教程 | 没有博士学位,照样玩转TensorFlow深度学习
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教程 | 没有博士学位,照样玩转TensorFlow深度学习相关的知识,希望对你有一定的参考价值。
选自Codelabs
机器之心编译
参与:侯韵楚、王宇欣、赵华龙、邵明、吴攀
本文内容由机器之心编译自谷歌开发者博客的 Codelabs 项目。据介绍,Google Developers Codelabs 提供了有引导的、教程式的和上手式的编程体验。大多数 Codelabs 项目都能帮助你了解开发一个小应用或为一个已有的应用加入新功能的过程。这些应用涉及到很多主题,包括 android Wear、Google Compute Engine、Project Tango、和 ios 上的 Google API。
本项目的原文可参阅:https://codelabs.developers.google.com/codelabs/cloud-tensorflow-mnist/#13
1、概述
在 codelab 项目中,你将学习如何构建并训练出能够识别手写数字的神经网络。在这过程中,当这个神经网络的准确度提升至 99%时,你还会发现深度学习专业人士用来有效训练模型的贸易工具。
这个 codelab 项目使用的是 MNIST 数据集,这个包含 60,000 个有标记数字的集合是几届博士努力近二十年的成果。你将会用不到 100 行的 Python/TensorFlow 代码来解决上述问题。
你将学到:
①神经网络的定义及如何训练神经网络
②如何使用 TensorFlow 构建基本的 1 层神经网络
③如何添加多层神经网络
④训练提示和技巧:过拟合、dropout、学习速率衰减等...
⑤如何解决深度神经网络的问题
⑥如何构建卷积网络
对此,你将需要:
①Python 2 或 3(建议使用 Python 3)
②TensorFlow
③Matplotlib(Python 的可视化库)
安装说明会在下一步中给出。
2. 准备:安装 TensorFlow,获取示例代码
在你的计算机上安装必要软件:Python、TensorFlow 和 Matplotlib。完整的安装说明如下:INSTALL.txt
克隆 GitHub 存储库:
$ git clone https://github.com/martin-gorner/tensorflow-mnist-tutorial
这个库包含了多个文件,而你将只在mnist_1.0_softmax.py中操作。其它文件是用于加载数据和可视化结果的解决方案或支持代码。
当你启动初始python脚本时,应当能够看到训练过程的实时可视化:
$ python3 mnist_1.0_softmax.py
疑难解答:如果无法运行实时可视化,或者如果你只想要使用文本输出,则可以通过注释掉一行并取消另一行的注释来禁用可视化。请参阅文件底部的说明。
为 TensorFlow 构建的可视化工具是 TensorBoard,其主要目标比我们在这里所需的更宏大。它能使你能够跟踪你在远程服务器上的分布式 TensorFlow 工作。而对于我们的这个实验,matplotlib 将作为替代,并且我们还有额外收获——实时动画。但是如果你使用 TensorFlow 进行严谨的工作,你一定要试试 TensorBoard。
3、理论:训练一个神经网络
我们首先来观察一个正在训练的神经网络。其代码会在下一节解释,所以现在不必查看。
我们的神经网络可以输入手写数字并对它们进行分类,即将它们识别为 0、1、2……9。它基于内部变量(「权重(weights)」和「偏差(bias)」,会在后面进行解释),需要有一个正确的值来分类才能正常工作。这个「正确的值」通过训练过程进行学习,这也将在后面详细解释。你现在需要知道的是,训练回路看起来像这样:
Training digits => updates to weights and biases => better recognition (loop)
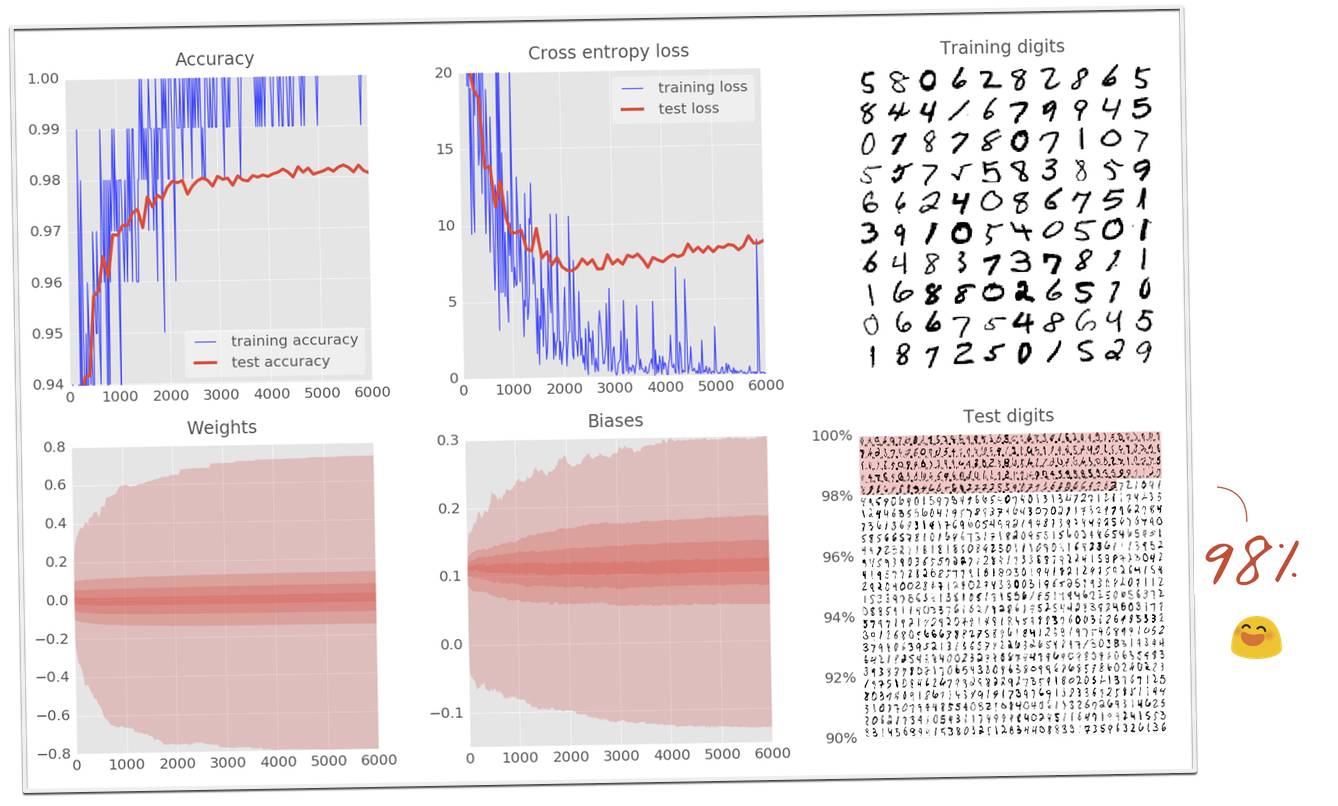
让我们逐个通过可视化的六个面板,了解训练神经网络需要什么。

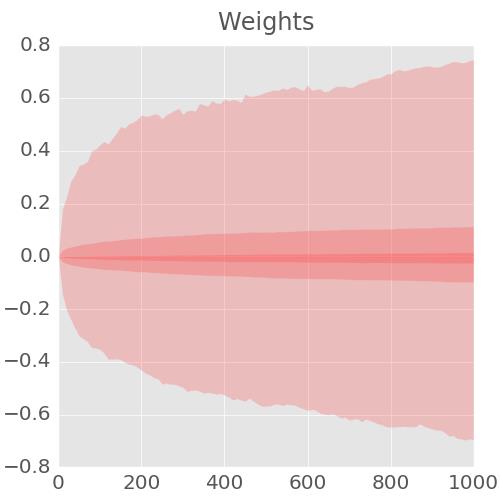
你可以看到训练数字每次 100 个被送入训练回路;也可以看到当前训练状态下的神经网络是已将数字正确识别(白色背景)还是误分类(红色背景,左侧印有正确的标示,每个数字右侧印有计算错误的标示)。
此数据集中有 50,000 个训练数字。我们在每次迭代(iteration)中将 100 个数字送入训练循环中,因此系统将在 500 次迭代之后看到所有训练数字一次。我们称之为一个「epoch」。

为了测试在现实条件下的识别质量,我们必须使用系统在训练期间从未看过的数字。否则,它可能记住了所有的训练数字,却仍无法识别我刚才写的「8」。MNIST 数据集包含了 10,000 个测试数字。此处你能看到每个数字对应的大约 1000 种书写形式,其中所有错误识别的数字列在顶部(有红色背景)。左边的刻度会给你一个粗略的分辨率精确度(正确识别的百分比)。
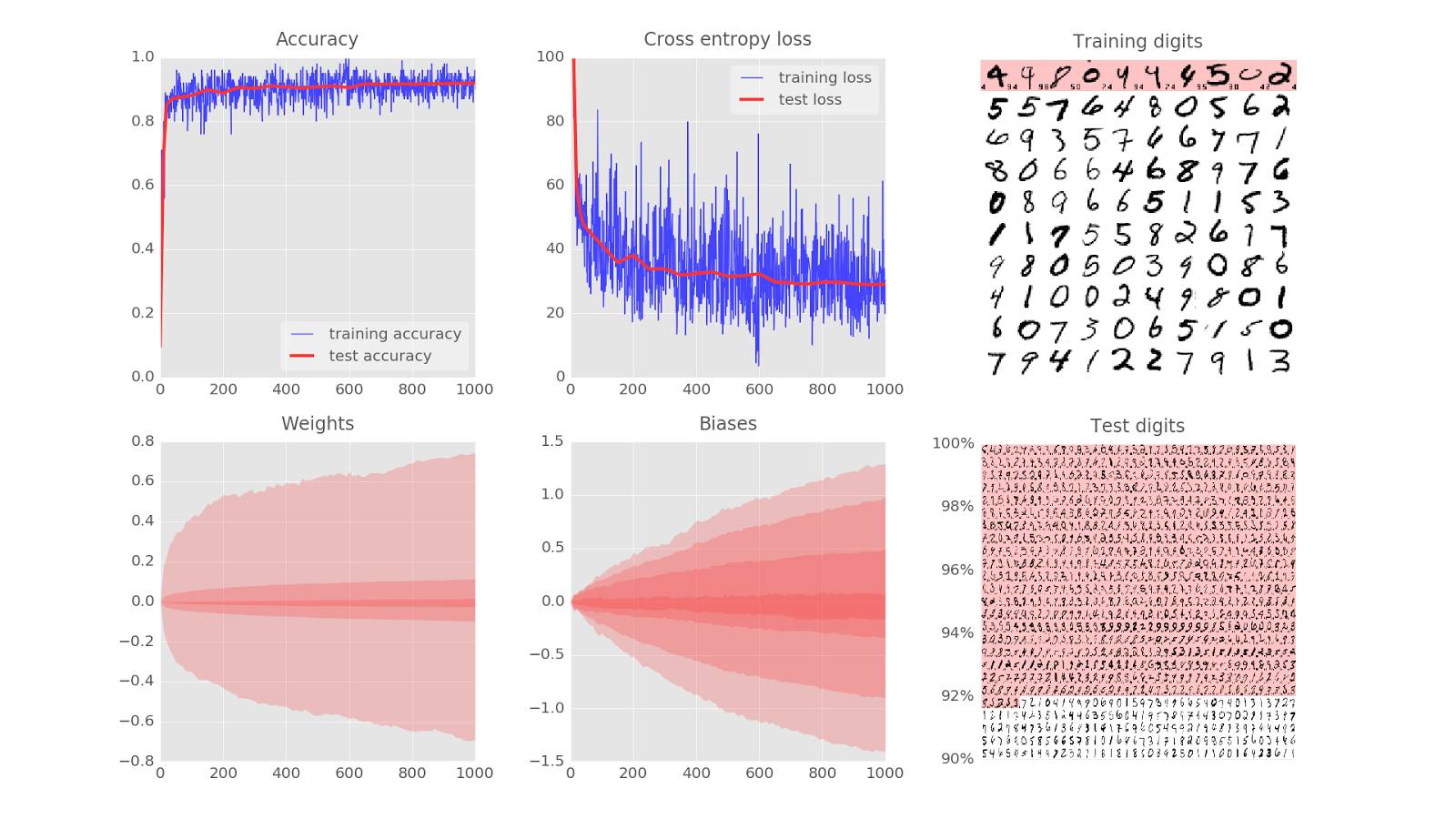
为了驱动训练,我们来定义损失函数,即一个展示出系统数字识别能力有多糟的值,并且系统会尽力将其最小化。损失函数(loss function,此处为「交叉熵」)的选择稍后会做出解释。你会看到,随着训练的进行,训练和测试数据的损失会减少,而这个现象是好的,意味着神经网络正在学习。X 轴表示了学习过程中的迭代。
