快速使用 Tensorflow 读取 7 万数据集!
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速使用 Tensorflow 读取 7 万数据集!相关的知识,希望对你有一定的参考价值。

作者 | 郭俊麟
责编 | 胡巍巍

Brief 概述
这篇文章中,我们使用知名的图片数据库「THE MNIST DATABASE」作为我们的图片来源,它的数据内容是一共七万张28×28像素的手写数字图片。
并被分成六万张训练集与一万张测试集,其中训练集里面,又有五千张图片被用来作为验证使用,该数据库是公认图像处理的 "Hello World" 入门级别库,在此之前已经有数不清的研究,围绕着这个模型展开。
不过初次看到这个库之后,肯定是对其长相产生许多的疑问,我们从外观上既看不到图片本身,也看不到任何的索引线索,他就是四个压缩包分别名称如下图:
对数据库以此方法打包的理由需要从计算机对数据的运算过程和内存开始说起,人类直观的图像是眼睛接收的光信号,这些不同颜色的光用数据的方式储存起来后有两种主要的格式与其对应的格式内容:
.jpeg: height, width, channels;
.png : height, width, channels, alpha。
(注意: .png 储存格式的图片含有透明度的信息,在处理图片的时候可以舍弃。)
这些图像使用模块如opencv导入到 python 中后,是以列表的方式呈现排列的数据,并且每次令image = cv2.imread()这类方式把数据指向到一个 image物件时。
都是把数据存入内存的一个过程,在内存里面的数据好处是可以非常快速的调用并处理,直到这个状态我们才算布置完数据被丢进算法前的状态。
然而,图像数据导入内存的转换并不是那么的迅捷,首先必须先解析每个像素的坐标和颜色值,再把每一次读取到的图片数据值合起来后,放入缓存中。
这样的流程在移动和读取上都显然没有优势,因此我们需要把数据回归到其最基本的本质 「二进制」 上。

Binary Data 二进制数据
Reasons for using binary data,使用二进制数据的理由
如果我们手上有成批的图片数据,把它们传入算法中算结果的过程,就好比一个人爬上楼梯,坐上滑水道的入口,等待经历一段未知的短暂旅程。
滑水道有很多个通道,一次可以让假设五个人准备滑下,而这时候如果后面递补的人速度不够快,就会造成该入口一定时间的空缺,直接导致效率地下。
而这个比喻中的滑水道入口,代表的是深度学习 GPU 计算端口,准备下滑的人代表数据本身,而我们现在需要优化的,就是如何让 GPU 在还没处理完这一个数据之前,就已经为它准备好下一批预处理数据。
让 GPU 永远保持工作状态可以进一步提升整体运算的效率,方法之一就是让数据回归到 「二进制」 的本质。
二进制是数据在电脑硬盘储存状态的原貌,也是数据被处理时,最本质的状态,因此批量图片数据第一件要被处理的事情就是让他们以二进制的姿态被放入到内存中。
此举就好比排队玩滑水道的人们都要事前把鞋子手表眼睛脱掉,带着最需要的东西上去排队后,等轮到自己时,一屁股坐上去摆好姿势后就可以开始,没有其他的冗余动作拖慢时间。
而我选择的入门数据库 MNIST 已经很贴心的帮我们处理好预处理的部分,分为四个类别:
测试集图像数据: t10k-images-idx3-ubyte.gz;
测试集图像标签: t10k-labels-idx1-ubyte.gz;
训练集图像数据: train-images-idx3-ubyte.gz;
训练集图像标签: train-labels-idx1-ubyte.gz。
图像识别基本上都是属于机器学习中的监督学习门类,因此四个类别其中两个是对应图片集的标签集,都是使用二进制的方法保存档案。

The approach to load images 读取数据的方法
既然知道了数据库里面的结构是二进制数据,接下来就可以使用 python 里面的模块包解析数据,压缩文件为 .gz 因此对应到打开此文件类型的模块名为 gzip,代码如下:
import gzip, os
import numpy as np
location = input('The directory of MNIST dataset: ')
path = os.path.join(location, 'train-images-idx3-ubyte.gz')
try:
with gzip.open(path, 'rb') as fi:
data_i = np.frombuffer(fi.read(), dtype=np.int8, offset=16)
images_flat_all = data_i.reshape(-1, 784)
print(images_flat_all)
print('----- Separation -----')
print('Size of images_flat: ', len(images_flat_all))
except:
print("The file directory doesn't exist!")
