重磅|2016 ScaledML会议演讲合辑:谷歌Jeff Dean讲解TensorFlow,微软陆奇解读FPGA(附PPT)
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重磅|2016 ScaledML会议演讲合辑:谷歌Jeff Dean讲解TensorFlow,微软陆奇解读FPGA(附PPT)相关的知识,希望对你有一定的参考价值。
选自 matroid
机器之心编译
参与:杜夏德、吴攀、李亚洲、微胖
本文主要介绍了 Jeff Dean(谷歌)、 陆奇(微软)、Ilya Sutskever(Open AI) 在 The Scaled Machine Learning Conference 2016 上的演讲。Jeff Dean 做了名为《使用 TensorFlow 的大规模深度学习》的演讲报告。这次报告和今年 3 月份李世石与 AlphaGo「人机大战」期间 Jeff Dean 所做的《用于智能计算机系统的大规模深度学习》的报告有一些共同之处(详情参阅机器之心之前的解读)。但是,这份新的演讲报告也仍有一些值得关注的新内容,尤其是在 TensorFlow 和谷歌 5 月份推出的张量处理单元(TPU)方面。陆奇在《微软的机器学习》演讲中第一次深入介绍了微软在FPGA方面的工作。来自 Open AI 的 Ilya Sutskever 介绍了该机构最新研究。详情可参阅 。
机器学习正朝着利用新硬件(比如 GPU和大型商业集群)的方向演进。大学和产业研究人员已经在使用这些新的计算平台多维扩展机器学习。2016年8月2日,斯坦福大学和 Matroid 公司举办了 The Scaled Machine Learning Conference 2016。
会议旨在让在各种不同计算平台上运行机器学习算法的研究人员汇聚一堂,彼此交流,并鼓励算法设计人员互相帮助,在平台之间扩展、移植、交流不同想法。

这次会议演讲者包括:陆奇(微软)、Jeff Dean(谷歌)、Ilya Sutskever(OpenAI)、Reza Zadeh(Stanford 和 Matroid)、John Canny (伯克利、谷歌) 、Lise Getoor(UCSC)、Ted Dunning(MapR)、Leah McGuire(Salesforce)、Xavier Amatriain(Quora)以及 Martin Wicke(谷歌)。

演讲者演讲主题一览:








一、Jeff Dean:使用 TensorFlow 的大规模深度学习

P2:谷歌大脑(Google Brain)团队介绍
关注长期人工智能研究的研究团队;拥有很多计算机系统和机器学习研究专家;专注纯粹的机器学习研究,以及机器人、语言理解、医疗等新兴机器学习应用领域背景中的研究。

P3:我们通过以下几种方式传播我们的研究成果:
发表我们的成果,详情查阅:http://research.google.com/pubs/BrainTeam.html
以开源项目的形式发布了我们的核心机器学习研究系统 TensorFlow
发布我们在 TensorFlow 里面实现的研究模型
与谷歌的产品团队合作,将我们的研究变成真正的产品

P4:我们的目标
构建能从经验中学习的人工智能算法和系统,并使用这些算法和系统解决困难的问题以造福人类。


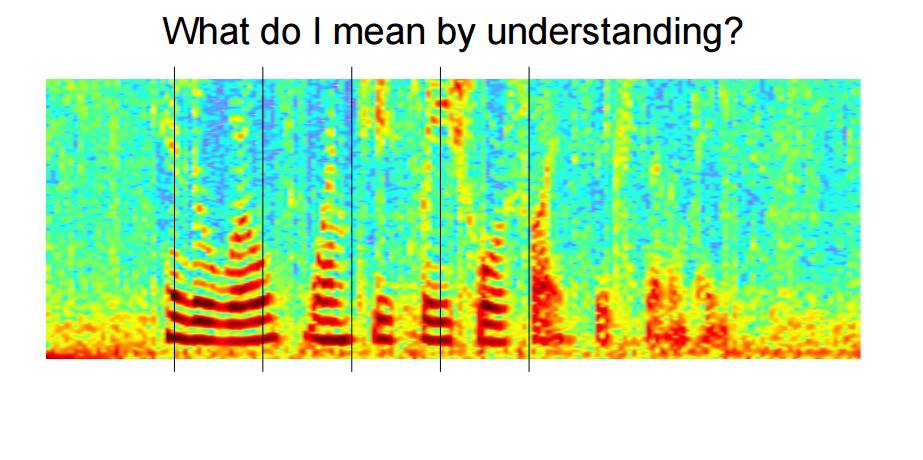
P5-7:理解就是要读懂这些图片中所隐含的信息和知识


P8-9:比如说对于查询 [car parts for sale(待售汽车零件)],如果以部分关键词的形式搜索结果,可能得到[… car parking available for a small fee(便宜的停车位)]和[… parts of our floor model inventory for sale(待售的陈列品清单的部分)]这样的无用结果。如果实现了理解,就可能得到[Selling all kinds of automobile and pickup truck parts,engines, and transmissions.(销售各种汽车和小型货车零件、引擎和传动装置)]这样比较的我们想要的结果,尽管其中只有[parts]一个关键词。

P10:未来需求的例子
这些眼睛图片中哪些带有糖尿病视网膜病的症状?
帮我找到北美的所有屋顶
用西班牙语描述这个视频
帮我找到所有和用于机器人的强化学习相关的文档,并用德语进行总结
找一个 Smart Calendar 项目组里面所有人都有空的时间,安排一次视频会议
机器人,请从小吃厨房给我拿一杯茶
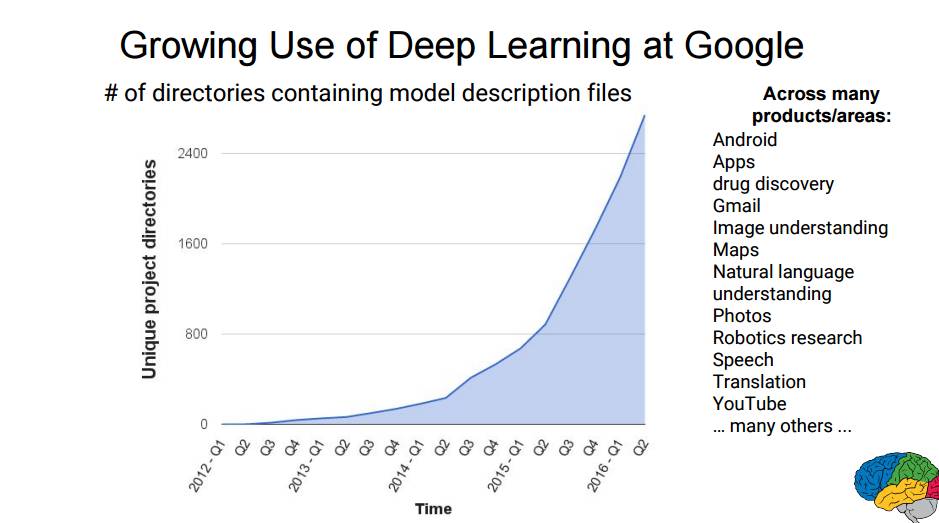
P11:谷歌对深度学习的应用快速增长。
如图为包含模型描述文件的独特项目目录的数量随时间的变化曲线,这项目横跨多种产品和领域:安卓、应用、药物发现、Gmail、图像理解、地图、自然语言理解、Photos、机器人研究、语音、翻译、YouTube……
P12:神经网络的重要性质
更多数据+更大的模型+更多计算=越来越好的结果
更多的算法、新的见解和改进的技术也总是会有帮助
P13:随便一提
目前很多成功的技术都是 20-30 年前开发出来的。现在有什么不同呢?现在我们有「足够的计算资源」和「大量足够的有趣的数据集」,另外大规模并行的应用让我们也可以知道未来的许多代硬件提升。

P14:你的机器学习系统应该具备哪些特性?
易于表达:对大量疯狂的机器学习想法/算法而言
可扩展性:可以快速运行实验
可移植性:可以在各种平台上运行
再现性:易于共享和重现研究
生产准备:从研究到实际产品

P15:TensorFlow
http://tensorflow.org/ 和 https://github.com/tensorflow/tensorflow
用于通用机器学习的开放的、标准的软件
对深度学习尤其好
2015 年 11 月首次发布
Apache 2.0 协议
P16:TensorFlow:异构分布式系统上的大规模机器学习
http://www.tensorflow.org/whitepaper2015.pdf

P17:TensorFlow:一种大规模机器学习系统
http://arxiv.org/abs/1605.08695 和机器之心的报道(google brain 论文)
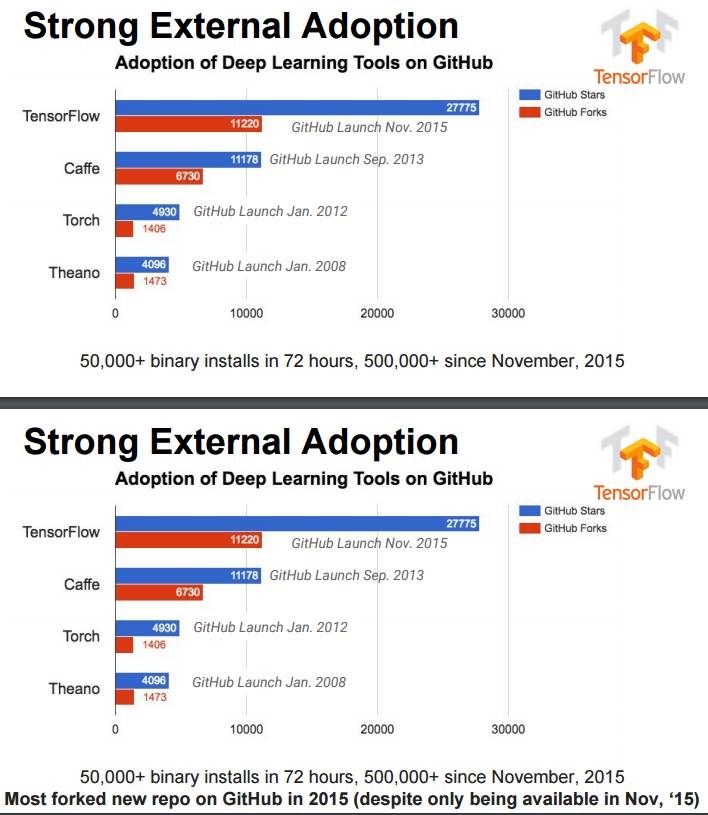
P18-19:GitHub 上各种深度学习工具的采用情况
发布 72 小时内实现 50,000 多次二进制安装,从 2015 年 11 月以来安装量已经超过了 500,000.
GitHub 上大部分 Fork 发生在 2015 年(尽管 2015 年 11 月才发布)
P20:网站上的教程位置

