机器学习之最近邻算法TensorFlow实现
Posted 数据魔法盒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之最近邻算法TensorFlow实现相关的知识,希望对你有一定的参考价值。
本期,我们介绍下最近邻算法的TensorFlow实现。由于是第一次谈及TensorFlow,我们先来介绍下TensorFlow。
TensorFlow是一款开源的Python机器学习框架。由Google机器智能研究部门的Googl Brain团队开发及维护,是一款基础框架。不仅可用于基础研究,也可用于生产环境。支持嵌入式处理器、CPU、GPU、TPU,具有部署灵活的特点。更重要的一点,由Google作为其背书,拥有不错的发展潜力。
虽然应用在Python环境中,但是使用tensorflow有点进入二次元空间的感觉。独立的数据结构,独立的运算符,独立的流程控制语句。并且不具备极致的交互式编程体验,有悖于python的编程特点。应用时一直有不可描述的抵触感,直到改变观点。这不是python,这是一款新的编程语言,开发环境。随即,开始拥抱tensorflow。下面展示使用tensorflow实现最近邻算法。
准备数据
我们依然使用从婚恋网站寻找约会对象的例子。有一名女主,经过多次兴奋亦或无聊的约会经历后,她将约会对象分为三类:
不喜欢的人,标记为Boring
一般的人,标记为Normal
极具魅力的人,标记为Fantastic
该女主还特别有心,除了打标签外,还将约会目标的一些特质数字化。简单起见,我们选用三个特质:
每年获得的飞行常客里程数,标记为air_miles
玩视频游戏所耗时间百分比,标记为video_games
每周消费的冰激凌公升数,标记为ice_cream
基于这些数据,我们通过机器学习算法,预测下一位约会者是否能吸引女主的目光,从而建议女主是去赴约,还是在家里追剧。
分析数据
我们使用python、pandas及matplotlib模块来可视化分析数据,对数据有一个感性认识后,再运用相应的机器学习算法。当然,我们已经提前选定了使用最近邻算法。
首先,导入数据到df变量
绘制散点图,用颜色区分女主是否喜欢
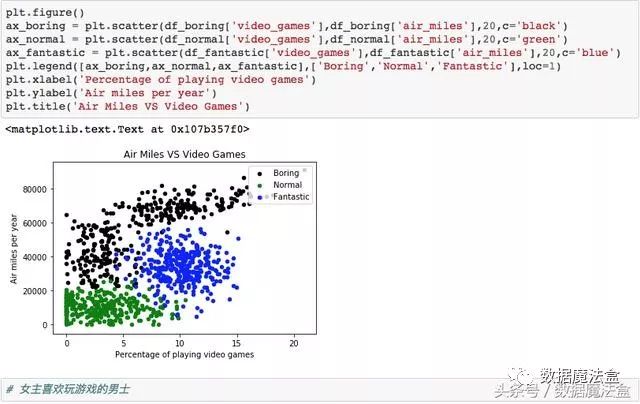
数据呈现一定的规律性,可以运用分类算法。我们还注意到,数据有一定的范围区间,具体描述为,每周游戏时间小于16%,食用冰激凌的数量小于1.75升,每年获得的飞行里程数少于80000公里。超出训练数据的范围,也即超出了分类器的预测能力。如每周100%玩游戏的勇士,分类器就会给出无价值的建议。
由于数据样本的单位不一致,我们需要对原始数据做归一化处理。

构建模型
使用TensorFlow进行运算前,需要预先定义模型。官方称为构建计算图,数据是以Tensor的形式在图中流动,运算。这种方式有助于将抽象的模型可视化呈现。
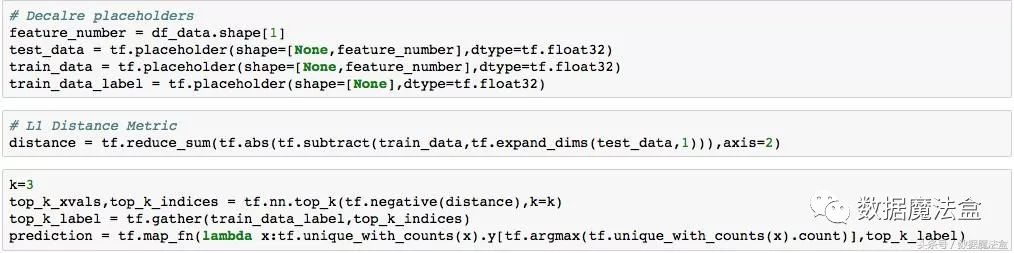
前二篇文章,我们采用数据点循环迭代的方式实现最近邻算法的运算及测试。本期我们采用批量矩阵运算的方式来解题,即构建距离矩阵。之前,我们使用L2范数(欧几里德距离),本期,我们使用L1范数。
构建计算图的过程如下:
测试算法
我们将10%的数据作为测试数据集,用于验证算法的泛化能力。
执行计算图并计算错误率
结语
最近邻算法是一个简单有效的基础机器学习算法,但对训练数据集敏感,即噪声敏感(错误的分类数据将导致错误的分类预测值)。也对训练数据集有一定的要求,在各个分类结果的值空间中,训练数据必须存在(待预测数据点需要计算最近邻,如果值空间的训练数据不存在,所得到的最近邻其实已经很远了)。也正是由于算法每次都使用整个训练数据集,最近邻算法不是高效的。当数据集巨大时,计算效率也是不可接受的。
以上是关于机器学习之最近邻算法TensorFlow实现的主要内容,如果未能解决你的问题,请参考以下文章