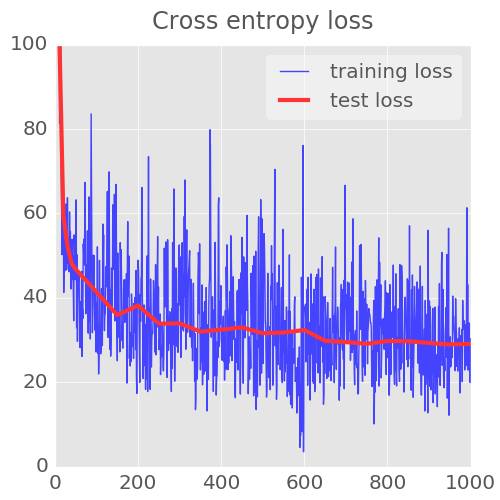
这个准确度只是正确识别的数字的百分比,是在训练和测试集上计算出的。如果训练顺利,它便会上升。
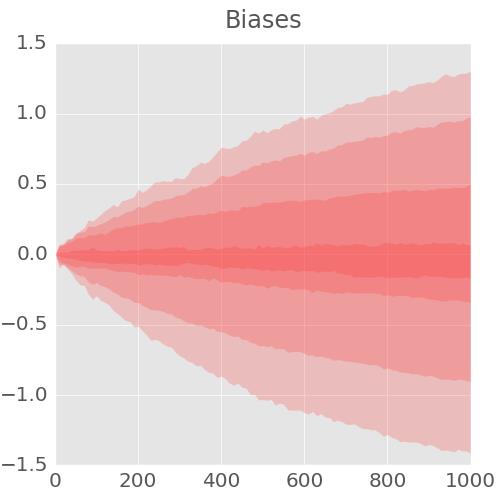
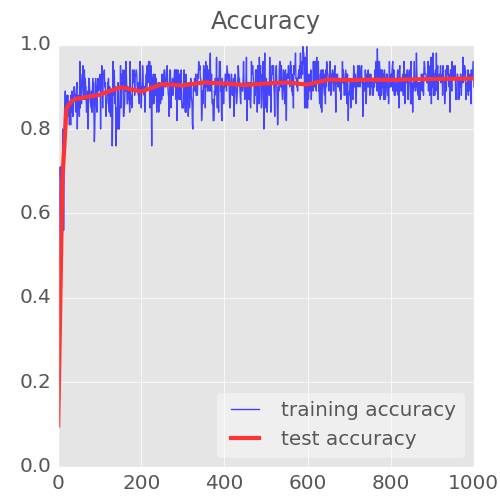
最后的两幅图表说明了内部变量所取的所有值的扩展,即随训练进行而变化的权重和偏置。比如偏置从 0 开始,且最终得到的值大致均匀地分布在-1.5 和 1.5 之间。如果系统不能很好地收敛,那么这些图可能有用。倘若你发现权重和偏差扩展到上百或上千,那么就可能有问题了。
图中的条带为百分数。此处有 7 条带,所以每条带是所有值的 100/7,也就是 14%。
用于可视化 GUI 的键盘快捷键
1 ......... display 1st graph only 仅显示第 1 张图
2 ......... display 2nd graph only 仅显示第 2 张图
3 ......... display 3rd graph only 仅显示第 3 张图
4 ......... display 4th graph only 仅显示第 4 张图
5 ......... display 5th graph only 仅显示第 5 张图
6 ......... display 6th graph only 仅显示第 6 张图
7 ......... display graphs 1 and 2 显示 1 和 2 图
8 ......... display graphs 4 and 5 显示 4 和 5 图
9 ......... display graphs 3 and 6 显示 3 和 6 图
ESC or 0 .. back to displaying all graphs 返回,显示所有图
空格 ..... pause/resume 暂停/继续
O ......... box zoom mode (then use mouse) 框缩放模式(然后使用鼠标)
H ......... reset all zooms 重置所有缩放
Ctrl-S .... save current image 保存当前图像
什么是“权重”和“偏置”?“交叉熵”又是如何被计算的?训练算法究竟是如何工作的?请到下一部分一探究竟。
4、理论 : 单层神经网络

MNIST 数据集中,手写数字是 28x28 像素的灰度图像。将它们进行分类的最简单的方法就是使用 28x28=784 个像素作为单层神经网络的输入。
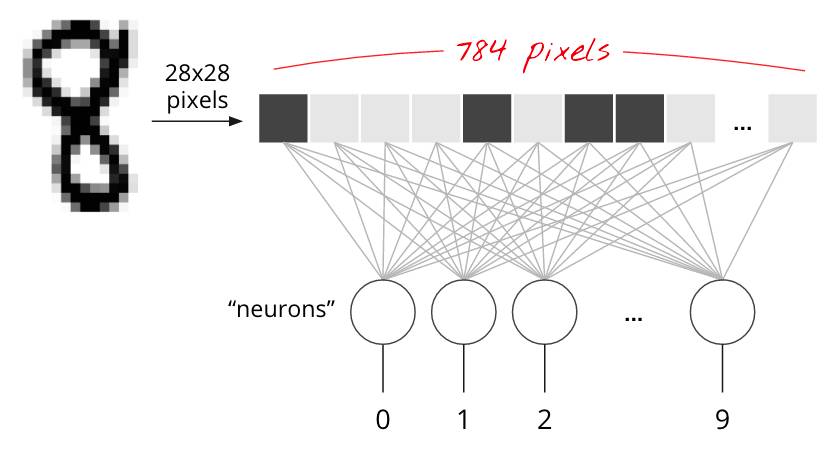
神经网络中的每个「神经元」对其所有的输入进行加权求和,并添加一个被称为「偏置(bias)」的常数,然后通过一些非线性激活函数来反馈结果。
为了将数字分为 10 类(0 到 9),我们设计了一个具有 10 个输出神经元的单层神经网络。对于分类问题,softmax 是一个不错的激活函数。通过取每个元素的指数,然后归一化向量(使用任意的范数(norm),比如向量的普通欧几里得距离)从而将 softmax 应用于向量。

那么为什么「softmax」会被称为 softmax 呢?指数是一种骤增的函数。这将加大向量中每个元素的差异。它也会迅速地产生一个巨大的值。然后,当进行向量的标准化时,支配范数(norm)的最大的元素将会被标准化为一个接近 1 的数字,其他的元素将会被一个较大的值分割并被标准化为一个接近 0 的数字。所得到的向量清楚地显示出了哪个是其最大的值,即「max」,但是却又保留了其值的原始的相对排列顺序,因此即为「soft」。
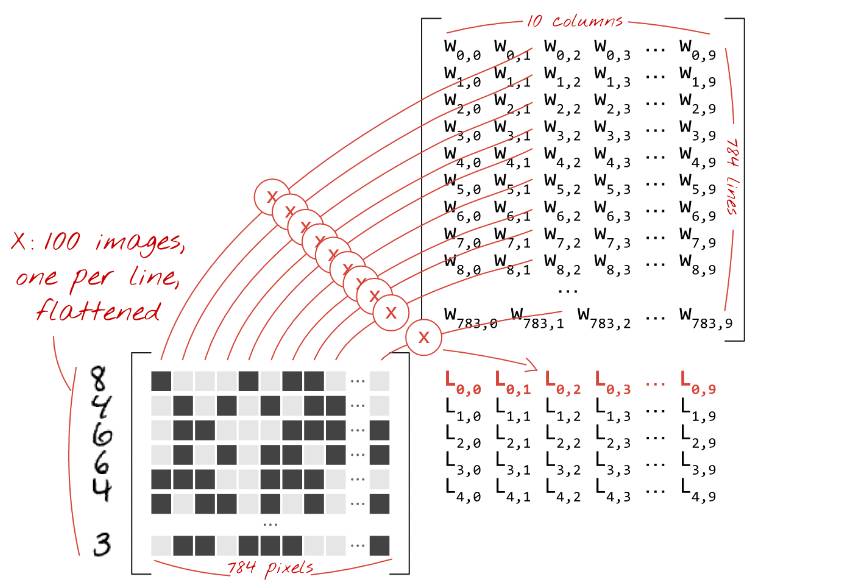
我们现在将使用矩阵乘法将这个单层的神经元的行为总结进一个简单的公式当中。让我们直接这样做:100 个图像的「mini-batch」作为输入,产生 100 个预测(10 元素向量)作为输出。
使用加权矩阵 W 的第一列权重,我们计算第一个图像所有像素的加权和。该和对应于第一神经元。使用第二列权重,我们对第二个神经元进行同样的操作,直到第 10 个神经元。然后,我们可以对剩余的 99 个图像重复操作。如果我们把一个包含 100 个图像的矩阵称为 X,那么我们的 10 个神经元在这 100 张图像上的加权和就是简单的 X.W(矩阵乘法)。
每一个神经元都必须添加其偏置(一个常数)。因为我们有 10 个神经元,我们同样拥有 10 个偏置常数。我们将这个 10 个值的向量称为 b。它必须被添加到先前计算的矩阵中的每一行当中。使用一个称为 "broadcasting" 的魔法,我们将会用一个简单的加号写出它。
「Broadcasting」是 Python 和 numpy(Python 的科学计算库)的一个标准技巧。它扩展了对不兼容维度的矩阵进行正常操作的方式。「Broadcasting add」意味着「如果你因为两个矩阵维度不同的原因而不能将其相加,那么你可以根据需要尝试复制一个小的矩阵使其工作。」
我们最终应用 softmax 激活函数并且得到一个描述单层神经网络的公式,并将其应用于 100 张图像:
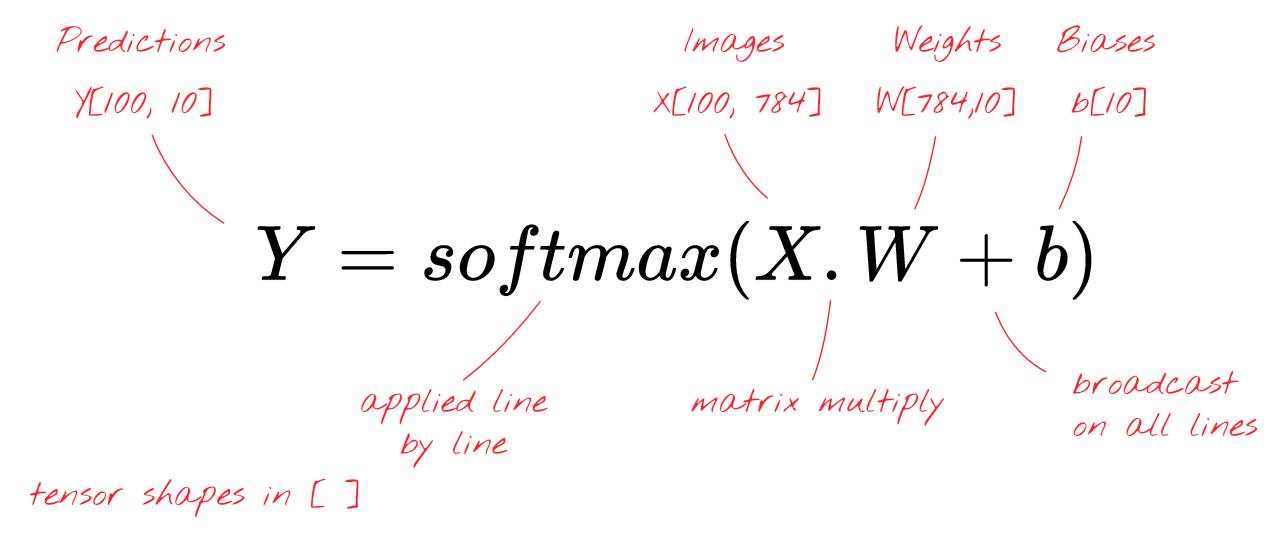
顺便说一下,什么是「tensor(张量)」?
