手把手丨用TensorFlow开发问答系统
Posted 大数据文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手丨用TensorFlow开发问答系统相关的知识,希望对你有一定的参考价值。
授权转载自 OReillyData(ID:OReillyData)
一个问答系统是被设计用来回答用自然语言提出的问题的系统。一些问答系统从诸如文本和图片这样的“源”里获得信息来回答特定的问题。这些依赖“源”的系统可以基本被分为两类:开放话题的,它需要回答的可能是任何问题,不限于特定的领域;特定话题的,它回答的问题是有特定限制的,因为它们是与一些预先定义的“源”相关,比如有给定上下文或是特定领域(如医学等)。
这篇博文会带领你完成一个使用TensorFlow来创建和开发问答系统的任务。我们会构建一个基于神经网络的问答系统,并基于一个特定话题的源信息。为了完成这个任务,我们会使用一个简化版的叫做动态记忆网络(Dynamic Memory Network,DMN)的模型。这个模型是Kumar等人在他们的论文《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》里给出的。
开始前的准备工作
除了要安装Python 3.0版本和TensorFlow 1.2版以外,确保你还安装了下面这些软件和Python库:
Jupyter
Numpy
Matplotlib
你也可以选择性地安装TQDM来观看训练过程并得到训练速度指标,但这不是必须的。这篇文章里的代码和Jupyter Notebook文件都可以在GitHub里找到。我建议你把它们下载下来并使用。如果这是你第一次使用TensorFlow,我建议你先看看Aaron Shumacher的《Hello, TensorFlow》这篇文章来对什么是TensorFlow以及它是如何运作的获得一个初步的概念。如果这是你第一次使用TensorFlow来解决自然语言的问题,我也会建议你先看看《Textual Entailment with TensorFlow》这篇文章。因为它里面介绍了一些对本文里构建神经网络有帮助的概念。
让我们首先导入所有的相关的库:
%matplotlib inline
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import urllib
import sys
import os
import zipfile
import tarfile
import json
import hashlib
import re
import itertools探索bAbI数据集
对于这个项目,我们将会使用由Facebook构建的bAbI数据集。与所有的问答数据集类似,这个数据集里包括了问题。bAbI数据集里的问题都非常直接明了,尽管有些比别的要难一点。这个数据集里的所有问题都有相关的上下文,即一些句子。这些句子里面肯定包括了回答问题所需要的细节。另外,这个数据集也会提供每个问题的正确答案。
基于回答问题所需要的技能,bAbI数据集里的问题被分成了20类任务。每种任务都有它自己的用于训练的问题和测试的问题。这些任务测试了多种标准的自然语言处理的能力,包括时间的推理(任务#14)和归纳逻辑(任务#16)。为了能对这些任务有更好的理解,让我们看一个我们的问答系统将需要回答的问题。如图1所示。

图1. bAbI数据集里的一个例子。上下文在蓝色框内,问题在金色框内,答案在绿色框内。来源:Steven Hewitt
这个#5号里面的任务要测试神经网络理解三个对象之间动作的关系的能力。语法上讲,这个任务是在测试问答系统是否能区分主语、直接宾语和间接宾语。在这个例子里,问题问的是最后一个句子里的间接宾语,即谁从Jeff手里接收了牛奶。神经网络必须能找出Bill是主语而Jeff是间接宾语所在的第五个句子,和Jeff是主语的第六个句子。当然我们的神经网络没有得到任何明确的训练来找到什么是主语或宾语,而是必须通过训练数据里的例子来推测出这个理解。
另外一个系统必须解决的小问题就是数据集里的各种同义词。Jeff把牛奶“递给”Bill,但他也可以是简单地“给”或是“交”给Bill。考虑这些,我们的神经网络并不是从零创建的,它会得到词向量的帮助。词向量会存储对词的定义以及词与词之间的关系。类似的词有相似的向量,这意味着神经网络可以认为它们是相同的词。我们会使用Stanford大学的GloVe词向量库。关于这个部分,我在之前的这篇文章里有更详细的介绍。
大部分任务都有限制,要求上下文里包含能回答问题的确切文字。在我们上面的例子里,答案“Bill”就可以在上下文里找到。我们会利用这一限制,从而在上下文里搜索和我们最终结果意思最相近的词。
注意:下载和解压缩数据可能会需要几分钟。因此尽早运行下面三段代码来开始。这些代码会下载bAbI和GloVe数据,并从中解压出需要的文件来用于我们的神经网络。
glove_zip_file = “glove.6B.zip”
glove_vectors_file = “glove.6B.50d.txt”
# 15 MB
data_set_zip = “tasks_1-20_v1-2.tar.gz”
#Select “task 5”
train_set_file = “qa5_three-arg-relations_train.txt”
test_set_file = “qa5_three-arg-relations_test.txt”
train_set_post_file = “tasks_1-20_v1-2/en/”+train_set_file
test_set_post_file = “tasks_1-20_v1-2/en/”+test_set_file
try: from urllib.request import urlretrieve, urlopen
except ImportError:
from urllib import urlretrieve
from urllib2 import urlopen
#large file – 862 MB
if (not os.path.isfile(glove_zip_file) and
not os.path.isfile(glove_vectors_file)):
urlretrieve (“http://nlp.stanford.edu/data/glove.6B.zip”,
glove_zip_file)
if (not os.path.isfile(data_set_zip) and
not (os.path.isfile(train_set_file) and os.path.isfile(test_set_file))):
urlretrieve (“https://s3.amazonaws.com/text-datasets/babi_tasks_1-20_v1-2.tar.gz”,
data_set_zip)
def unzip_single_file(zip_file_name, output_file_name):
“””
If the output file is already created, don’t recreate
If the output file does not exist, create it from the zipFile
“””
if not os.path.isfile(output_file_name):
with open(output_file_name, ‘wb’) as out_file:
with zipfile.ZipFile(zip_file_name) as zipped:
for info in zipped.infolist():
if output_file_name in info.filename:
with zipped.open(info) as requested_file:
out_file.write(requested_file.read())
return
def targz_unzip_single_file(zip_file_name, output_file_name, interior_relative_path):
if not os.path.isfile(output_file_name):
with tarfile.open(zip_file_name) as un_zipped:
un_zipped.extract(interior_relative_path+output_file_name)
unzip_single_file(glove_zip_file, glove_vectors_file)
targz_unzip_single_file(data_set_zip, train_set_file, “tasks_1-20_v1-2/en/”)
targz_unzip_single_file(data_set_zip, test_set_file, “tasks_1-20_v1-2/en/”)解析GloVe和处理未知的词条
在《Textual Entailment with TensorFlow》里,我介绍了sentence2sequence函数。这是一个基于GloVe定义的映射把字符串转换成矩阵的功能。它把字符串分成词条。这些词条是更小的词片段,大致类似于标点、词或词的一部分。例如“Bill traveled to the kitchen.”里包含6个词条,对应于5个单词和最后的那个句号。每个词条独立地被向量化,就形成了和这个句子相对应的向量列表。如图2所示。
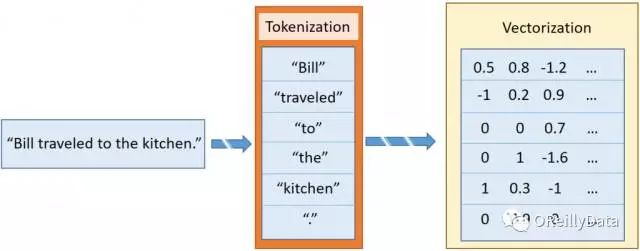
图2 把句子变成多个向量的过程。来源:Steven Hewitt
在bAbI的一些任务里,问答系统将会碰到GloVe的词向量化里没有的词。为了让我们的神经网络能处理这些未知的词条,我们需要维护一个这些词的一致的向量。常见的动作是把所有的这些未知词条替换成一个单一的<UNK>向量,但这并不总是有效。这里,我们使用随机化的方法来为每一个未知的词条新建一个向量。
当我们首次碰到一个未知的词条,我们就从最初的GloVe向量化的分布(近似高斯分布)里获取一个新的向量,然后把这个向量放回到GloVe的词映射里。想获得分布的超参数,Numpy有可以自动计算方差和均值的函数。
下面的fill_unk函数会在我们需要时给出一个新的词向量。
# Deserialize GloVe vectors
glove_wordmap = {}
with open(glove_vectors_file, “r”, encoding=”utf8″) as glove:
for line in glove:
name, vector = tuple(line.split(” “, 1))
glove_wordmap[name] = np.fromstring(vector, sep=” “)
wvecs = []
for item in glove_wordmap.items():
wvecs.append(item[1])
s = np.vstack(wvecs)
# Gather the distribution hyperparameters
v = np.var(s,0)
m = np.mean(s,0)
RS = np.random.RandomState()
def fill_unk(unk):
global glove_wordmap
glove_wordmap[unk] = RS.multivariate_normal(m,np.diag(v))
return glove_wordmap[unk]已知还是未知
bAbI任务里有限的词汇表意味着我们的神经网络即使在不知道词的意思的情况下也可以学习词之间的关系。不过,为了加快学习的速度,我们会尽量选择有意思的向量。为了实现它,我们使用贪婪搜素策略,查找Stanford的GloVe词向量数据集里已经存在的词。如果不存在,则把整个词用一个未知的随机生成的新的向量表示替换掉。
使用这一词向量的模型,我们可以定义新的sentence2sequence函数:
def sentence2sequence(sentence):
“””
– Turns an input paragraph into an (m,d) matrix,
where n is the number of tokens in the sentence
and d is the number of dimensions each word vector has.
TensorFlow doesn’t need to be used here, as simply
turning the sentence into a sequence based off our
mapping does not need the computational power that
TensorFlow provides. Normal Python suffices for this task.
“””
tokens = sentence.strip(‘”(),-‘).lower().split(” “)
rows = []
words = []
#Greedy search for tokens
for token in tokens:
i = len(token)
while len(token) > 0:
word = token[:i]
if word in glove_wordmap:
rows.append(glove_wordmap[word])
words.append(word)
token = token[i:]
i = len(token)
continue
else:
i = i-1
if i == 0:
# word OOV
# https://arxiv.org/pdf/1611.01436.pdf
rows.append(fill_unk(token))
words.append(token)
break
return np.array(rows), words现在我们可以把每个问题需要的数据给打包起来了,包括上下文、问题和答案的词向量。在bAbI里,上下文被我们定义成了带有序号的句子。用contextualize函数可以完成这个任务。问题和答案都在同一行里,用tab符分割开。因此在一行里我们可以使用tab符作为区分问题和答案的标记。当序号被重置后,未来的问题将会指向是新的上下文(注意:通常对于一个上下文会有多个问题)。答案里还有另外一个我们会保留下来但不用的信息:答案对应的句子的序号。在我们的系统里,神经网络将会自己学习用来回答问题的句子。
def contextualize(set_file):
“””
Read in the dataset of questions and build question+answer -> context sets.
Output is a list of data points, each of which is a 7-element tuple containing:
The sentences in the context in vectorized form.
The sentences in the context as a list of string tokens.
The question in vectorized form.
The question as a list of string tokens.
The answer in vectorized form.
The answer as a list of string tokens.
A list of numbers for supporting statements, which is currently unused.
