而是一个单独的类型,主要作用是存储网络权重参数,从而能够在运行过程中动态改变。tf将每一个操作抽象成了一个符号Operation,它能够读取0个或者多个Tensor对象作为输入(输出),操作内容包括基本的数学运算、支持reduce、segment(对tensor中部分进行运算。例如tensor长度为10,可以同时计算前5个,中间2个,后面三个的和)、对image的resize、pad、crop、filpping、transposing等。tf没有像mxnet那样给出很好的图形解释或者实例(可能因为我没找到。。),按照自己的理解画了一部分流程图。有点疑惑的是,为什么要设计Variable,tf给出的一个alexnet的example源码中,输入数据和权重都设置成了Variable,每一层的输出并未直接定义,按照tf的说法,只有tensor类型能够在网络中传递,输出的类型应该是tensor,但是由于输入和权重改变了,输出应该也在随着改变,既然如此,为何不只设计一个tensor,让tensor也能动态改变。
图3 TensorFlow的computation graph
就设计而言,TensorFlow相对于其他两个更像是一种通用的机器学习框架,而不是只针对cnn或rnn,但就现在的性能而言,tf的速度比很多开源框架都要差一点[6]。
3.分布式训练
Caffe和TensorFlow没有给出分布式的版本,MXNet提供了多机分布式,因而前两者只有如何控制使用多gpu。Caffe通过直接在执行指令后面加上-gpu 0,1来表示调用两个gpu0和1,只实现了数据并行,也就是在不同的gpu上执行相同网络和不同数据,caffe会实例化多个solver和net让每次处理的batch_size加倍。TensorFlow则能够自己定义某个操作执行在哪个gpu上,通过调用with tf.device(‘/gpu:2’)表示接下来的操作要在gpu2上处理,它也是数据并行。MXNet通过执行脚本时指定多机节点个数来确定在几台主机上运行,也是数据并行。MXNet的多gpu分配和它们之间数据同步是通过MXNet的数据同步控制KVStore来完成的。
KVStore的使用首先要创建一个kv空间,这个空间用来在不同gpu不同主机间分享数据,最基本的操作是push和pull,push是把数据放入这个空间,pull是从这个空间取数据。这个空间内保存的是key-value([int, NDArray]),在push/pull的时候来指定到哪个key。下面的代码将不同的设备上分配的b[i]通过key3在kv空间累加再输出到a,从而完成了对多gpu的处理。这个是个非常棒的设计,提供了很大的自由度,并且为开发者减少了控制底层数据传输的麻烦。
gpus = [mx.gpu(i) for i in range(4)] b = [mx.nd.ones(shape, gpu) for gpu in gpus] kv.push(3, b) kv.pull(3, out = a)
之前有看过一篇论文,如何将卷积网络放在多gpu上训练,论文中有两种方法,一种是常用的数据并行,另一种是模型并行。模型并行指的是将一个完整的网络切分成不同块放在不同gpu上执行,每个gpu可能只处理某一张图的四分之一。采用模型并行很大程度上是因为显存不够放不下整个网络的数据,而现在gpu的功能性能提高,一个gpu已经能够很好的解决显存不够的问题,再加上模型并行会有额外的通信开销,因此开源框架采用了数据并行,用来提高并行度。
4.小结
上面针对三个框架的不同方面进行了一些分析与比较,可以看出TensorFlow和MXNet有一些相似的地方,都是想做成更加通用的深度学习框架,貌似caffe2也会采用符号计算[5],说明以后的框架会更加的偏向通用性和高效,个人最喜欢的是caffe,也仿造它和cuda-convnet的结构写过卷积网络,如果是想提高编程能力可以多看看这两个框架的源码。而MXNet给人的感觉是非常用心,更加注重高效,文档也非常的详细,不仅上手很容易,运用也非常的灵活。TensorFlow则是功能很齐全,能够搭建的网络更丰富而不是像caffe仅仅局限在CNN。总之框架都是各有千秋,如何选择也仅凭个人的喜好,然而google这个大杀器一出现引起的关注度还是最大的,虽然现在单机性能还不够好,但是看着长长的开发人员名单,也只能说大牛多就是任性。
参考:
[1]http://tensorflow.org/
[2]http://mxnet.readthedocs.org/en/latest/index.html
[3]http://caffe.berkeleyvision.org/
[4][caffe]的项目架构和源码解析
[5]如何评价Tensorflow和其它深度学习系统
[6]Imagenet Winners Benchmarking
文章来源:酷勤网
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,php,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
以上是关于CaffeTensorFlowMXnet三个开源库对比的主要内容,如果未能解决你的问题,请参考以下文章
CaffeMXnetTensorFlow三个深度学习开源库对比
Q新闻丨新版本发布潮:CeylonNode.js和Atom;微软公布用于Windows的OpenSSH代码;苹果开源三个加密库