分布式机器学习平台比较:Spark / PMLS / TensorFlow
Posted Spark技术日报
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式机器学习平台比较:Spark / PMLS / TensorFlow相关的知识,希望对你有一定的参考价值。
原文:https://yq.aliyun.com/articles/158322
本文调查分析了多个分布式机器学习平台所使用的设计方法,并提出了未来的研究方向。这是我与我的学生Kuo Zhang、Salem Alqahtani通力合作的成果。我们在2016年的秋天写了这篇论文,并且将在ICCCN'17(International Conference on Computer Communications and Networks,计算机通信与网络国际会议)上介绍这篇文章。
机器学习,特别是深度学习(DL),最近已经在语音识别、图像识别、自然语言处理、推荐/搜索引擎等领域获得了成功。这些技术在自主驾驶汽车、数字卫生系统、CRM、广告、物联网等方面都存在着非常有前景的应用。当然,资金驱动着这些技术以极快的速度向前发展,而且,最近我们已经看到了有很多机器学习平台正在建立起来。
由于在训练过程中要涉及到庞大的数据集和模型的大小,因此机器学习平台通常是分布式平台,而且并行运行了10到100个作业来训练模型。据估计,在不久的将来,数据中心的绝大多数任务将是机器学习任务。
我的知识背景是分布式系统,因此,我们决定从分布式系统的角度来研究这些机器学习平台,分析这些平台的通信和控制瓶颈。我们还研究了这些平台的容错性和编程的难易性。
我们根据三种基本的设计方法对分布式机器学习平台进行了分类,分别是:
基本数据流
参数服务器模型
高级数据流
我们将对每一种方法进行简单的介绍,我们使用Apache Spark作为基本数据流方法的示例,使用PMLS(Petuum)作为参数服务器模型的示例,使用TensorFlow和MXNet作为高级数据流模型的示例。 我们将提供它们之间的性能比较评估结果。有关更多的评估结果,请参阅本文最开始提到的那篇论文。不幸的是,我们无法作为一个来自学术界的小团队进行规模上的评估。
在这篇文章的末尾,我对分布式机器学习平台的未来工作提出了总结性意见和建议。如果你已经有这些分布式机器学习平台的使用经验,可以直接跳到文章的末尾。
Spark
在Spark中,计算被建模为有向无环图(DAG, directed acyclic graph),其中的每个顶点表示弹性分布式数据集(RDD, Resilient Distributed Dataset),每个边表示RDD上的操作。 RDD是以逻辑分块进行划分的对象集合,它缓存在内存中,当内存不够时,会保存到磁盘上。
在DAG上,从顶点A到顶点B的边E表示RDD B是在RDD A上执行操作E的结果。有两种类型的操作:转换和动作。转换(例如,映射、过滤、连接)就是对RDD执行操作并产生新的RDD。
Spark用户将计算作为DAG进行建模,该DAG会转换并运行RDD上的动作。DAG会分阶段进行编译。每个阶段将作为一系列的任务并行执行(每个分区一个任务)。窄的依赖关系有利于高效的执行,而广泛的依赖关系会带来瓶颈,因为它们会破坏流水线,而且需要通信密集的随机操作。
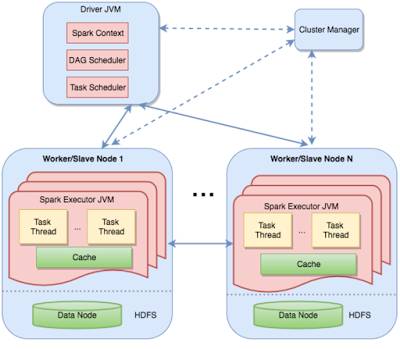
Spark中的分布式执行是通过对机器上的DAG阶段进行分块来实现的。这个图清晰地展示了master-worker架构。Driver包含了两个调度组件,DAG调度器和任务调度器,用于给workers分配任务,以及协调workers。
Spark是为一般数据处理而不是为机器学习设计的。然而,利用专用于Spark的MLlib,使得在Spark上进行机器学习成为可能。在基本的设置中,Spark将模型参数存储在driver节点中,而workers与driver进行通信,以便在每次迭代后更新参数。对于大规模的部署来说,模型参数可能不适合保存在driver中,而应该将其作为RDD进行维护。这引入了很大的开销,因为需要在每次迭代中创建新的RDD以保存更新过的模型参数。更新模型包括在机器/磁盘之间混洗数据,这限制了Spark的可扩展性。这是Spark中基本数据流模型(DAG)不足的地方。 Spark不支持机器学习所需的迭代。
PMLS
PMLS从诞生的那一天起就是专门为机器学习设计的。它引入了参数服务器(parameter-server,简写为PS)抽象用于迭代密集型机器学习训练过程。
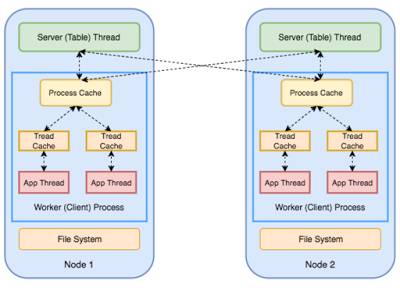
