开源 | 为Go语言设计的机器学习库Gorgonia:对标TensorFlow与Theano
Posted 深度学习世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源 | 为Go语言设计的机器学习库Gorgonia:对标TensorFlow与Theano相关的知识,希望对你有一定的参考价值。
选自GitHub
机器之心编译
参与:侯韵楚、黄小天、蒋思源
Gorgonia 是一个促进在 Go 中进行机器学习的库,旨在更容易地编写与评估涉及多维数组的数学方程。如果这听起来很像 Theano 或者 TensorFlow,原因是三者的想法非常相似。具体而言,Gorgonia 像 Theano 一样相当低级;但又像 Tensorflow 一样具有更高目标。
项目介绍:https://blog.chewxy.com/2016/09/19/gorgonia/
可执行自动微分
可执行符号微分
可执行梯度下降优化
可执行数值稳定
提供了许多便利功能,以助于创建神经网络
非常快(与 Theano 和 Tensorflow 的速度相当)
支持 CUDA / GPGPU 计算(OpenCL 尚不支持,需发送拉取请求)
将支持分布式计算
为何选择 Gorgonia?
Gorgonia 的使用主要方便了开发者。如果你使用 Go 广泛地堆栈,便可以在熟悉而舒适的环境中创建生产就绪的机器学习系统。
机器学习/人工智能通常笼统地分为两个阶段:(a)建立多种模型并测试、再测试的试验阶段,(b)以及模型在测试与试用之后被部署的部署阶段。这两个阶段不可或缺且作用各异,就像数据科学家和数据工程师之间的区别。
原则上这两个阶段使用的工具也不同:实验阶段通常使用 Python / Lua(使用 Theano,Torch 等),而后这个模型会使用性能更高的语言来重新编写,如 C++(使用 dlib、mlpack 等)。当然,如今差距正在慢慢缩短,人们也经常会进行工具共享,比如 Tensorflow 便可用来填补差距。
而 Gorgonia 的目的,却是在 Go 环境中完成相同的事情。目前 Gorgonia 性能相当高,其速度与 Theano 和 Tensorflow 相当(由于目前 Gorgonia 存在 一个 CUDA 缺陷,所以还未完成官方基准测试;另外,因为实现可能会稍有不同,所以很难去比较一个精确的以牙还牙模型)。
安装
安装包是 go-get 的: go get -u github.com/chewxy/gorgonia.
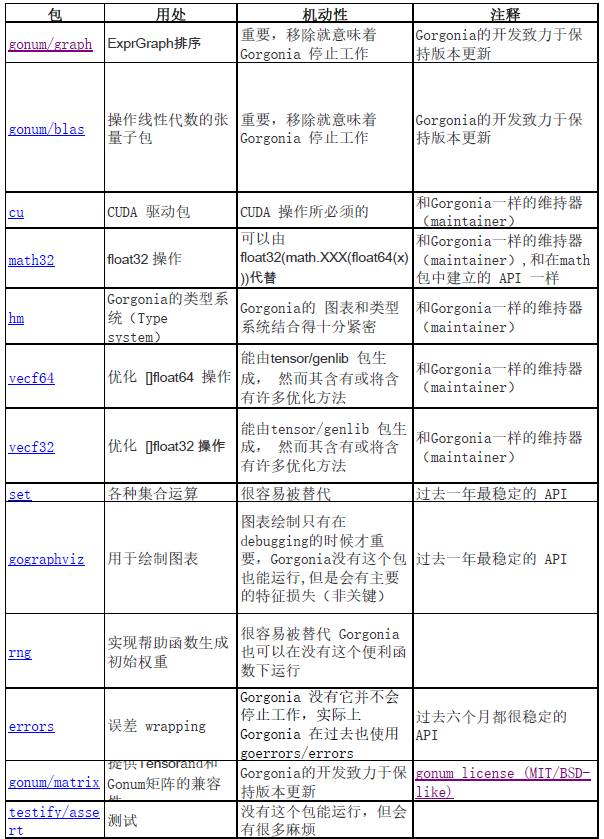
Gorgonia 所使用的依赖很少且都很稳定,所以目前不需要代管工具。下表为 Gorgonia 所调用的外部软件包列表,并按照它所依赖的顺序进行了排列(已省略子软件包):
保持更新
Gorgonia 的项目有一个邮件列表和 Twitter 帐户,官方更新和公告会发布到这两个网站:
https://groups.google.com/forum/#!forum/gorgonia
https://twitter.com/gorgoniaML
用法
Gorgonia 通过创建计算图来工作,而后将其执行。请把它当作一种仅限于数学函数方面的编程语言;事实上,这应当作为用户思考的主要实例。它创建的计算图是一个 AST。
微软 CNTK 的 BrainScript 可能是用来说明计算图的构建与运行并不相同的最佳实例,所以用户对于这二者,应当运用不同的思维模式。
虽然 Gorgonia 的实现并不像 CNTK 的 BrainScript 那样强制性分离思维,但语法确实略有裨益。