「张量(tensor)」像一个矩阵,但是却有着任意数量的维度。一个 1 维的张量是一个向量。一个二维的张量是一个矩阵。然后你可以有 3, 4, 5 或者更多维的张量。
5、理论:梯度下降
现在我们的神经网络从输入图像中产生预测,我们需要知道它们可以做到什么样的程度,即在我们知道的事实和网络的预测之间到底有多大的距离。请记住,我们对于这个数据集中的所有图像都有一个真实的标签。
任何一种定义的距离都可以进行这样的操作,普通欧几里得距离是可以的,但是对于分类问题,被称为「交叉熵(cross-entropy)」的距离更加有效。

「one-hot」编码意味着你使用一个 10 个值的向量,其中除了第 6 个值为 1 以外的所有值都是 0。这非常方便,因为这样的格式和我们神经网络预测输出的格式非常相似,同时它也作为一个 10 值的向量。
「训练」一个神经网络实际上意味着使用训练图像和标签来调整权重和偏置,以便最小化交叉熵损失函数。它是这样工作的。
交叉熵是一个关于权重、偏置、训练图像的像素和其已知标签的函数。
如果我们相对于所有的权重和所有的偏置计算交叉熵的偏导数,我们就得到一个对于给定图像、标签和当前权重和偏置的「梯度」。请记住,我们有 7850 个权重和偏置,所以计算梯度需要大量的工作。幸运的是,TensorFlow 可以来帮我们做这项工作。
梯度的数学意义在于它指向「上(up)」。因为我们想要到达一个交叉熵低的地方,那么我们就去向相反的方向。我们用一小部分的梯度更新权重和偏置并且使用下一批训练图像再次做同样的事情。我们希望的是,这可以使我们到达交叉熵最小的凹点的低部。
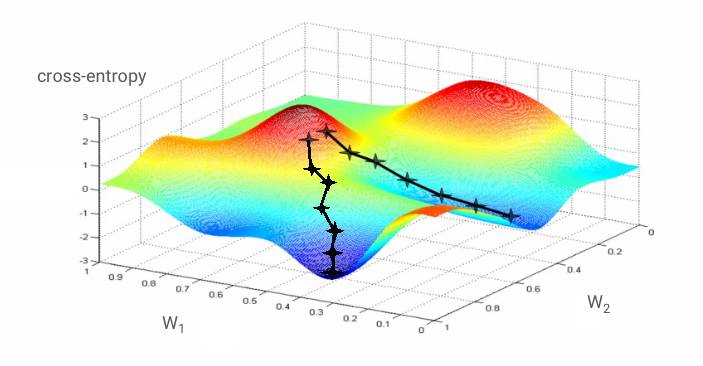
在这副图片当中,交叉熵被表示为一个具有两个权重的函数。事实上,还有更多。梯度下降算法遵循着一个最陡的坡度下降到局部最小值的路径。训练图像在每一次迭代中同样会被改变,这使得我们向着一个适用于所有图像的局部最小值收敛。
「学习率(learning rate)」: 在整个梯度的长度上,你不能在每一次迭代的时候都对权重和偏置进行更新。这就会像是你穿着七里靴却试图到达一个山谷的底部。你会直接从山谷的一边到达另一边。为了到达底部,你需要一些更小的步伐,即只使用梯度的一部分,通常在 1/1000 区域中。我们称这个部分为「学习率(Learning rate)」。
总结一下,以下是训练过程的步骤:
Training digits and labels => loss function => gradient (partial derivatives) => steepest descent => update weights and biases => repeat with next mini-batch of training images and labels
训练数字和标签 => 损失函数 => 梯度(部分偏导数)=> 最陡的梯度 => 更新权重和偏置 => 使用下一个 mini-batch 的图像和标签重复这一过程
为什么使用 100 个图像和标签的 mini-batch?
你当然也可以只在一个示例图像中计算你的梯度并且立即更新权重和偏置(这在科学文献中被称为「随机梯度下降(stochastic gradient descent)」)。在 100 个样本上都这样做可以得到一个更好地表示由不同样本图像施加约束的梯度并且可能更快地朝着解决方案收敛。mini-batch 的大小是可调整的参数。还有一个更加技术化的原因:使用批处理也意味着使用较大的矩阵,而这些通常更容易在 GPU 上优化。
常见问题
为什么交叉熵是在分类问题中合适的定义距离?
解答链接:https://jamesmccaffrey.wordpress.com/2013/11/05/why-you-should-use-cross-entropy-error-instead-of-classification-error-or-mean-squared-error-for-neural-network-classifier-training/
6、实验:让我们来看看代码
单层神经网络的代码已经写好了。请打开 mnist_1.0_softmax.py 文件并按说明进行操作。
你在本节的任务是理解开始代码,以便稍后对其改进。
你应该看到,在文档中的说明和启动代码只有微小的差别。它们对应于可视化的函数,并且在注释中被标记。此处可忽略。
mnist_1.0_softmax.py:
https://github.com/martin-gorner/tensorflow-mnist-tutorial/blob/master/mnist_1.0_softmax.py
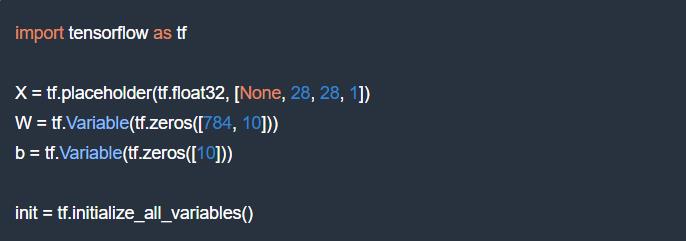
我们首先定义 TensorFlow 的变量和占位符。变量是你希望训练算法为你确定的所有的参数。在我们的例子中参数是权重和偏差。
占位符是在训练期间填充实际数据的参数,通常是训练图像。持有训练图像的张量的形式是 [None, 28, 28, 1],其中的参数代表:
28, 28, 1: 图像是 28x28 每像素 x 1(灰度)。最后一个数字对于彩色图像是 3 但在这里并非是必须的。
None: 这是代表图像在小批量(mini-batch)中的数量。在训练时可以得到。
mnist_1.0_softmax.py:
https://github.com/martin-gorner/tensorflow-mnist-tutorial/blob/master/mnist_1.0_softmax.py

第一行是我们单层神经网络的模型。公式是我们在前面的理论部分建立的。tf.reshape 命令将我们的 28×28 的图像转化成 784 个像素的单向量。在 reshape 中的「-1」意味着「计算机,计算出来,这只有一种可能」。在实际当中,这会是图像在小批次(mini-batch)中的数量。
然后,我们需要一个额外的占位符用于训练标签,这些标签与训练图像一起被提供。
现在我们有模型预测和正确的标签,所以我们计算交叉熵。tf.reduce_sum 是对向量的所有元素求和。
最后两行计算了正确识别数字的百分比。这是留给读者的理解练习,使用 TensorFlow API 参考。你也可以跳过它们。
mnist_1.0_softmax.py:
https://github.com/martin-gorner/tensorflow-mnist-tutorial/blob/master/mnist_1.0_softmax.py)
optimizer = tf.train.GradientDescentOptimizer(0.003)
train_step = optimizer.minimize(cross_entropy)
才是 TensorFlow 发挥它力量的地方。你选择一个适应器(optimiser,有许多可供选择)并且用它最小化交叉熵损失。在这一步中,TensorFlow 计算相对于所有权重和所有偏置(梯度)的损失函数的偏导数。这是一个形式衍生( formal derivation),并非是一个耗时的数值型衍生。
梯度然后被用来更新权重和偏置。学习率为 0.003。
最后,是时候来运行训练循环了。到目前为止,所有的 TensorFlow 指令都在内存中准备了一个计算图,但是还未进行计算。
TensorFlow 的 “延迟执行(deferred execution)” 模型:TensorFlow 是为分布式计算构建的。它必须知道你要计算的是什么、你的执行图(execution graph),然后才开始发送计算任务到各种计算机。这就是为什么它有一个延迟执行模型,你首先使用 TensorFlow 函数在内存中创造一个计算图,然后启动一个执行 Session 并且使用 Session.run 执行实际计算任务。在此时,图形无法被更改。
由于这个模型,TensorFlow 接管了分布式运算的大量运筹。例如,假如你指示它在计算机 1 上运行计算的一部分 ,而在计算机 2 上运行另一部分,它可以自动进行必要的数据传输。
计算需要将实际数据反馈进你在 TensorFlow 代码中定义的占位符。这是以 Python 的 dictionary 的形式给出的,其中的键是占位符的名称。
mnist_1.0_softmax.py:
https://github.com/martin-gorner/tensorflow-mnist-tutorial/blob/master/mnist_1.0_softmax.py
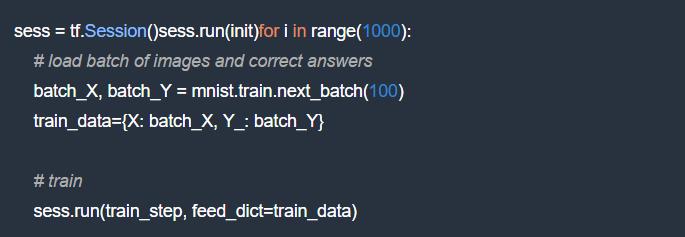
在这里执行的 train_step 是当我们要求 TensorFlow 最小化交叉熵时获得的。这是计算梯度和更新权重和偏置的步骤。
最终,我们还需要一些值来显示,以便我们可以追踪我们模型的性能。
在训练回路中使用该代码来计算准确度和交叉熵(例如每 10 次迭代):
# success ?
a,c = sess.run([accuracy, cross_entropy], feed_dict=train_data)
通过在馈送 dictionary 中提供测试而不是训练数据,可以对测试数据进行同样的计算(例如每 100 次迭代计算一次。有 10,000 个测试数字,所以会耗费 CPU 一些时间):