P21:TensorFlow 的动力
DistBelief(我们的第一个系统)是第一个可扩展的深度学习系统,但没有我们研究目的所需的那种灵活性
对问题空间的更好理解让我们实现一些极大的简化
定义机器学习的行业标准
解决 MapReduce/Hadoop 的低效


P22-24:TensorFlow:表达高水平的机器学习计算
核心用 C++ 编写,额外开销非常低
用于指定/驱动计算的不同前端,目前是 Python 和 C++,容易添加更多
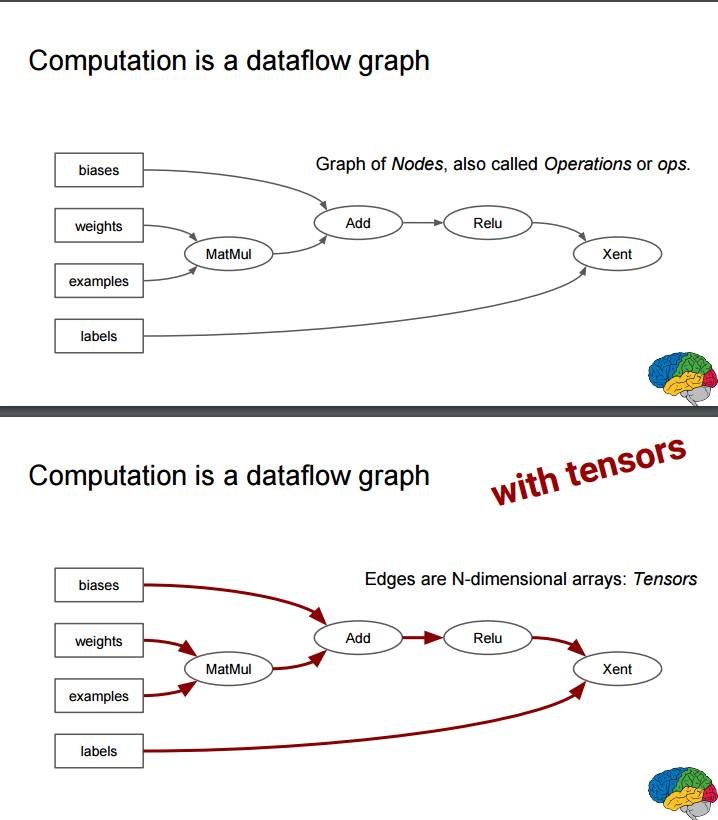
P25-26:计算是一个数据流图谱(使用张量(tensor)
样本和权重进行矩阵相乘,然后加入偏置,再输入 ReLU(修正线性单元),最后在 Xent 中与标签进行匹配
P27:TensorFlow 代码片段例子:创建一个计算一个神经网络接口的图谱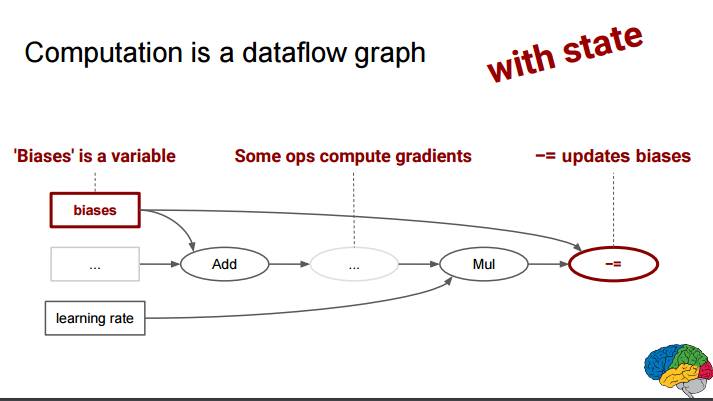
P28:计算是一个数据流图谱(使用状态(state))
P29:符号微分
自动添加指令来计算关于损失函数的变量的符号梯度
使用一个优化算法来应用这些梯度

P30:定义图谱,然后重复地执行
启动图谱并在环路中运行训练指令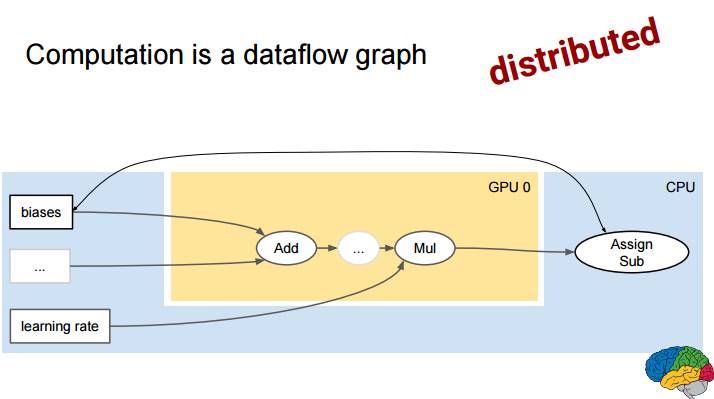
P31:计算是一个数据流图谱(分布式)
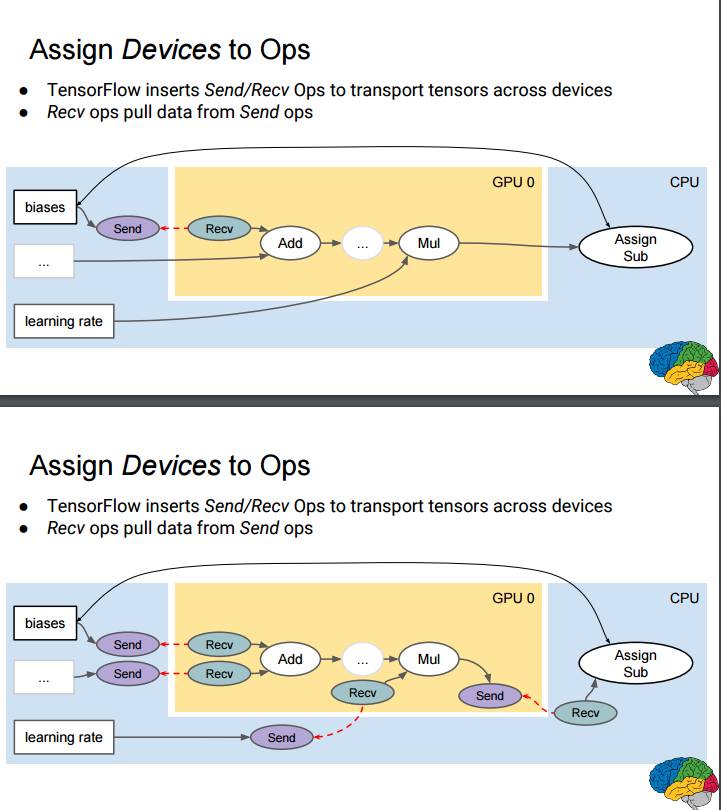
P32-33:将设备分配到张量
TensorFlow 插入 Send/Recv 指令来跨设备传输张量
Recv 指令从 Send 指令中拉取数据
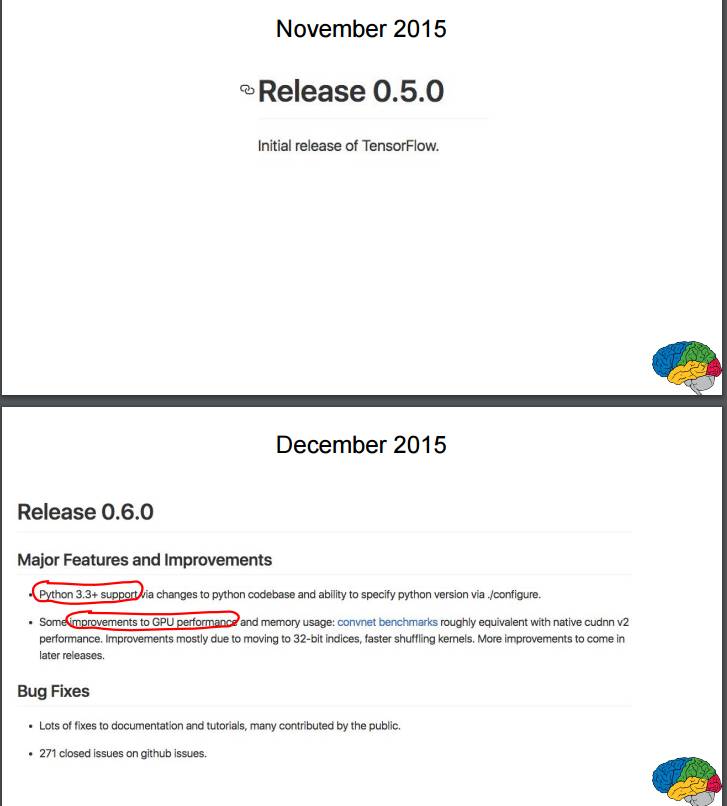

