验证码识别ctc_loss
Posted 深度学习从入门到放弃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了验证码识别ctc_loss相关的知识,希望对你有一定的参考价值。
前情提要:在前面一章中,我们学习了如何使用 多输出模型对验证码进行分类。但是实际预测中,我们发现效果并没有很好。所有接下来,我们要结束一个更好的方法进行验证码识别:CRNN+CTC
1
CRNN+CTC
CRNN,顾名思义就是CNN+RNN,使用CNN提取图像特征,使用RNN提取序列特征,我们可以简单地理解为如下图片。
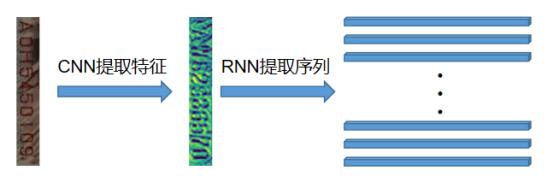
而CTC是一个神奇的loss,它可以在只知道序列的顺序,不知道具体位置的情况下,让模型收敛。在这方面百度似乎做得很不错,利用它来识别音频信号。
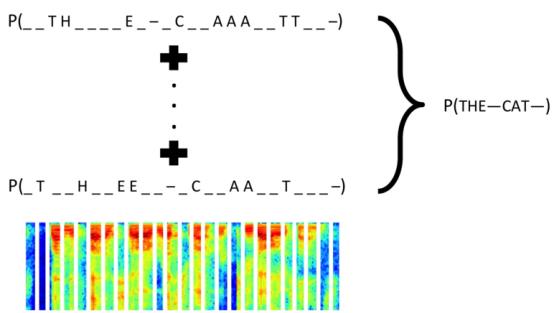
那么在 Keras 里面,CTC Loss 已经内置了,我们直接定义这样一个函数,即可实现 CTC Loss,由于我们使用的是循环神经网络,所以默认丢掉前面两个输出,因为它们通常无意义,且会影响模型的输出。(不丢弃差别也不大)


2
模型搭建
那么这样一个模型,我们应该 怎么搭建呢?让我们一起在代码中体现吧!首先是CRNN+CTC网络的搭建。代码如下,比较长,但是值得认真去阅读。首先是ctc_lambda_func这个需要的参数我们前面已经提到了。接着是CteateModel 函数,该函数输入图片的尺寸和要搭建的基础模型命名。如果你有过迁移学习的实践,你一定知道我在干什么。就是把tensorflow中已经预训练好的模型,拿出来,选择某一层的输出 作为我们RNN层的输入。这里我提供了多个模型如 DenseNet121,MobileNet等。
from tensorflow.keras.applications import DenseNet121,DenseNet169, Xception,MobileNetimport tensorflow.keras as kimport tensorflow.keras.backend as Kfrom utils import load_data,ctc_gan_dataimport numpy as npimport tensorflow as tfdef ctc_lambda_func(args):y_pred, labels, input_length, label_length = argsy_pred = y_pred[:, :, :]return K.ctc_batch_cost(labels, y_pred, input_length, label_length)def CreateModel(input,cnnName):if cnnName=='dn121':base_model= DenseNet121(include_top=False,input_tensor=input)x=base_model.get_layer('pool4_conv').outputif cnnName=='dn169':base_model = DenseNet169(include_top=False, input_tensor=input)x = base_model.get_layer('pool4_conv').outputif cnnName=='Xception':base_model = Xception(include_top=False, input_tensor=input)x = base_model.get_layer('block13_sepconv2_bn').outputif cnnName=='MobileNet':base_model=MobileNet(include_top=False,input_tensor=input)x=base_model.get_layer('conv_pw_11_relu').output
接着,我们把前面CNN的提取的特征进行维度的转换,然后输入RNN层。记住这里的rnn_length,这是时间序列的长度,也就是说,会被切分成rnn_length 块,然后分别预测这些块中会出现标签。接着是LSTM层,当然你也可以换成GRU层。这个层的整体结构是这样的。(懒得重新跑,用以前跑过的其他项目的结构)
conv_shape=x.get_shape().as_list()rnn_length=conv_shape[2]l2_rate = 1e-5 #l2正则化x = k.layers.Reshape(target_shape=(conv_shape[2],* conv_shape[3]))(x)x = k.layers.Dropout(0.6)(x)x = k.layers.Dense(256, kernel_regularizer=k.regularizers.l2(l2_rate),bias_regularizer=k.regularizers.l2(l2_rate))(x)x = k.layers.\BatchNormalization(gamma_regularizer=k.regularizers.l2(l2_rate),beta_regularizer=k.regularizers.l2(l2_rate))(x)x = k.layers.Activation('relu')(x)# 使用GRU提取序列信息gru_1a = k.layers.LSTM(256, return_sequences=True, name='gru_1a')(x)gru_1b = k.layers.LSTM(256, return_sequences=True,go_backwards=True, name='gru_1b')(x)gru1_add = k.layers.add([gru_1a, gru_1b])gru_2a = k.layers.LSTM(256, return_sequences=True, name='gru_2a')(gru1_add)gru_2b = k.layers.LSTM(256, return_sequences=True,go_backwards=True, name='gru_2b')(gru1_add)x = k.layers.concatenate([gru_2a, gru_2b])x = k.layers.Dropout(0.6)(x)# 0~9+A~Z+1 这里37=36+1 多出来的1 是因为我们使用RNN 要加一个空白符的概念x = k.layers.Dense(37, activation='softmax',kernel_regularizer=k.regularizers.l2(l2_rate),bias_regularizer=k.regularizers.l2(l2_rate))(x)base_model=k.models.Model(inputs=input,outputs=x)
接着是尾部,由上面的图你可以看见,它是一个多输入的模型,所以我们需要定义其他的3个输入。记住这些输入要和ctc中的输入一致。分别为图片,标签,时间序列长度,标签长度。这样一个CRNN+CTC的模型就完成了。