# success on test data ?
test_data={X: mnist.test.images, Y_: mnist.test.labels}
a,c = sess.run([accuracy, cross_entropy], feed=test_data)
TensorFlow 和 Numpy 是朋友:在准备计算图时,你只需要操纵 TensorFlow 张量和命令,比如 tf.matmul, tf.reshape 等。
然而,只要执行 Session.run 命令,它的返回值就是 Numpy 张量,即 Numpy 可以使用的 numpy.ndarray 对象以及基于它的所有科学计算库。这就是使用 matplotlib(基于 Numpy 的标准 Python 绘图库)为本实验构建实时可视化的方法。
这个简单的模型已经能识别 92% 的数字了。这不错,但是你现在要显著地改善它。
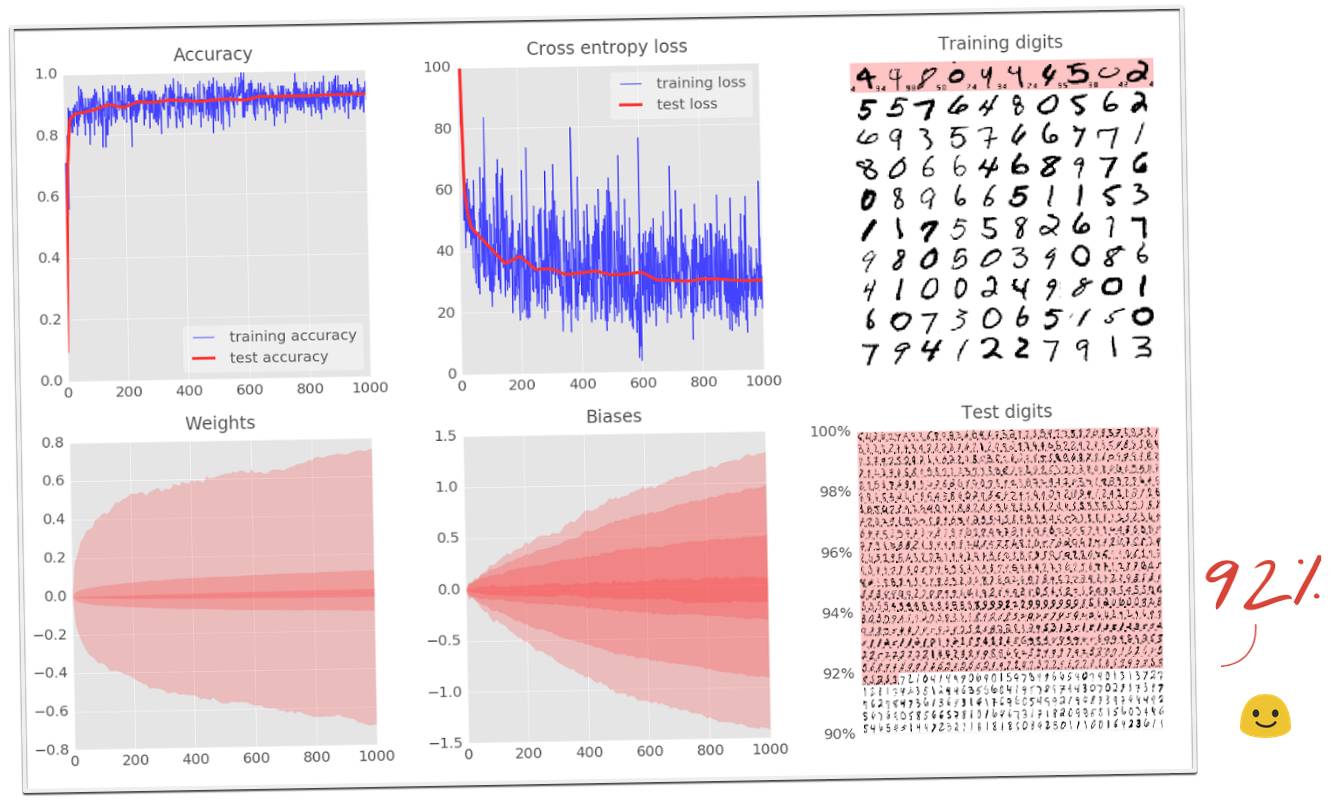
7、实验:增加层

为了提高识别的准确度,我们将为神经网络增加更多的层。第二层神经元将计算前一层神经元输出的加权和,而非计算像素的加权和。这里有一个 5 层全相连的神经网络的例子:
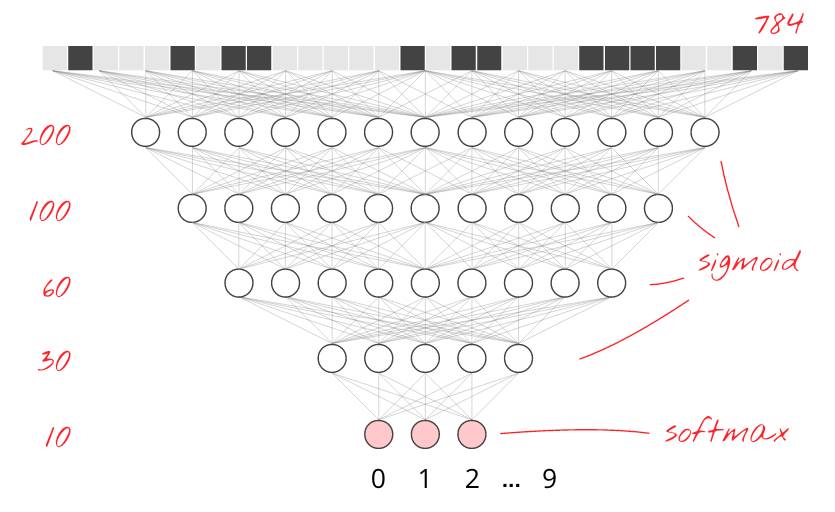
我们继续用 softmax 来作为最后一层的激活函数,这也是为什么在分类这个问题上它性能优异的原因。但在中间层,我们要使用最经典的激活函数:sigmoid:在这一节中你的任务是为你的模型增加一到两个中间层以提高它的性能。
答案可以在 mnist_2.0_five_layers_sigmoid.py 中找到。只有当你实在想不出来的时候再使用它!为了增加一个层,你需要为中间层增加一个额外的权重矩阵和一个额外的偏置向量:
W1 = tf.Variable(tf.truncated_normal([28*28, 200] ,stddev=0.1))
B1 = tf.Variable(tf.zeros([200]))
W2 = tf.Variable(tf.truncated_normal([200, 10], stddev=0.1))
B2 = tf.Variable(tf.zeros([10]))
对,就这么做。通过 2 个中间层以及例子中 200 个和 100 个神经元,你现在应该能够把你的神经网络的准确度推高到 97% 了。
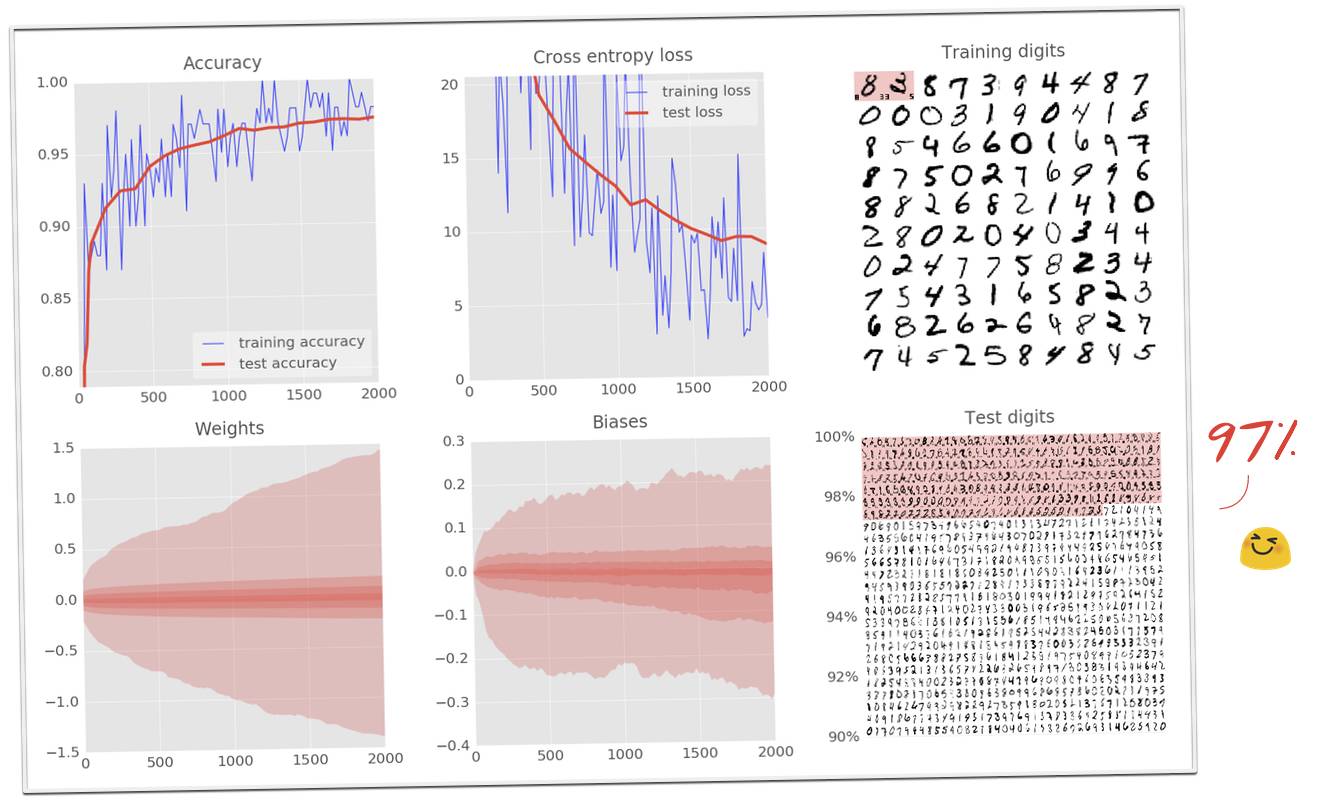
8、实验:深度网络需要特别注意的地方

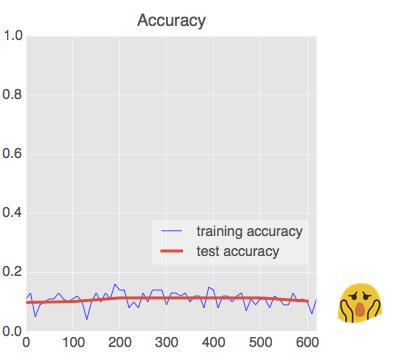
随着层数的增加,神经网络越来越难以收敛。但现在我们知道如何控制它们的行为了。这里是一些只用 1 行就可以实现的改进,当你看到准确度曲线出现如下情况的时候,这些小技巧会帮到你:
修正线性单元(ReLU)激活函数
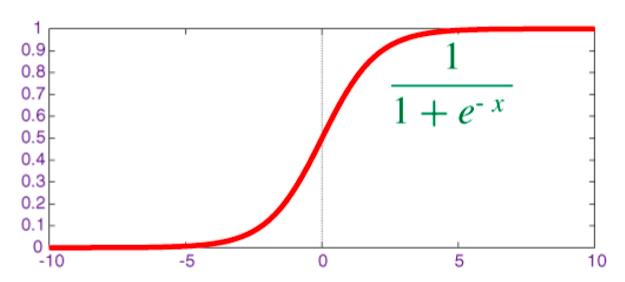
在深度网络里,sigmoid 激活函数确实能带来很多问题。它把所有的值都挤到了 0 到 1 之间,而且当你重复做的时候,神经元的输出和它们的梯度都归零了。值得一提的是,出于历史原因,一些现代神经网络使用了 ReLU(修正线性单元),它大致是如下这个样子:
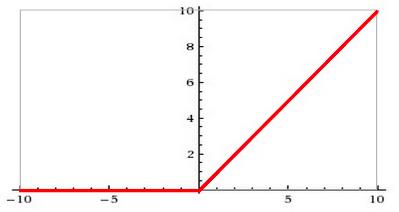
升级 1/4:用 RELU 替换你所有的 sigmoid,然后你会得到一个更快的初始收敛并且当我们继续增加层的时候也避免了一些后续问题的产生。仅仅在代码中简单地用 tf.nn.relu 来替换 tf.nn.sigmoid 就可以了。
一个更好的优化器
在一个特别多维的空间里,就像当前这个情况——我们有 10K 量级的权值和偏置值——「鞍点 (saddle points)」会频繁出现。这些点不是局部最小值点,但它的梯度却是零,那么梯度降的优化会卡在这里。TensorFlow 有一系列可以用的优化器,包括一些带有一定的惯性,能够安全越过鞍点的优化器。
升级 2/4:现在将你的 tf.train.GradientDescentOptimiser 替换为 tf.train.AdamOptimizer。
随机初始化