此处举出一个实例——若要定义一个数学表达式 z = x + y,应当这样做:
package mainimport ( "fmt"
"log"
. "github.com/chewxy/gorgonia")func main() { g := NewGraph() var x, y, z *Node var err error
// define the expression
x = NewScalar(g, Float64, WithName("x"))
y = NewScalar(g, Float64, WithName("y"))
z, err = Add(x, y) if err != nil {
log.Fatal(err)
} // compile into a program
prog, locMap, err := Compile(g) if err != nil {
log.Fatal(err)
} // create a VM to run the program on
machine := NewTapeMachine(prog, locMap) // set initial values then run
Let(x, 2.0) Let(y, 2.5) if machine.RunAll() != nil {
log.Fatal(err)
}
fmt.Printf("%v", z.Value()) // Output: 4.5}
你可能会发现,它比其他类似的软件包更显冗长。如 Gorgonia 并未编译为可调用的函数,而是特地编译为需要TapeMachine 来运行的program;此外它还需要手动调用一个 Let(...)。
作者却认为这是好事——能够将人的思维转变为机器的思维。它在我们想查清哪里出错的时候很有帮助。
虚拟内存系统
当前版本的 Gorgonia 有两个虚拟内存系统:
TapeMachine
LispMachine
它们功能不同,采取的输入也不同。TapeMachine 通常更善于执行静态表达式(即计算图并不改变);由于其静态特性,它适用于一次编写,多次运行的表达式(如线性回归,SVM 等)。
LispMachine 则是将图形设为输入,并直接在图形的节点上执行。如果图形有所改变,只需新创建一个轻量级 LispMachine 来执行便可。LispMachine 适于诸如创建大小不固定的循环神经网络这类的任务。
在 Gorgonia 发布之前存在第三个虚拟内存,它基于堆栈,且与 TapeMachine 相似,但能够更妥善地处理人工梯度。当作者解决了所有的问题后,它也许就能重见天日。
微分
Gorgonia 执行符号与自动微分,而这两个过程存在细微差别。作者认为这样理解是最合适的:自动微分是在运行时所做的微分,与图表的执行同时发生;符号微分是在编写阶段所做的微分。
此处「运行时」当然是指表达式图的执行,而非程序的实际运行。
通过介绍这两个虚拟内存系统,便很容易理解 Gorgonia 如何执行符号与自动微分。使用与上文相同的示例,读者 能够发现此处并没有进行微分。这次用 LispMachine 做一次尝试吧:
package mainimport ( "fmt"
"log"
. "github.com/chewxy/gorgonia")func main() { g := NewGraph() var x, y, z *Node var err error
// define the expression
x = NewScalar(g, Float64, WithName("x"))
