推荐阅读 | 如何让TensorFlow模型运行提速36.8%(续)
Posted 深度学习每日摘要
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐阅读 | 如何让TensorFlow模型运行提速36.8%(续)相关的知识,希望对你有一定的参考价值。
之前讲过,但是之前的推送只是牛刀小试,让大家看看效果,代码案例没有包括所有的情况,例如如何在批训练中引入Pipeline,如何针对大数据集和小数据集作不同的处理等等,有很多读者对这些问题比较关心,今天为大家介绍如何写一个更实用的TensorFlow Pipeline,从而为模型提速。
我们知道,在基于TensorFlow构建深度学习项目的时候,都是先构建好计算图,然后建立会话,在训练的时候,每一步都要将数据feed到计算图里面。实际上,这种做法十分不高效,如果我们改用多线程和队列来导入数据的话,模型的训练速度可以提高36.8%,也就是说对于某个模型原本可能需要一个星期的训练时间,经过数据导入优化以后,现在只需要大约4天时间了,这对于调参工作是十分有利的。
看过的读者应该都熟悉了TensorFlow中Pipeline的流程,这里不再重复描述了,我们今天要谈的重点就是如何将上一期的思想运用到实际项目中,也就是如何进行mini-batch 训练、如何写入并读取TFRecords文件。
1. 训练数据集较小,一次性导入
当我们的数据集较小时,例如它本身已经是数组的形式存储的,我们可以采取一次性读取到内存的方式。例如下面一段代码,我演示了生成一对训练数据,其中x的大小是[sn, fs],y的大小是[sn, num_classes],这里的sn的含义是指总样本个数,而fs是指特征向量维度。这里我假设的是一个分类问题,标签其实就是one-hot向量。
在建立好数据以后,我们需要构建一个队列,以及出队的操作,目的是运用多线程来执行出队操作并弹出训练样本到计算图中。这里我的做法就是,运用tf.train.slice_input_producer来产生num_epochs*sn个样本对,这个函数类似一种复制操作,可以将所有样本复制为其num_epochs倍个。同时,这个函数提供了shuffle参数,可以将num_epochs*sn个样本进行随意打乱。这个函数内部是使用了FIFOQueue,并且这个Queue已经加入到TensorFlow QUEUE_RUNNER集合中,后文中讲解的多个函数内部都是使用了FIFOQueue。我们的代码如下所示:

在产生了所有样本以后,接下来顺理成章的事情就是将num_epoch*sn个样本对划分成多个mini-batch,这里我的做法是使用tf.train.batch函数,由下面的代码可以看到,tf.train.batch函数的作用实际上就是从num_epoch*sn个样本中选取batch_size个样本出来,这正好满足mini-batch训练的要求。示例代码如下:
对于小数据集,关键的步骤就是以上两步,我的示例代码中还象征性地构建了一个DNN模型,并且使用了交叉熵函数作为损失函数,以及如何开启多线程、如何保存模型、如何添加summary,不过这些不是本文的重点,大家点击阅读原文就可以看到该项目的所有代码。
通过Tensorboard可视化模块,我们得到了如下的计算图的结构,这就是对于小数据集的处理框架。
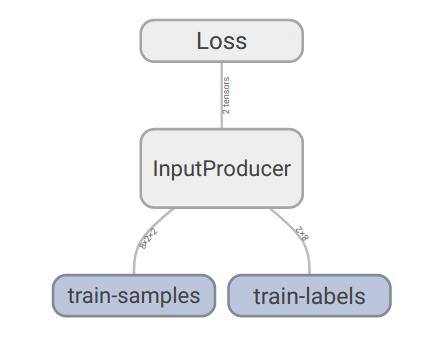
2. 训练数据集较大,转成TFRecords
其实,大部分时候,我们所做的深度学习项目涉及的数据集都是十分庞大的,大到几十G甚至是几百G,那么这么大的数据集我们一般是不能直接一次性读取的,而是采取存储为文件中然后再读取。
这里我们要介绍TensorFlow官方提供的一种标准的文件存储格式TFRecords,TFRecords可以存储任意格式的数据,它是基于Google的Protocol Buffer数据格式来存取,可以独立于语言、独立于平台,并且TFRecords通过Features字段来指定对象。
我代码中详细列出了如何写TFRecords,简单来说,首先把待写对象放到tf.train.Feature中,对于这一步,我写了两个辅助函数,_bytes_feature和_int64_feature。如果你存储的是一个整型标量的话,那么你就可以调用_int64_feature函数,如果你要存储的是其他任意格式,你都可以调用_bytes_feature函数。将对象放入到Feature字段之后,再调用tf.train.Example即可转成Protocol Buffer,然后对其序列化即可存储到TFRecords文件中。整个流程的代码如下所示:
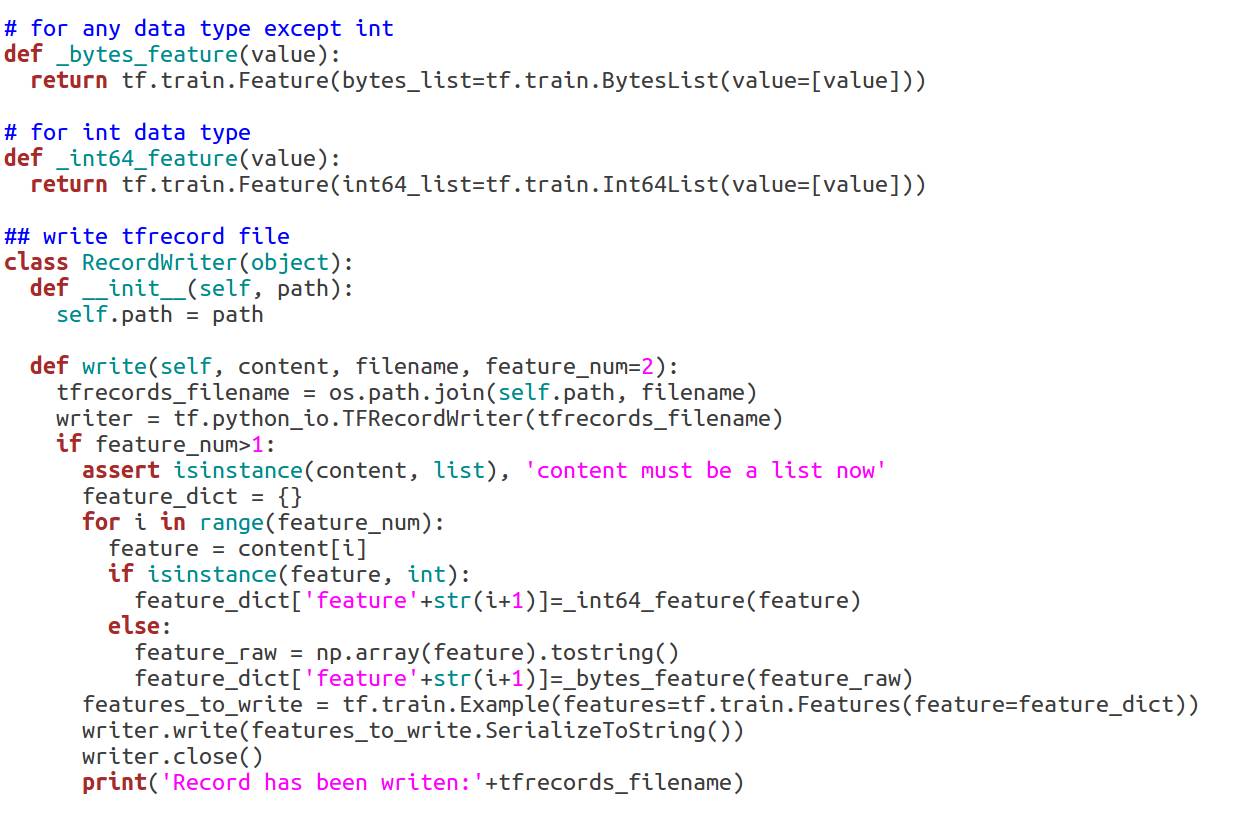
在写入的时候,我们一般采取的方式是将一对sample-label存储到一个文件中,这样方便我们后续的读取以及导入,具体写入TFRecords的示例代码如下:

到目前为止,还只是写文件的阶段,只能谈得上是预处理中的预处理,接下来就是重点的部分了。在项目中,首先第一步就是读取TFRecords文件并把其中的数据解析出来,为了引入多线程和FIFOQueue来处理数据,我们这里调用了一个tf.train.string_input_producer函数。顾名思义,这个函数是用来产生字符串的,为什么要产生字符串?其实这里的字符串就是文件名,也就是说TensorFlow内部的队列中存储了一个个TFRecords文件的文件名称(或者说文件路径),tf.train.string_input_producer函数中同样有一个参数num_epochs,这个参数的作用也是为了复制文件名形成一个总体的集合,这样我们就构建了一个文件名的队列,代码如下:

构建好文件名队列以后,当TensorFlow内部的多线程程序运行出队这个操作的时候,也就是要读取那些TFRecords文件,这里读取也需要注意,读取相当于解码,当初是怎么存储的就要怎么读取,格式不能乱,格式不对解码出来的数据也就肯定不对。比如你当初存储的格式是float64,如果现在读取的时候使用float32去读取,那么数据个数显然是增多了,这样结果就不对了。还有一点需要注意的是,读取之后要显式指明数据的大小,因为解码出来的数据TensorFlow是不知道它的维度特征的,这里我建议可以采用tf.reshape函数,表面上是对数据进行reshape,实际上是指明数据的格式,当然有时候两个作用都有,因为解码出来的都是一维向量,但是存储的时候是二维向量,这个时候reshape就起到了应有的作用了。代码如下:

读取完成以后,剩下的代码就和小数据集中的代码基本一样了,也是调用tf.train.batch函数来进行mini-batch训练,这里就不重复说明了。大家可以点击阅读原文查看我项目的所有代码。
类似的,我们可以通过Tensorboard可视化模块,得到了如下的计算图的结构,这就是我代码中对于大数据集的示例计算图。
本文中只是列举了一些重点代码,其实还有很多细节的代码,大家可以点击阅读原文查看此项目。希望对大家有所帮助!
题图:Pawel Kuczynski
你可能会感兴趣的文章有:
深度学习每日摘要|坚持技术,追求原创
以上是关于推荐阅读 | 如何让TensorFlow模型运行提速36.8%(续)的主要内容,如果未能解决你的问题,请参考以下文章