海难幸存者:基于项目的TensorFlow.js简介
Posted 论智
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海难幸存者:基于项目的TensorFlow.js简介相关的知识,希望对你有一定的参考价值。
编者按:今年4月,谷歌在TensorFlow开发者峰会上发布TensorFlow的javascript版本,引起开发者广泛关注。如今3个月过去了,大家学会使用这个机器学习新框架了吗?在这篇文章中,我们将用一个初级项目Neural Titanic来演示如何使用TensorFlow.js,联系到最近发生在泰国的事故,这次我们选用的数据集是“泰坦尼克号”,目标是分析哪些人更能从悲剧中幸免于难(二元分类)。
Demo
注:本文适合对前端JavaScript开发有基本了解的读者。
神经网络
经过Geoffrey Hinton、Yoshua Bengio、Andrew Ng和Yann LeCun等人的不懈努力,如今神经网络终于可以正大光明地站在阳光下,并在现实中有了用武之地。众所周知,传统统计模型可以处理结构化的数据,但对非结构化的数据,如图像、音频和自然语言却无可奈何。现在,通过往神经网络中添加更多层神经元,也就是我们常说的深度学习研究,对非结构化数据建模已经不再是难事。
以图像建模为例,图像中最简单的特征是边缘,这些边缘是形成纹理的基础,纹理是形成简单对象的基础,而简单对象又是形成复杂对象的基础。这种关系正好契合深层神经网络的多层结构,因此我们也能学习这些可组合的特征。(考虑到文章的目的是介绍TensorFlow.js,我们对深度学习的介绍就此打住。)

如需要以上PPT,欢迎私信哦
在过去这几十年中,随着计算机算力和可用数据的急剧增加,神经网络已经成为解决诸多现实世界问题的可行方案。与此同时,像TensorFlow这样的机器学习库也在快速崛起,鼓励开发者尝试用神经网络解决问题。虽然完全搞懂神经网络不是一时半会儿就能做到的,但我们希望这篇文章能激发开发者兴趣,鼓励他们去创建自己的的神经网络程序。
项目概述
如上所述,神经网络非常适合对非结构化数据进行建模,而本文的示例数据集是泰坦尼克号,它只包含表格数据。这里我们先澄清一个误区,看完之前的介绍,一些人可能会认为神经网络是万能的,它比传统统计模型更好,但事实上,对于简单数据,模型结构越简单,它的性能就越好,因为那样越不容易出现过拟合。
例如泰坦尼克号数据集,或者其他几乎所有类型的表格数据,神经网络在处理它们时需要用到的超参数有batch-size、激活函数和神经元数量等,但像决策树这样的常规算法只需调整更少超参数,最后性能也差不多。所以虽然鼓励新手多多尝试,但当我们建模时,真的没有必要事事都用神经网络。
在这个项目中,因为神经网络处理的是简单数据集的二元分类任务,我们会结合可视化技术,具体介绍最后的单隐藏层神经网络。如果你已经精通前端JavaScript开发,也能熟练使用像React这样的前端框架,你可以在读完本文后再去学习官方文档,相信它会让你对TensorFlow.js产生更多兴趣:js.tensorflow.org/tutorials/mnist.html
数据集和建模概述
泰坦尼克号数据集适合初学者,由于比较小,影响输出结果的各项特征也比较好找。我们的任务是根据表格数据预测乘客的生存概率,因此可以被用来辅助预测的列是X,预测的目标列则是Y。下面是数据集中的部分数据:
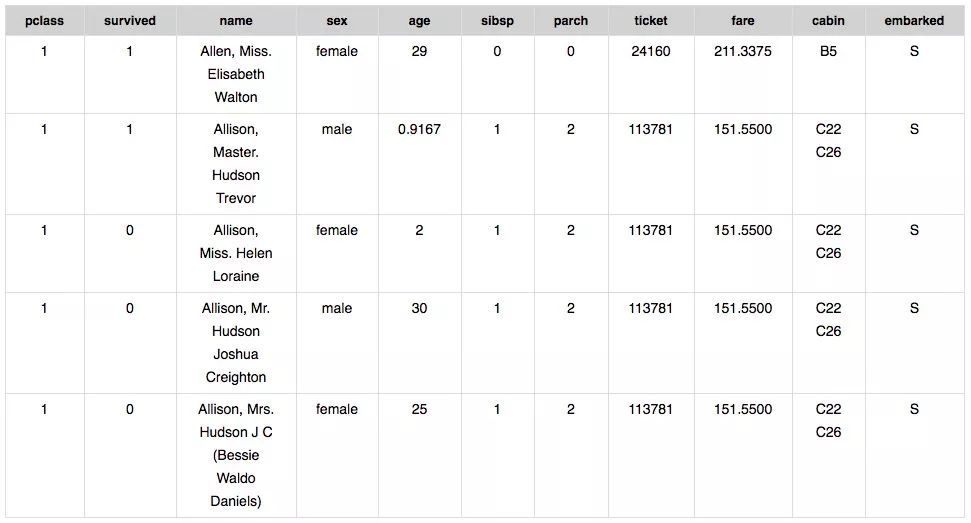
对应X和Y,我们可以获得:
预测特征(X)
pClass:船票等级(1等、2等、3等)
name:乘客的姓名
sex:乘客的性别
age:乘客的年龄
sibsp:船上和乘客相关的兄弟姐妹、配偶人数
parch:船上与乘客相关的父母和孩子人数
ticket:乘客的票号
fare:乘客为船票支付的金额
cabin:乘客所在船舱
Embarked:登船港口(C=Cherbourg, Q=Queenstown, S=Southampton)
目标标签(Y)
survived:乘客幸存为1,死亡为0
原数据集中包含超过1000名乘客的信息,这里为了简洁直观,我们假装上表就是我们的数据集,X和y的映射关系如下所示:

从技术意义上讲,神经网络为非线性函数拟合提供了一个强大的框架。如果把上图转换成函数形式,它就是:
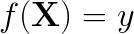
对于神经网络,如果我们要模型学会其中的映射关系,这个学习过程被称为训练。最后得到的结果必定是个近似值,而不是精确函数,因为如果是后者,这个神经网络就过拟合了,它强行记住了数据集的所有结果,这样的模型是没法用在其他数据上的,泛化(通用化)水平太低。作为深度学习实践者,我们的目标是构建近似上述函数的神经网络体系结构,让它不仅在训练集上表现出色,也能被推广到从未见过的数据上。
项目设置
为了防止每次开发都要重新绑定源代码,这里我们先用webpack bundler把JavaScript源代码和webpack dev服务器捆绑起来。

在开始项目前,我们先做一些设置:
安装Node.js
到github上下载这个repo:github.com/Andrewnetwork/NeuralTitanic
打开终端,再打开下载的repo
设置终端类型:npm install
键入以下命令启动dev服务器:npm run dev
单击终端中显示的URL,或在Web浏览器中输入:localhost:8080/
在步骤4中,用npm来安装package.json中列出的项目依赖项。在步骤5中,启动开发服务器,上面会显示步骤6中需要点击的URL。这之后,每当我们保存对源代码的修改时,网页上会实时刷新内容,并显示更改。
如果需要捆绑源代码,只需运行npm run build,它会自动生成文件放进./dist/文件夹中。
代码
虽然文章开头我们展示了一个比较美观的Demo,但这里我们没有介绍index.html、index.js、ui.js等内容,一方面是因为本文假设读者已经熟悉现代前端JavaScript开发,另一方面是这些细枝末节介绍起来太复杂,容易讲不清楚。如果确实有需要,可以直接用步骤2中提到的repo,或者Python了解下?学起来很快的!:stuckouttongue:
preprocessing.js
function prepTitanicRow(row){
var sex = [0,0];
var embarked = [0,0,0];
var pclass = [0,0,0];
var age = row["age"];
var sibsp = row["sibsp"];
var parch = row["parch"];
var fare = row["fare"];
// Process Categorical Variables
if(row["sex"] == "male"){
sex = [0,1];
}else if(row["sex"] == "female"){
sex = [1,0];
}
if(row["embarked"] == "S"){
embarked = [0,0,1];
}
else if(row["embarked"] == "C"){
embarked = [0,1,0];
}
else if(row["embarked"] == "Q"){
embarked = [1,0,0];
}
if(row["Pclass"] == 1){
pclass = [0,0,1];
}
else if(row["Pclass"] == 2){
pclass = [0,1,0];
}
else if(row["Pclass"] == 3){
pclass = [1,0,0];
}
// Process Quantitative Variables
if(parseFloat(age) == NaN){
age = 0;
}
if(parseFloat(sibsp) == NaN){
sibsp = 0;
}
if(parseFloat(parch) == NaN){
parch = 0;
}
if(parseFloat(fare) == NaN){
fare = 0;
}
return pclass.concat(sex).concat([age,sibsp,parch,fare]).concat(embarked);
}
对于任何数据分析工作,数据预处理是非常重要的,也是十分有必要的,上面的代码就在进行预处理:把分类变量转换为one-hot编码,并用0替代缺失值(NaN)。因为这是个简单数据集,事实上我们还可以更优雅一点,用算法来填补缺失值,但考虑到篇幅因素,这里我们都做简化处理。
}
export function titanicPreprocess(data){
const X = _.map(_.map(data,(x)=>x.d),prepTitanicRow);
const y = _.map(data,(x)=>x.d["survived"]);
return [X,y];
}
在这里,我们把预处理函数prepTitanicRow映射到数据的每一行,这个函数的输出是特征变量X和目标向量y。
modeling.js
export function createModel(actFn,nNeurons){
const initStrat = "leCunNormal";
const model = tf.sequential();
model.add(tf.layers.dense({units:nNeurons,activation:actFn,kernelInitializer:initStrat,inputShape:[12]}));
model.add(tf.layers.dense({units:1,activation:"sigmoid",kernelInitializer:initStrat}));
model.compile({optimizer: "adam", loss: tf.losses.logLoss});
return model;
}
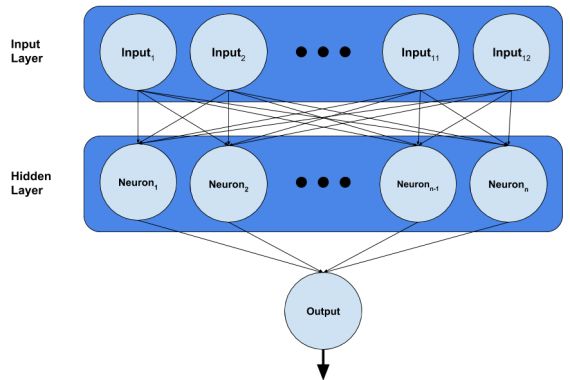