### ----- Result is shown below ----- ###
The directory of MNIST dataset: /home/abc/MNIST_data
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
----- Separation -----
Size of images_flat: 60000
path_label = os.path.join(location, 'train-labels-idx1-ubyte.gz')
with gzip.open(path_label, 'rb') as fl:
data_l = np.frombuffer(fl.read(), dtype=np.int8, offset=8)
print(data_l)
print('----- Separation -----')
print('Size of images_labels: ', len(data_l), type(data_l[0]))
### ----- Result is shown below ----- ###
[5 0 4 ... 5 6 8]
----- Separation -----
Size of images_labels: 60000 <class 'numpy.int8'>
代码分为上下半段,上半段的代码用来提取MNIST DATASET中训练集的六万个图像样本,每一个样本都是由28×28尺寸的图片数据拉直成一个1×784 长度的向量形式记录下来。
下半段的代码则是提取对应训练集图像的标签,表示每一个图片所描绘的数字实际上是多少,同样也是六万个标签。(注:数据储存格式同理测试集与其他种类数据库。)

Explanation to the code 代码说明
基于我们对神经网络的了解,一张图片被用来放入神经网络解析的时候,需要把一个代表图像之二维矩阵的每条row拼成一个长条的一维向量,以此一向量作为一张图片的计量单位。
而MNIST进一步把六万张图片的一维向量拼起来,形成一个超级长的向量后,以二进制的方式储存在电脑中,因此如果要让人们可以图像化的看懂内部数据,就需要下面步骤还原数据:
使用 gzip.open 的 'rb' 读取二进制模式打开指定的压缩文件;
为了转换数据成为 np.array ,使用 .frombuffer;
原本的二进制数据格式使用 dtype 修改成人类读得懂的八进制格式;
MNIST 原始数据中直到第十六位数才开始描述图像信息,而数据标签则是第八位就开始描述信息,因此 offset 设置从第十六或是八位开始读取;
读出来的数据是一整条六万个向量拼起来的数据,因此需要重新拼接数据, .reshape(-1, 784) 中的 -1 像一个未知数一样,数据整形的过程中,只要 column = 784,那 row 是多少就是多少;
剥离出对应的标签时,最后还需要对其使用 one_hot() 数据的转换,让标签以例如 [0, 0, 0, 1, 0, 0, 0, 0, 0, 0] 的形式表示 "3" 的意思,目的是方便套入损失函数中运算,并寻找最优解。
把数据使用 numpy 数组描述好处是处理效率高,且此库和大多数数据处理的库都相容,不论是便利性和效率都是很大的优势。
后面两个链接 "numpy.frombuffer" "在NumPy中使用动态数组" 进一步深入的讲述了函数的用法。

Linear Model 线性模型
在理解数据集的数据格式和调用方法后,接下来就是把最简单的线性模型应用到数据集中,并经过多次的梯度下降算法迭代,找出我们为此模型定义的损失函数最小值。
回顾第一章的内容,一个线性函数的代码如下:
import numpy as np
import tensorflow as tf
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
weight = tf.Variable(tf.random_uniform(shape=[1], minval=-1.0, maxval=1.0))
bias = tf.Variable(tf.zeros(shape=[1]))
y = weight * x_data + bias
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
training = optimizer.minimize(loss)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for step in range(101):
sess.run(training)
if step % 10 == 0:
print('Round {}, weight: {}, bias: {}'
.format(step, sess.run(weight[0]), sess.run(bias[0])))
其中我们可以看到沿着x轴上对应的y有两组解,其中的y_data是我们预设的正解,而另外一个由wx + b计算产生的y则是我们要用来拟合正解的未知解,对应同一样东西x的两个不同的y轴值接下来需要被套入一个选定的损失函数中。
上面选中的是方差法,使用该方法算出损失函数后接着用reduce_mean()取平均,然后使用梯度下降算法把该值降到尽可能低的地步。
同理图像数据的归类问题,图片的每一个像素数据就好比一次上面计算的过程,如同x的角色,是正确标签和预测标签所共享的一个维度数据。
而y_data所对应的则是正确的标签,预测的标签则是经过一系列线性加法乘法与归一化运算处理后才得出来的结果。
图像数据有一点在计算上看起来不同上面示例的地方是: 每一个像素的计算被统一包含进了一个大的矩阵中,被作为整体运算的其中一个小单元平行处理,大大的加速整体运算的进程。
但是计算机处理物件的缓存是有限的,我们需要适量的把图像数据放入缓存中做平行处理,如果过载了则整个计算框架就会崩溃。

MNIST in Linear Model
梳理了一遍线性模型与MNIST数据集的组成元素后,接下来就是基于 Tensorflow搭建一个线性回归的手写数字识别算法,有以下几点需要重新声明:
batch size: 每一批次训练图片的数量需要调控以免内存不够;
loss function: 损失函数的原理是计算预测和实际答案之间的差距。
接下来就是制定训练步骤:
需要一个很简单方便的方法呼叫我们需要的 MNIST 数据,因此需要写一个类;
开始搭建 Tensorflow 数据流图,用节点设计一个 wx + b 的线性运算;
把运算结果和实际标签带入损失函数中求出损失值;
使用梯度下降法求出损失值的最小值;
迭代训练后,查看训练结果的准确率;
检查错误判断的图片被归类成了什么标签。
import gzip, os
import numpy as np
################ Step No.1 to well manage the dataset. ################
class MNIST:
# Images size is told in the official website 28*28 px.
image_size = 28
image_size_flat = image_size * image_size
# Let the validation set flexible when making an instance.
def __init__(self, val_ratio=0.1, data_dir='MNIST_data'):
self.val_ratio = val_ratio
self.data_dir = data_dir
# Load 4 files to individual lists with one string pixels.
img_train = self.load_flat_images('train-images-idx3-ubyte.gz')
lab_train = self.load_labels('train-labels-idx1-ubyte.gz')
img_test = self.load_flat_images('t10k-images-idx3-ubyte.gz')
lab_test = self.load_labels('t10k-labels-idx1-ubyte.gz')
# Determine the actual number of training / validation sets.
self.val_train_num = round(len(img_train) * self.val_ratio)
self.main_train_num = len(img_train) - self.val_train_num
# The normalized image pixels value can be more convenient when training.
# dtype=np.int64 would be more general when applying to Tensorflow.
self.img_train = img_train[0:self.main_train_num] / 255.0
self.lab_train = lab_train[0:self.main_train_num].astype(np.int)
self.img_train_val = img_train[self.main_train_num:] / 255.0
self.lab_train_val = lab_train[self.main_train_num:].astype(np.int)
# Also convert the format of testing set.
self.img_test = img_test / 255.0
self.lab_test = lab_test.astype(np.int)
# Extract the same codes from "load_flat_images" and "load_labels".
# This method won't be called during training procedure.
def load_binary_to_num(self, dataset_name, offset):
path = os.path.join(self.data_dir, dataset_name)
with gzip.open(path, 'rb') as binary_file:
# The datasets files are stored in 8 bites, mind the format.
data = np.frombuffer(binary_file.read(), np.uint8, offset=offset)
return data
# This method won't be called during training procedure.
def load_flat_images(self, dataset_name):
# Images offset position is 16 by default format
data = self.load_binary_to_num(dataset_name, offset=16)
images_flat_all = data.reshape(-1, self.image_size_flat)
return images_flat_all
# This method won't be called during training procedure.
def load_labels(self, dataset_name):
# Labels offset position is 8 by default format.
labels_all = self.load_binary_to_num(dataset_name, offset=8)
return labels_all
# This method would be called for training usage.
def one_hot(self, labels):
# Properly use numpy module to mimic the one hot effect.
class_num = np.max(self.lab_test) + 1
convert = np.eye(class_num, dtype=float)[labels]
return convert
#---------------------------------------------------------------------#
path = '/home/abc/MNIST_data'
data = MNIST(val_ratio=0.1, data_dir=path)
import tensorflow as tf
flat_size = data.image_size_flat
label_num = np.max(data.lab_test) + 1
################ Step No.2 to construct tensor graph. ################
x_train= tf.placeholder(dtype=tf.float32, shape=[None, flat_size])
t_label_oh = tf.placeholder(dtype=tf.float32, shape=[None, label_num])
t_label = tf.placeholder(dtype=tf.int64, shape=[None])
################ These are the values ################
# Initialize the beginning weights and biases by random_normal method.
weights = tf.Variable(tf.random_normal([flat_size, label_num],
mean=0.0, stddev=1.0,
dtype=tf.float32))
biases = tf.Variable(tf.random_normal([label_num], mean=0.0, stddev=1.0,
dtype=tf.float32))
########### that we wish to get by training ##########
logits = tf.matmul(x_train, weights) + biases # < Annotation No.1 >
# Shrink the distances between values into 0 to 1 by softmax formula.
p_label_soh = tf.nn.softmax(logits)
# Pick the position of largest value along y axis.
p_label = tf.argmax(p_label_soh, axis=1)