准确性一直卡在 0.1?你把你的权值初始化成随机值了没?对于偏置值,如果用 ReLU 的话,最好的办法就是把它们都初始化成小的正值,这样神经元一开始就会工作在 ReLU 的非零区域内。
W = tf.Variable(tf.truncated_normal([K, L] ,stddev=0.1))
B = tf.Variable(tf.ones([L])/10)
升级 3/4:现在检查是否你所有的权值和偏置值都被初始化好了。上图所示的 0.1 会作为偏置值。
不定值(NaN)
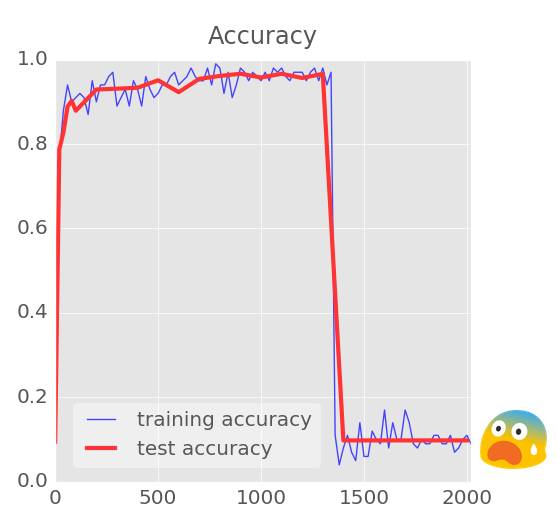
如果你看到你的精确曲线陡然下滑并且调试口输出的交叉熵是 NaN,不用感到头疼,你其实是正在尝试计算 log(0),而这肯定是个不定值(NaN)。还记得吗,交叉熵的计算涉及到对 softmax 层的输出取对数。鉴于 softmax 基本上是一个指数,它肯定不是 0,我们如果用 32 位精度的浮点运算就还好,exp(-100) 基本上可以算作是 0 了。
很幸运,TensorFlow 有一个非常方便的函数可以在单步内计算 softmax 和交叉熵,它是以一种数值上较为稳定的方式实现的。如果要使用它,你需要在应用 softmax 之前将原始的权重和加上你最后一层的偏置隔离开来(在神经网络的术语里叫「logits」)。
如果你模型的最后一行是这样的:
Y = tf.nn.softmax(tf.matmul(Y4, W5) + B5)
你需要把它替换成:
Ylogits = tf.matmul(Y4, W5) + B5 Y = tf.nn.softmax(Ylogits)
并且你现在能以一种安全的方式计算交叉熵了:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(Ylogits, Y_)
同样加上下面这行代码使得测试和训练的交叉熵能够同框显示:
cross_entropy = tf.reduce_mean(cross_entropy)*100
升级 4/4:请把 tf.nn.softmax_cross_entropy_with_logits 加到你的代码里。你也可以跳过这一步,等你真在你的输出里看到 NaN 以后再来做这步。现在,你已经准备好实现「深度」了。
9、实验:学习速率衰退

通过两个、三个或者四个中间层,你现在可以将准确度提升至接近 98%,当然,你的迭代次数要达到 5000 次以上。不过你会发现你并不总是会得到这样的结果。
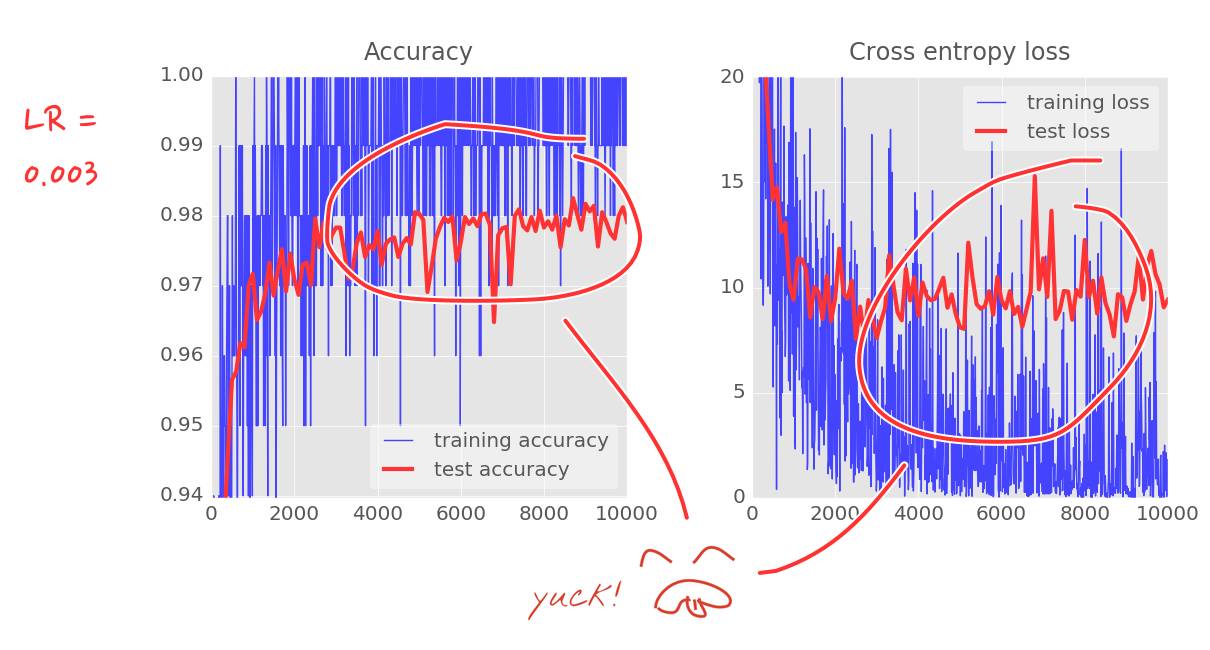
这些曲线很嘈杂,看看测试精确度吧:它在全百分比范围内跳上跳下。这意味着即使 0.003 的学习率我们还是太快了。但我们不能仅仅将学习率除以十或者永远不停地做训练。一个好的解决方案是开始很快随后将学习速率指数级衰减至比如说 0.0001。
这个小改变的影响是惊人的。你会看到大部分的噪声消失了并且测试精确度持续稳定在 98% 以上。
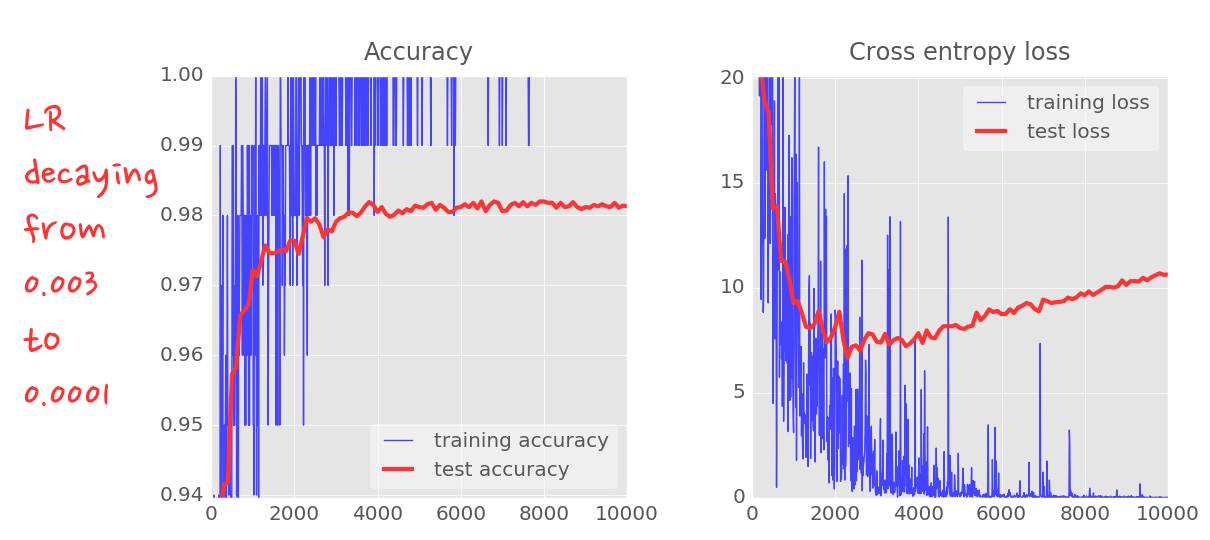
再看看训练精确度曲线。在好多个 epoch 里都达到了 100%(一个 epoch=500 次迭代=全部训练图片训练一次)。第一次我们能很好地识别训练图片了。
请把学习率衰退加到你的代码里。为了把一个不同的学习率在每次迭代时传给 AdamOptimizer,你需要定义一个新的占位符(placeholder)并在每次迭代时通过 feed_dict 赋给它一个新的参数。
这里是一个指数级衰减的方程:lr = lrmin+(lrmax-lrmin)*exp(-i/2000) 答案可以在这个文件里找到:mnist_2.1_five_layers_relu_lrdecay.py。如果你被卡住了可以用它。
10、实验:dropout、过拟合

你可能已经注意到在数千次迭代之后,测试和训练数据的交叉熵曲线开始不相连。学习算法只是在训练数据上做工作并相应地优化训练的交叉熵。它再也看不到测试数据了,所以这一点也不奇怪:过了一会儿它的工作不再对测试交叉熵产生任何影响,交叉熵停止了下降,有时甚至反弹回来。
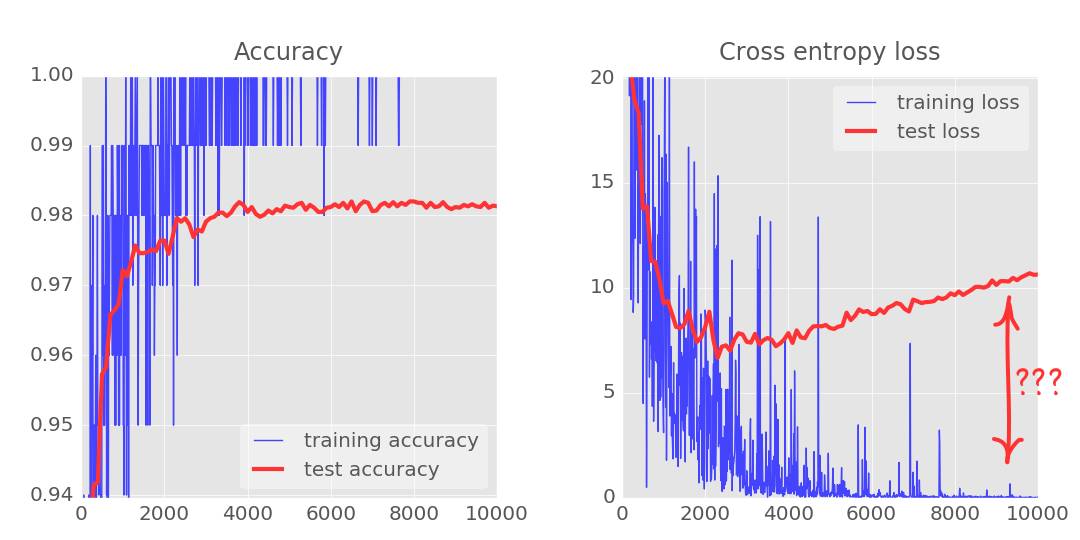