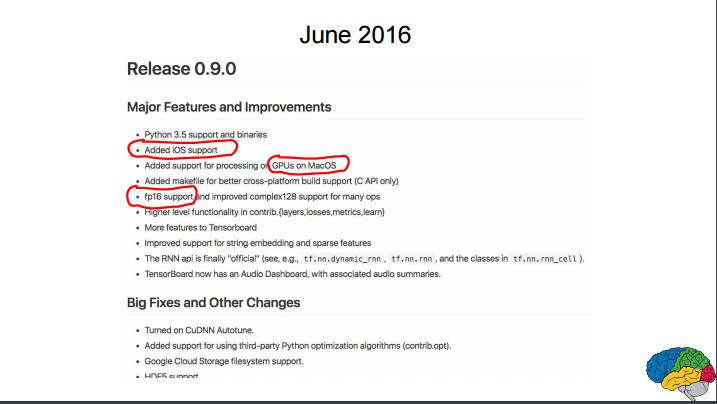
P34-38:2015 年 11 月首次发布 0.5.0 版;2015 年 12 月更新 0.6.0 版;2016 年 2 月更新 0.7.0 版;2016 年 4 月更新 0.8.0 版;2016 年 6 月更新 0.9.0 版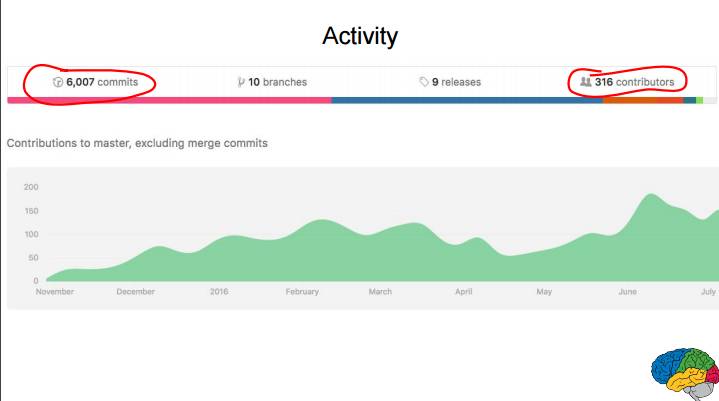
P39:GitHub 上的活动:已有 316 位贡献者共计 6007 次提交
P40:实验周转时间和研究生产力
分钟、小时:互动研究! 及时行乐!
1-4 天:可容忍的,交互性被并行运行许多实验替代
1-4 周:仅限高价值的实验;进程拖延
大约 1 个月:不要尝试
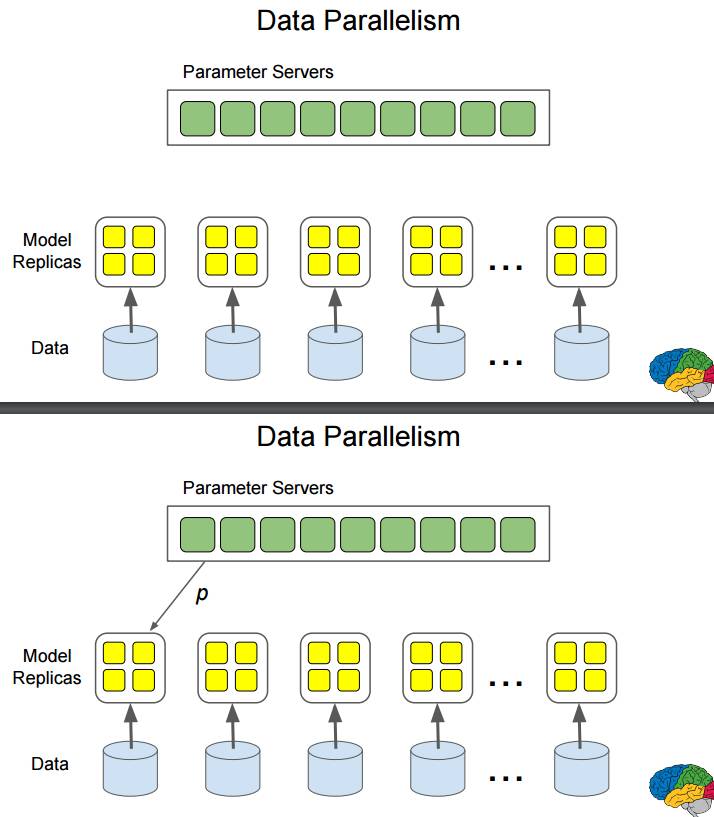
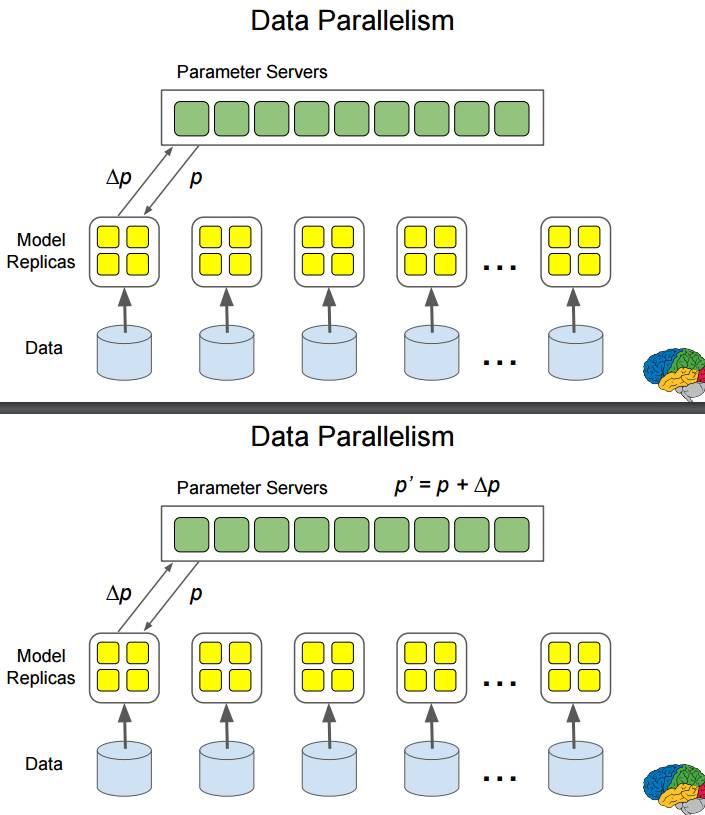
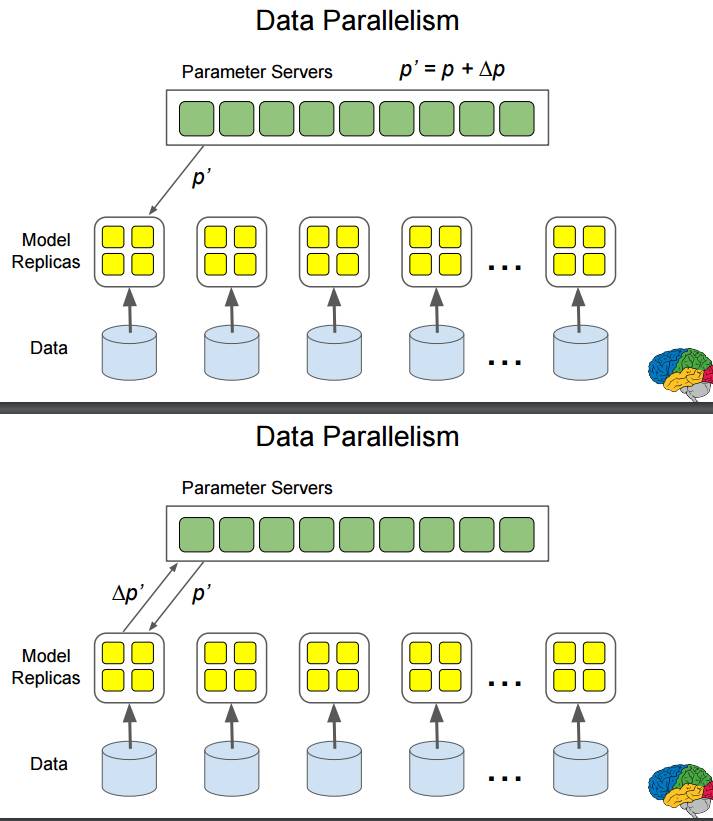
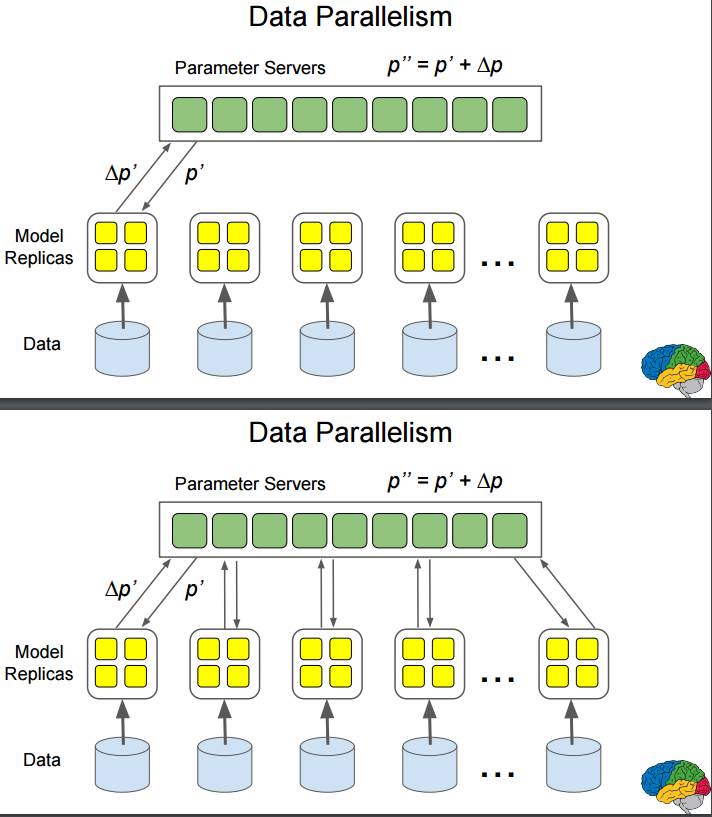
P42-49:数据并行:数据输入多个模型副本,同时进行计算。
