验证码识别多输出模型
Posted 深度学习从入门到放弃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了验证码识别多输出模型相关的知识,希望对你有一定的参考价值。
前面我们使用了Python-tesseract进行验证码的识别。不过我们发现一个问题,稍微复杂一点的验证码它就识别不出来了。
本章我们就来实现一个自己的验证码识别程序。我们使用的是CNN多输出的方式来进行验证码的识别。CNN多输出在很多场景都有用到如:ACGAN,Yolo等。
数据生成 captcha
首先是数据集,我们使用了captcha来生成验证码图片。captcha 是用 python 写的生成验证码的库,它支持图片验证码和语音验证码,我们使用的是它生成图片验证码的功能。由于比较简单,这里就直接给代码。
from captcha.image import ImageCaptchaimport randomimport stringimport os# 修改为对应的地址 (先创建好)train_path=r'E:\DataSets\Digitalverificationcode\train_image'val_path=r'E:\DataSets\Digitalverificationcode\val_image'# 生成图片def gen_image(path,num):# 字符 A~Z + 0~9characters=string.digits+string.ascii_uppercase# print(characters)width,height,n_len,n_class=160,40,4,len(characters)# 生成160*40的图片generator=ImageCaptcha(width=width,height=height)for i in range(num):random_str=''.join([random.choice(characters) for j in range(4)])# 随机生成图片img=generator.generate_image(random_str)# 防止重名报错停止运行try:img.save(os.path.join(path,'%s.jpg'%random_str))except:continueprint('done')# 数据生成gen_image(train_path,20000)gen_image(val_path,1000)
运行上述代码,我们就可以在对应的文件夹中看见如下的图片,并且图片内的验证码就是图片的命名,这会方便我们后面进行读取。当然写成CSV的格式也是可以的。

网络搭建 CNN
接着,我们搭建网络结果,这次搭建的网络和我们之前搭建的网络有所不同,之前搭建的单输入单输出的网络结构,在这里我们要搭建的是单输入多输出的网络结构,因为每张图片其实对应的是4个标签。对应的网络结构图如下:
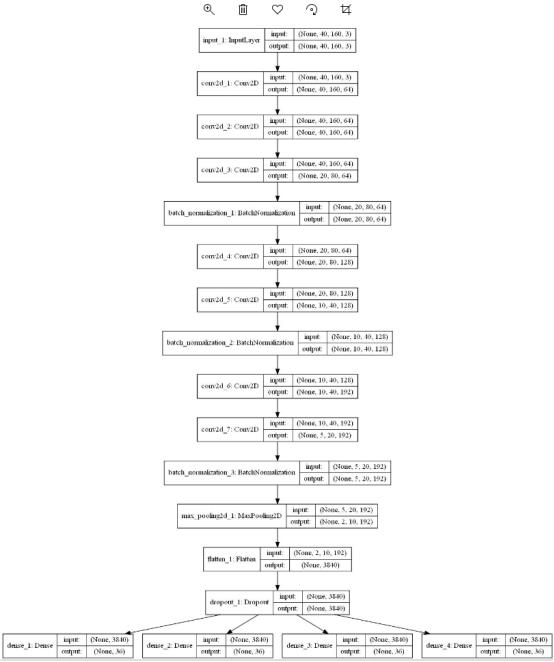
模型搭建这块,如果你已经学会如何搭建VGG,ResNet等网络。我想对你来说是比较简单的。代码如下:
import tensorflow.keras as kerasimport osimport randomimport cv2import numpy as npdef create_model(input):x=keras.layers.Conv2D(64,kernel_size=(3,3),padding='same',activation='relu')(input)for i in range(3):x=keras.layers.Conv2D(64*(i+1),kernel_size=(3,3),padding='same',activation='relu')(x)x=keras.layers.Conv2D(64*(i+1),kernel_size=(3,3),strides=2,padding='same',activation='relu')(x)x=keras.layers.BatchNormalization()(x)x=keras.layers.MaxPool2D()(x)x=keras.layers.Flatten()(x)x=keras.layers.Dropout(0.5)(x)x=[keras.layers.Dense(36,activation='softmax')(x) for i in range(4)]model=keras.models.Model(inputs=input,outputs=x)return model
数据加载 generator
接着是加载数据,我们需要读取图片的路径,然后把标签换成对应的字符索引。并把数据封装成生成器的格式,避免内存溢出。最后记得将标签独热编码。