它不会立刻影响你模型对于真实世界的识别能力,但是它会使你运行的众多迭代毫无用处,而且这基本上是一个信号——告诉我们训练已经不能再为模型提供进一步改进了。这种无法连接通常会被标明「过拟合(overfitting)」,而且当你看到这个的时候,你可以尝试采用一种规范化(regularization)技术,称之为「dropout」。
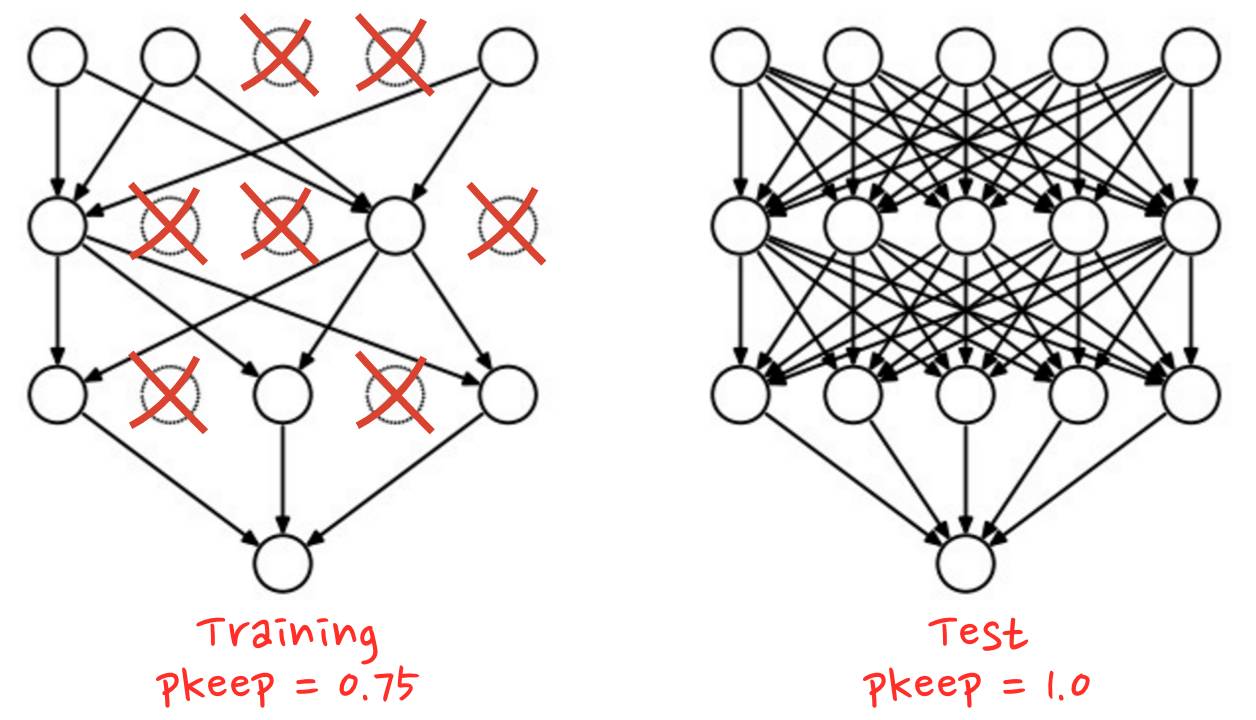
在 dropout 里,在每一次训练迭代的时候,你可以从网络中随机地放弃一些神经元。你可以选择一个使神经元继续保留的概率 pkeep,通常是 50% 到 75% 之间,然后在每一次训练的迭代时,随机地把一些神经元连同它们的权重和偏置一起去掉。在一次迭代里,不同的神经元可以被一起去掉(而且你也同样需要等比例地促进剩余神经元的输出,以确保下一层的激活不会移动)。当测试你神经网络性能的时候,你再把所有的神经元都装回来 (pkeep=1)。
TensorFlow 提供一个 dropout 函数可以用在一层神经网络的输出上。它随机地清零一些输出并且把剩下的提升 1/pkeep。这里是如何把它用在一个两层神经网络上的例子。
# feed in 1 when testing, 0.75 when training
pkeep = tf.placeholder(tf.float32)
Y1 = tf.nn.relu(tf.matmul(X, W1) + B1)
Y1d = tf.nn.dropout(Y1, pkeep)
Y = tf.nn.softmax(tf.matmul(Y1d, W2) + B2)
你现在可以在网络中每个中间层以后插入 dropout。如果你没时间深入阅读的话,这是本项目里的可选步骤。
该解决方案可以在 mnist_2.2_five_layers_relu_lrdecay_dropout.py:
(https://github.com/martin-gorner/tensorflow-mnist-tutorial/blob/master/mnist_2.2_five_layers_relu_lrdecay_dropout.py)
里找到。如果你被难住了,可以用它。
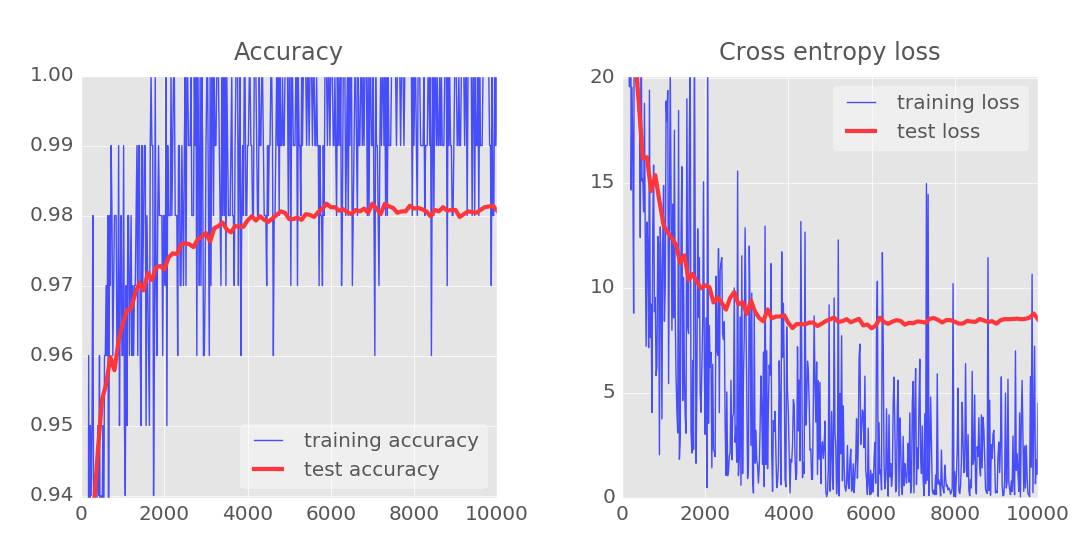
你会看到测试损失已经被搞回来了,已经在可控范围内了,不过至少在这个例子中噪声重新出现了(如果你知道 dropout 的工作原理的话,这一点也不奇怪)。测试的准确度依然没变,这倒是有点小失望。这个「过拟合」一定还有其它原因。在我们继续进行下一步之前,我们先扼要重述一下我们到目前为止用过的所有工具:
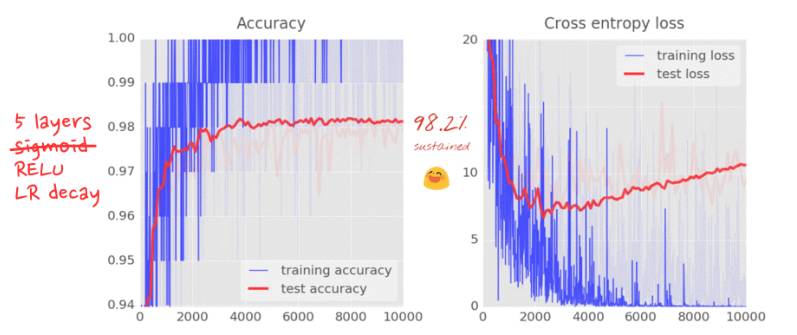
无论我们做什么,我们看上去都不可能很显著地解决 98% 的障碍,而且我们的损失曲线依然显示「过拟合」无法连接。什么是真正的「过拟合」?过拟合发生在该神经网络学得「不好」的时候,在这种情况下该神经网络对于训练样本做得很好,对真实场景却并不是很好。有一些像 dropout 一样的规范化技术能够迫使它学习得更好,不过过拟合还有更深层的原因。

基本的过拟合发生在一个神经网络针对手头的问题有太多的自由度的时候。想象一下我们有如此多的神经元以至于所组成的网络可以存储我们所有的训练图像并依靠特征匹配来识别它们。它会在真实世界的数据里迷失。一个神经网络必须有某种程度上的约束以使它能够归纳推理它在学习中所学到的东西。
如果你只有很少的训练数据,甚至一个很小的网络都能够用心学习它。一般来说,你总是需要很多数据来训练神经网络。
最后,如果你已经做完了所有的步骤,包括实验了不同大小的网络以确保它的自由度已经约束好了、采用了 dropout、并且训练了大量的数据,你可能会发现你还是被卡在了当前的性能层次上再也上不去了。这说明你的神经网络在它当前的形态下已经无法从你提供的数据中抽取到更多的信息了,就像我们这个例子这样。
还记得我们如何使用我们的图像吗?是所有的像素都展平到一个向量里么?这是一个很糟糕的想法。手写的数字是由一个个形状组成的,当我们把像素展平后我们会丢掉这些形状信息。不过,有一种神经网络可以利用这些形状信息:卷积网络(convolutional network)。让我们来试试。
11、理论:卷积网络
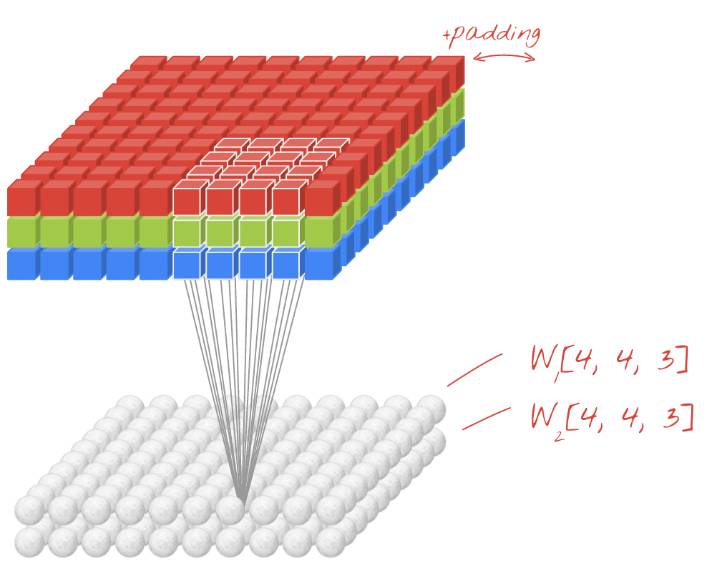
