TD 分享 | TensorFlow 在企业中的应用——深度学习生态概述 Ⅱ
Posted TalkingData数据学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TD 分享 | TensorFlow 在企业中的应用——深度学习生态概述 Ⅱ相关的知识,希望对你有一定的参考价值。
本文为 TalkingData Heisatis 翻译自 O'Reilly 的一篇报告,介绍了 TensorFlow 在企业中的应用,对深度学习生态进行了概述。文章篇幅较长,分为三篇推送,本文为第二篇。
原文作者为 Sean Murphy & Allen Leis,原文链接及报告下载链接见阅读原文。
可点击下方链接阅读本报告第一部分:
第二章:选择一个深度学习框架
当决定采用深度学习时,第一个问题就是你应该选择哪个深度学习库(以及为什么)?深度学习已经成为许多大型科技公司的重要差异化因素,每一个都已经发展或正在倡导一个特定的选择。
如谷歌的 TensorFlow,微软的认知工具包(又名 CNTK)。亚马逊正在支持学术界建造的 MXNet,这导致有人质疑其内部开发的 DSSTNE(Deep Scalable Sparse Tensor Network Engineer)的寿命。百度拥有并列分布式深度学习(PADDLE)库。 Facebook 有 Torch 和 PyTorch。英特尔拥有 BigD 等等。毫无疑问未来还会有更多选择出现。
我们可以对各种深度学习库进行评估,包括性能、支持的神经网络类型、易用性、支持的编程语言、作者、社区的支持等等。为了提高竞争力,每个库应该支持使用图形处理单元(GPU),最好是多个 GPU 和分布式计算集群。表 2-1 总结了十几种可用的顶级开源深度学习库。
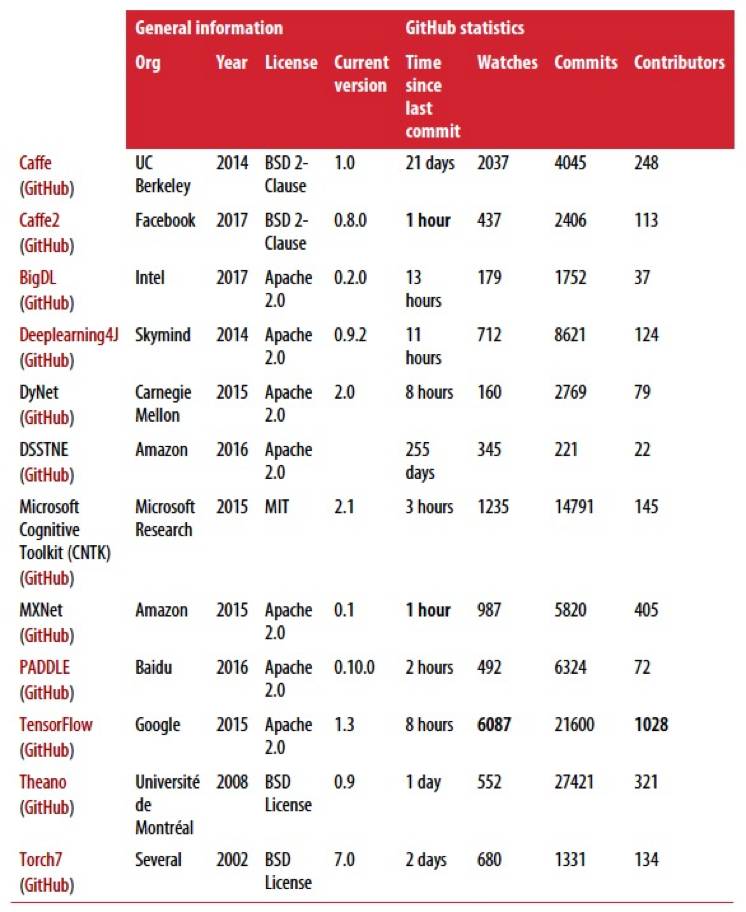
表 2-1 12 个选定深度学习框架的一般信息和 GitHub 统计信息(每个适用列中的“最佳”值以粗体突出显示)
支持的编程语言
几乎所有表内列出的框架都是用 C ++ 实现的(可以使用 Nvidia 的 CUDA 进行 GPU 加速),但是在 Lua 中有后端的 Torch 和为 Java 虚拟机(JVM)写了后端的 Deeplearning4J。
使用这些框架的一个重要问题是他们支持哪些编程语言进行魔性训练,允许神经网络从数据中学习并更新内部权重的计算密集型任务,以及支持哪种语言进行推断,通过之前训练得到模型和新数据获得预测值。
由于推断是生产中比较常见的任务,人们可能会争辩说,库支持推理的语言越多,插入现有企业基础架构就越容易。一般来说训练过程需要专业技术,支持的语言可能会比较有限。理想情况下,一个框架需要可以支持这两个任务的同一套语言。
不同类型的网络
有许多不同类型的神经网络,学术界和工业界的研究人员几乎每天都在开发具有相应新缩写词的新网络类型。例如前馈网络、全连接网络、卷积神经网络(CNN)、受限玻耳兹曼机器(RBM)、深度信念网络(DBN)、自动去噪编码器、堆叠去噪自动编码器、生成对抗网络(GAN)、循环神经网络(RNN)等等。
如果要用图形或列表来表示不同的神经网络类型/结构,神经网络俱乐部,是一种初步的选择。