y = NewScalar(g, Float64, WithName("y"))
z, err = Add(x, y) if err != nil {
log.Fatal(err)
} // set initial values then run
Let(x, 2.0) Let(y, 2.5) // by default, LispMachine performs forward mode and backwards mode execution
m := NewLispMachine(g) if m.RunAll() != nil {
log.Fatal(err)
}
fmt.Printf("z: %v\n", z.Value()) xgrad, err := x.Grad() if err != nil {
log.Fatal(err)
}
fmt.Printf("dz/dx: %v\n", xgrad) ygrad, err := y.Grad() if err != nil {
log.Fatal(err)
}
fmt.Printf("dz/dy: %v\n", ygrad) // Output:
// z: 4.5
// dz/dx: 1
// dz/dy: 1}
当然,Gorgonia 同样支持更传统的的符号微分,比如在 Theano 中:
package mainimport ( "fmt"
"log"
. "github.com/chewxy/gorgonia")func main() { g := NewGraph() var x, y, z *Node var err error
// define the expression
x = NewScalar(g, Float64, WithName("x"))
y = NewScalar(g, Float64, WithName("y"))
z, err = Add(x, y) if err != nil {
log.Fatal(err)
} // symbolically differentiate z with regards to x and y
// this adds the gradient nodes to the graph g
var grads Nodes
grads, err = Grad(z, x, y) if err != nil {
log.Fatal(err)
} // compile into a program
prog, locMap, err := Compile(g) if err != nil {
log.Fatal(err)
} // create a VM to run the program on
machine := NewTapeMachine(prog, locMap) // set initial values then run
Let(x, 2.0) Let(y, 2.5) if machine.RunAll() != nil {
log.Fatal(err)
}
fmt.Printf("z: %v\n", z.Value()) xgrad, err := x.Grad() if err != nil {
log.Fatal(err)
}
fmt.Printf("dz/dx: %v | %v\n", xgrad, grads[0]) ygrad, err := y.Grad() if err != nil {
log.Fatal(err)
}
fmt.Printf("dz/dy: %v | %v\n", ygrad, grads[1]) // Output:
// z: 4.5
// dz/dx: 1 | 1
// dz/dy: 1 | 1}
虽然人们在 Gorgonia 中,能嗅到支持 dualValue 存在条件下进行正向模式微分的旧版痕迹,但其目前仅执行反向模式自动微分(又名反向传播)。正向模式微分也许在将来能够回归。
图表
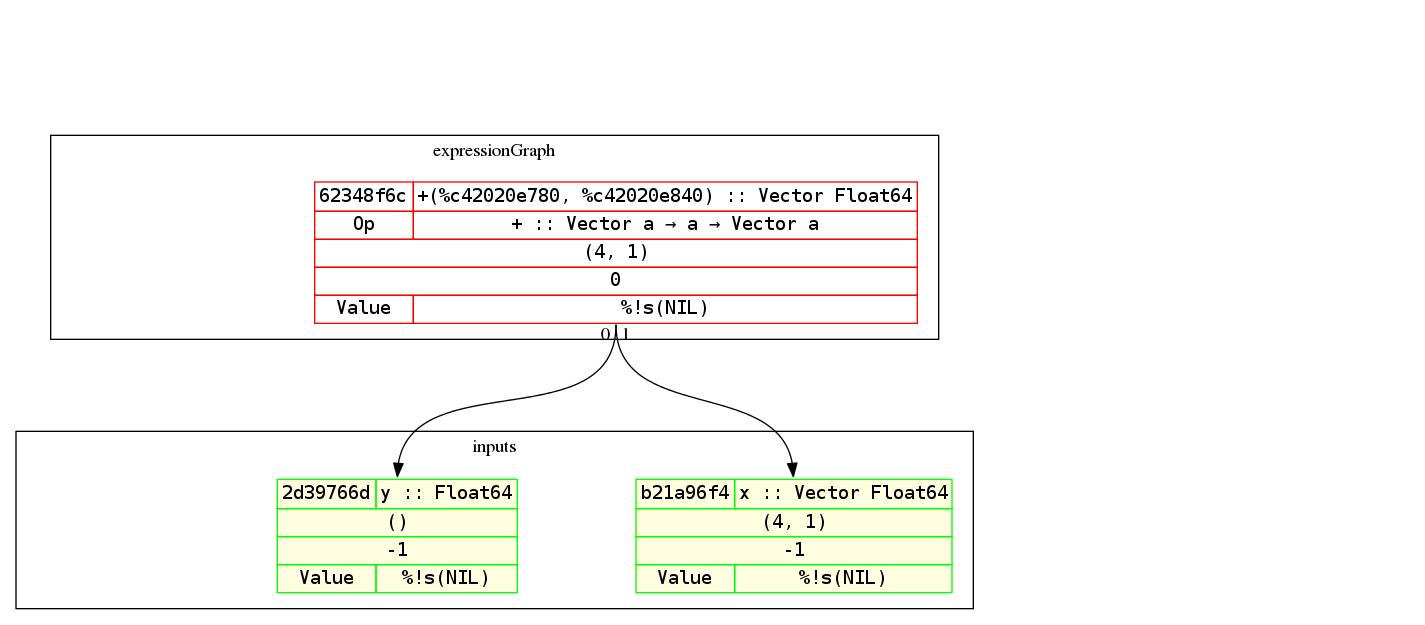
确实存在许多计算图或表达式图的有关说法,但它究竟是什么?请将它想象成你想要的数学表达式的 AST。此处为上述示例的图形(但还有一个向量和一个标量加法):
顺便一提,Gorgonia 的图形打印能力很强。此处为方程式 y = x² 及其导数的图形示例:
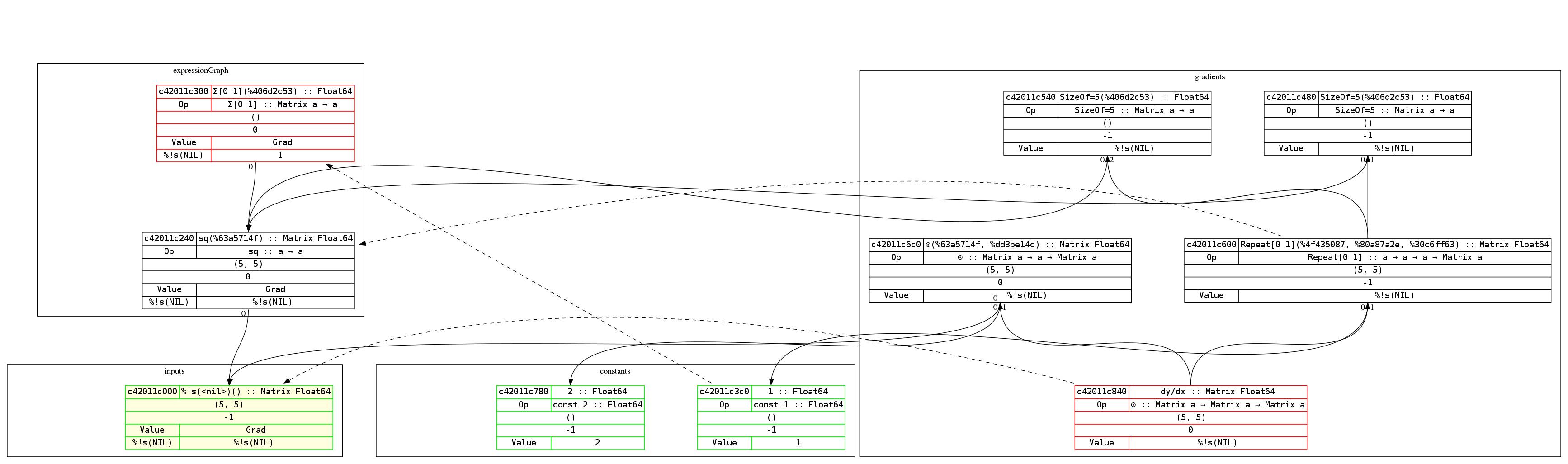
图形很容易阅读。表达式从下往上进行构建,而导数是由上向下构建的。因此每个节点的导数大致处于同一水平。
红色轮廓的节点表示它们是根节点,而绿色轮廓则表示为叶节点,带有黄色背景的节点表示为输入节点,而虚线箭头则表示哪个节点是指向节点的梯度节点。
具体而言,比如 c42011e840 (dy/dx) 便表示输入 c42011e000(即 x)的梯度节点。
节点渲染
节点是这样渲染的:

补充说明:
如果它是输入节点,则 Op 行不会显示。
如果没有绑定到节点的值,将显示为 NIL。但若有值和梯度存在,它将极尽所能显示绑定到节点的值。
使用 CUDA
此外,还存在附加要求:
1. 需要 CUDA toolkit 8.0。安装这个程序将会安装 nvcc 编译器,这是使用 CUDA 运行代码所必备的。
2. go install github.com/chewxy/gorgonia/cmd/cudagen。这是 cudagen 程序的安装网址。运行 cudagen 将生成与 Gorgonia 有关的 CUDA 相关代码。
3. 务必使用 UseCudaFor 选项,务必使代码中的 CUDA 操作能够手动启用。
4. runtime.LockOSThread() 必须在虚拟内存正在运行的主函数中调用。CUDA 需要线程亲和性,因此必须锁定 OS 线程。
示例
所以,我们该如何使用 CUDA 呢?假设有一个文件 main.go:
import ( "fmt"
"log"
"runtime"
T "github.com/chewxy/gorgonia"
"github.com/chewxy/gorgonia/tensor")func main() { g := T.NewGraph() x := T.NewMatrix(g, T.Float32, T.WithName("x"), T.WithShape(100, 100)) y := T.NewMatrix(g, T.Float32, T.WithName("y"), T.WithShape(100, 100)) xpy := T.Must(T.Add(x, y)) xpy2 := T.Must(T.Tanh(xpy)) prog, locMap, _ := T.Compile(g) m := T.NewTapeMachine(prog, locMap, T.UseCudaFor("tanh"))
T.Let(x, tensor.New(tensor.WithShape(100, 100), tensor.WithBacking(tensor.Random(tensor.Float32, 100*100))))