在卷积网络层中,一个「神经元」仅对该图像上的一个小部分的像素求加权和。然后,它通常会添加一个偏置单元,并且将得到的加权和传递给激活函数。与全连接网络相比,其最大的区别在于卷积网络的每个神经元重复使用相同的权重,而不是每个神经元都有自己的权重。
在上面的动画中,你可以看到通过连续修改图片上两个方向的权重(卷积),能够获得与图片上的像素点数量相同的输出值(尽管在边缘处需要填充(padding))。
要产生一个输出值平面,我们使用了一张 4x4 大小的彩色图片作为出输入。在这个动画当中,我们需要 4x4x3=48 个权重,这还不够,为了增加更多自由度,我们还需要选取不同组的权重值重复实验。
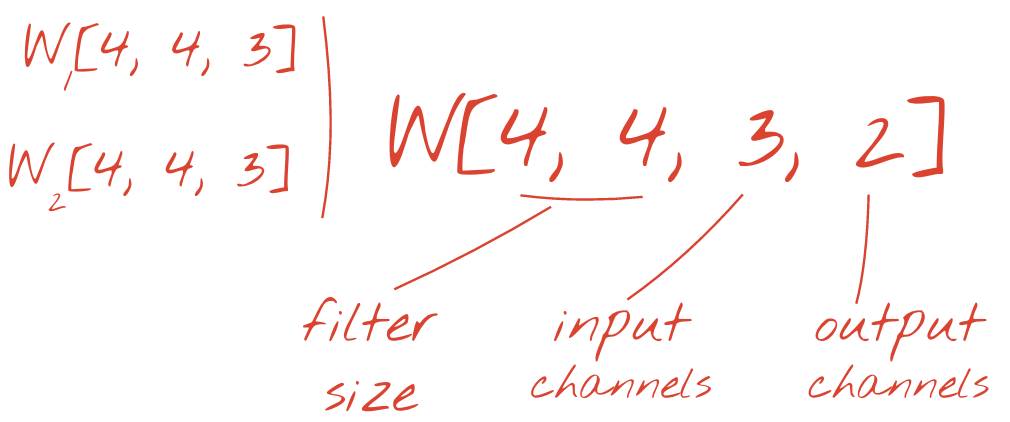
通过向权重张量添加一个维度,能够将两组或更多组的权重重写为一组权重,这样就给出了一个卷积层的权重张量的通用实现。由于输入、输出通道的数量都是参数,我们可以开始堆叠式(stacking)和链式(chaining)的卷积层。
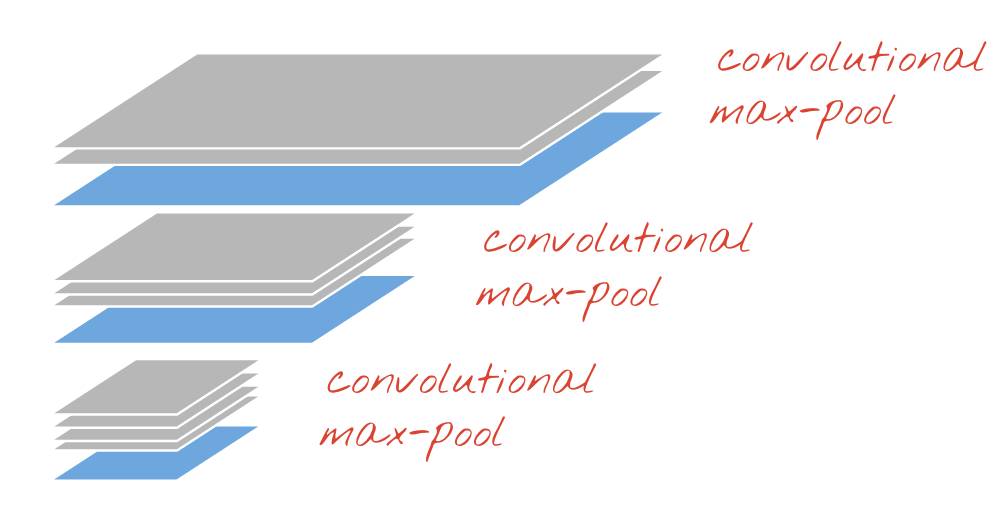
最后,我们需要提取信息。在最后一层中,我们仅仅想使用 10 个神经元来分类 0-9 十个不同的数字。传统上,这是通过「最大池化(max-pooling)」层来完成的。即使今天有许多更简单的方法能够实现这分类任务,但是,「最大池化」能够帮助我们直觉地理解卷积神经网络是怎么工作的。如果你认为在训练的过程中,我们的小块权重会发展成能够过滤基本形状(水平线、垂直线或曲线等)的过滤器(filter),那么,提取有用信息的方式就是识别输出层中哪种形状具有最大的强度。实际上,在最大池化层中,神经元的输出是在 2x2 的分组中被处理,最后仅仅保留输出最大强度的神经元。
这里有一种更简单的方法:如果你是以一步两个像素移动图片上的滑块而不是以每步一个像素地移动图片上的滑块。这种方法就是有效的,今天的卷积网络仅仅使用了卷积层。

让我们建立一个用于手写数字识别的卷积网络。在顶部,我们将使用 3 个卷积层;在底部,我们使用传统的 softmax 读出层,并将它们用完全连接层连接。
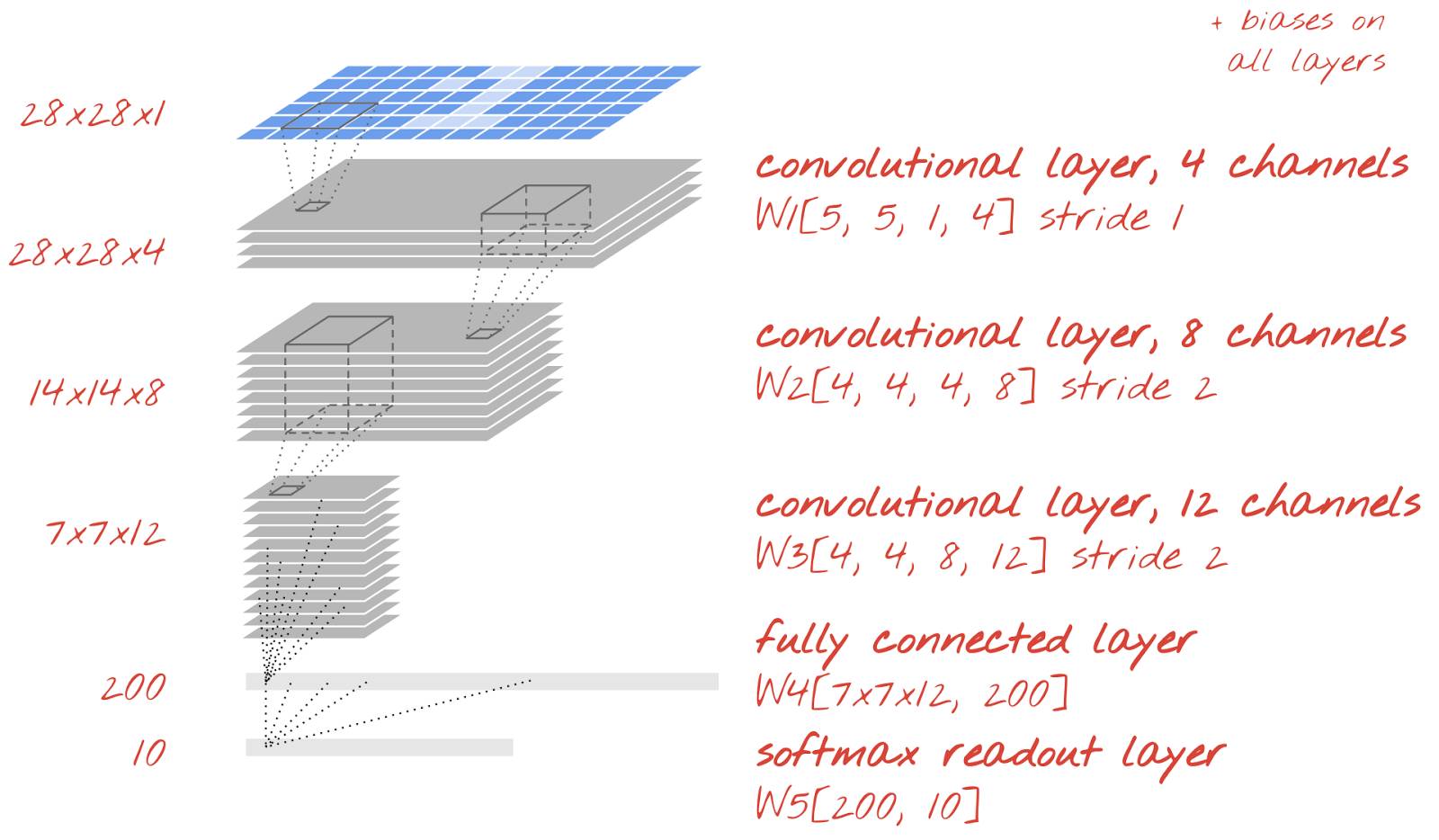
注意,第二与第三卷积层神经元数量以 2x2 为倍数减少,这就解释了为什么它们的输出值从 28x28 减少为 14x14,然后再到 7x7。卷积层的大小变化使神经元的数量在每层下降约为:28x28x14≈3000->14x14x8≈1500 → 7x7x12≈500 → 200。下一节中,我们将给出该网络的具体实现。
12、实现:一个卷积网络
为了将我们的代码转化为卷积模型,我们需要为卷积层定义适当的权重张量,然后将该卷积层添加到模型中。我们已经理解到卷积层需要以下形式的权重张量。下面代码是用 TensorFlow 语法来对其初始化:

W = tf.Variable(tf.truncated_normal([4, 4, 3, 2], stddev=0.1))
B = tf.Variable(tf.ones([2])/10) # 2 is the number of output channels
在 TensorFlow 中,使用 tf.nn.conv2d 函数实现卷积层,该函数使用提供的权重在两个方向上扫描输入图片。这仅仅是神经元的加权和部分,你需要添加偏置单元并将加权和提供给激活函数。
stride = 1 # output is still 28x28
Ycnv = tf.nn.conv2d(X, W, strides=[1, stride, stride, 1], padding='SAME')
Y = tf.nn.relu(Ycnv + B)
不要过分在意 stride 的复杂语法,查阅文档就能获取完整的详细信息。这里的填充(padding)策略是为了复制图片的边缘的像素。所有的数字都在一个统一的背景下,所以这仅仅是扩展了背景,并且不应该添加不需要的任何样式。
现在该你了。修改你的模型并将其转化为卷积模型。你可以使用上图中的值来修改它,你可以减小你的学习速率但是务必先移除 dropout。
你的模型的准确率应该会超过 98%,并且最终达到约 99%。眼看目标就要实现,我们不能停止!看看测试的交叉熵曲线。在你的头脑中,此时,是否解决方案正在形成?