#---------------------------------------------------------------------#
####### Step No.3 to get a loss value by certain loss function. #######
# This softmax function can not accept input being "softmaxed" before.
CE = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=t_label_oh)
# Shrink all loss values in a matrix to only one averaged loss.
loss = tf.reduce_mean(CE)
#---------------------------------------------------------------------#
#### Step No.4 get a minimized loss value using gradient descent. ####
# Decrease this only averaged loss to a minimum value by using gradient descent.
optimizer = tf.train.AdamOptimizer(learning_rate=0.5).minimize(loss)
#---------------------------------------------------------------------#
# First return a boolean list values by tf.equal function
correct_predict = tf.equal(p_label, t_label)
# And cast them into 0 and 1 values so that its average value would be accuracy.
accuracy = tf.reduce_mean(tf.cast(correct_predict, dtype=tf.float32))
sess = tf.Session()
sess.run(tf.global_variables_initializer())
###### Step No.5 iterate the training set and check the accuracy. #####
# The trigger to train the linear model with a defined cycles.
def optimize(iteration, batch_size=32):
for i in range(iteration):
total = len(data.lab_train)
random = np.random.randint(0, total, size=batch_size)
# Randomly pick training images / labels with a defined batch size.
x_train_batch = data.img_train[random]
t_label_batch_oh = data.one_hot(data.lab_train[random])
batch_dict = {
x_train: x_train_batch,
t_label_oh: t_label_batch_oh
}
sess.run(optimizer, feed_dict=batch_dict)
# The trigger to check the current accuracy value
def Accuracy():
# Use the totally separate dataset to test the trained model
test_dict = {
x_train: data.img_test,
t_label_oh: data.one_hot(data.lab_test),
t_label: data.lab_test
}
Acc = sess.run(accuracy, feed_dict=test_dict)
print('Accuracy on Test Set: {0:.2%}'.format(Acc))
#---------------------------------------------------------------------#
### Step No.6 plot wrong predicted pictures with its predicted label.##
import matplotlib.pyplot as plt
# We can decide how many wrong predicted images are going to be shown up.
# We can focus on the specific wrong predicted labels
def wrong_predicted_images(pic_num=[3, 4], label_number=None):
test_dict = {
x_train: data.img_test,
t_label_oh: data.one_hot(data.lab_test),
t_label: data.lab_test
}
correct_pred, p_lab = sess.run([correct_predict, p_label],
feed_dict=test_dict)
# To reverse the boolean value in order to pick up wrong labels
wrong_pred = (correct_pred == False)
# Pick up the wrong doing elements from the corresponding places
wrong_img_test = data.img_test[wrong_pred]
wrong_t_label = data.lab_test[wrong_pred]
wrong_p_label = p_lab[wrong_pred]
fig, axes = plt.subplots(pic_num[0], pic_num[1])
fig.subplots_adjust(hspace=0.3, wspace=0.3)
edge = data.image_size
for ax in axes.flat:
# If we were not interested in certain label number,
# pick up the wrong predicted images randomly.
if label_number is None:
i = np.random.randint(0, len(wrong_t_label),
size=None, dtype=np.int)
pic = wrong_img_test[i].reshape(edge, edge)
ax.imshow(pic, cmap='binary')
xlabel = "True: {0}, Pred: {1}".format(wrong_t_label[i],
wrong_p_label[i])
# If we are interested in certain label number,
# pick up the specific wrong images number randomly.
else:
# Mind that np.where return a "tuple" that should be indexing.
specific_idx = np.where(wrong_t_label==label_number)[0]
i = np.random.randint(0, len(specific_idx),
size=None, dtype=np.int)
pic = wrong_img_test[specific_idx[i]].reshape(edge, edge)
ax.imshow(pic, cmap='binary')
xlabel = "True: {0}, Pred: {1}".format(wrong_t_label[specific_idx[i]],
wrong_p_label[specific_idx[i]])
ax.set_xlabel(xlabel)
# Pictures don't need any ticks, so we remove them in both dimensions
ax.set_xticks([])
ax.set_yticks([])
plt.show()
#---------------------------------------------------------------------#
Accuracy() # Accuracy before doing anything
optimize(10); Accuracy() # Iterate 10 times
optimize(1000); Accuracy() # Iterate 10 + 1000 times
optimize(10000); Accuracy() # Iterate 10 + 1000 + 10000 times
### ----- Results are shown below ----- ###
Accuracy on Test Set: 11.51%
Accuracy on Test Set: 68.37%
Accuracy on Test Set: 86.38%
Accuracy on Test Set: 89.34%
Annotation No.1 tf.matmul(x_train, weights)
这个环节是在了解整个神经网络训练原理后,最重要的一个子标题,计算的矩阵模型中必须兼顾 random_batch 提取随意多的数据集,同时符合矩阵乘法的运算原理,如下图描述:
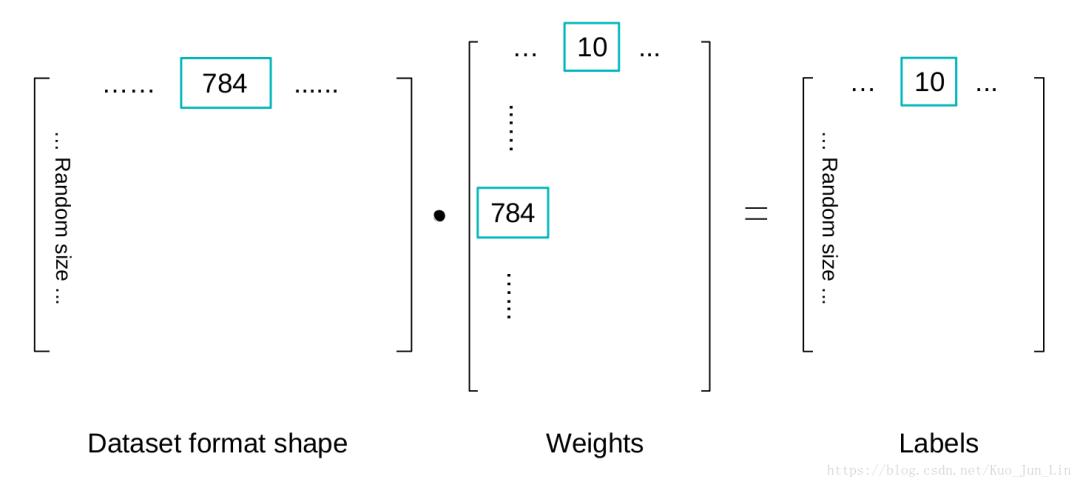
矩阵位置前后顺序很重要,由于数据集本身经过我们处理后,就是左边矩阵的格式,在期望输出为右边矩阵的情况下,只能是 x·w 的顺序,以 x 的随机列数来决定后面预测的标签列数, w 则决定有几个归类标签。
Reason of using one_hot()
数据集经过一番线性运算后得出的结果如上图所见,只能是 size=[None, 10] 的大小,但是数据集给的标签答案是数字本身,因此我们需要一个手段把数字转换成 10 个元素组成的向量,而第一选择方法就是 one_hot() ,同时使用 one_hot 的结果来计算损失函数。

Finally
呼叫上面定义的函数,如下代码:
wrong_predicted_images(pic_num=[3, 3], label_number=5)
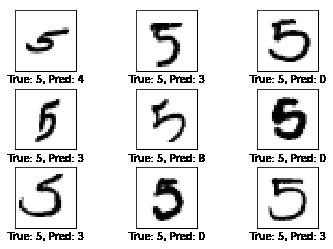
其中可以自行选择想要一次陈列几张图片,每次陈列的图片都是随机选择,并同时可以选择想查看的标签类别,如上面一行函数设定为 5 ,则就只显示标签 5 的错误判断图片和误判结果。最后等整个框架计算完毕后,需要执行下面代码结束 tf.Session ,释放内存:
sess.close()
CSDN 原文:
https://blog.csdn.net/Kuo_Jun_Lin/article/details/82106711?utm_source=copy
推荐阅读:
以上是关于快速使用 Tensorflow 读取 7 万数据集!的主要内容,如果未能解决你的问题,请参考以下文章
如何使用 TFRecord 数据集使 TensorFlow + Keras 快速运行?