首先,参数服务器为一个模型配置参数 p,得到反馈 Δp;然后计算出新参数 p';再将参数 p' 配置给该模型得到反馈 Δp';再计算出新参数 p"
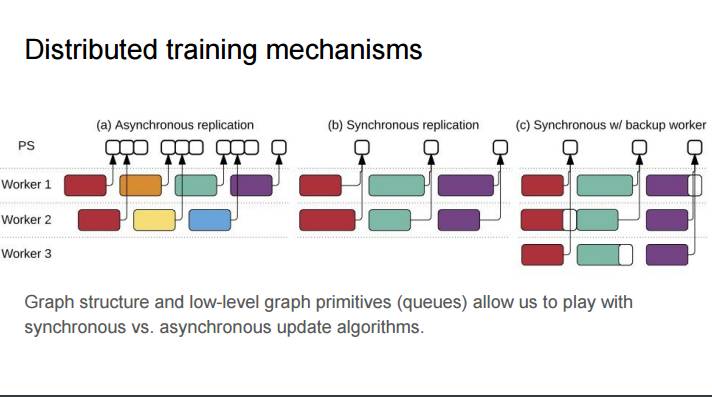
P50:分布式训练机制
(a)异步复制 (b)同步复制 (c) 带有备份工作器的同步
图谱结构和低水平图谱基元(队列)让我们可以使用同步 vs. 异步更新算法
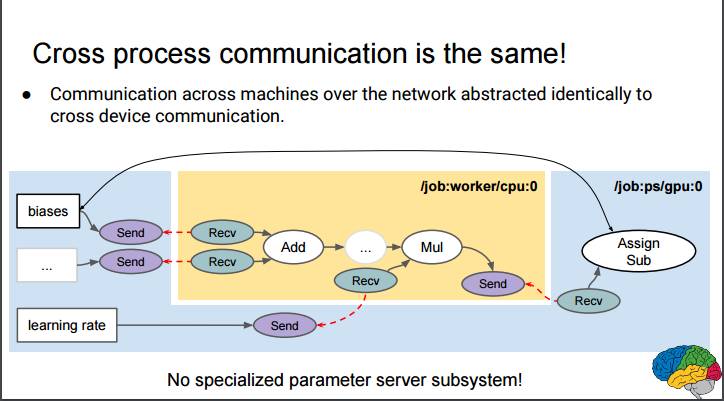
P51:跨进程通信还是一样!
网络中跨机器的通信可以完全抽象为跨进程的通信
没有特定参数服务器子系统!
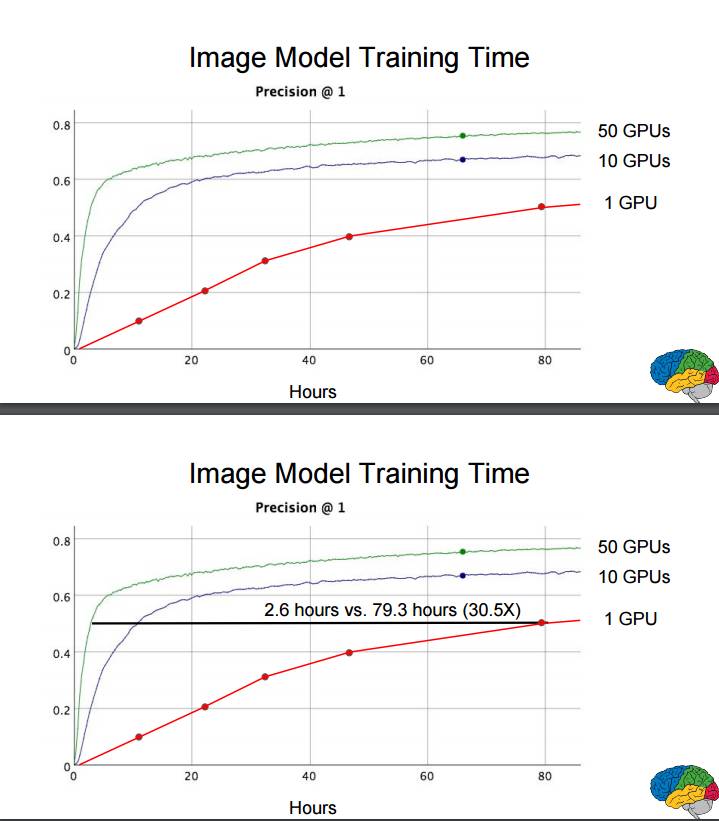
P52-53:图像模型的训练时间
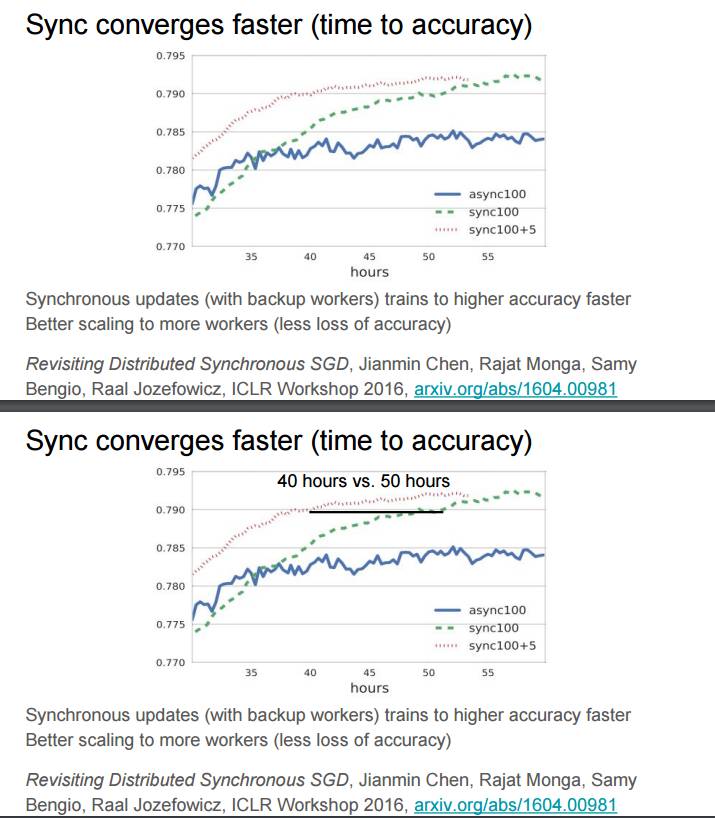
P54-55:同步的收敛更快(考虑精度的时间)
同步更新(带有备份工作器)可以更快训练出更高的精度
更好地扩展至更多工作器(更少的精度损失)
参考论文:Revisiting Distributed Synchronous SGD http://arxiv.org/abs/1604.00981

