简单验证码识别入门
Posted 黑客工具箱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单验证码识别入门相关的知识,希望对你有一定的参考价值。
表哥已经换域名的,现在的域名是 www.92aq.com,比原来好记,各位表弟只要记住 “就爱安全”即可
一、简单入门
首先从最简单的验证码入手:
这种验证码基本没有干扰,也比较常见,只有数字。识别这种验证码的步骤主要是”去噪->切割->异或”,在识别之前得有做好的字模。
0x01 去噪
这种最简单的干扰就用最简单的去噪:二值去噪
设置一个阈值,颜色比阈值浅就算噪点设置为”255,255,255″(rgb值白色),比阈值深就保留为”0,0,0“(rbg值黑色)。
代码:
def binary(f):
img = Image.open(f)
pixdata = img.load()
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][0] < 90:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][1] < 136:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][2] > 0:
pixdata[x, y] = (255, 255, 255, 255)
return img
0x02 字模
这个就得自己切割了,选取出现次数较多的作为字模。
这是我切图的辅助代码:
#!/usr/bin python
#coding: utf-8
import os ,Image
j = 1
dir="./data/"
for f in os.listdir(dir):
if f.endswith(".gif"):
img = Image.open(dir+f)
for i in range(4):
x = 7 + i*13
y = 0
img.crop((x, y, x+9, y+20)).save("./font/%d.bmp" % j, 'bmp')
print "j=",j
j += 1
0x03 切割
把一个图片切割成4个小块,与字模进行异或对比:
代码:
def cut(img):
font = []
for i in range(4):
x=7+i*13
y=3
font.append(img.crop((x,y,x+9,y+13)))
return font
0x04 异或
对比图像相似度时,有很多种方法,其中异或是最简单的。不过在对付这种简单验证码时,已经足够了。
代码:
def compare(img, im):
num = 0
for x in range(9):
for y in range(13):
if img[x, y] != im[x, y]:
num += 1
return num
然后加上判断语句,从返回的num里面选择最小的,也就是不同程度最小的字模,即可认定该数字等于字模标识的数字。最后完整的识别文件:
res.zip
该脚本会识别data1目录下所有图片(使用了PIL库)。
二、进阶
在dzscan第二次改版的时候,就想到了爆破UCenter,只是UCenter存在验证码,所以就想做个识别的,这次分享出来供大家参考。
0x01 去噪
验证码识别去噪一般都是最大的问题,如图:

如果用二值去噪,右边的那些也会被认为是普通的字符,导致无法识别。所以我选择了rgb值去噪。主要方法为:
先转换成黑白图,即rgb 转化为 L模式,只有256个值,从全黑到全白。然后对每个相同像素的个数进行统计,像素点个数最多的四个L值必然是四个字母,效果如图:
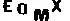
不过也有这样的:
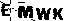
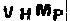
明显是去噪残了,所以就要第二次去噪,通过判断周围的像素点数量去除小的噪点,也就是看某个像素点前后左右有多少像素点,如果像素周围的像素点之和小于等于2,即认为是孤立像素点,去掉,效果如图:
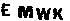
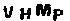
基本上可以进行下一步了。
0x02 匹配算法
由于有像素损失,这种图片不能确保切割下来的长宽高和形状是一样的,所以简单地异或是肯定不可以的
这次我选择的是另外一种匹配算法。
首先对图片进行切割,因为第二步已经基本没有了单独的噪点了,所以直接从左向右搜索,遇到又黑色的一列就作为切割的起始,遇到全是白色的列就作为切割的结束,对其切割,将切割下来的图进行识别,重复四次,即可切出4个字母的大概轮廓。
对每个字符来说,确定位置的是字符的左和右,而字符是悬浮不定的,如上图,每个字符的上下是不可知的。
但是对于每个字符来说,每一列最上面的像素点到最下面的像素点的长度都基本相同
根据这个原理可以提取出来一系列特征值,为了更加精确,个别字符有两个特征值(图片中的字符本来就不完全相同,加上去噪的影响,所以有些图片特征不同但是同一个字符)就用大小写来分别代替,不过有个缺点,那就是”O,C,Q”分不清,这种目前未解决,解决方法其实也不难,再加个每一列像素点个数之和的比较。
将特征提取出来后即可与预置的特征比较,相差最少的即可认为相同。
由于各种影响,比如“O,C,Q”等特征不明确,所以最终识别率在百分之30左右,如果再加个判断应该能达到百分之60以上。
此处随机选取了15个验证码进行识别,5个是对的。
以上是关于简单验证码识别入门的主要内容,如果未能解决你的问题,请参考以下文章
爬虫遇到头疼的验证码?Python实战讲解弹窗处理和验证码识别