让 TensorFlow 估算器的推断提速百倍,我是怎么做到的?
Posted AI开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让 TensorFlow 估算器的推断提速百倍,我是怎么做到的?相关的知识,希望对你有一定的参考价值。
本文为雷锋字幕组编译的技术博客,原标题 Multithreaded predictions with TensorFlow Estimators,作者为 Archy de Berker 。
翻译 | 李晶 校对 | 陈涛 整理 | MY
TensorFlow 估算器提供了一套中阶 API 用于编写、训练与使用机器学习模型,尤其是深度学习模型。在这篇博文中,我们描述了如何通过使用异步执行来避免每次调用预测方法时都需重载模型,从而让 TF 估算器的推断提速超过百倍。
什么是 TF 估算器?
TensorFlow 估算器于 2017 年年中被提出,首次出现在 KDD 的白皮书中。其设计目标(如下面的两分钟视频中所总结的)值得称赞:将重复且容易出错的任务自动化,将最佳实践进行封装,保证了从训练到部署的顺利执行,所有这一切都以 scikit-learn 风格进行封装。
2017 年 Martin Wicke 在介绍估算器接口。视频来源:Google Developers, KDD 2017.
核心概念总结:用户在 model_fn 中指定其模型中的关键点,使用条件语句来区分在训练和推断中的不同操作。其中添加了一系列的 input_fns 来描述如何处理数据,可选择为训练、评估和推断分别指定各自的 input_fns 。
这些函数被 tf.estimator.Estimator 类调用并返回一个初始化的估算器。通过此估算器,可以调用 .train、.eval和 .predict 函数,而不用关心图和会话,这两个组件在基础的 TensorFlow 设置中比较难用。
估算器接口。图片来自 whitepaper (Cheng et al, 2017)
想获得完整的实践介绍,onfido blog 页面提供了一个很棒的教程,该教程还包括 TensorFlow Dataset 和 Experiment 类(已弃用)。你可以在开始操作之前,先尝试各种预先打包的估算器。
估算器面临的挑战
TensorFlow 是一个嵌合体:许多好的想法碰撞在一起,然而总体结构并不完善。在这样的背景下,估算器被提了出来,它需要与传统的基于图和会话的设计模式进行竞争,而后者更为开发者所熟悉。开发者对估算器的接受也受到其代码库的混乱集成所影响,代码库中充满了即将弃用的警告以及几个明显特征的遗漏(如 早期停止)。
因为其良好的默认检查点和 Tensorboard 集成,估算器在训练中使用起来很方便。然而,我们认为推断的接口有点不大直观。
估算器的一个核心设计准则是每次调用方法(.predict、.eval、.train)时都会重新对图初始化。这不是很合理,下面所引用的原始论文对此进行了总结:
为了确保封装,每次调用方法时,估算器都会重新创建一个新图,或许还会重载检查点。重建图的代价是很昂贵的,因而图可以被缓存起来,从而减少在循环中执行评估或预测的代价。但是,我们发现显式重建图还是很有用的,即使在明显牺牲性能的情况下。
「TensorFlow 估算器:在高阶机器学习框架下实现间接性和灵活性」,第 4 页,作者 Cheng 等人
也就是说:在每次调用方法【train、predict、eval】时,都会重新构建 TensorFlow 图,并重新加载检查点。要理解为什么会这样,以及这会引起什么问题,我们需要深入了解这些方法的约定。
TF 估算器方法的约定
.train、.eval、.predict 都会用到 tensorflow 称为 input_fn 的函数。调用此函数会返回一批数据。
通常由某种类型的生成器提供数据,这些生成器分批读取数据,执行预处理,并把它们传递给估算器。它们可以与 tf.Dataset 很好地结合在一起使用,tf.Dataset 能够使上述过程(载入, 处理, 传递)并行化运行。
这意味着对于估算器而言,训练循环是在内部进行的。这样做很有道理,正如白皮书中所强调的:
因为训练循环非常普遍,对其的最好实现应该是移除许多重复的用户代码。这在理论上很简单,我们可以避免由此产生的一些错误,不让用户为此而烦恼。因此,估算器实现并控制了训练循环。
「TensorFlow 估算器:在高阶机器学习框架下实现间接性和灵活性」,第 5 页,作者 Cheng 等人
这样的设计可以很好地满足需要预先对送入估算器的数据进行指定的情况。该使用场景常出现在训练和评估中。
但是实际使用该模型进行推断的效果如何呢?
原始的推断
假设我们想要将训练过的估算器用于另外一个任务,同样是使用 Python。我们通常希望在一个工作流程中组合使用多个模型,例如使用语言模型作为自动语音转录或光学字符识别中定向搜索的补充。
为了简化代码库,我们使用预打包的 Iris 数据集和估算器来模拟这种情况。假设我们有一种花卉推荐过程,它会不时地生成数据,并且每次都会从我们的估算器中读取预测值。
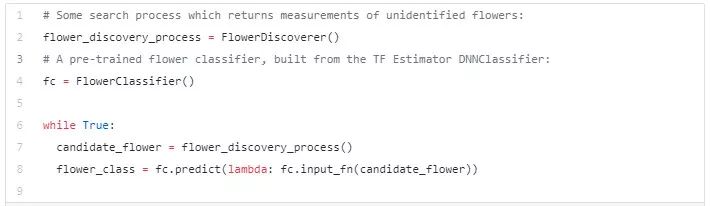
每次生成推荐的候选时,该搜索过程都会调用我们的估算器。如果采用估算器的原始的实现方式,那么会非常缓慢,因为每次调用 flower_estimator.predict 都会重载估算器。
FlowerClassifier 类是对估算器的简单包装,它可能看起来像:

完整的代码见 https://github.com/ElementAI/multithreaded-estimators/blob/1d0fba758d183193a822b8e44bda98a9443b456d/threaded_estimator/models.py#L12.
估算器的 .predict 方法已经被封装,所以调用 FlowerClassifier.predict() 会返回一个经过训练的估算器的预测值。
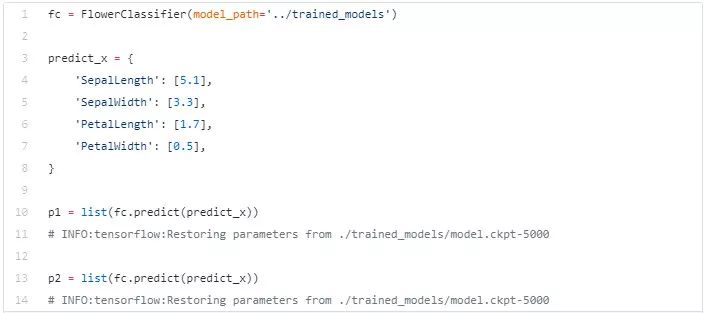
完整代码见 https://github.com/ElementAI/multithreaded-estimators/blob/master/threaded_estimator/tests/test_flower_estimator.py
但是现在每次我们想要分析一个新实例的时候,我们最终都会重新初始化整个模型!如果我们正在处理的任务代价很高,并且涉及到对模型的大量调用,那么效率就会严重下降。
缓存估算器来推断
我们需要找到一种方法:仅调用一次 predict 方法,同时保证还能向生成器传入新样本。但是因为我们希望执行其他中间计算,我们需要在单独的线程中配置该生成器。
这是一个生产者-消费者问题 的例子,在 Python 中可以使用队列轻松解决。我们将使用两个队列以一种线程安全的方式移动数据,一个队列用于保存输入,另外一个队列返回输出:

乍看起来不大直观,我们通过一个例子仔细研究一下到底发生了什么:
[主线程]: 用户调用 .predict 方法
[主线程]: 将一系列新的数据被添加到 input_queue
[辅助线程]:数据生成器将从 input_queue 中生成一个输入实例
[辅助线程]:该输入实例被传递给模型
[辅助线程]:模型把生成的输出实例添加到 output_queue
[主线程]: 调用封装好的模型,返回 output_queue 中的最新项
在这个实现方案中,Python queues 的行为至关重要:如果队列为空,则对 input_queue.get() 的调用会被先挂起,意味着生成器未被阻碍,只有数据被加入队列后,才会继续生成实例。
结果显示整个会话过程中仅载入了一次模型。在 2017 款 MacBook Pro(没有 GPU)的开发环境下运行,相比于原始实现,预测 100 个样本类别的速度提升了大约 150 倍。

使用线程可能有些繁琐,但是他们能把推断的速度显著加快。全部源代码请见 https://github.com/ElementAI/multithreaded-estimators/blob/1d0fba758d183193a822b8e44bda98a9443b456d/threaded_estimator/models.py#L171.
需要注意的是,我们没有对这个问题的其他解决方案进行完全探索。我们可以使用 generator.send() 方法将实例注入数据生成器,我们也可以尝试手动加载检查点以执行推理。我们发现这种特殊的方法非常有用,并且有很好的通用性,所以我们将其公之于众:如果你发现这个问题还有其他的解决方案,我们愿闻其详。
代码
你可以在 Github 中找到代码: https://github.com/ElementAI/multithreaded-estimators
我们提供了本文中讨论到的类,一些测试和 Dockerfile,以帮助你启动和运行环境。如果您觉得可以改进代码,随时欢迎提交 Pull 请求。如果你更喜欢使用装饰器,我们还有一个更复杂的版本,请参阅 decorator-refactor 分支。
感谢 Majid Laali 的原始想法和 Element AI 的整个 NLP 团队的编辑与建议。
想知道更多深度学习的技巧,订阅 Element AI Lab Blog。
原文链接: https://medium.com/element-ai-research-lab/multithreaded-predictions-with-tensorflow-estimators-eb041861da07
新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
将 Tensorflow 图序列化以及反序列化的巧妙方法
▼▼▼
以上是关于让 TensorFlow 估算器的推断提速百倍,我是怎么做到的?的主要内容,如果未能解决你的问题,请参考以下文章