“””
data = []
context = []
with open(set_file, “r”, encoding=”utf8″) as train:
for line in train:
l, ine = tuple(line.split(” “, 1))
# Split the line numbers from the sentences they refer to.
if l is “1”:
# New contexts always start with 1,
# so this is a signal to reset the context.
context = []
if “\t” in ine:
# Tabs are the separator between questions and answers,
# and are not present in context statements.
question, answer, support = tuple(ine.split(“\t”))
data.append((tuple(zip(*context))+
sentence2sequence(question)+
sentence2sequence(answer)+
([int(s) for s in support.split()],)))
# Multiple questions may refer to the same context, so we don’t reset it.
else:
# Context sentence.
context.append(sentence2sequence(ine[:-1]))
return data
train_data = contextualize(train_set_post_file)
test_data = contextualize(test_set_post_file)
final_train_data = []
def finalize(data):
“””
Prepares data generated by contextualize() for use in the network.
“””
final_data = []
for cqas in train_data:
contextvs, contextws, qvs, qws, avs, aws, spt = cqas
lengths = itertools.accumulate(len(cvec) for cvec in contextvs)
context_vec = np.concatenate(contextvs)
context_words = sum(contextws,[])
# Location markers for the beginnings of new sentences.
sentence_ends = np.array(list(lengths))
final_data.append((context_vec, sentence_ends, qvs, spt, context_words, cqas, avs, aws))
return np.array(final_data)
final_train_data = finalize(train_data)
final_test_data = finalize(test_data)定义超参数
到这里,我们已经完全准备好了所需的训练和测试数据。下面的任务就是构建用来理解数据的神经网络。让我们从清除TensorFlow的默认计算图开始,从而能让我们在修改了一些东西后再次运行网络。
tf.reset_default_graph()这里是网络的开始,因此让我们在这里定义所有需要的常量。我们叫它们“超参数”,因为它们定义了网络的结构和训练的方法。
# Hyperparameters
# The number of dimensions used to store data passed between recurrent layers in the network.
recurrent_cell_size = 128
# The number of dimensions in our word vectorizations.
D = 50
# How quickly the network learns. Too high, and we may run into numeric instability
# or other issues.
learning_rate = 0.005
# Dropout probabilities. For a description of dropout and what these probabilities are,
# see Entailment with TensorFlow.
input_p, output_p = 0.5, 0.5
# How many questions we train on at a time.
batch_size = 128
# Number of passes in episodic memory. We’ll get to this later.
passes = 4
# Feed Forward layer sizes: the number of dimensions used to store data passed from feed-forward layers.
ff_hidden_size = 256
weight_decay = 0.00000001
# The strength of our regularization. Increase to encourage sparsity in episodic memory,
# but makes training slower. Don’t make this larger than leraning_rate.
training_iterations_count = 400000
# How many questions the network trains on each time it is trained.
# Some questions are counted multiple times.
display_step = 100
# How many iterations of training occur before each validation check.网络架构
有了这些超参数,让我们定义网络的架构。这个架构大致能被分成4个模块,具体描述请见这篇《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》。
网络里定义了一个循环层,能基于文本里的其他的信息被动态地定义,因此叫动态记忆网络(DMN,Dynamic Memory Network)。DMN大致是基于人类是如何试图去回答一个阅读理解类型的问题的理解。首先,人类会读取一段上下文,并在记忆里创建一些事实内容。基于这些记住的内容,他们再去读问题,并再次查看上下文,特别是去寻找和问题相关的答案,并把问题和每个事实去比对。
有时候,一个事实会把我们引向另外一个事实。在bAbI数据集里,神经网络可能是想找到一个足球的位置。它也许会搜索句子里和足球相关的内容,并发现John是最后一个接触足球的人。然后搜索和John相关的句子,发现John曾经出现在卧室和门厅里。一旦它意识到John最后是出现在门厅里,它就可以有信心地回答这个问题,指出足球是在门厅里。
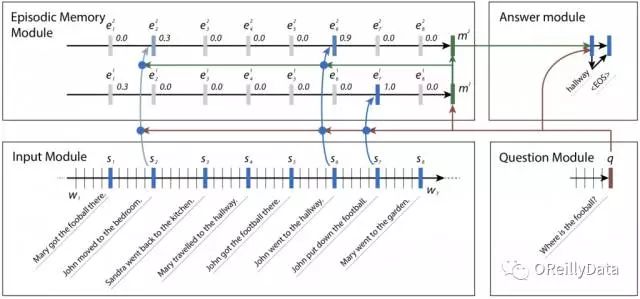
图3 神经网络里的4个模型,它们组合在一起来回答bAbI的问题。在每个片段里,新的事实被注意到,它们能帮助找到答案。Kumar注意到这个网络不正确地给句子2分配了权重,但这也合理,因为John曾经在那里,尽管此时他没有足球。来源:Ankit Kumar等,授权使用
输入模块
输入模块是我们的动态记忆网络用来得到答案的4个模块的第一个。它包括一个带有门循环单元(GRU,Gated Recurrent Unit,在TensorFlow里的tf.contrib.nn.GRUCell)的输入通道,让数据通过来收集证据片段。每个片段的证据或是事实都对应这上下文的单个句子,并由这个时间片的输出所代表。这就要求一些非TensorFlow的预处理,从而能获取句子的结尾并把这个信息送给TensorFlow来用于后面的模块。
我们会在后面训练的时候处理这些额外的过程。我们会使用TensorFlow的gather_nd来处理数据从而选择相应的输出。gather_nd功能是一个非常有用的工具。我建议你仔细看看它的API文档来学习它是如何工作的。
# Input Module
# Context: A [batch_size, maximum_context_length, word_vectorization_dimensions] tensor
# that contains all the context information.
context = tf.placeholder(tf.float32, [None, None, D], “context”)
context_placeholder = context # I use context as a variable name later on
# input_sentence_endings: A [batch_size, maximum_sentence_count, 2] tensor that
# contains the locations of the ends of sentences.
input_sentence_endings = tf.placeholder(tf.int32, [None, None, 2], “sentence”)
# recurrent_cell_size: the number of hidden units in recurrent layers.
input_gru = tf.contrib.rnn.GRUCell(recurrent_cell_size)