P56:通用计算
尽管我们起初是为我们自己的围绕深度神经网络的应用开发的 TensorFlow,但其十分灵活。许多种类的机器学习和其它类型的数值计算都可以在该计算图谱模型中进行表示。

P57:可以运行在不同类型的平台上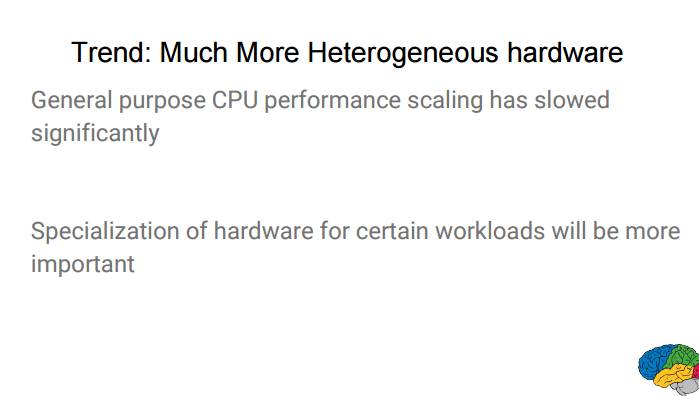
P58:趋势:远远更加异构的硬件
通用 CPU 的性能增长已经显著减缓,为特定工作负载设计的定制硬件将越来越重要。
P59:张量处理单元
定制化机器学习 ASIC。已在生产中使用了 16 多个月的时间:用在每一次搜索查询中,用于 AlphaGo 的比赛……
参见:https://cloudplatform.googleblog.com/2016/05/Google-supercharges-machine-learning-tasks-with-custom-chip.html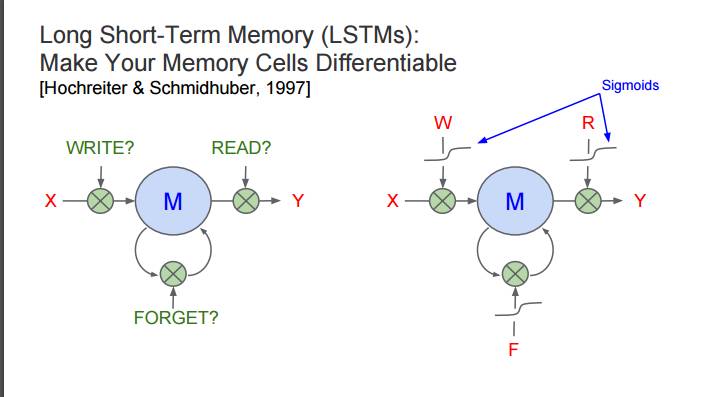
P60:长短期记忆(LSTM):让你的记忆细胞可微分 [Hochreiter & Schmidhuber, 1997]
P78:深度学习对谷歌有哪些显著的影响方式?
使用 TensorFlow 或我们之前的系统实现的所有案例
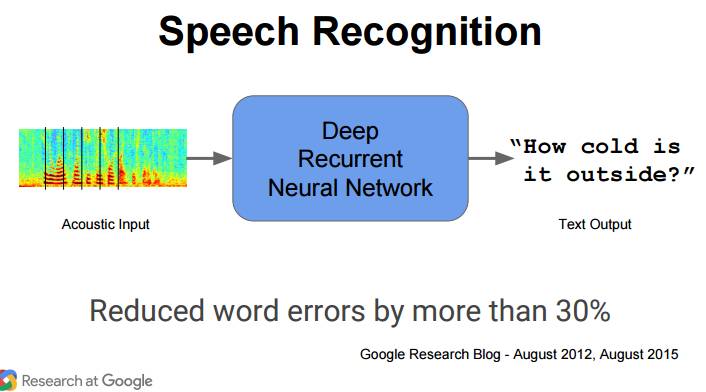
P79:语音识别
声音输入→深度循环神经网络→文本输出
减少词错误 30%
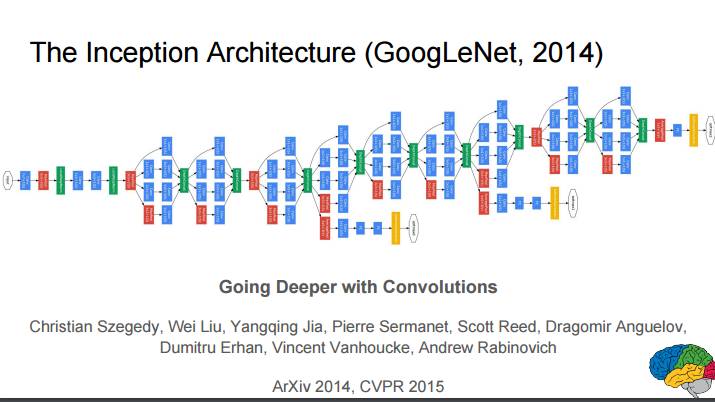
P80:Inception 架构(GoogLeNet, 2014)
使用卷积做到更深
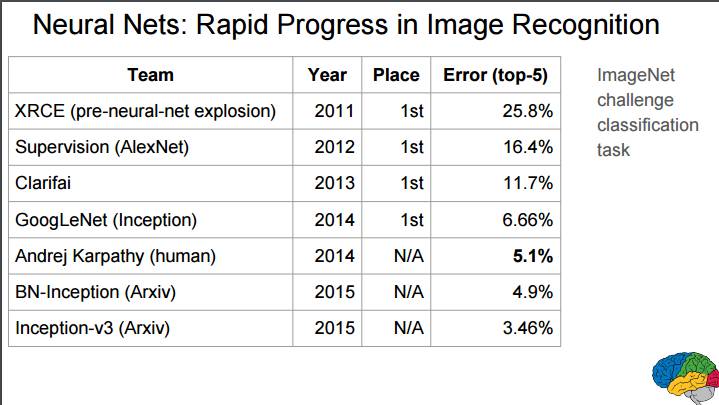
P81:神经网络:图像识别的快速进展
ImageNet 挑战赛分类任务的误差率对比
P82 Google Photos 搜索
照片→深度卷积神经网络→自动标签
搜索不带标签的个人照片

P84-87:为完全不同的问题重新使用相同的模型
在不同的数据上训练的相同的基本模型结构,在完全不同的语境中很有用。比如:对于给定的图像→预测有趣的像素
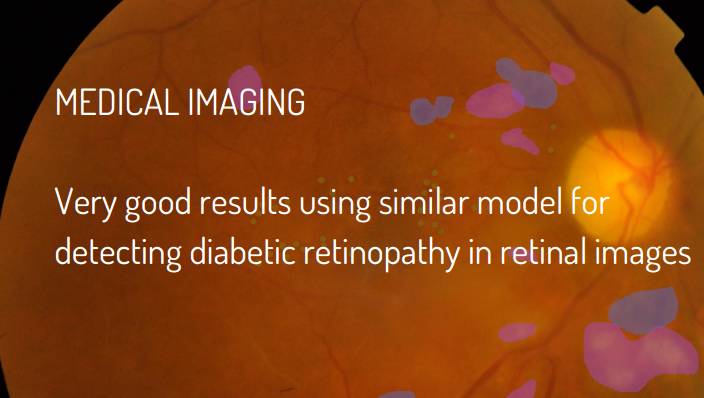
P88:医学成像
使用相似的模型用于检测视网膜图像中的糖尿病视网膜病变,可以得到很好的结果
P89:围棋