已经受到广泛关注的两种网络类型是卷积神经网络,其能够处理图像作为输入,以及可以处理时序数据的循环神经网络及其变体(例如 LSTM),支持将句子中的文本、时间序列数据、音频流等等作为输入。企业选择的深度学习库应该支持最广泛的网络,至少需要尽量与业务需求相关。
部署和操作选项
尽管机器学习和深度学习通常需要大量的训练数据,但深度学习确实预示着从大数据向大型计算的过渡。
对于企业来说,这可能是最大的问题和潜在的障碍,从更传统的机器学习技术过渡到深度学习。训练大规模的神经网络可能需要几周甚至几个月的时间; 因此即使是 50% 的性能增益也能带来巨大的收益。
为了使这个过程变得可行,训练网络需要大量的原始计算能力,这些计算能力通常以一个到多个 GPU,或专用处理器的形式出现。理想情况下,一个框架将支持单 CPU、多 CPU、GPU 环境以及他们的异构组合。
无障碍的帮助
提供帮助的程度对于库的实用性和成功性而言是非常重要的组成部分。文档量是衡量平台是否成功(及其潜在寿命)的有力指标。大量的文档促使用户容易选择和使用库。随着生态系统的不断发展,在线教程、电子书籍和在线图书、视频、在线和离线课程、甚至会议等多种形式的文档都是需要的。
特别要注意的是企业商业支持的问题。尽管上述所有库都是开源的,但只有一个库提供直接的商业支持:Deeplearning4J。 第三方很可能会更愿意提供咨询服务来支持每个库的使用。
1. 企业级的深度学习
从十几个深度学习框架中进行选择,我们对其中四个更适合企业生产环境部署的库进行了深入研究:TensorFlow、MXNet、Microsoft Cognitive Toolkit 和 Deeplearning4J。为了大致估算受欢迎程度,图 2-1 显示了按 Google 搜索量衡量的搜索词相对全球范围内的兴趣。
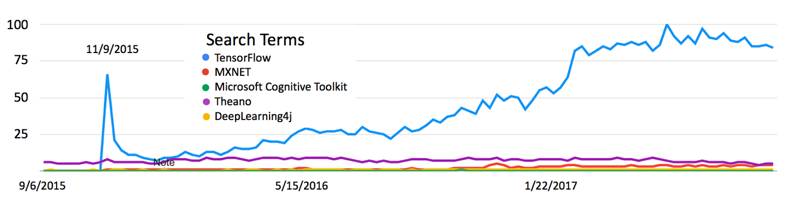
图 2-1 在深度学习开源框架中,全球搜索“随时间推移的兴趣”最大相对值(100)出现在在 2017 年 5 月 14 日这周
TensorFlow
Google 在处理大规模数据方面有着丰富的历史经验,运用机器学习和深度学习为消费者和企业创造有价值的服务。当 Google 发布开源软件时,业界都会比较关注,特别是有新版本发布时。
2011 年,Google 内部使用名为 DistBelief 的系统进行深度学习,该系统能够使用“大规模机器集群在深度网络中分发训练和推理”。凭借多年运营这个平台的经验,Google 最终于 2015 年 11 月发布了 TensorFlow。

TensorFlow 是用于表达机器学习算法的界面,以及用于执行这种算法的实现。 使用 TensorFlow 表达的计算可以在各种各样的异构系统上执行,从移动设备(例如手机和平板电脑)到大型分布式系统(数百台机器)以及数千个计算设备(如 GPU)。
该系统是灵活的,可以用来表达各种各样的算法,包括深度神经网络模型的训练和推理算法,它已经被应用在十几个计算机科学等研究领域,进行机器学习系统部署和投产,例如语音识别、计算机视觉、机器人学、信息检索、自然语言处理、地理信息提取和计算药物成分等。
有些人认为这是一个赢家通吃的领域,可以说 TensorFlow 已经赢得了开发者的心。虽然这个声明可能还为时过早,但 TensorFlow 目前拥有令人印象深刻的源动力。