# input_p: The probability of maintaining a specific hidden input unit.
# Likewise, output_p is the probability of maintaining a specific hidden output unit.
gru_drop = tf.contrib.rnn.DropoutWrapper(input_gru, input_p, output_p)
# dynamic_rnn also returns the final internal state. We don’t need that, and can
# ignore the corresponding output (_).
input_module_outputs, _ = tf.nn.dynamic_rnn(gru_drop, context, dtype=tf.float32, scope = “input_module”)
# cs: the facts gathered from the context.
cs = tf.gather_nd(input_module_outputs, input_sentence_endings)
# to use every word as a fact, useful for tasks with one-sentence contexts
s = input_module_outputs问题模块
问题模块是第二个模块,也可是说是最简单的一个。它包括另外一个GRU的通道。这次是处理问题的文本。不再是找证据,我们就是简单地进入结束状态,因为数据集里的问题肯定就是一个句子。
# Question Module
# query: A [batch_size, maximum_question_length, word_vectorization_dimensions] tensor
# that contains all of the questions.
query = tf.placeholder(tf.float32, [None, None, D], “query”)
# input_query_lengths: A [batch_size, 2] tensor that contains question length information.
# input_query_lengths[:,1] has the actual lengths; input_query_lengths[:,0] is a simple range()
# so that it plays nice with gather_nd.
input_query_lengths = tf.placeholder(tf.int32, [None, 2], “query_lengths”)
question_module_outputs, _ = tf.nn.dynamic_rnn(gru_drop, query, dtype=tf.float32,
scope = tf.VariableScope(True, “input_module”))
# q: the question states. A [batch_size, recurrent_cell_size] tensor.
q = tf.gather_nd(question_module_outputs, input_query_lengths)片段记忆模块
我们第三个模块是片段记忆模块。在这里事情开始变得有趣了。它使用注意力来进行多次数据通路流转。每个通路包括多个GRU,对输入进行循环。基于当时有多少注意力被放在相应的事实上,每个通路内部的循环对现有记忆的权重进行更新。
注意力
神经网络里的注意力最初是被设计用来进行图像分析的,特别是图片的部分内容远比其他部分和分析的主题更相关。诸如在图片里寻找目标对象、在图片之间跟踪对象、面部识别,或是其他需要在图片里找到最相关信息这样的任务里,神经网络使用注意力来决定图片里需要进一步进行分析的最佳的部分。
这里的主要问题是注意力或至少是硬注意力(仅关注一个输入区域)不容易被优化。与处理其他神经网络类似,我们的优化策略是计算不同输入和权重下的损失函数的导数。但由于它的二元特性,硬注意力是不可导的。因此我们被迫使用了基于实数的版本(“软注意力”),它对所有输入的区域都用某种权重来标识注意的程度。而这个实数权重是完全可导的,也能正常被训练。尽管硬注意力也能被训练学习,但非常困难,而且有时它的表现也不如软注意力好。因此在这个模型里我们还是使用软注意力。不用担心要写求导的代码,TensorFlow的优化策略已经为我们完成了。
在这个模型里,我们通过构建每个事实、现有记忆和最初的问题之间的相似度来计算注意力(需要注意的是,这一方法和通常的注意力是有区别的。通常的注意力只构建事实和现有记忆的相似度)。我们把结果送进一个两层的前馈网络来获得每个事实的注意力常数。接着我们把输入的事实通过一个GRU来给予权重(通过相应的注意力常数来给予),从而修改了现有记忆。为了避免当上下文比矩阵的长度小的时候向现有记忆里加入不正确的信息,我们创建了一掩盖层,当事实不存在的时候就根本不去注意它(例如,获取了相同的现有记忆)。
另外一个值得注意的方面就是注意力掩盖层几乎总是在网络的一层里封包了表达层。例如在图像里,这个封包很可能是发生在卷积层上(很可能是把图片的位置直接映射)。对于自然语言,这一层很可能是封包在循环层上。尽管技术上是可以的,但对一个前馈网络进行注意力封包通常并没什么用,或至少在那些不能容易被后续前馈网络层模拟的方式上有用。
# Episodic Memory
# make sure the current memory (i.e. the question vector) is broadcasted along the facts dimension
size = tf.stack([tf.constant(1),tf.shape(cs)[1], tf.constant(1)])
re_q = tf.tile(tf.reshape(q,[-1,1,recurrent_cell_size]),size)
# Final output for attention, needs to be 1 in order to create a mask
output_size = 1
# Weights and biases
attend_init = tf.random_normal_initializer(stddev=0.1)
w_1 = tf.get_variable(“attend_w1”, [1,recurrent_cell_size*7, recurrent_cell_size],
tf.float32, initializer = attend_init)
w_2 = tf.get_variable(“attend_w2”, [1,recurrent_cell_size, output_size],
tf.float32, initializer = attend_init)
b_1 = tf.get_variable(“attend_b1”, [1, recurrent_cell_size],
tf.float32, initializer = attend_init)
b_2 = tf.get_variable(“attend_b2”, [1, output_size],
tf.float32, initializer = attend_init)
# Regulate all the weights and biases
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, tf.nn.l2_loss(w_1))
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, tf.nn.l2_loss(b_1))
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, tf.nn.l2_loss(w_2))
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, tf.nn.l2_loss(b_2))
def attention(c, mem, existing_facts):
“””
Custom attention mechanism.
c: A [batch_size, maximum_sentence_count, recurrent_cell_size] tensor
that contains all the facts from the contexts.
mem: A [batch_size, maximum_sentence_count, recurrent_cell_size] tensor that
contains the current memory. It should be the same memory for all facts for accurate results.
existing_facts: A [batch_size, maximum_sentence_count, 1] tensor that
acts as a binary mask for which facts exist and which do not.