T.Let(y, tensor.New(tensor.WithShape(100, 100), tensor.WithBacking(tensor.Random(tensor.Float32, 100*100))))
runtime.LockOSThread() for i := 0; i < 1000; i++ { if err := m.RunAll(); err != nil {
log.Fatalf("iteration: %d. Err: %v", i, err)
}
}
runtime.UnlockOSThread()
fmt.Printf("%1.1f", xpy2.Value())
}
如果它正常运行:
go run main.go
CUDA 不会被使用。
如果程序要使用 CUDA 运行,那么必须进行调用:
go run -tags='cuda'
即便如此,也只有 tanh 函数使用 CUDA。
解释
使用 CUDA 的要求这么复杂,主要与其性能有关。正如 Dave Cheney 的名言:cgo 不是 Go。但不幸的是,使用 CUDA 必定需要 cgo;而若要使用 cgo,则需做出大量权衡。
因此,解决方案是将 CUDA 相关代码嵌套于构建标记 cuda 中,以这样的方式默认未使用 cgo(好吧,只用了一点点,你仍然可以使用 cblas 或 blase)。
安装 CUDA toolkit 8.0 的原因是:存在许多 CUDA 计算能力,为它们生成代码将产生一个毫无益处的巨大二进制。相反,用户会倾向于为他们特定的计算能力编译。
最后,要求制定使用 CUDA 操作的明确规范,是由于 cgo 调用的成本问题。目前为了实现批量的 cgo 调用而在进行额外的努力,但是直到完成之前,该解决方案都会是特定操作的「升级」关键。
CUDA 支持的操作
迄今为止,只有极基本的简单操作能够支持 CDUA:
元素一元运算:
abs
sin
cos
exp
ln
log2
neg
square
sqrt
inv (reciprocal of a number)(数字的倒数)
cube
tanh
sigmoid
log1p
expm1
softplus
元素二进制操作——只有算术运算支持 CUDA:
add
sub
mul
div
pow
根据对作者个人项目的大量剖析,发现真正重要的是 tanh、sigmoid、expm1、exp 和 cube,即激活函数。其他使用 MKL + AVX 的操作正常运行,且并非造成神经网络缓慢的主因。
CUDA 的改进
在一项次要的基准测试中,CUDA 的谨慎使用(此情况通常调用 sigmoid)显示出非 CUDA 代码的大幅改进(考虑到 CUDA 内核十分朴素且未优化):
BenchmarkOneMilCUDA-8 300 3348711 ns/op BenchmarkOneMil-8 50 33169036 ns/opAPI 的稳定性
Gorgonia 的 API 如今并不稳定,它将从 1.0 版本开始慢慢稳定。
1.0 版本是测试覆盖率达到 90%时所定义的,并且相关的 Tensor 方法已经完成。
路线图
这是依照重要性排序所列出的 Gorgonia 的目标:
80%以上的测试覆盖率。目前 Gorgonia 的覆盖率为 50%,tensor 为 80%。
更高级的操作(如 einsum)。目前的 Tensor 操作符非常原始。
软件包中的 TravisCI。
软件包中的 Coveralls。
清除测试。测试是多年积累的结果,妥当地重构它们将大有裨益。若条件允许,使用表格驱动测试。
提升性能,特别是应当重新分配,将系统类型的影响最小化。