# 读取数据集地址和标签信息def load_data(path,data_split=0.9):print('loading_data...')str='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'image_paths=[os.path.join(path,p) for p in os.listdir(path)]# 将 字符转换为 索引 8AFS ==>[8,10,15,28]label_=[label.split('.')[0] for label in os.listdir(path)]label=[]for i in label_:lab=[]for j in i:lab.append(str.index(j))label.append(lab)# 打乱数据集seed_=random.randint(1,100)random.seed(seed_)random.shuffle(image_paths)random.seed(seed_)random.shuffle(label)# 分割数据集num=int(len(image_paths)*data_split)x_train=image_paths[:num]y_train=label[:num]x_test=image_paths[num:]y_test=label[num:]print('done')return x_train,y_train,x_test,y_test# 数据生成器def gen_data(image_paths,labels,batch_size):while True:data=[]label=[]for index,image_path in enumerate(image_paths):# print(image_path) 图片处理image=cv2.imread(image_path)image=cv2.resize(image,(160,40))data.append(image)label.append(labels[index])# 当数组中存在一个批次的数据之后返回if len(data)==batch_size:data=np.array(data)data=data.reshape(-1,40,160,3)/255.label=np.array(label)# y 对应4个输出,一个batch的数据 以及36分类y=np.zeros([4,batch_size,36])for i in range(batch_size):for idx,row_i in enumerate(label[i]):=1y=[yy for yy in y]yield data,ydata=[]label=[]
使用如下的方式查看生成器生成的数据是否图片和标签一一对应,如果没有问题,就可以编写训练代码了。
训练和测试 train&test
训练代码如下,由于前面我们以及把需要用到的东西写好了,这里我们只需要简单的调用一下就可以进行训练了。
if __name__ == '__main__':batch_size=32train_path=r'E:\DataSets\Digitalverificationcode\train_image'x_train,y_train,x_test,y_test=load_data(train_path)input=keras.layers.Input((40,160,3))model=create_model(input)model.compile(loss='categorical_crossentropy',optimizer=keras.optimizers.Adam(lr=3e-4),metrics=['acc'])model.fit_generator(gen_data(x_train,y_train,batch_size),steps_per_epoch=len(x_train)//batch_size,validation_data=gen_data(x_test,y_test,batch_size),validation_steps=len(x_test)//batch_size,epochs=5)model.save('yzm_.h5')
训练结束之后,我们就可以使用测试集来进行测试了。注意在图片处理的时候要和训练时一致。
import tensorflow.keras as kerasimport osimport cv2import numpy as npval_path=r'E:\DataSets\Digitalverificationcode\val_image'str='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'model=keras.models.load_model('yzm_.h5')image_paths=[os.path.join(val_path,path) for path in os.listdir(val_path)]num=0for index ,image_path in enumerate(image_paths):image=cv2.imread(image_path)img=image.copy()image=cv2.resize(image,(160,40))image=image.reshape(-1,40,160,3)/255.p=model.predict(image)y=np.argmax(np.array(p),axis=2)[:,0]char=''.join([str[x] for x in y])cv2.putText(img,char,(5,15),cv2.FONT_HERSHEY_COMPLEX,.5,(255,0,255),1)cv2.imshow('img',img)cv2.waitKey(0)
测试效果
以上是关于验证码识别多输出模型的主要内容,如果未能解决你的问题,请参考以下文章