PS(在图中用绿色的框表示)用于分布式内存键值的存储。它复制和分片的方式是这样的:每个节点既是模型中某个分片的主节点,又是其他分片的辅节点(或副本)。因此,PS可以通过增加节点数量的方法很容易地进行扩展。
PS节点用于存储和更新模型参数,并响应workers的请求。workers从本地PS副本中请求最新的模型参数,并对分配给自己的数据集分区进行计算。
PMLS还采用了SSP(Stale Synchronous Parallelism,变味的同步并行)模型,它放宽了BSP(Bulk Synchronous Parellelism,批量同步并行)模型中workers在每次迭代最后要进行同步操作的要求。 SSP减少了workers同步的难度,确保最快的worker不能在最慢的worker之前迭代。由于对过程中产生的噪声具有一定的容错能力,这个宽松的一致性模型仍可适用于机器学习训练。
TensorFlow
Google有一个基于分布式机器学习平台的参数服务器模型,名为DistBelief。人们对DistBelief主要的抱怨是编写机器学习应用程序的时候会弄乱底层代码。Google希望公司内的任何员工无需精通分布式执行就能编写机器学习代码,这也是Google为大数据处理编写MapReduce框架的原因。
所以,TensorFlow正是为了实现这一目标而设计的。TensorFlow采用了数据流范例,但在它的高级版本中,计算图不需要是DAG,但可以包括循环和支持可变状态。我想,可能是Naiad的设计对TensorFlow产生了一些影响吧。
TensorFlow中的计算可以表示为一个带有节点和边的有向图。节点表示具有可变状态的计算。边表示在节点之间传递的多维数据矩阵(张量)。 TensorFlow要求用户静态地声明这个符号计算图,并且使用图形的重写和分区来让机器进行分布式的执行。
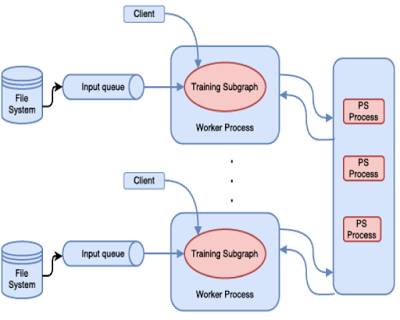
如上图所示,这个TensorFlow中的分布式机器学习训练使用了参数服务器的方法。在TensorFlow中使用PS抽象的时候,可以使用参数服务器和数据并行机制。对于TensorFlow来说,你可以做更为复杂的事情,但这需要编写自定义代码并走入未知的领域。
一些评估结果
为了对这些平台进行评估,我们使用了Amazon EC2 m4.xlarge实例。每个实例包含由Intel Xeon E5-2676 v3处理器和16GB RAM组成的4个vCPU。EBS带宽为750Mbps。我们使用两种常见的机器学习任务进行评估:使用多层神经网络的二级逻辑回归和图像分类。我只是在这里提供几张图,请查看我们的论文以进行更多的实验。我们的实验有几个限制:我们使用的机器比较少,不能进行规模上的测试。我们的测试仅限于CPU计算,并没有进行GPU计算测试。
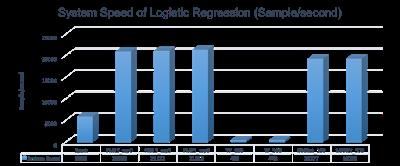
该图显示了逻辑回归平台的速度。Spark比PMLS和MXNet慢,但表现得还算可以。
该图显示了DNN平台的速度。与单层逻辑回归相比,Spark的性能损失比两层NN更大,这是因为需要更多的迭代计算。这里,我们将driver的参数保存在Spark中。如果我们将参数保存在RDD中并且在每次迭代之后进行更新,情况会更糟。
该图显示了平台的CPU利用率。 Spark应用程序的CPU利用率明显比较高,主要是因为存在序列化的开销。
结语,以及未来的方向
机器学习/深度学习应用程序有着令人尴尬的并行机制,而且从并发算法角度来看也并不是很有趣。可以肯定的是,参数服务器方法赢得了分布式机器学习平台训练的青睐。
至于瓶颈问题,网络仍然是分布式机器学习应用程序的瓶颈。更好的数据或模型分级比更先进的通用数据流平台更有用,请重视数据和模型。
然而,也存在着一些令人惊讶和微妙的地方。 在Spark中,CPU开销正在成为比网络限制更为重要的瓶颈。 Spark中使用的编程语言(例如Scala/JVM)会显着影响它的性能。因此,特别需要一个更好的工具来进行分布式机器学习平台的监控和性能预测。近来,已经出现了一些能够解决Spark数据处理程序问题的工具,例如Ernest和CherryPick。
支持机器学习运行时的分布式系统存在着许多悬而未决的问题,例如资源调度和运行时性能提升。通过对应用程序运行时的监控和分析,下一代分布式机器学习平台应该要为正在运行的任务提供计算、内存、网络资源的通用运行时弹性配置和调度。
最后,还有编程和软件工程支持方面的问题有待解决。适用于机器学习应用程序的分布式编程抽象是什么?还需要更多的研究来检验和确认分布式机器学习应用程序。
以上是关于分布式机器学习平台比较:Spark / PMLS / TensorFlow的主要内容,如果未能解决你的问题,请参考以下文章