精选文章 | 机器学习在图形验证码识别上的应用
Posted 得物技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精选文章 | 机器学习在图形验证码识别上的应用相关的知识,希望对你有一定的参考价值。
·
机
器
学
习
·
图
形
验
证
码
识
别
应
用

偶然看到小伙伴们的讨论:具体内容还不太了解,但似乎在说登录界面验证码的事儿。
验证码是测试过程中经常遇到的一个问题,于是不禁思考:如何在自动化测试的过程中对验证码进行高效的识别和处理,以此来提升测试效率?
首先,对于简单的拖放验证码(drag-and-drop),可以使用selenium的拖放函数,来操作被拖放的元素并设定拖放的距离、拖放到的目标元素。
以下的例子展示了运用拖放操作在http://pythonscraping.com/pages/javascript/draggableDemo.html的页面,来证明访问者不是一个机器人。

页面中的message元素中展示了一条信息,内容为:
Prove you are not a bot, by dragging the square from the blue area to the read area!
很快地,python就会运行完毕,并得到第二条信息:
You are definitely not a bot!
当然这是一种较为简单的验证码情况,如果是对于一个陌生的网页,实现这样的操作可能会有一点困难,尤其是绝大多数网站的验证码远比这复杂。
实际环境中,我们常见的验证码是图形验证码,以上的操作就并不适用了。
因此下面我就谈谈自己对于运用机器学习算法进行图像验证码的识别的一点粗浅看法。

问
题
分
析
要弄清怎样让机器识别图像验证码,先来想想,我们作为充满智慧的人类是怎样认出一张验证码中的字符的:
1) 对图像进行浏览,找出N个字符在图像中的位置;
2) 对找到的字符依次进行辨认,并最终得到整个验证码的结果。
其实想要让计算机识别一张图像验证码,步骤也是类似的,比如:
1) 采取某种策略对包含多个字符的图像进行拆分,使得每个图像中尽量只包含一个字符;
2) 对得到的子图像依次进行识别,得到概率最高的结果,并将全部结果依次组合则得到最终结果。
第一个步骤常被称之为图像分割。如果大家对动态规划有一点印象的话,就会更容易理解了,因为图像分割的作用与之类似,即将大的问题拆分为若干个子问题,依次攻破。