“””
with tf.variable_scope(“attending”) as scope:
# attending: The metrics by which we decide what to attend to.
attending = tf.concat([c, mem, re_q, c * re_q, c * mem, (c-re_q)**2, (c-mem)**2], 2)
# m1: First layer of multiplied weights for the feed-forward network.
# We tile the weights in order to manually broadcast, since tf.matmul does not
# automatically broadcast batch matrix multiplication as of TensorFlow 1.2.
m1 = tf.matmul(attending * existing_facts,
tf.tile(w_1, tf.stack([tf.shape(attending)[0],1,1]))) * existing_facts
# bias_1: A masked version of the first feed-forward layer’s bias
# over only existing facts.
bias_1 = b_1 * existing_facts
# tnhan: First nonlinearity. In the original paper, this is a tanh nonlinearity;
# choosing relu was a design choice intended to avoid issues with
# low gradient magnitude when the tanh returned values close to 1 or -1.
tnhan = tf.nn.relu(m1 + bias_1)
# m2: Second layer of multiplied weights for the feed-forward network.
# Still tiling weights for the same reason described in m1’s comments.
m2 = tf.matmul(tnhan, tf.tile(w_2, tf.stack([tf.shape(attending)[0],1,1])))
# bias_2: A masked version of the second feed-forward layer’s bias.
bias_2 = b_2 * existing_facts
# norm_m2: A normalized version of the second layer of weights, which is used
# to help make sure the softmax nonlinearity doesn’t saturate.
norm_m2 = tf.nn.l2_normalize(m2 + bias_2, -1)
# softmaxable: A hack in order to use sparse_softmax on an otherwise dense tensor.
# We make norm_m2 a sparse tensor, then make it dense again after the operation.
softmax_idx = tf.where(tf.not_equal(norm_m2, 0))[:,:-1]
softmax_gather = tf.gather_nd(norm_m2[…,0], softmax_idx)
softmax_shape = tf.shape(norm_m2, out_type=tf.int64)[:-1]
softmaxable = tf.SparseTensor(softmax_idx, softmax_gather, softmax_shape)
return tf.expand_dims(tf.sparse_tensor_to_dense(tf.sparse_softmax(softmaxable)),-1)
# facts_0s: a [batch_size, max_facts_length, 1] tensor
# whose values are 1 if the corresponding fact exists and 0 if not.
facts_0s = tf.cast(tf.count_nonzero(input_sentence_endings[:,:,-1:],-1,keep_dims=True),tf.float32)
with tf.variable_scope(“Episodes”) as scope:
attention_gru = tf.contrib.rnn.GRUCell(recurrent_cell_size)
# memory: A list of all tensors that are the (current or past) memory state
# of the attention mechanism.
memory = [q]
# attends: A list of all tensors that represent what the network attends to.
attends = []
for a in range(passes):
# attention mask
attend_to = attention(cs, tf.tile(tf.reshape(memory[-1],[-1,1,recurrent_cell_size]),size),
facts_0s)
# Inverse attention mask, for what’s retained in the state.
retain = 1-attend_to
# GRU pass over the facts, according to the attention mask.
while_valid_index = (lambda state, index: index < tf.shape(cs)[1])
update_state = (lambda state, index: (attend_to[:,index,:] *
attention_gru(cs[:,index,:], state)[0] +
retain[:,index,:] * state))
# start loop with most recent memory and at the first index
memory.append(tuple(tf.while_loop(while_valid_index,
(lambda state, index: (update_state(state,index),index+1)),
loop_vars = [memory[-1], 0]))[0])
attends.append(attend_to)
# Reuse variables so the GRU pass uses the same variables every pass.
scope.reuse_variables()答案模块
最后一个模块是答案模块。它使用一个全连接层来对问题和片段记忆模块的输出进行回归来得到最后结果的词向量,以及上下文里和这个词向量距离最接近的词作为我们最后的答案(保证结果是一个实际的词)。我们为每个词创建一个得分来计算最近的词,这个得分就是结果的词距离。虽然你可以设计一个答案模块来返回多个词,但这对于我们要解决的bAbI任务而言就不必要了。
# Answer Module
# a0: Final memory state. (Input to answer module)
a0 = tf.concat([memory[-1], q], -1)
# fc_init: Initializer for the final fully connected layer’s weights.
fc_init = tf.random_normal_initializer(stddev=0.1)
with tf.variable_scope(“answer”):
# w_answer: The final fully connected layer’s weights.
w_answer = tf.get_variable(“weight”, [recurrent_cell_size*2, D],
tf.float32, initializer = fc_init)
# Regulate the fully connected layer’s weights
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES,
tf.nn.l2_loss(w_answer))
# The regressed word. This isn’t an actual word yet;
# we still have to find the closest match.
logit = tf.expand_dims(tf.matmul(a0, w_answer),1)
# Make a mask over which words exist.
with tf.variable_scope(“ending”):
all_ends = tf.reshape(input_sentence_endings, [-1,2])
range_ends = tf.range(tf.shape(all_ends)[0])
ends_indices = tf.stack([all_ends[:,0],range_ends], axis=1)
ind = tf.reduce_max(tf.scatter_nd(ends_indices, all_ends[:,1],
[tf.shape(q)[0], tf.shape(all_ends)[0]]),
axis=-1)
range_ind = tf.range(tf.shape(ind)[0])
mask_ends = tf.cast(tf.scatter_nd(tf.stack([ind, range_ind], axis=1),
tf.ones_like(range_ind), [tf.reduce_max(ind)+1,
tf.shape(ind)[0]]), bool)
# A bit of a trick. With the locations of the ends of the mask (the last periods in
# each of the contexts) as 1 and the rest as 0, we can scan with exclusive or
# (starting from all 1). For each context in the batch, this will result in 1s
# up until the marker (the location of that last period) and 0s afterwards.
mask = tf.scan(tf.logical_xor,mask_ends, tf.ones_like(range_ind, dtype=bool))
