移动端 GPU 推理性能提升 2 倍!TensorFlow 推出新 OpenCL 后端
Posted 我爱计算机视觉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了移动端 GPU 推理性能提升 2 倍!TensorFlow 推出新 OpenCL 后端相关的知识,希望对你有一定的参考价值。
文 / 软件工程师 Juhyun Lee 和 Raman Sarokin
TensorFlow Lite (TFLite) GPU 团队在不断改进现有基于 OpenGL 的移动 GPU 推理引擎,同时我们也在不断研究其他技术。在我们所开展的实验中,有一个实验相当成功。在此,我们很高兴地为 android 推出基于 OpenCL 的移动 GPU 推理引擎,与现有的 OpenGL 后端相比,其在适当大小的神经网络(为 GPU 提供足够的工作负载)的推理速度可提升高 2 倍。

图 1. OpenCL 后端可为 Duo 的 AR 特效提供技术支持
对 OpenGL 后端的改进
一直以来,OpenGL 都是为渲染矢量图形而打造 API。我们已在 OpenGL ES 3.1 中添加计算着色器 (Compute shaders),但限于其向后兼容的 API 设计限制,无法发挥出 GPU 的全部潜力。另一方面,OpenCL 本就是为在不同加速器上开展计算工作而设计的,因而与移动 GPU 推理领域尤为相关。因此,我们研究出了基于 OpenCL 的推理引擎,并运用其中的许多功能来优化我们的移动 GPU 推理引擎。
OpenGL
https://www.opengl.org/
OpenCL
https://www.khronos.org/opencl/
性能分析:与优化 OpenGL 相比,优化 OpenCL 后端更容易实现,因为 OpenCL 可为我们提供出色的分析功能,且 Adreno 能为其提供良好支持。通过使用这些分析 API,我们能够非常精确地衡量出每个内核调度的性能。
Adreno
https://developer.qualcomm.com/software/adreno-gpu-sdk/gpu
经过优化的工作组大小:我们发现,Qualcomm Adreno GPU 上的 TFLite GPU 性能易受工作组大小影响;采用合适的工作组大小可以提高性能,而选择不当的工作组大小则会相应地降低性能。遗憾的是,对于具有复杂显存访问模式的复杂内核来说,采用合适的工作组大小却并非易事。借助 OpenCL 中的性能分析功能(如上所述),我们可实现针对工作组大小的优化工具,从而将平均速度提升了50%。
原生 16 位精度浮点 (FP16):OpenCL 本身支持 FP16,并需要加速器指定可用的数据类型。官方规范中规定,一些较早推出的 GPU(例如 2012 年推出的 Adreno 305)也可全功能运行 OpenCL。另一方面,OpenGL 比较依赖提示,而供应商有可能在实施过程中选择忽略这些提示,导致无法保证发挥其应有的性能水平。