第二个步骤则是一个比较标准的监督学习(Supervised Learning)问题中的分类问题。监督学习主要分为回归(Regression)问题和分类(Classification)问题两类,其区别在于,回归问题所产生的结果是连续的,而分类问题的结果是离散的。
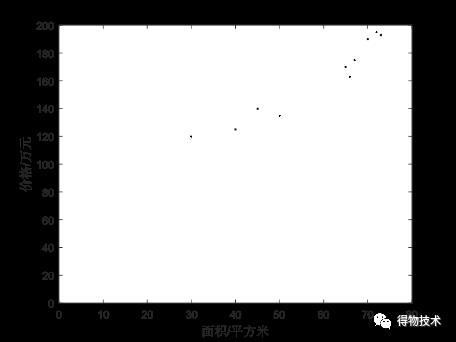
一个典型的分类问题的例子是:已知某城市若干套房子的面积与其对应的房价,以此为依据,对给出面积的房子进行房价预测。
那么已知的信息用图像表达出来就会像这样:
而一个机器学习算法给出的一条拟合函数可能会像这样:
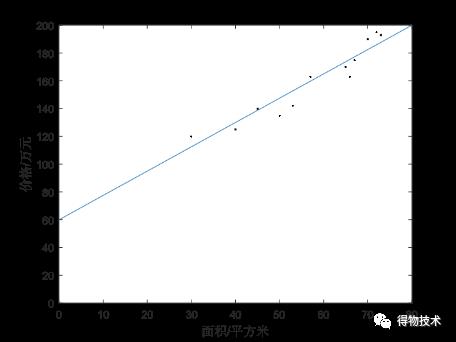
虽然实际中的回归问题往往会有更多的维度,即可能对于预测房价而言,面积不是唯一的影响因素,还会有更多的信息能造成影响,如房子所在的区域、周围的学校、与最近警察局的距离、楼层等等,这些因素作为“参数(Parameters)”,以不同的程度对最终的结果:房价产生着影响。
工程师们往往需要考虑使用哪些,或是注重哪些参数来获得一个较优的结果。
而对于分类问题,相信只要你再稍微往后看看,就会有一个清晰的认识了。
不知你有没有注意到,对于监督学习而言,已知的数据必须包含参数以及结果两方面的信息,否则如果你不知道房子的任何价格信息,就无法做出预测。
与之对应的另一个大类的问题叫做“非监督学习(Unsupervised Learning)”,我们很快也会谈到。
对于两个步骤分别可能存在的难点,我们也会在之后进行讨论。
环
境
准
备
传统算法的机器学习vs神经网络
对于传统算法的机器学习而言,无论是MATLAB还是python都是很常用的。
不过说到神经网络,由于TensorFlow,PyTorch等开源工具被广泛使用,python可能就要略胜一筹了。
Anaconda是一个开源的Python包管理器,它可以方便我们对多个虚拟环境的管理,并简单地处理好不同包之间的版本依赖问题。
如果你还在使用Python2,那么建议更换到Python3,因为有许多包已经不再对Python2提供更新。
至于其他各种相关的Python包,在之后用到的时候会单独进行列出。
数
据
集
准
备
产生一个图像验证码的数据集并不是一件太复杂的事情。大致步骤如下:
1) 在指定的字符集合(如0-9,A-Z,甚至是汉字等)中随机选取N个字符;
2) 将产生的字符放置于背景图像之上;
3) 在图像之上增加噪声;
4) 对产生的字符进行随机的缩放、旋转、投影等变换;
5) 得到验证码。
如果是为了产生验证码作为数据集,还会有额外的两个步骤:
6)将产生的验证码进行存储;
7)将产生的验证码对应的字符进行记录,写入文件。
道理说完了,不过在python中,也不乏存在简简单单就可以产生一个图像验证码的库。这里我使用到了captcha。
在安装后,使用如下的代码就可以产生一个验证码:
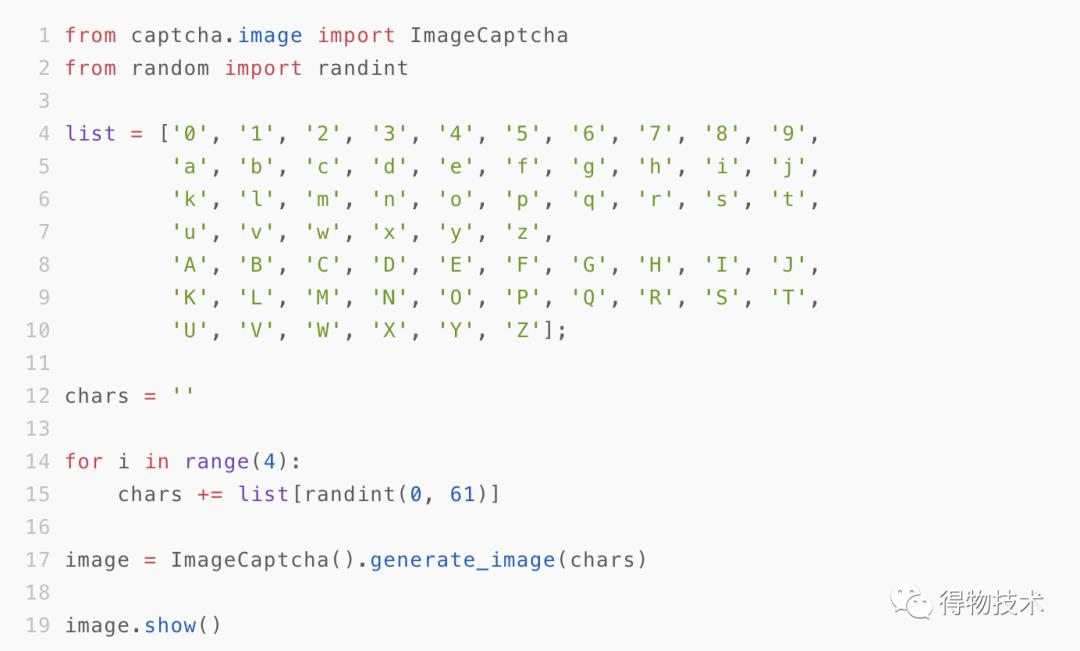
产生的验证码如下:

更进一步的,使用一个循环来批量产生验证码并写入称为文件就可以得到一个个验证码的图像了,由此可以得到训练集,它们将用来进行模型的训练。
在产生验证码的同时,对其字符内容进行记录。一个简单的思路是使用一个list来存储,并使用诸如Pandas之类的库将其写入一个csv文件,便于将来读取。

采用类似的方法,我们再来生成一个数量小一些的测试集,用于在模型训练完成后检验训练的成果:

数
据
预
处
理
不难看出,一张验证码的图像还是有挺多噪点的。
在机器学习中,图像常常被读取为“灰度图(Gray Scale Image)”。灰度图保存了各个像素的灰度信息,用0-255表示,分别对映了从黑到白的不同深浅程度。使用灰度图并不是说彩色图像不好,而是在彩色图片上进行训练会需要更大的数据量,毕竟多出了R,G,B三条通道。
对于这样一个相对较简单的问题,我觉得就没有必要使用彩色图像了。事实上,现在越来越多的相对复杂的机器学习任务是在彩色图像上进行的。另一方面,灰度图常常可以便于区分出图像的前景和背景,所以对于降噪而言,可能会更容易一点。
对于从RGB图像得到灰度图的计算,
公式为:
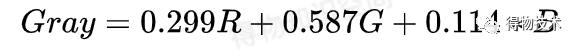
当然,这可是python,基本没有什么需要我们自己处理的算法。
使用如下的代码以产生一个灰度图的例子:

这里我们使用了matplotlib库来进行图像的显示,“cmap="gray"”的参数用于指定该库以灰度图的形式进行图像的显示,否则整张图片就会被显示得绿油油的。
这段代码产生的结果如下:
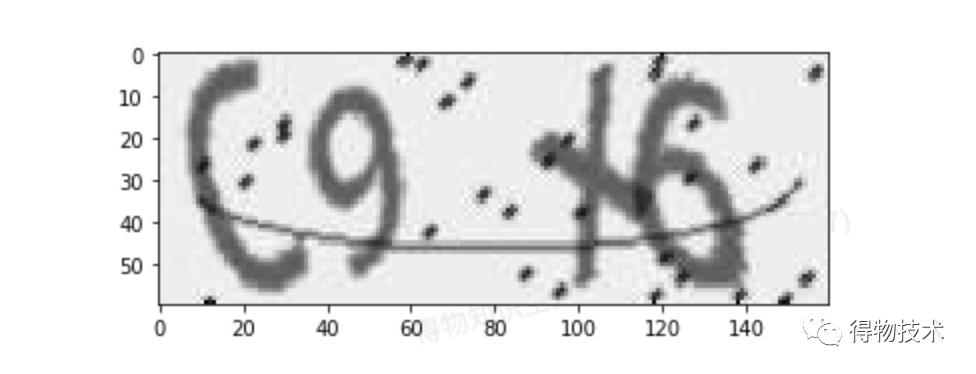