现在我们就可以创建单隐藏层神经网络了,它已经被actFn和nNeurons两个变量参数化。可以发现,我们要近似的函数有多个输入,却只有一个输出,这是因为我们在上面的预处理步骤中扩展了特征空间的维度;也就是说,我们现在有一个步长为3的one-hot输入,而不是只有一个输入端口,如下图所示:
const initStrat = "leCunNormal";
上图中这些带箭头的线被称为“边”,它们自带权重,我们训练神经网络的最终目标就是把这些权重调整到最佳值。在刚开始训练的时候,因为对情况一无所知,这些边会被随机分配一个初始值,我们把它称为初始化策略。
一般情况下,这个初始化不用你自己声明,TensorFlow提供了通用性较强的默认初始化策略,在大多数情况下都表现良好。但就事论事,这个策略确实会影响神经网络性能,尤其是我们这次用到的数据集太小了,权重的初始值会对训练过程造成明显影响。所以这里我们自选一种初始化策略。
const model = tf.sequential();
这个序列模型对象就是我们用来构建神经网络的东西。它意味着当我们往里面添加神经网络层时,它们会按顺序堆叠,先输入层,再隐藏层,最后是输出层。
model.add(tf.layers.dense({units:nNeurons,activation:actFn,kernelInitializer:initStrat,inputShape:[12]}));
在这里,我们添加了一个输入层(大小为12),并在它后面又加了个密集连接的隐藏层。密集连接表示这一层的所有神经元都与上一层的每个神经元相连,在图中,神经元被表示为圆,但需要注意的是,它是个存储单位,我们的输入不是神经元。
隐藏层会继承定义图层的参数词典:我们定义了多少参数,它就接收多少参数。除了我们提供的参数,它还有一些默认参数:
units:神经元个数,这是个可调整的超参数。
activation:该层中应用于每个神经元的激活函数,对于本文已超纲,请自学选择。
kernelInitializer:初始化。
inputShape:输入空间大小,在我们的例子里是12。
model.add(tf.layers.dense({units:1,activation:"sigmoid",kernelInitializer:initStrat}));
这是我们整个神经网络的最后一层,它只是一个密集连接到隐藏层的单个输出神经元。我们用sigmoid函数作为该神经元的激活函数,因为函数的范围是[0,1],刚好适合二元分类问题。如果你还要深究“为什么这个函数能用于预测概率”,我只能简单告诉你,它和逻辑回归息息相关。
model.compile({optimizer: "adam", loss: tf.losses.logLoss});
截至目前,我们已经完成网络的搭建工作,最后就只剩下TensorFlow编译了。在编译过程中,我们会遇到两个新参数:
optimizer:这是我们在训练期间使用的优化算法。如果是新手,用Adam;如果很要求高,梯度下降会是你的最爱。
loss:这个参数的选择要多加注意,因为不同的建模问题需要不同的损失函数,它决定了我们会如何测量神经网络预测结果和实际结果之间的差异。这个误差会结合优化算法、反向传播算法进一步训练模型,一般情况下,我们用交叉熵。
最后就是神经网络模型的实际训练:
export async function trainModel(data,trainState){
// Disable Form Inputs
d3.select("#modelParameters").selectAll(".form-control").attr('disabled', 'disabled');
d3.select("#tableControls").selectAll(".form-control").attr('disabled', 'disabled');
// Create Model
const model = createModel(d3.select("#activationFunction").property("value"),
parseInt(d3.select("#nNeurons").property("value")));
// Preprocess Data
const cleanedData = titanicPreprocess(data);
const X = cleanedData[0];
const y = cleanedData[1];
// Train Model
const lossValues = [];
var lastBatchLoss = null;
// Get Hyperparameter Settings
const epochs = d3.select("#epochs").property("value");
const batchSize = d3.select("#batchSize").property("value")
// Init training curve plotting.