几乎所有的指标都显示,TensorFlow 都是深度学习领域最活跃的开源项目。现在已经产生了相当多有关 TensorFlow 的书籍和高端会议。以 Google 搜索量衡量,已经获得了全球范围内广泛的关注和兴趣,并且具有最多的有关活动聚会。 对竞争对手来说,这种领先将很难被超越。
MXNet
MXNet 是我们将深入研究的最新的深度学习框架。它于 2017 年 1 月进入 Apache 孵化,截至 2017 年 10 月的最新版本是目前已经发布 1.0 正式版。 问题是,由于其比较新而且竞争对手很强大,企业是否应该考虑到这种替代性的深度学习框架呢?
亚马逊在 2016 年 11 月宣布,AWS 选择的深度学习框架是 Apache MXNet。MXNet 背后的创始机构之一,卡内基梅隆大学和 CMU 机器学习系教授 Alexander Smola 博士,2017 年 7 月加入亚马逊可能并非巧合。
为了进一步证明 MXNet 的竞争力,最新的框架版本允许开发人员将 MXNet 深度学习模型转换为 Apple 的 CoreML 格式,这意味着数十亿 ios 设备现在可以为使用 MXNet 的应用程序提供推理功能。另外请注意,苹果公司是与上述任何一个深度学习框架都没有关联的大型科技公司。
什么是 MXNet,它是如何改进现有的库的?
MXNet 是一个多语言机器学习库,用于简化机器学习算法的开发,特别是深度神经网络。 嵌入在宿主语言中,它将声明性符号表达式与命令张量计算相结合。它提供了自动分化来推导梯度。MXNet 具有计算和内存的高效性,可运行在各种异构系统上,从移动设备到分布式 GPU 集群。
MXNet 是由许多顶尖大学(包括 CMU、麻省理工学院、斯坦福大学、纽约大学、华盛顿大学和阿尔伯塔大学)合作而成的。从其最近的开发情况看,作者有机会在已有的深度学习框架中学习并改进。
框架提供灵活的性能。开发人员可以混合使用符号和命令式编程模型,并且可以通过动态依赖调度程序来并行化两者。开发人员还可以利用预定义的神经网络层来构建复杂的网络,而代码很少。
重要的是,MXNet 远不止支持 Python。 它也具有完整的 Scala、R、Julia、C ++、甚至 Perl 的 API。最后,MXNet 代码库很小,专为在 GPU 和 CPU 上进行高效扩展而设计。
微软认知工具包(CNTK)
尽管互联网崛起,微软仍然是企业领域的主要厂商之一。因此,微软研究院推出深度学习框架应该是不足为奇的。以前称为“计算神经工具包”(CNTK),该工具包显然是从微软研究院的世界级语音识别团队中涌现出来的,然后推广到其他问题集。

2014 年出现了第一篇综合报告,2016 年 1 月在 Github 上发布了该软件。2016 年,该软件在会话语音识别领域取得了人类的表现。与竞争对手相比,该工具包有望实现高效的可扩展性和令人印象深刻的性能。
Deeplearning4J
Deeplearning4J 在这个列表中有些奇怪的框架。尽管 Python 已经成为深度学习的近乎事实上的首选语言,但 Deeplearning4J 是在 Java 中开发的,旨在使用 JVM 并与基于 JVM 的语言(如 Scala、Clojure、Groovy、Kotlin 和 JRuby)兼容。
请注意,底层计算采用 C / C ++和 CUDA 编码。这也意味着 Deeplearning4J 可以同时支持 Hadoop 和 Spark。