通过观察我们可以得到,大多数噪点的颜色要比字符更深,即其灰度值要更低;而背景的颜色要比字符更浅,即其灰度值更高。
通过阈值进行图像的“二值化”(仅包含0与255,即黑白两色),可以在一定程度上进行噪点的去除,便于之后的图像分割与图像分类。
如下的代码进行了该步骤:

值得注意的是,这两个阈值仅是针对此数据集而选取的两个值。
如果使用的是与此不同的数据集,则需要选取别的方式进行二值化。
二值化的结果如图所示:
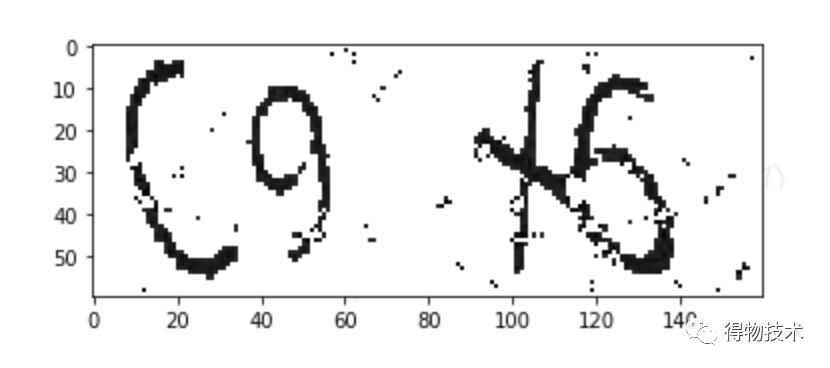
可以看到,大多数噪点被去除了。当然,我们同时也丢失了一部分信息。
对于剩下的离散噪点,一个处理的思路是,对整个图像进行遍历,检测每个像素其周围八个点的灰度值,在这个九宫格内,黑色的像素点数量小于一定阈值的点,即视为离散噪点进行清除。

这是一个效率不高的写法,不过很便于看懂究竟做了怎样的操作。
如果你想的话,可以自己进行优化。
处理后得到的图像如下:
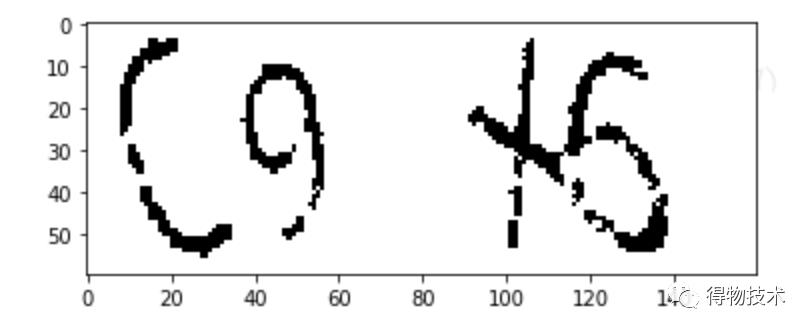
接下来,便是采取同样的方法对整个数据集进行这样的处理。
在处理结束后,由于数据量较大,在之后的聚类的步骤中,不仅需要的时间较长,对内存也会有相当大的占用。
如果在这个过程中发生因为诸如内存不足而崩溃的情况,就需要重新将图片读取为灰度图再进行处理,这就有点麻烦了。
一个解决方法是使用诸如pickle的库,将得到的train_array与test_array作为二进制文件存储:

图
像
分
割
之前已经提到过图像分割对于大问题拆分的意义。
对于一个具有4位字符,每个字符的范围从数字到大小写字母的分类问题,共有624种可能的结果,而对于拆分完的图像,分类器只需要决定它是62个可能中的哪一个就可以了——这样即使是瞎蒙,也能提高很多的准确率。
对于图像验证码的图像分割问题,我大致有以下几种思路:
1)使用若干个预先设计好的filter,依次对图像进行点乘。
对于点乘得到的若干个结果,选取响应的值较高的,并且距离相对合理的,即可完成对图像的分割。
用图像来讲解就像这样:
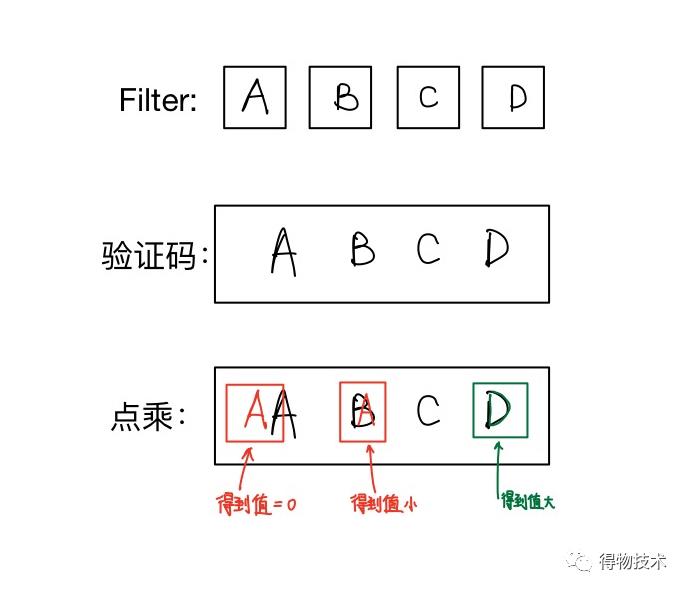
这一方法的难点在于,如何设计filter,以及如何选取filter产生的结果。
由于字符数量较多,且可能包含多种变换的结果,需要经验丰富的工程师才能决定设计怎样的filter。