P90:谷歌搜索排序中的 RankBrain 使用了深度神经网络
RankBrain 推出于 2015 年,是第三重要的搜索排序信号
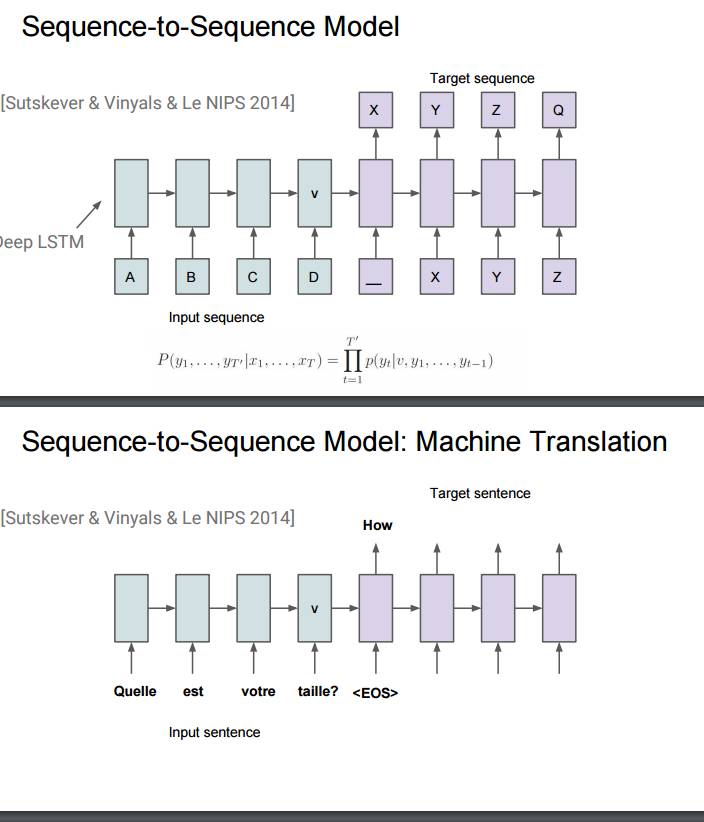
P91-96:序列到序列模型在机器翻译上的应用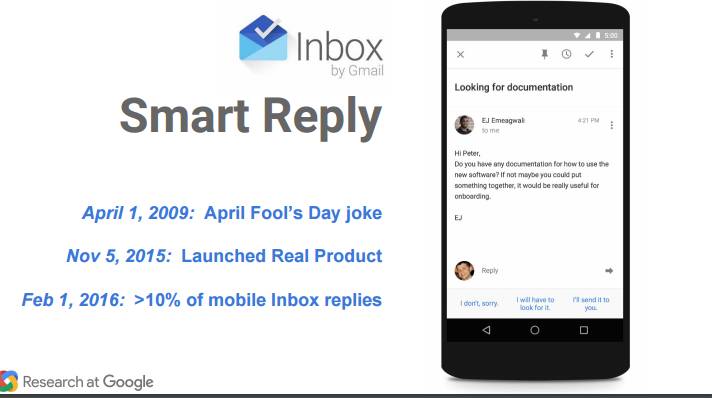
P97-99:Inbox 的智能回复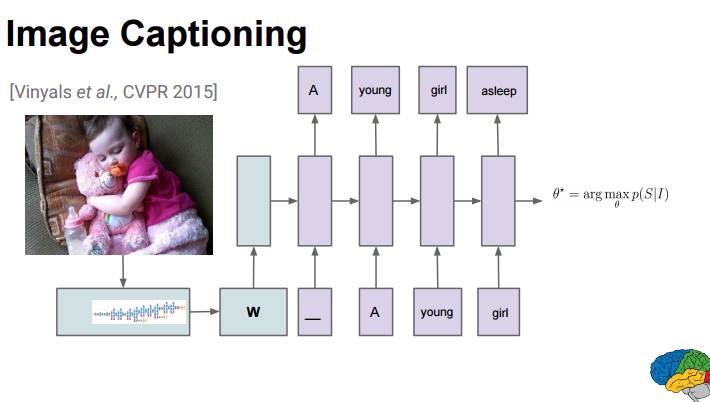
P100-101:图像描述研究
对于这样一张图片,人和模型的描述:
人类:抱着一个毛绒小熊的小女孩在沙发上睡觉
模型:小孩抱着填充玩具动物的特写
模型:一个婴儿在一个泰迪熊旁睡觉
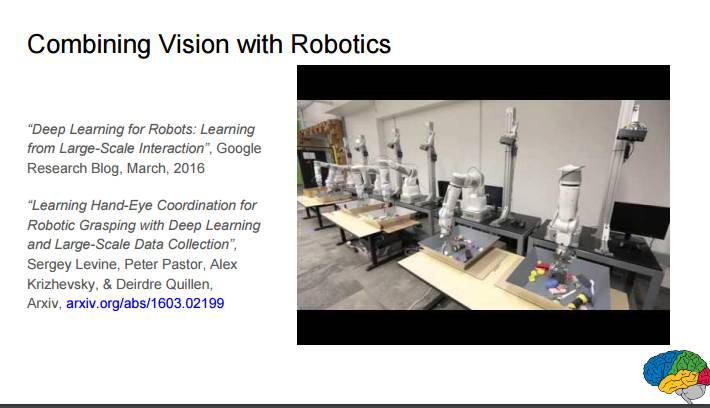
P103:视觉和机器人的结合
用于机器人的深度学习:从大规模交互中学习;Google Research Blog, March, 2016
使用深度学习和大规模数据收集学习用于机器人抓取的手眼协作;http://arxiv.org/abs/1603.02199
P104:你怎么开始使用机器学习?
根据复杂度的不同,有三种不同的方式(越灵活,就越需要更多工作):
(1):使用基于云的 API(视觉、语音等)
(2):使用已有的模型架构,然后根据你自己的数据集进行再训练或微调
(3):为新问题开发你自己的机器学习模型
P105-107:使用基于云的 API
谷歌翻译 API:http://cloud.google.com/translate
云语音 API(Alpha):http://cloud.google.com/speech
云视觉 API:http://cloud.google.com/vision
云文本 API:http://cloud.google.com/text
P108:谷歌云机器学习:使用 TensorFlow 的扩展的训练服务和接口
P109-116:TensorFlow 社区的一些案例(截至目前,GitHub 上可搜索到 2100 多条与 tensorflow 有关的结果)
● DQN: github.com/nivwusquorum/tensorflow-deepq
● NeuralArt: github.com/woodrush/neural-art-tf
● Char RNN: github.com/sherjilozair/char-rnn-tensorflow
● Keras ported to TensorFlow: github.com/fchollet/keras
● Show and Tell: github.com/jazzsaxmafia/show_and_tell.tensorflow
● Mandarin translation: github.com/jikexueyuanwiki/tensorflow-zh
P117:展望未来
深度学习的使用将会继续增长和加速,将跨越来越多的领域,解决越来越多的问题:机器人、自动驾驶汽车、医疗保健、视频理解、对话系统、个人助理……
P118:总结
深度神经网络正在语音、视觉、语言、搜索、机器人等领域的理解问题上大步向前。
如果你还没考虑如何使用深度神经网络解决你的视觉或理解问题,你也差不多应该开始了。
P119:延伸阅读
Dean, et al., 大规模分布式深度网络, NIPS 2012, research.google.com/archive/large_deep_networks_nips2012.html.
● Mikolov, Chen, Corrado & Dean. 向量空间中词表征的有效评估, NIPS 2013, arxiv.org/abs/1301.3781.
● Sutskever, Vinyals, & Le, 使用神经网络的序列到序列学习, NIPS, 2014, arxiv.org/abs/1409.3215.
● Vinyals, Toshev, Bengio, & Erhan. Show and Tell: 一种神经图像描述生成器. CVPR 2015. arxiv.org/abs/1411.4555
● TensorFlow 白皮书, tensorflow.org/whitepaper2015.pdf
二、陆奇 : 微软的机器学习
1. 我们做什么
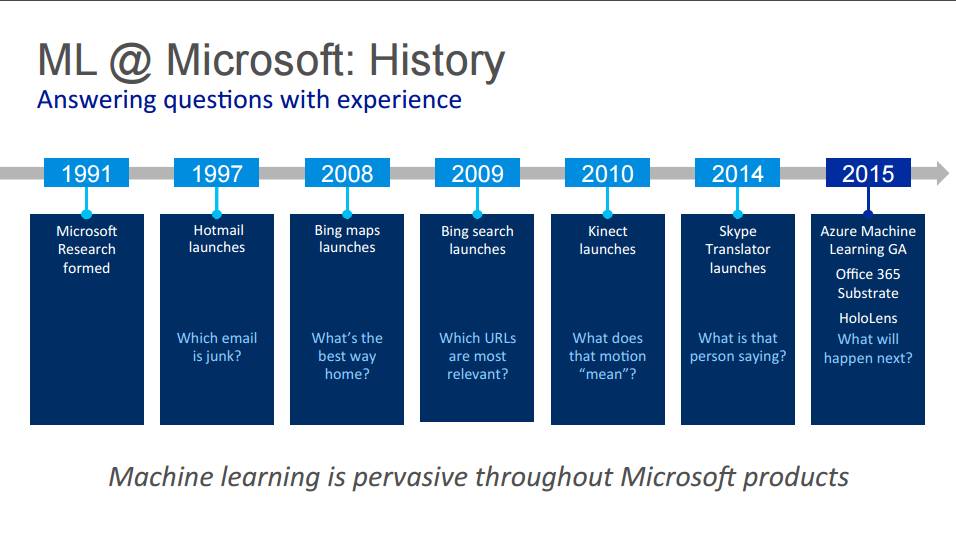
P4:微软的机器学习:历史。用经历回答问题
1991 年微软研究院组建
1997 年发布 Hotmail——哪些电子邮件是垃圾邮件?
2008 年必应地图发布——回家的最佳路线是什么?
2009 年必应搜索发布——哪个 URL 是最相关的?
2010 年 Kinect 发布——动作到底「意味」着什么?
2014 年 Skype 翻译器发布——这个人在说什么?
2015 年微软推出 Azure 机器学习云服务 GA 版、Office 365 Substrate、HoloLens——接下来会发生什么?
机器学习遍布微软的产品之中。

P5:微软的机器学习:前行
数据=>模型=>智能=>创新动力
应用 & 服务
Office 365、Dynamic 365(Biz SaaS)、Skype、必应、Cortana
数字化办公 & 数字化生活
模型:世界、组织、用户、语言、环境……
计算设备
PC、平板、手机、可穿戴设备、Xbox、HoloLens(AR/VR)......
模型:自然用户界面、现实......云
Azure 基础设施和平台
Azure 机器学习工具 & 服务
智能服务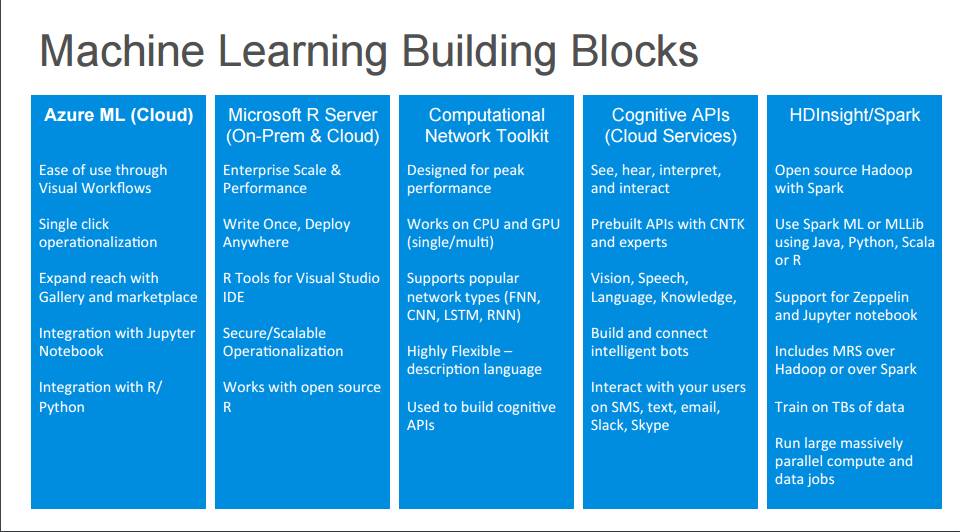
P6:机器学习建筑模块
Azure 机器学习(云)
通过 Visual Workflows 可轻松使用
通过 Gallery 和市场触及更多人
与 Jupyter Notebook 融合
集成 R 语言/Python
微软 R 服务器(On-Prem & 云)
企业级的规模 & 性能
编写一次,随地部署
Visual Studio IDE 的 R 工具
安全/可拓展的操作化
使用开源的 R 语言计算网络工具包(CNTK)
为顶尖性能而设计
支持 CPU 和 GPU(单个/多个)
支持流行的网络类型(FNN、CNN、LSTM、RNN)
高度灵活的描述语言
可用于构建认知 API认知 API(云服务)
听、视、解释与交互
使用 CNTK 与专家预建 API
视觉、语音、语言、知识
建立并连接智能 bot
在 SMS、文本、电子邮件、Slack、Skype 上与用户交互HDInsight/Spark
开源带有 Spark 的 Hadoop
使用 Spark ML 或 MLLib(使用语言是 Java、Python、Scala 或 R)
支持 Zeppelin 和 Jupyter Notebook
在 TB 级的数据上进行训练
运行大规模并行计算与数据工作
P7:Azure 机器学习服务
轻松使用带有 drag/drop(拖放) 范式的工具,单击操作化
内建支持列表数据与文本的统计函数、数据摄取、转换、特征生成/选择、训练、得分,从而进行分类、聚类、推荐、异常点检测。
R/Python 无缝融合对 SQL lite 的支持,以进行过滤与转换
进行数据探索的 Jupyter Notebook,快速开始的 Gallery 延展
用于文本处理、关键语句提取、语言检测、n-gram 生成、LDA、压缩特征哈希(compressed feature hash)、基于统计异常点检测的模块。
Spark/HDInsight/MRS 融合
GPU 支持
新布局
计算预订
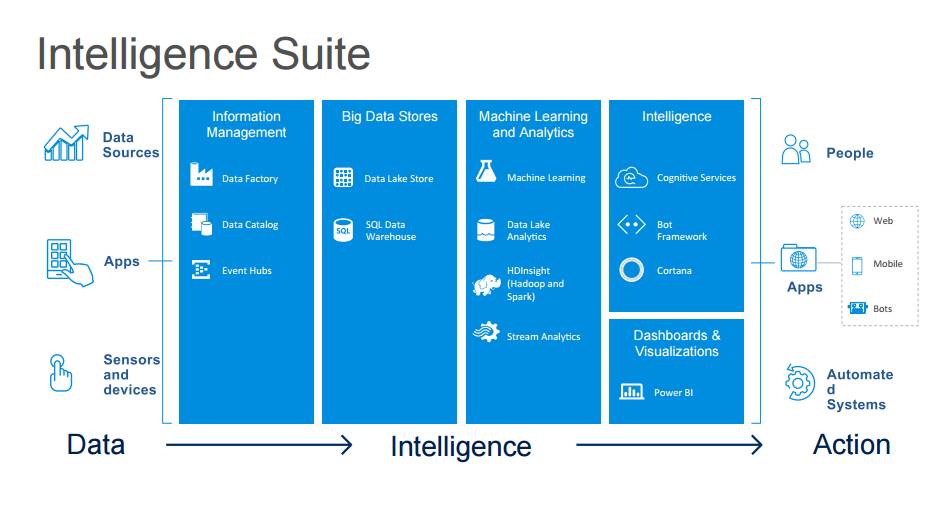
P8:智能组件
数据→智能→行为
P9:认知服务
视觉认知:计算机视觉、面部识别、情绪、视频
语音:讲话者识别、语音识别、定制的识别
语言:文本分析、必应拼写检查、网页语言模型、语言学分析、语言理解、翻译
知识:学术知识、实体链接服务、知识发现服务、推荐
搜索:必应搜索 API、必应图片搜索 API、必应视频搜索 API、必应新闻搜索 API、必应自动建议 API
2. 我们如何规模化