# We score each possible word inversely with their Euclidean distance to the regressed word.
# The highest score (lowest distance) will correspond to the selected word.
logits = -tf.reduce_sum(tf.square(context*tf.transpose(tf.expand_dims(
tf.cast(mask, tf.float32),-1),[1,0,2]) – logit), axis=-1)对优化的策略进行优化
梯度下降是神经网络的默认优化器。它的目标是降低网络的“损失”。损失是通过测量网络的表现来确定的。为了计算损失,梯度下降法会找到权重和输入所对应的损失的导数,然后通过“下降”权重来降低损失。大部分情况下,这个方法都不错,但并不是最理想的。现在有很多不同的策略,使用“动量”或是其他的对于直接路径的近似的方法来优化权重。其中一个最常用的就是自适应动量估计,叫Adam。
Adam方法会估计梯度的头两个动量。它计算上一个循环的梯度和梯度的平方的平均值的指数衰减,这两个值对应着这些梯度的均值和方差的估计。计算会使用两个额外的超参数来控制平均衰减和得到新的信息的速度。平均值被初始化成零,并导致偏置量为零,特别是在超参数也趋近于零的时候。
为了抵消这些偏置量,Adam计算偏置修正动量估计,这个值一般比初始值要大。然后这个修正过的估计被用来在网络里更新权重。这些估计的组合使得Adam方法成为总体优化的最佳方案之一,特别是对复杂的神经网络。而对于非常稀疏的数据(这在自然语言处理里的任务是很常见的),它的效果就更好了。
在TensorFlow里,我们可以用tf.train.AdamOptimizer来创建Adam优化器。
# Training
# gold_standard: The real answers.
gold_standard = tf.placeholder(tf.float32, [None, 1, D], “answer”)
with tf.variable_scope(‘accuracy’):
eq = tf.equal(context, gold_standard)
corrbool = tf.reduce_all(eq,-1)
logloc = tf.reduce_max(logits, -1, keep_dims = True)
# locs: A boolean tensor that indicates where the score
# matches the minimum score. This happens on multiple dimensions,
# so in the off chance there’s one or two indexes that match
# we make sure it matches in all indexes.
locs = tf.equal(logits, logloc)
# correctsbool: A boolean tensor that indicates for which
# words in the context the score always matches the minimum score.
correctsbool = tf.reduce_any(tf.logical_and(locs, corrbool), -1)
# corrects: A tensor that is simply correctsbool cast to floats.
corrects = tf.where(correctsbool, tf.ones_like(correctsbool, dtype=tf.float32),
tf.zeros_like(correctsbool,dtype=tf.float32))
# corr: corrects, but for the right answer instead of our selected answer.
corr = tf.where(corrbool, tf.ones_like(corrbool, dtype=tf.float32),
tf.zeros_like(corrbool,dtype=tf.float32))
with tf.variable_scope(“loss”):
# Use sigmoid cross entropy as the base loss,
# with our distances as the relative probabilities. There are
# multiple correct labels, for each location of the answer word within the context.
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits = tf.nn.l2_normalize(logits,-1),
labels = corr)
# Add regularization losses, weighted by weight_decay.
total_loss = tf.reduce_mean(loss) + weight_decay * tf.add_n(
tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))
# TensorFlow’s default implementation of the Adam optimizer works. We can adjust more than
# just the learning rate, but it’s not necessary to find a very good optimum.
optimizer = tf.train.AdamOptimizer(learning_rate)
# Once we have an optimizer, we ask it to minimize the loss
# in order to work towards the proper training.
opt_op = optimizer.minimize(total_loss)
# Initialize variables
init = tf.global_variables_initializer()
# Launch the TensorFlow session
sess = tf.Session()
sess.run(init)训练神经网络
万事俱备,我们可以开始批次化训练神经网络了。在训练过程中,我们应该持续监测神经网络的准确度指标。我们从测试数据里取出一部分作为验证数据集,这样它们和训练数据就不会有重叠了。
使用从测试数据集里生成的验证数据,我们就能够观察我们的神经网络的泛化能力,即从训练数据里学习到的东西能否应用于未知的上下文中。如果我们使用训练数据里的部分做验证,整个网络可能会过拟合,即学到了特定的上下文例子,并记住答案。但这在碰到新问题的时候并不会很好。
如果你安装了TQDM,你可以用它来跟踪网络已经被训练了多久,以及还要多久才能训练完。你可以通过中断Jupyter Notebook的kernel来在任何你觉得结果已经够好的时间停止训练。
def prep_batch(batch_data, more_data = False):
“””
Prepare all the preproccessing that needs to be done on a batch-by-batch basis.