如果filter的数量过多,不仅会增大计算量,也会在结果的选取过程中增加噪音,难以获得最优解。
人为的设计出优秀filter不是一件容易的事,也许需要一支相当庞大团队的努力,这就使得实现一个这样的算法很难。不过这样的思路是很可取的,之后我们也还会再见到。
2)通过某种算法进行判断。最简单的比如,纵向切割,每检测到一条不存在点的线即进行切割。
这一方法的缺点在于,对于粘连的字符难以拆分。
如果两个字符粘连在一起,还可以通过平均切割等方法大致获得结果,但如果有更多的字符粘连,甚至所有的字符都粘连在一起,这一方法就可能完全失效了。
3)通过某种聚类(Cluster)算法,得到图像分割的结果。
聚类算法是非监督学习的一种,用于在无标签的情况下,将数据集拆分为若干个类。
在传统机器学习方法中,常见的聚类算法包括K-Means,EM-GMM,Mean-Shift等。
而在神经网络中,常通过Encoder-Decoder模型来实现聚类任务。
接下来是这三个常用到的传统学习中的聚类算法的介绍:
K-means算法
对于K-means而言,它的目标函数在于最小化其点与中心的总方差和:
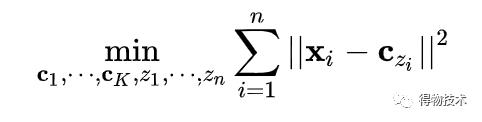
假设聚类中心已知,则只需要选取可以最小化各点到聚类中心的方差的分配方式:
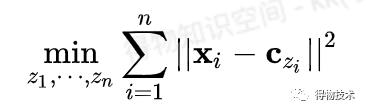
那么对于每个点而言,采取如下方式将每个点分配到离它最近的聚类中心:
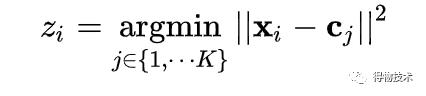
同理,如果我们已知每个点到最近聚类中心的距离,也很容易得到聚类中心的问题。
然而实际上,对于这两个前提,我们都没法直接知道,这就像先有鸡还是先有蛋的问题了。
幸好工程上而言,这个问题是可解的。
常用的方法是:
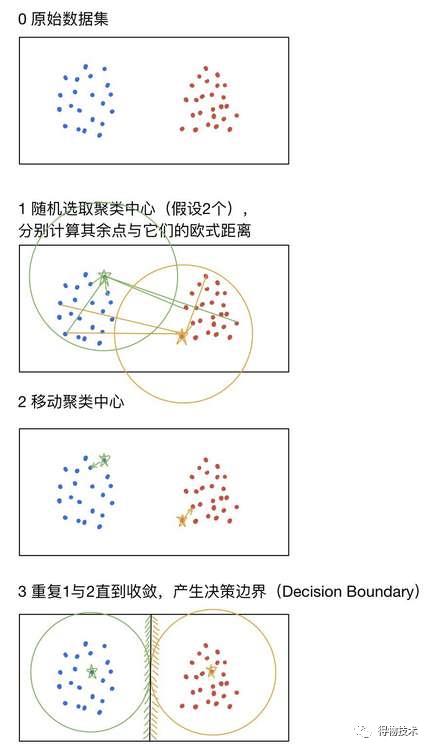
随机选取若干个初始的聚类中心;
重复:
- 通过欧氏距离计算每个点到其到不同聚类中心的距离,以得到其应属于的聚类;
- 对于每一个聚类,重新计算新的聚类中心为其平均点;直到收敛。
对于K-means而言,最终的结果依赖于初始化的聚类中心。
因此,如果运气不好,你可能需要多次使用K-means才能得到一个比较合理的聚类结果。