initPlot();
for(let epoch = 0; epoch < epochs && trainState.s; epoch++ ){
try{
var i = 0;
while(trainState.s){
// Select Batch
const [xs,ys] = tf.tidy(() => {
const xs = tf.tensor(X.slice(i*batchSize,(i+1)*batchSize))
const ys = tf.tensor(y.slice(i*batchSize,(i+1)*batchSize))
return [xs,ys];
});
const history = await model.fit(xs, ys, {batchSize: batchSize, epochs: 1});
lastBatchLoss = history.history.loss[0];
tf.dispose([xs, ys]);
await tf.nextFrame();
i++;
}
}catch(err){
// End of epoch.
//console.log("Epoch "+epoch+"/"+epochs+" ended.");
const xs = tf.tensor(X);
const pred = model.predict(xs).dataSync();
updatePredictions(pred);
const accuracy = _.sum(_.map(_.zip(pred,y),(x)=> (Math.round(x[0]) == x[1]) ? 1 : 0))/pred.length;
lossValues.push(lastBatchLoss);
plotLoss(lossValues,accuracy);
}
}
trainState.s = true;
createTrainBttn("train",data);
console.log("End Training");
// Enable Form Controls
d3.select("#modelParameters").selectAll(".form-control").attr('disabled', null);
d3.select("#tableControls").selectAll(".form-control").attr('disabled', null);
}
在具体介绍前,我们先看看一些常用的术语:
Epoch:在整个数据集上训练一次被称为一个epoch。
Mini-Batch:完整训练数据的子集。对于每个epoch,我们会把训练数据分成较小的子集一批批进行训练,通过对比,想必你也应该理解上一个术语的含义了。
如果还是觉得有困难,这里是完整版:
创建神经网络
预处理数据
Epoch Loop:我们手动设置的迭代次数
Mini-Batch Loop:我们还没有完成一个epoch,还有剩余数据,训练也没有停止——在Mini-Batch上训练模型。
End of epoch:已经进一步训练了模型,并让它对数据做了预测,而且已经用函数
updatePredictions更新了预测结果。
什么是“async”和“await”?
ES6允许我们定义异步函数,常见的有async函数,这里应该没问题。当我们训练模型时,用await,它也是个异步函数,这样我们就能让模型在进入下一个epoch前先完成训练。
tf.tidy和tf.dispose?
这些函数涉及所创建的张量。你可以在张量或变量上调用dispose来清除它并释放其GPU内存;或者用tf.tidy执行一个函数并清除所有创建的中间张量,释放它们的GPU内存(它不清除内部函数的返回值)。
await tf.nextFrame();
如果没有这个,模型训练会冻结你的浏览器。其实查遍资料,关于它的记录非常少,这大概是TensorFlow.js早起开发时的产物。
tf.tensor()和dataSync();
因为我们的数据存储在标准JavaScript数组中,所以我们需要用tf.tensor()将它们转换为TensorFlow的张量格式。反之,如果要从张量转回数组,用dataSync()。
小结
如果你下载了repo,而且准确无误地理解了上述内容,你会得到之前动图的演示结果,其中红色表示死亡,绿色表示幸存,亮绿色表示幸存几率更高。
本文探讨了一个完整的现代JavaScript项目,该项目使用TensorFlow.js可视化单层神经网络的演化预测,使用的数据集是泰坦尼克号,问题类型是二元分类。希望读者能根据这篇文章开始理解如何使用TensorFlow.js。
以上是关于海难幸存者:基于项目的TensorFlow.js简介的主要内容,如果未能解决你的问题,请参考以下文章