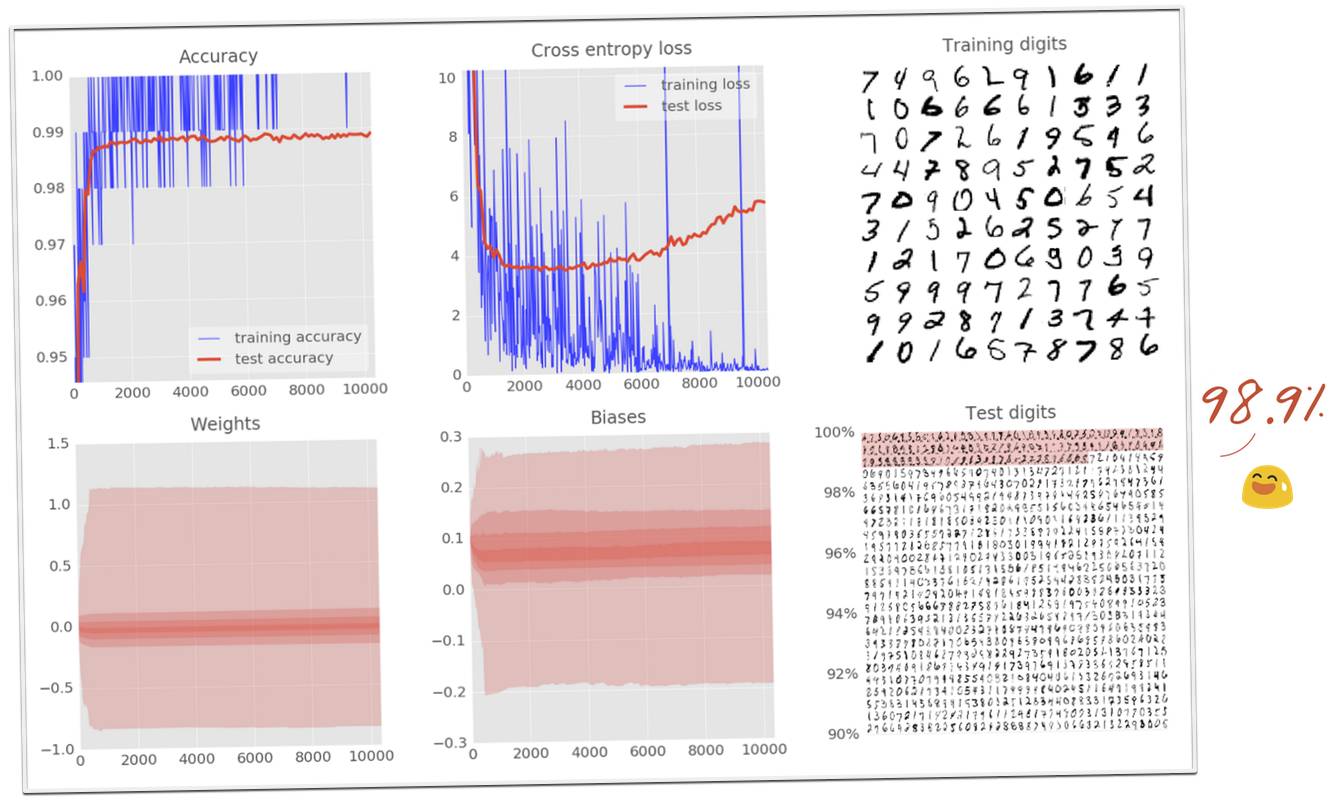
13、99% 准确率的挑战
调整你的神经网络的一个好方法:先去实现一个限制较多的神经网络,然后给它更多的自由度并且增加 dropout,使神经网络避免过拟合。最终你将得到一个相当不错的神经网络。
例如,我们在第一层卷积层中仅仅使用了 4 个 patch,如果这些权重的 patch 在训练的过程中发展成不同的识别器,你可以直观地看到这对于解决我们的问题是不够的。手写数字模式远多于 4 种基本样式。
因此,让我们稍微增加 patch 的数量,将我们卷积层中 patch 的数量从 4,8,12 增加到 6,12,24,并且在全连接层上添加 dropout。它们的神经元重复使用相同的权重,在一次训练迭代中,通过冻结(限制)一些不会对它们起作用的权重,dropout 能够有效地工作。
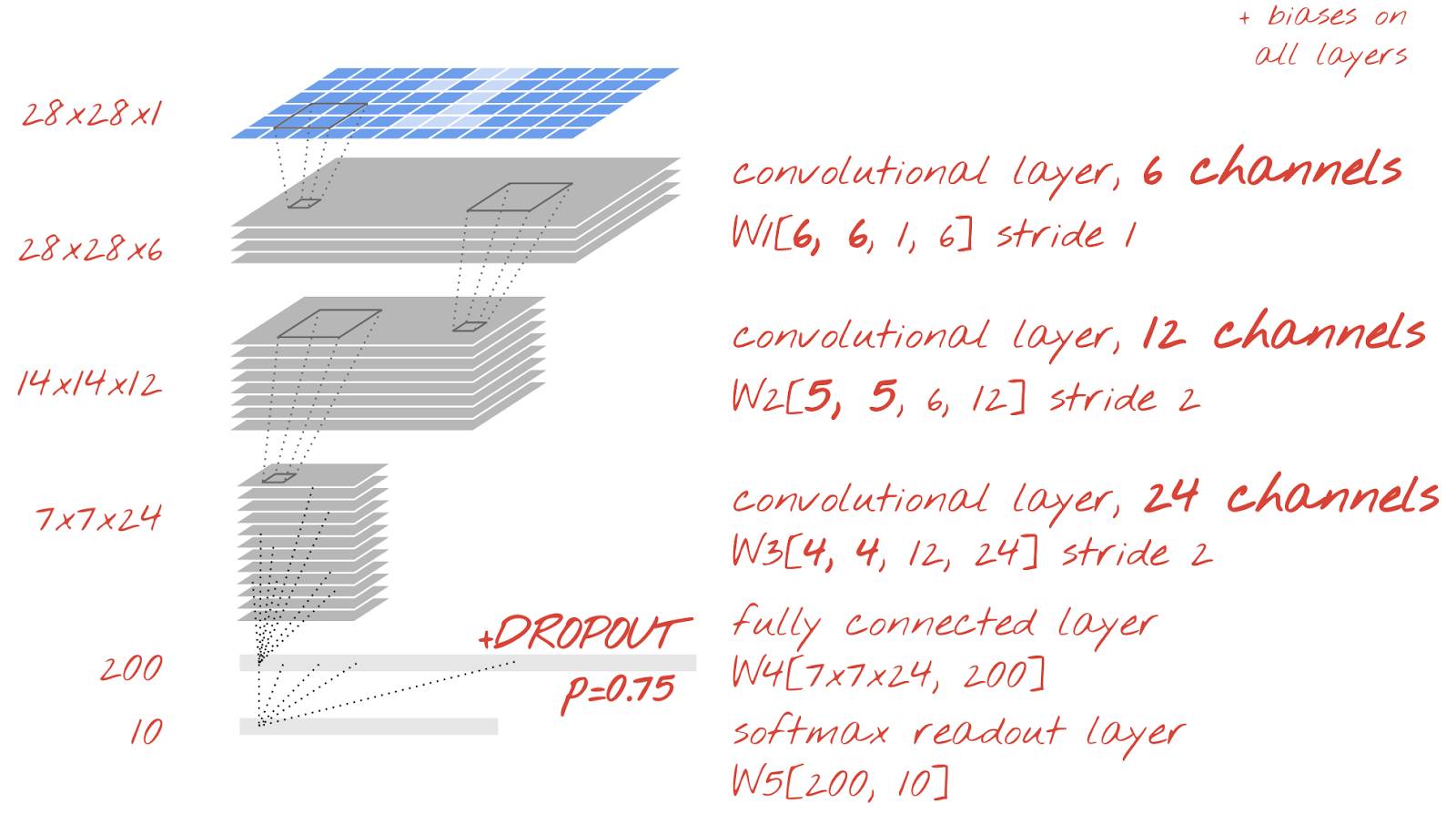
加油吧,去打破 99%的限制。增加 patch 数量和通道的数量,如上图所示,在卷积层中添加 dropout。
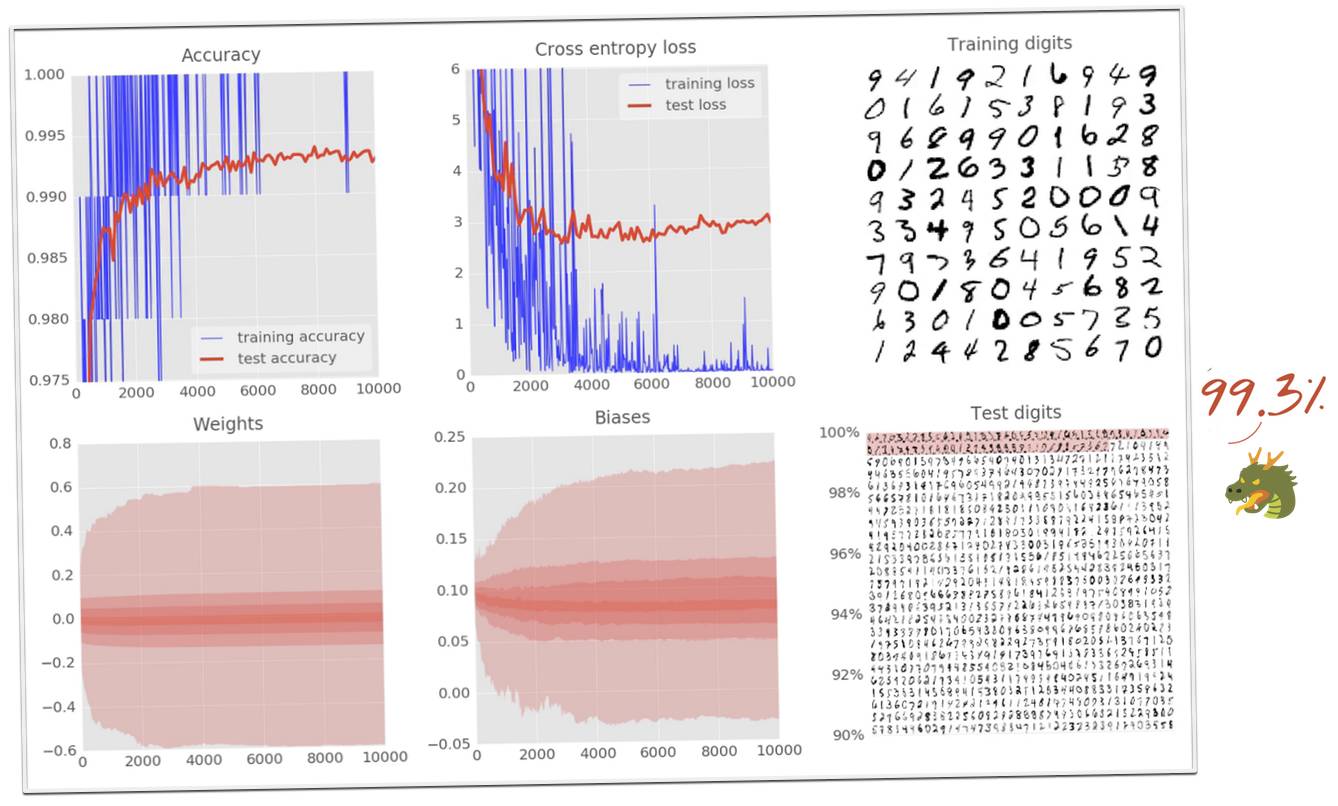
解决方案可以在文件 mnist_3.1_convolutional_bigger_dropout.py 中找到。
使用上图所示的模型,在 10000 个测试的数字中,结果仅仅错误了 72 个。你可以在 MNIST 网站上发现,数字识别准确率的世界纪录大约为 99.7%,这仅比我们用 100 行 Python/TensorFlow 代码构建的模型的准确率高 0.4%。
最后,不同的 dropout 使我们能够训练更大的卷积网络。增加神经网络的额外自由度,使模型的最终准确率从 98.9% 达到 99.1%。向卷积层中增加 dropout 不仅减少了测试误差,而且使我们模型的准确率突破 99%,甚至达到了 99.3%。
14、恭喜!
你已经建立了你的第一个神经网络,并且训练精度达到了 99%。在这个学习过程中,你所学到的技术,并不局限于 MNIST 数据集。实际上,这些技术在训练神经网络的过程中被广泛使用。作为礼物,下面提供的内容可以用来帮助你回忆已经所学的内容。
在完成了完全神经网络和卷积网络后,你应该学习循环神经网络:https://www.tensorflow.org/tutorials/recurrent/。
在本教程中,你已经学习了如何在矩阵层次构建 TensorFlow 模型。Tensorflow 还有更高级的 API,称为 tf.learn:https://www.tensorflow.org/tutorials/tflearn/
要在云上的分布式框架上训练,我们提供 Cloud ML 服务:https://cloud.google.com/ml
最后,我们希望收到你的反馈。如果你在发现了本实验中的些许错误,或者你认为有什么需要改进的地方,请告诉我们。我们通过 GitHub 处理反馈。反馈链接:https://github.com/googlecodelabs/feedback/issues/new?title=[cloud-tensorflow-mnist]:&labels[]=content-platform&labels[]=cloud
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@almosthuman.cn
投稿或寻求报道:editor@almosthuman.cn
广告&商务合作:bd@almosthuman.cn
以上是关于教程 | 没有博士学位,照样玩转TensorFlow深度学习的主要内容,如果未能解决你的问题,请参考以下文章