将 Op 界面从半输出公开/更改为全输出,以此提高 Op 的可扩展性(或者为扩展性创建一个 Compose 的 Op 类型)。这样每个人都可以制作自定义的 Op。
为了跟随 CUDA 的实现,重构 CuBLAS 以及 Blase 软件包。
分布式计算。尝试多个机器上传播作业并彼此通信已至少 3 次,但无一成功。
更好地记录做出某些决定的原因,并从宏观上对 Gorgonia 进行设计。
高阶导数优化算法(LBFGS)
无导数的优化算法
目标
Gorgonia 的主要目标是成为一个基于机器学习/图形计算,能够跨多台机器进行扩展的高性能库。它应将 Go(简单的编译和部署过程)的呼吁带至机器学习领域。这条路还很漫长,然而我们已然迈出了第一步。
其次要目标是为非标准的深度学习和神经网络相关事物提供一个探索平台,其中包括 neo-hebbian 学习、角切割算法、进化算法等。
显然,由于你在 Github 上阅读的可能性最大,Github 将构建该软件包工作流程的主要部分以完善该软件包。
参见:CONTRIBUTING.md
贡献者与重要贡献者
我们欢迎任何贡献。但还有一类新的贡献者,称为重要贡献者。
重要贡献者是对库的运作方式和/或其周围环境有深刻理解的人。此处举出重大贡献者的例子:
撰写了大量与特定功能/方法的原因/机制,及不同部分相互影响的方式的有关文档
编写代码,并对 Gorgonia 更复杂的连接的部分进行了测试
编写代码和测试,并且至少接受 5 个拉取请求
对软件包的某些部分提供专家分析(比如你可能是优化一个功能的浮点操作专家)
至少回答了 10 个支持性问题
重要贡献者列表将每月更新一次(如果有人使用 Gorgonia)。
如何获得支持
如今最好的支持方式,便是在 Github 上留言。
常见问题
为什么在测试中似乎出现了 runtime.GC() 的随机调用?
答案非常简单:软件包的设计使其以特定的方式使用 CUDA:具体而言,一个 CUDA 设备及其景况会绑定一个虚拟内存,而不是软件包。这意味着对于每个创建的虚拟内存,其每一设备每一个虚拟内存都会创建不同的 CUDA 景况。因此在其他可能正在使用 CUDA 的应用程序中,所有操作都能够正常运行(然而这需要进行压力测试)。
CUDA 的景况只有在虚拟内存回收垃圾(经由终结器函数的帮助)时才会被销毁。在测试中大约会创建 100 个虚拟内存,并且大多数垃圾回收是随机的;当景况被使用过多时,会导致 GPU 内存耗尽。
因此,在任何可能使用 GPU 的测试结束时,会调用 runtime.GC() 来强制垃圾回收,以释放 GPU 内存。
人们在生产过程中不太可能启动过多的虚拟内存,因此这并不是问题。若有问题,请在 Github 上留言,我们会想办法为虚拟内存添加一个 Finish() 方法。
许可
Gorgonia 根据 Apache 2.0 的变体授权。其所有意图与目的 Apache 2.0 的许可相同,除了重要贡献者(如软件包的商业支持者),其他人均不能直接从中获得商业利润。但从 Gorgonia 的衍生直接获利是可行的(如在产品中使用 Gorgonia 作为库)。所有人都可将 Gorgonia 用于商业目的(如用于业务软件)。
各类其他版权声明
这是在写 Gorgonia 的过程中有所启发和进行改编的软件包和库(使用的 Go 软件包已经在上文做出了声明):
✄------------------------------------------------
点击“阅读原文”了解同声译
↓↓↓
以上是关于开源 | 为Go语言设计的机器学习库Gorgonia:对标TensorFlow与Theano的主要内容,如果未能解决你的问题,请参考以下文章