工程上也常常使用多次K-means算法获得聚类中心后,取使得目标方程值最小的解。
由于使用了欧式距离,K-means算法会得到一个圆形的聚类。
K-means算法的图形演示如下:
EM-GMM算法
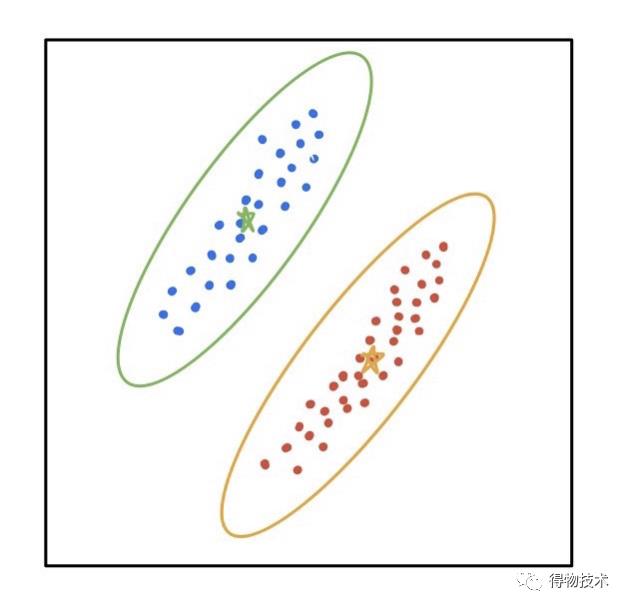
一个多元的高斯混合模型(GMM)可以获得椭圆状的聚类。
椭圆的形状由高斯分布的协方差矩阵所决定,而位置由均值所决定。
高斯混合模型是一个高斯分布的加权和:
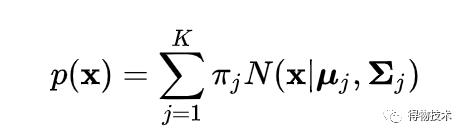
每个高斯分布代表了一个椭圆的聚类。

实践中,常用期望最大化(Expectation Maximization, EM)算法来对于GMM进行计算。
当有隐变量(hidden/unseen variables)时,EM算法常用来获得最大似然估计解。
对于GMM的EM算法求解过程如下:
E-step:计算聚类的关系,将分配给聚类 j
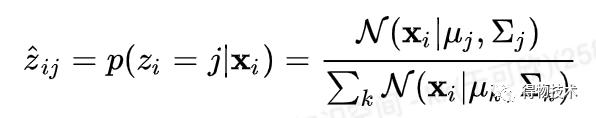
注意,这里使用的分配实际是一种软分配,即一个点可以分数化地分配给不同的聚类。
2. M-step:更新每个高斯分布聚类的均值、协方差和权重
计算聚类中的点(软性的):
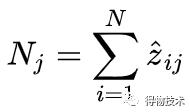
权重:
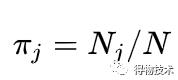
均值:
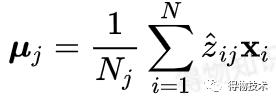
协方差:
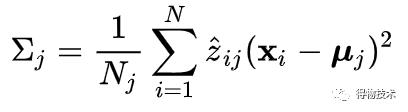
由于圆实际上是一种特殊的椭圆,所以在协方差相等时,使用EM-GMM算法获得的聚类结果应与K-means的结果相同。
使用EM-GMM算法常常能够得到这样的聚类结果:
Mean-Shift算法
Mean-Shift算法的理念在于,对于集合中的每个点逐步地计算其梯度并相应的移动,最终移动到同一个局部最优的点,即属于同一个聚类。
实践中,具体步骤如下:
1) 从一个初始点x开始;
2) 重复:
- 根据高斯kernel,找到x在一定半径内的最近邻居;
- 将x作为其临近点的均值,直到x不再变化。
该步骤的图形演示如下:
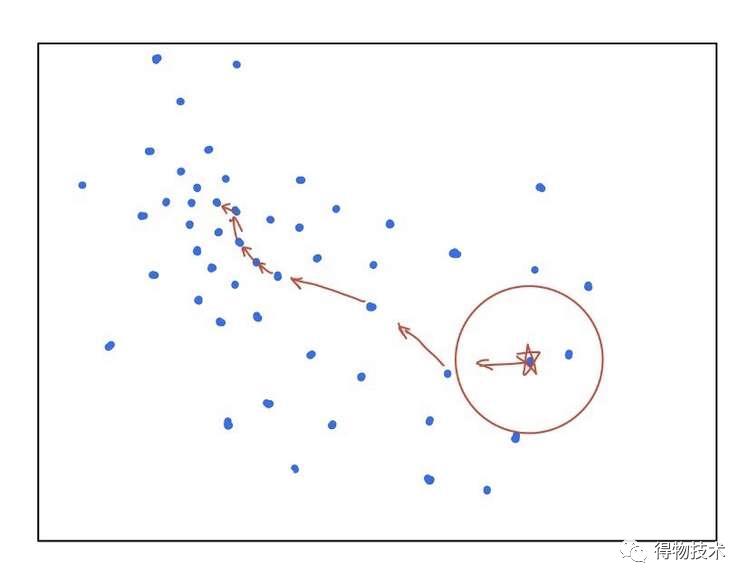