labels = k.layers.Input(name='the_labels', shape=[4], dtype='float32')input_length = k.layers.Input(name='input_length', shape=[1], dtype='int64')label_length = k.layers.Input(name='label_length', shape=[1], dtype='int64')loss_out = k.layers.Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([])model = k.models.Model(inputs=(input, labels, input_length, label_length),outputs=loss_out)k.utils.plot_model(model,'dn121.png',show_shapes=True)return base_model,model,rnn_length
3
数据生成
然后我们需要改写一下数据的生成函数,比较简单,直接给出代码:
str='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'def ctc_gan_data(image_paths,labels,rnn_le,batch_size):while True:image_=[]label_=[]for i in range(len(image_paths)):label = labels[i]# print(label)label_.append(label)image=cv2.imread(image_paths[i])image=cv2.resize(image,(160,40))# cv2.imshow('s',image)# cv2.waitKey(0)image_.append(image)if len(image_)==batch_size:image_=np.array(image_).reshape(-1,40,160,3)/255.label_=np.array(label_)yield [image_,label_,np.array([rnn_le]*batch_size),np.array([4]*batch_size)],np.ones(batch_size)image_=[]label_=[]
4
训练
然后就可以进行训练了,代码直接给出。
bacth_size=16train_path=r'E:\DataSets\Digitalverificationcode\train_image'x_train,y_train,x_test,y_test=load_data(train_path)input_tensor=k.Input((40,160,3))base_model,model,rnn_le=CreateModel(input_tensor,'MobileNet')adam = tf.keras.optimizers.Adam(lr=3e-4)model.load_weights('logs/MobileNet_ep003-loss1.209-val_loss1.051.h5')model.compile(loss={'ctc':lambda y_true,y_pred:y_pred},optimizer=adam)#检测val_loss是否下降 如果没有下降则减低学习率reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=10, min_lr=1e-6, verbose=1)# 保持最优模型model_checkpoint=tf.keras.callbacks.ModelCheckpoint('logs/MobileNet_ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',monitor='val_loss',save_weights_only=True,period=1,save_best_only=True)# val_loss 停止下降 终止训练earlystop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=15, verbose=1, mode='auto')history = model.fit_generator(ctc_gan_data(x_train,y_train,rnn_le,batch_size=bacth_size),steps_per_epoch=len(x_train)//bacth_size+1,validation_data=ctc_gan_data(x_test,y_test,rnn_le,batch_size=bacth_size),validation_steps=len(x_test)//bacth_size+1,epochs=50,callbacks=[model_checkpoint,reduce_lr])model.save('MobileNet.h5')
5
回调函数可视化测试过程
但是我们发现一个问题,我们并不能在训练的适合,获得实际的预测情况,这时候我们可以自定义一个回调函数,用来在每次模型开始训练前可视化预测结果。代码如下,然后在fit中添加对应的对象即可。
# 测试 准确率def evaluate(x_test,y_test,bacth_size,steps):batch_acc = 0generator = ctc_gan_data(x_test,y_test,rnn_le,batch_size=bacth_size)for i in range(steps):[X_test, y_test, _, _], _ = next(generator)# print(X_test.shape,y_test.shape)y_pred = base_model.predict(X_test)shape = y_pred[:, :, :].shapectc_decode = tf.keras.backend.ctc_decode(y_pred[:, :, :],input_length=np.ones(shape[0]) * shape[1])[0][0]out = tf.keras.backend.get_value(ctc_decode)print(y_test[0], '=>', out[0])if out.shape[1] == 4:batch_acc += sum((y_test == out).all(axis=1))base_model.save('mobile_.h5')return batch_acc / (bacth_size * steps)class Evaluator(tf.keras.callbacks.Callback):def __init__(self):self.accs = []def on_epoch_begin(self, epoch, logs=None):acc = evaluate(x_test,y_test,bacth_size=bacth_size,steps=30) * 100self.accs.append(acc)print('\n acc: %f%%' % acc)evaluator = Evaluator()
history = model.fit_generator(ctc_gan_data(x_train,y_train,rnn_le,batch_size=bacth_size),steps_per_epoch=len(x_train)//bacth_size+1,validation_data=ctc_gan_data(x_test,y_test,rnn_le,batch_size=bacth_size),validation_steps=len(x_test)//bacth_size+1,epochs=50,callbacks=[model_checkpoint,evaluator,reduce_lr])
现在你就可以一边训练,一边查看测试准确率了,是不是很方便呢?训练过程截图如下:
以上是关于验证码识别ctc_loss的主要内容,如果未能解决你的问题,请参考以下文章