P11:规模化的关键维度
数据量/维度
模型/算法复杂性
训练/评估时间
部署/升级速度
开发者生产率/创新灵活性
基础设施/平台
软件框架/工具
数据集/算法

P13:样例详解 CNTK:计算网络工具包
CNTK 是微软开源的、跨平台的工具包,可用于学习和评估特别是深度神经网络这样的模型。
CNTK 可通过将简单的建筑模块组合进复杂的计算网络而表达任意神经网络,支持常见的网络类型和应用。
CNTK 可部署在产品中:准确、高效、可扩展至多 GPU/多服务器。

P14:CNTK 开发
在公司内外开源开发模型
有微软语音研究员于四年前创立,在 2015 年早期开源
在 Github 上,从 2016 年 1 月处于公共许可协议下
几乎所有的开发都是开放的驱动应用:语音、必应、HoloLens、微软研究院的 研究
每个团队都有全职员工积极为 CNTK 做贡献
CNTK 训练的模型是在产品环境下测试与部署的外部贡献:
比如来自 MIT 和斯坦福大学的贡献平台和运行时间
Linux、Windows、.Net、docker、cudnn5
Python、C++,C# API 即将会有
P15:CNTK 设计目标 & 方法
一个深度学习框架要平衡:
效率:能够尽快地训练产品系统
性能:产品系统能够在基准任务上获得一流的表现
灵活性:能够支持不断增加的、大量的任务,比如语音、视觉、文本;
能够非常快速地尝试新思路。
乐高一样的可组合性:
支持许多类型的网络,例如,前馈 DNN、RNN、CNN、LSTM、DSSM、序列到序列
进化与适应 :
为新兴的流行模式进行设计
P16:关键功能与能力
支持
CPU 和 GPU,集中在 GPU 集群。
自动数值微分
通过批处理进行有效统计与循环网络训练
机器内和跨机器的数据并行,比如,1 位的量化 SGD
在实施规划期间进行内存共享分割成几大模块
计算网络
执行引擎
学习算法
模型描述
数据阅读器模型描述方式
网络定义语言(NDL)和模型编辑语言(MEL)
带有易于理解的句法的 Brain Script(beta 版)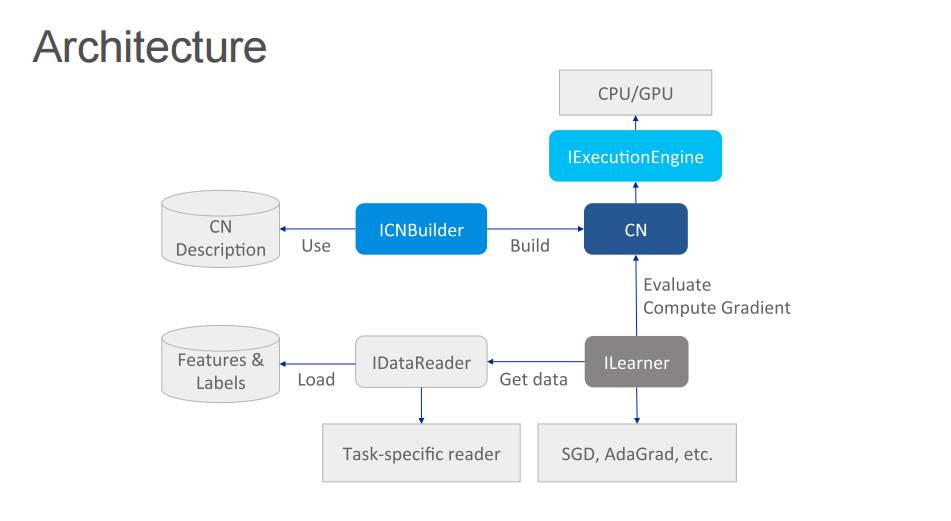
P17:架构
P18:路线图
CNTK 作为库
支持更多语言:Python/C++/C#/.Net更具表现力
嵌套循环、稀疏支持对学习器出色的控制
带有非标准循环的 SGD,比如强化学习更大的模型
模型并行、存储交换、16 位浮点Azure 上更强大的 CNTK 服务
更快的 GPU、更长期的集群、容器、新硬件,比如 FPGA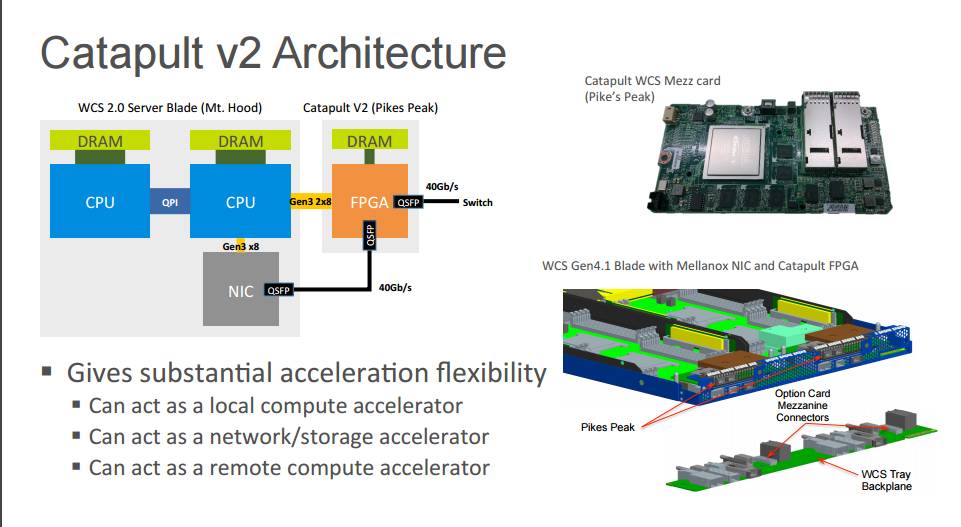
P20:详解样例 FPGA:Catapult v2 架构
给予显著的加速灵活性
可充当局域计算加速器
可充当网络/存储加速器
可充当远程计算加速器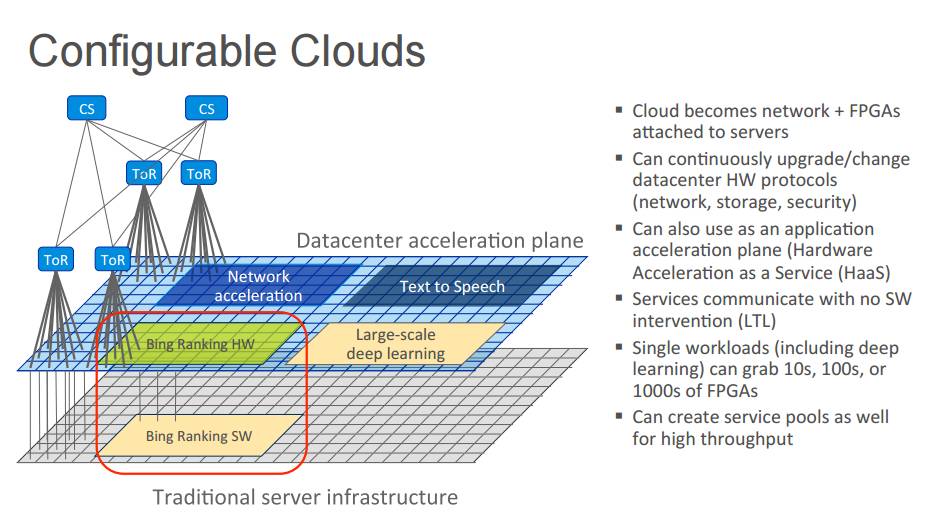
P21:可配置云
云成为了附着到服务器的网络 + FPGA
能够连续不断的升级/改变数据中心硬件的协议(网络、存储、安全)
也能作为应用加速器使用(硬件加速即服务,Hardware Acceleration as a Service,HaaS)
无软件打断的服务交流(线性时序逻辑)
单负载(包括深度学习)能攫取 FPGA 的10s、100s、或者 1000s
能创造高吞吐量的服务池
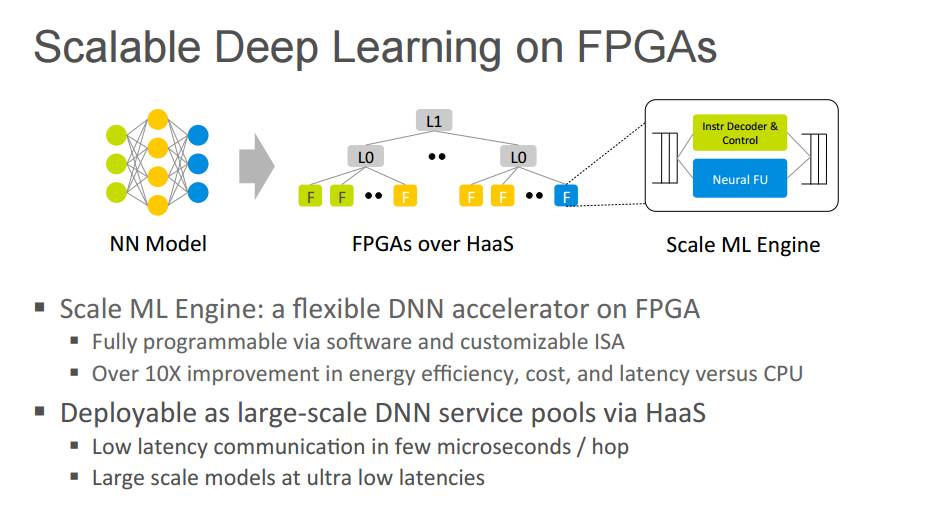
P22:FPGA 上的可扩展深度学习
可扩展机器学习引擎:FPGA 上的一个灵活的 DNN 加速器
通过软件和可定制的 ISA 全部可编程
相对于 CPU,在能源利用率、成本和延迟性能上有了 10 倍的提升
通过 HaaS,可部署为大规模 DNN 服务池
通信延迟低至数微秒
有着极其低延迟的大规模模型
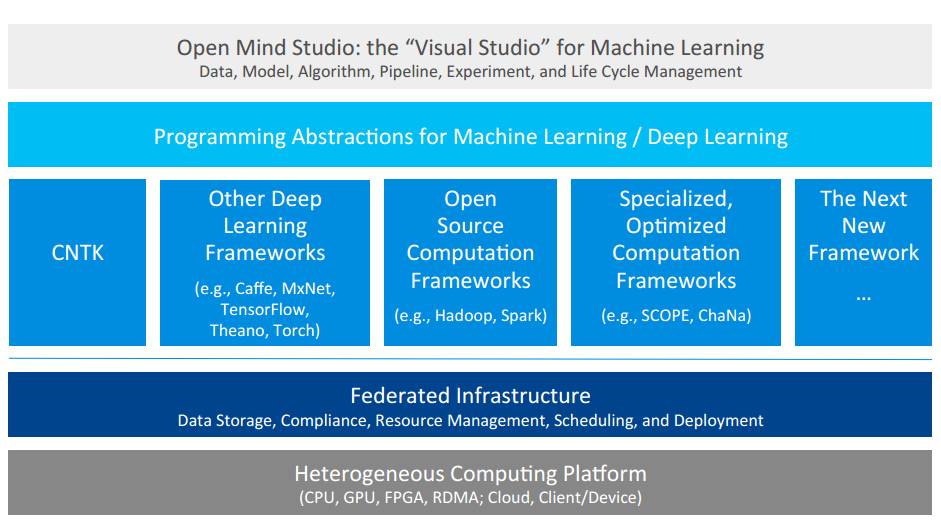
P24:详解样例 Open Mind
Open Mind Studio:机器学习「Visual Studio」
数据、模型、算法、管道、实验和生命周期管理
机器学习/深度学习编程抽象
CNTK、其他深度学习框架(如 Caffe、MxNet、TensorFlow、Theano、Torch)、开源计算框架(如 Hadoop、Spark)、专门优化过的计算框架(如 SCOPE、ChaNa)、下一代新框架……
联合基础设施:数据存储、审计、资源管理、调度与部署
异步计算平台:CPU、GPU、FPGA、RDMA;Cloud、Client/Device
P25:ChaNa:RDMA 优化过的计算框架注重更快的网络
紧凑的存储表征
平衡的并行
高度优化过的明确 RDMA 的通信基础
交流和计算重叠
对早期结果的一系列大幅度改进
超越现有的使用 TCP 的计算框架
生产中有数个大规模的负载
P26:机器学习的编程抽象
进行分布式机器学习的图像引擎
自动系统层级的优化
并行和分布式
设计有效的数据访问
为均衡的并行处理进行划分
有前途的早期结果
通过高层次的抽象,简化分布式机器学习程序
大约减少 70%-80% 的代码:相对于 Petuum、Parameter Server 这样的机器学习系统;用于推荐系统的矩阵因子分解;用于主题建模的隐狄利克雷分布
三、 IIya Sutskever :生成模型的近期进展