常量显存 (Constant Memory):我们已在 OpenCL 中引入常量显存的概念。Qualcomm 在其 GPU 中加入了物理显存,物理显存的一些特性使其非常适合与 OpenCL 的常量显存一起使用。并在某些特定情况下有非常好的效果,例如在神经网络首尾较窄的层上运行时。通过与该物理常量显存和原生 FP16 支持(如上所述)的协同作用,Adreno 上的 OpenCL 可发挥出远超 OpenGL 的性能。
性能评估
我们会在下方展示 TFLite 在 CPU(大核单线程)、使用现有 OpenGL 后端的 GPU 和使用新 OpenCL 后端的 GPU 上的性能水平。图 2 和图 3 分别说明推理引擎在搭载 OpenCL 的所选 Android 设备上,使用数个广为人知的神经网络(如 MNASNet 1.3 和 SSD MobileNet v3(大))时所发挥出的性能水平。每组的 3 个柱形显示了 TFLite 后端在设备上的相对加速效果。我们新 OpenCL 后端的速度约为 OpenGL 后端的两倍,其在 Adreno 设备(标注 SD)上的表现尤为出色,这是因为我们已使用 Adreno 性能分析器(如上所述)调整了工作组的大小。此外,图 2 和图 3 之前的差异表明,OpenCL 在较大网络上的表现更为出色。
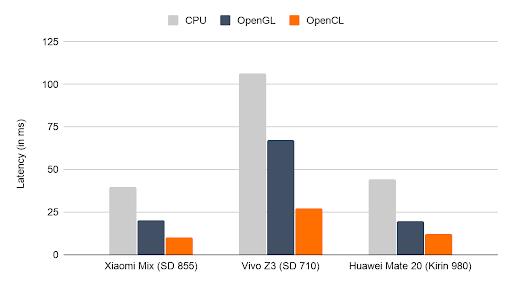
图 2. 在搭载 OpenCL 的特定 Android 设备上,推理引擎在 MNASNet 1.3 中的延迟时间
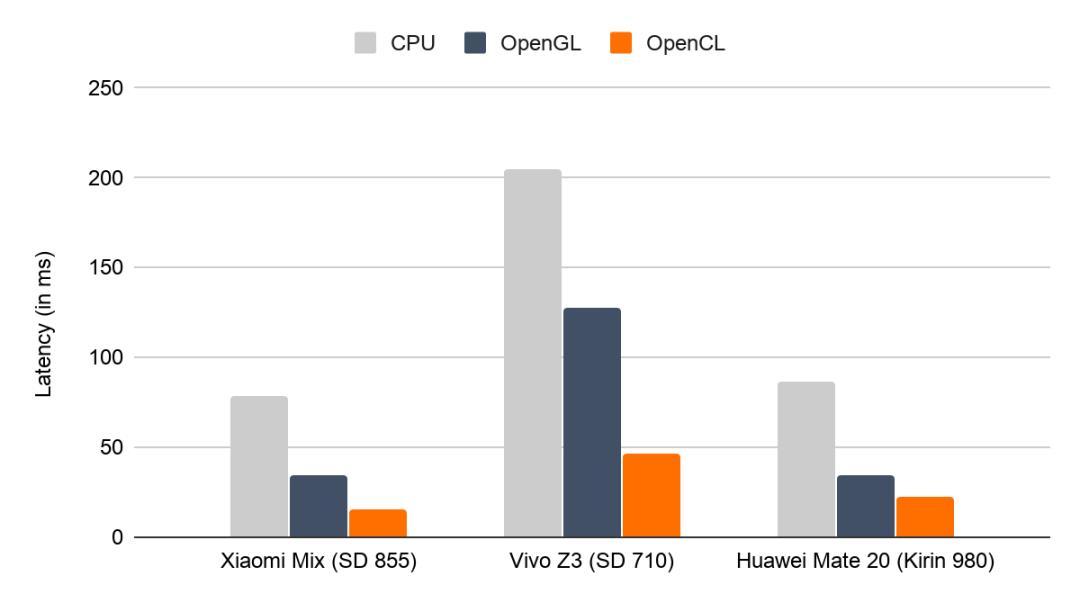
图 3. 在搭载 OpenCL 的特定 Android 设备上,SSD MobileNet v3 (large) 的推理延迟时间
借助 GPU Delegate,提供无缝集成体验
使用 OpenCL 推理引擎的主要障碍在于 Android 发行版中不包含 OpenCL。尽管大多数 Android 供应商会将 OpenCL 纳入系统库中,但一些用户可有能仍无法使用 OpenCL。针对这些设备,我们需要回退到 Android 设备上运行的 OpenGL 后端。
为方便开发者,我们对 TFLite GPU Delegate 添加了一些修改。首先,我们会在运行时检查 OpenCL 的可用性。如果 OpenCL 可用,我们会使用新的 OpenCL 后端,因为其速度远高于 OpenGL 后端;如果 OpenCL 不可用或无法加载,我们将会回退到现有的 OpenGL 后端。事实上,OpenCL 后端自 2019 年年中以来便一直存在于 TensorFlow 代码库中,并已通过 TFLite GPU Delegate v2 版与代码库无缝集成,因此,您可能已在使用代理的回退机制时,用到过这个后端。
致谢
感谢 Andrei Kulik、Matthias Grundman、Jared Duke、Sarah Sirajuddin,也特别感谢 Sachin Joglekar 对本博文的贡献。

备注:框架

TF&PyTorch学习交流群
深度学习框架、TensorFlow、PyTorch等技术,若已为CV君其他账号好友请直接私信。
微博知乎:@我爱计算机视觉
投稿:amos@52cv.net
网站:www.52cv.net
在看,让更多人看到
以上是关于移动端 GPU 推理性能提升 2 倍!TensorFlow 推出新 OpenCL 后端的主要内容,如果未能解决你的问题,请参考以下文章