“””
context_vec, sentence_ends, questionvs, spt, context_words, cqas, answervs, _ = zip(*batch_data)
ends = list(sentence_ends)
maxend = max(map(len, ends))
aends = np.zeros((len(ends), maxend))
for index, i in enumerate(ends):
for indexj, x in enumerate(i):
aends[index, indexj] = x-1
new_ends = np.zeros(aends.shape+(2,))
for index, x in np.ndenumerate(aends):
new_ends[index+(0,)] = index[0]
new_ends[index+(1,)] = x
contexts = list(context_vec)
max_context_length = max([len(x) for x in contexts])
contextsize = list(np.array(contexts[0]).shape)
contextsize[0] = max_context_length
final_contexts = np.zeros([len(contexts)]+contextsize)
contexts = [np.array(x) for x in contexts]
for i, context in enumerate(contexts):
final_contexts[i,0:len(context),:] = context
max_query_length = max(len(x) for x in questionvs)
querysize = list(np.array(questionvs[0]).shape)
querysize[:1] = [len(questionvs),max_query_length]
queries = np.zeros(querysize)
querylengths = np.array(list(zip(range(len(questionvs)),[len(q)-1 for q in questionvs])))
questions = [np.array(q) for q in questionvs]
for i, question in enumerate(questions):
queries[i,0:len(question),:] = question
data = {context_placeholder: final_contexts, input_sentence_endings: new_ends,
query:queries, input_query_lengths:querylengths, gold_standard: answervs}
return (data, context_words, cqas) if more_data else data
# Use TQDM if installed
tqdm_installed = False
try:
from tqdm import tqdm
tqdm_installed = True
except:
pass
# Prepare validation set
batch = np.random.randint(final_test_data.shape[0], size=batch_size*10)
batch_data = final_test_data[batch]
validation_set, val_context_words, val_cqas = prep_batch(batch_data, True)
# training_iterations_count: The number of data pieces to train on in total
# batch_size: The number of data pieces per batch
def train(iterations, batch_size):
training_iterations = range(0,iterations,batch_size)
if tqdm_installed:
# Add a progress bar if TQDM is installed
training_iterations = tqdm(training_iterations)
wordz = []
for j in training_iterations:
batch = np.random.randint(final_train_data.shape[0], size=batch_size)
batch_data = final_train_data[batch]
sess.run([opt_op], feed_dict=prep_batch(batch_data))
if (j/batch_size) % display_step == 0:
# Calculate batch accuracy
acc, ccs, tmp_loss, log, con, cor, loc = sess.run([corrects, cs, total_loss, logit,
context_placeholder,corr, locs],
feed_dict=validation_set)
# Display results
print(“Iter ” + str(j/batch_size) + “, Minibatch Loss= “,tmp_loss,
“Accuracy= “, np.mean(acc))
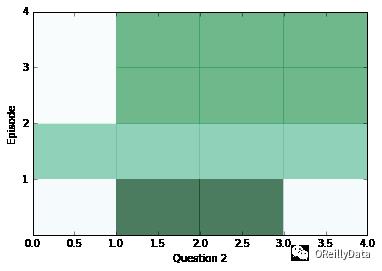
train(30000,batch_size) # Small amount of training for preliminary results在一段训练后,让我们看看网络的内部,检查一下网络会返回什么样的答案。在下面的一系列图片里,我们可视化了每个片段(行)和上下文里的所有的句子(列)。深色代表那个句子对片段有更多的注意力。
你应该能看到对每个问题,注意力至少在两个片段里被改变过。但是有时候注意力将能在一个里面发现答案,或者有时候注意力会关注所有四个片段。如果注意力看起来是空的,它可能是饱和了,对每个事情都进行关注。碰到这种情况,你可以试着使用一个更高的weight_decay来降低这种情况发生的可能性。在训练的后期,饱和会变得非常常见。
ancr = sess.run([corrbool,locs, total_loss, logits, facts_0s, w_1]+attends+
[query, cs, question_module_outputs],feed_dict=validation_set)
a = ancr[0]
n = ancr[1]
cr = ancr[2]
attenders = np.array(ancr[6:-3])
faq = np.sum(ancr[4], axis=(-1,-2)) # Number of facts in each context
limit = 5
for question in range(min(limit, batch_size)):
plt.yticks(range(passes,0,-1))
plt.ylabel(“Episode”)
plt.xlabel(“Question “+str(question+1))
pltdata = attenders[:,question,:int(faq[question]),0]
# Display only information about facts that actually exist, all others are 0
pltdata = (pltdata – pltdata.mean()) / ((pltdata.max() – pltdata.min() + 0.001)) * 256
plt.pcolor(pltdata, cmap=plt.cm.BuGn, alpha=0.7)
plt.show()
#print(list(map((lambda x: x.shape),ancr[3:])), new_ends.shape)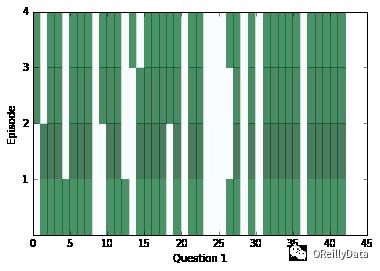
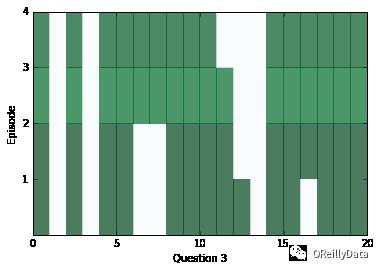
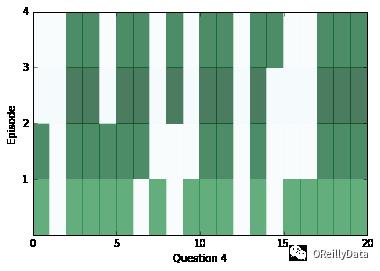
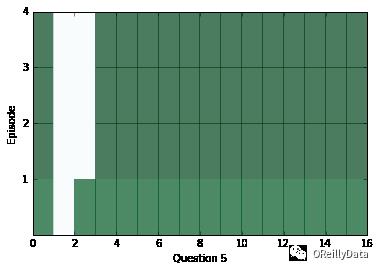
为了能看看上面问题的答案是什么,我们可以使用上下文里的距离得分的位置作为一个指数,看看什么词出现在那个指数里。
# Locations of responses within contexts
indices = np.argmax(n,axis=1)
# Locations of actual answers within contexts
indicesc = np.argmax(a,axis=1)
for i,e,cw, cqa in list(zip(indices, indicesc, val_context_words, val_cqas))[:limit]:
ccc = ” “.join(cw)
print(“TEXT: “,ccc)
print (“QUESTION: “, ” “.join(cqa[3]))
print (“RESPONSE: “, cw[i], [“Correct”, “Incorrect”][i!=e])
print(“EXPECTED: “, cw[e])
print()
TEXT: mary travelled to the bedroom . mary journeyed to the bathroom . mary got the football there . mary passed the football to fred .