其次,许多早期的深度学习框架是由学术界出现的,而第二波则是由大型科技公司兴起的。

Deeplearning4J 是不同的,因为它是由一个位于旧金山的小型科技创业公司(Skymind)在 2014 年创建的。尽管 Deeplearning4J 是开源的,但还是有一家公司愿意为使用该框架的客户提供付费支持。
2. 行业观点

Jet.com 提供了深度学习库选择的一个有趣的例子。 Jet.com 是一家从上到下采用微软技术栈的公司,是美国为数不多的专注于 F#编程语言的商店之一(他们也使用 C#和.NET 框架)。

对于云服务,该公司使用 Microsoft Azure。尽管重度依赖微软,Jet.com 还是使用 TensorFlow 进行深度学习。该公司最初是从 Theano 开始的,但在 TensorFlow 发布之后迅速转换到了 TensorFlow。TensorFlow 运行在具有在 Microsoft Azure 云中运行的 GPU 的虚拟实例上。

作为一家技术创业公司,PingThings 在选择不同的技术方面有很大的余地。 Google 在这个领域的突出地位以及大量的文档和教程都是选择 TensorFlow 的强大动力。
然而,PingThings 正在与国家科学基金会(NSF)和高级研究计划署能源(ARPA-E)资助的项目与多个研究机构的合作者合作,同时在公用事业部门内部署硬件。
因此,Google 设计 TensorFlow 来平衡研究和大规模运营的需求是非常重要的事实。Tensor2Tensor(我们稍后讨论的生态系统的一部分)特别吸引人,因为它专注于序列数据。MXNet 是一个有趣的新选项,未来的发展将受到关注,特别是考虑到其卓越的性能和亚马逊的支持。
3. 本章小结
TensorFlow 做得非常好:有竞争力的性能、对不同神经网络类型的强大支持、大量的硬件部署选项、支持多 GPU、多种编程语言选项等等。
然而,库的魅力超越了这个功能集。Google 通过分布式文件系统和 Map-Reduce 计算框架的结合,在帮助启动大数据革命方面发挥了重要作用,并在今天继续领跑业界。
此外,谷歌内部有许多成功的技术迭代,然后看到广泛的发布。受欢迎的容器编排系统 Kubernetes 就是这样一个例子,它是早期内部系统(如 Borg 和 Omega)的多年经验和教训的结果。谷歌在网络技术和软件工程方面的推进规模,学术界和工业界之间的平衡,似乎特别适合于深度学习的淘金热。
TensorFlow 继承了这种合理性,目的是充分灵活地进行深入的研究,同时也足够强大,以允许其模型的生产部署。未来可能会出现更新的框架,可以借鉴 TensorFlow 的经验教训,改进库的各个方面,提供多种编程方法,或提供更高的性能。
上述许多库都试图做一个或多个这样的事情。然而,TensorFlow 正在不断应用这些教训,努力提高性能并探索新的方法。
只要 Google 的重量和努力落在 TensorFlow 后面,它将继续成为深度学习库的一个强大、安全、实际上默认的选择,特别是考虑到我们在第 3 章中描述的生态系统。
(To be Continue…)
注:图片来自网络
以上是关于TD 分享 | TensorFlow 在企业中的应用——深度学习生态概述 Ⅱ的主要内容,如果未能解决你的问题,请参考以下文章