P2: 人工智能的目标,保证人工智能确实对人类有益

P3: 目标
防止人工智能力量的集中化
打造让尽可能多的人受益的人工智能
打造听人类指挥的人工智能

P4 机器学习:什么起作用?
深度监督学习
视觉,演讲,翻译,语言,广告,机器人
深度监督学习
获得大量输入— 输出例子
训练一个非常大的深度神经网络卷积或者带有注意的序列到序列(seq2seq with attention)

P6: 下一步是什么?
能完成目标的代理
能对这个世界建立全面了解的系统
创造性问题解决
等等
 P7 生成模型:对许多即将出现的模型非常关键
P7 生成模型:对许多即将出现的模型非常关键

P8:什么是生成模型?
能学习你的数据分布
分配高概率给它
学习生成合理的结构
探索数据的「真实」结构

P9: 它们有什么用?我们能用它们做什么?
P10: 传统的应用
好的生成模型一定会有以下功能:
结构化预测(例如,输出文本)
更强大的预测
检测 异常
基于模型的强化学习
P11:推测可以加以应用的领域
非常好的特征学习
在强化学习中探索
逆向强化学习
真正实用的对话
「理解这个世界」
迁移学习

P12 生成模型的三大类:
变化的自动编码器
生成对抗式网络
自动回归模型

P14 生成对抗式网络
一个生成器 G(z)和一个鉴别器 D(x)
鉴别器的目标是将真实的数据从生成器样本分离出来
生成器尝试混淆鉴别器
生成对抗式网络常常会会产生最好的样本

P15: 生成对抗式网络
Yann LeCun:在我看来最重要的(最近研究进展中)是对抗式训练(也叫生成对抗式网络,缩写为 GAN)——来自 Quora Q&A

P16: 早期有前景的结果
目前为止任一模型的最好的高分辨率图像样本:
1.深度生成图像模型使用一个对抗性网络的拉普拉斯金字塔(Laplacian pyramid)。
— Denton 等人
2.DCGAN
— Radford 等人

P17: 难以训练
这个模型被定义在最小的极小化极大算法问题中
没有损失函数
很难区分是否正在取得进展

P18: 改进 GAN 训练的简单想法
GAN 无法学习是因为崩溃问题:
生成器开始退化并且这个学习也卡主了解决方法:鉴别器应该看到整个 mini batch
如果所有的案例都是相同的,区别起来就很简单 P25: 带有生成对抗式网络的半监督学习
P25: 带有生成对抗式网络的半监督学习
半监督学习是使用无标签数据获得更佳分类的问题
一个好的通用的半监督学习算法会改进所有的机器学习应用
 P26: 带有生成对抗式网络的半监督学习
P26: 带有生成对抗式网络的半监督学习
鉴别器分辨训练样本的类别,也能将真实的样本从假样本中辨别出来。
具体方法的完成过程很重要,但是也需要技术,我不做解释。
这个生成对抗式训练算法也不同

MNIST:50 个监督训练的案例 + 10个模型集成 = 1.4% 的测试误差
CIFAR 10: 4000 个监督训练案例 = 18.5% 的测试误差
两个结果都是最好的

P28: 结论
我们更好的方法来训练 GAN
简单的新方法是使用 GAN 来改进判别模型(discriminative model)
样本质量和半监督学习精确度的新水平

P29 :InfoGAN

P30: 解开的表征
表征学习的圣杯

P31: InfoGAN
训练一个GAN
像这样:它的变量的一个小子集是可从生成的样本中来精确预测的
直接添加这个约束

P40: 用生成模型探索
P41 : 问题
在强化学习中,我采取随机的行动
有时这些行动做的不错
然后我会在未来做更多这些行动

P42: 探讨
随机的行动是我们能做的最好的吗?
肯定不是

P43 :疑问
关键想法:采取行动来最大化「获取信息」
P44 :通常的做法
学习一个该环境的贝叶斯生成模型
对采取的行动来说,计算通过生成模型获取的关于环境的信息量
把信息量加到这个奖励中

P45: 确实有效
在低维环境中极度有效
许多无法解决的问题变得可解
现在的任务:扩展到高维环境中

 P48: 用自回归流改进
P48: 用自回归流改进 
P49: 亥姆霍兹机
潜在的变量模型
使用近似后验
尽可能最大化一个下限
已经不可能训练

P50: 再参数化窍门
亥姆霍兹机已经永远不可能训练
只要潜变量是连续的时候,Kingma 和 Welling 的参数化技巧修复了这个问题
P51 : 高质量的后验概率
近似后验很重要
典型的近似后验非常简单
强大后验的正常方式非常贵
IAF = 获得极度强大的后验的一个新廉价方法
结果:
CIFAR - 10 上最好的非像素卷积神经网络概率
优秀样本
当下训练的大型 ImageNet 模型
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@almosthuman.cn
投稿或寻求报道:editor@almosthuman.cn
广告&商务合作:bd@almosthuman.cn
点击「阅读原文」,下载PDF↓↓↓
以上是关于重磅|2016 ScaledML会议演讲合辑:谷歌Jeff Dean讲解TensorFlow,微软陆奇解读FPGA(附PPT)的主要内容,如果未能解决你的问题,请参考以下文章