QUESTION: who received the football ?
RESPONSE: mary Incorrect
EXPECTED: fred
TEXT: bill grabbed the apple there . bill got the football there . jeff journeyed to the bathroom . bill handed the apple to jeff . jeff handed the apple to bill . bill handed the apple to jeff . jeff handed the apple to bill . bill handed the apple to jeff .
QUESTION: what did bill give to jeff ?
RESPONSE: apple Correct
EXPECTED: apple
TEXT: bill moved to the bathroom . mary went to the garden . mary picked up the apple there . bill moved to the kitchen . mary left the apple there . jeff got the football there . jeff went back to the kitchen . jeff gave the football to fred .
QUESTION: what did jeff give to fred ?
RESPONSE: apple Incorrect
EXPECTED: football
TEXT: jeff travelled to the bathroom . bill journeyed to the bedroom . jeff journeyed to the hallway . bill took the milk there . bill discarded the milk . mary moved to the bedroom . jeff went back to the bedroom . fred got the football there . bill grabbed the milk there . bill passed the milk to mary . mary gave the milk to bill . bill discarded the milk there . bill went to the kitchen . bill got the apple there .
QUESTION: who gave the milk to bill ?
RESPONSE: jeff Incorrect
EXPECTED: mary
TEXT: fred travelled to the bathroom . jeff went to the bathroom . mary went back to the bathroom . fred went back to the bedroom . fred moved to the office . mary went back to the bedroom . jeff got the milk there . bill journeyed to the garden . mary went back to the kitchen . fred went to the bedroom . mary journeyed to the bedroom . jeff put down the milk there . jeff picked up the milk there . bill went back to the office . mary went to the kitchen . jeff went back to the kitchen . jeff passed the milk to mary . mary gave the milk to jeff . jeff gave the milk to mary . mary got the football there . bill travelled to the bathroom . fred moved to the garden . fred got the apple there . mary handed the football to jeff . fred put down the apple . jeff left the football .
QUESTION: who received the football ?
RESPONSE: mary Incorrect
EXPECTED: jeff让我们继续训练。为了能得到好的结果,你或许必须训练很久(用我的笔记本,花了12个小时)。但你应该最终能得到一个非常高的准确率(超过90%)。有经验的Jupyter Notebook用户应该知道,你可以在任何时间中断训练过程并保存已经训练的网络,只要你保持使用相同的tf.Session。如果你想可视化注意力和当前网络能给出的答案,这一方式会非常有用。
train(training_iterations_count, batch_size)
# Final testing accuracy
print(np.mean(sess.run([corrects], feed_dict= prep_batch(final_test_data))[0]))
0.95当看到我们的模型被训练出来之后,我们就可以结束这个会话来释放资源。
sess.close()想尝试更多?
完成上面的步骤后,还是有很多可以试验和尝试的东西:
bAbI里的其他任务。我们仅仅只是处理了bAbI的很多任务里的一小部分。你可尝试修改一下预处理的过程来适配其他的任务,再看看动态记忆网络在它们上面的表现。当然你可能希望在用于新任务前重新训练一下神经网络。如果新的任务并不保证答案一定在上下文里,你可能希望去比较网络的输出和一本字典里的词的相应的向量。任务6-10和17-20是这样一些任务。我也建议你去尝试一下任务1和3。你只要通过修改test_set_file和train_set_file就能实现任务修改。
监督训练。我们的注意力机制是无监督的,因为我们并没有明确地给出哪些句子应该被注意,而是让网络自己去发现。你可以试着去给网络的损失加上一些方法来在注意力关注了正确的句子时鼓励它一下。
同时注意力。不像我们这里这样只关注于单一输入的句子,一些研究人员已经在他们叫做“动态同时注意力网络”里获得成功。这种网络会同时关注两个句子里的两个位置的矩阵。
其他向量化的方法和来源。你可以尝试更智能的句子和向量的映射方法,或是使用不同的数据集。GloVe提供了一个多达8400亿条唯一词条的语料库,每个词条有300个维度。
这篇文章是O’Reilly和TensorFlow的合作产物。请阅读我们的编辑独立声明。
This article originally appeared in English: "Question answering with TensorFlow".

Steven Hewitt
Steven Hewitt目前是加州大学伯克利分校EECA系的计算机专业研究生。他的研究兴趣包括AI、自然语言处理、教育和机器人。他目前的研究项目包括教会程序去理解代码里的模式并用人能理解的方式来展示,还有词向量的方法,以及问答系统。当他不上课或写代码的时候,他会创作音乐或是分形火焰艺术。
课程推荐
使用keras快速构造深度学习模型实战
微软&谷歌数据科学家,带你每周案例实战
语音转换、智能音箱、语音翻译、图像识别等关键技术均涉及深度学习。
CNTK、TensorFlow、Theano、Caffe等来源深度学习工具包应运而生,降低了深度学习技术的使用门槛,但也对初学者造成了学习困难。
Keras是一个更易于使用、兼具兼容性和灵活性的深度学习框架,它的底层可以在CNTK、TensorFlow和Theano中自由切换。
Keras的出现使很多初学者可以快速体验深度学习的基本技术和模型,并且应用到实际问题中。
——《Keras快速上手 基于Python的深度学习实战》学习笔记
 往期精彩文章
往期精彩文章
点击图片阅读
以上是关于手把手丨用TensorFlow开发问答系统的主要内容,如果未能解决你的问题,请参考以下文章
手把手教你由TensorFlow上手PyTorch(附代码)