更直白一些的说,就是随机初始化一个半径固定的圆,然后将其圆心一直向数据集密度最大的方向移动。
多次迭代后,当其不再移动时,即到达了一个聚类中心位置,而圆的半径以内的点则为该聚类中的点。对于mean-shift算法而言,其变量自然就是圆的半径了。
在这一问题中,一个比较接近于mean-shift的实现(同时也是比较常用的)算法被称为分水岭算法(Watershed Algorithm)。
想象有一条连绵起伏的山脉,这时突然下起了大雨,山与山之间低的地方自然就积满了水,图像也就这样被分割了。在实现中,“下雨”的过程实质上就是梯度下降的过程。
这样听上去,聚类算法似乎很适合实现这样的目标。事实上,对于较为简单的验证码(字符分隔界限较明显、较为容易分隔的情况),聚类算法能够进行分类,但对于复杂的情况,或许结果就不是那么理想了。
以下为使用K-means算法对之前验证码进行聚类后的结果:

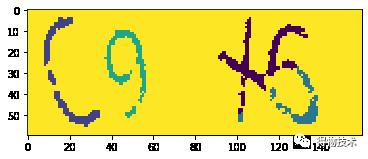
可以看到,C和9两个字符已经被分割开,而X与6则完全被混淆到了一起。
原因可能是:
字符并不符合于圆形的分布,又或是K-means在这种情况下难以得到一个好的初始化点等等。
更关键的问题在于,如果我们这时候去检查聚类中心的横坐标的位置,并将其对应结果依次从左到右显示:
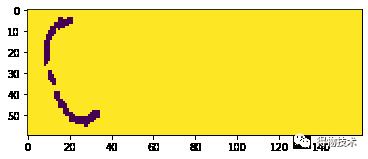
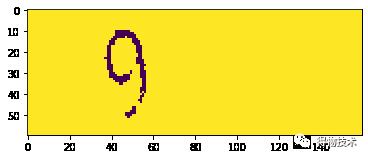
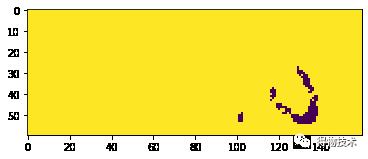
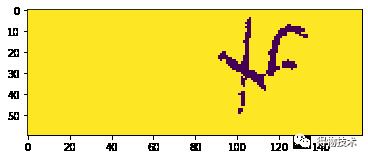
可以看到,更像“6”的结果3出现在更像“x”的结果4之前,如果直接进行标注,这样的标注就可以被认为是“脏数据”。
使用分水岭算法得到的结果也并不理想:
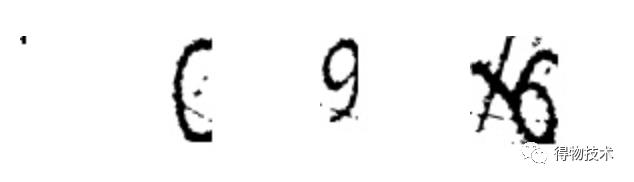
对于传统算法的机器学习而言,解决一个较为困难的问题,往往需要一支数十人甚至数百人的工程师团队,花费数月甚至数年的时间进行设计。
鉴于这样的分割结果,直接图像分类肯定是走不下去了。所以我接下来我会对常见的分类算法进行一些介绍,然后一起来看看运用神经网络是否能解决这个问题。
在图像分割之后,有一些诸如对图像进行“归一化(normalization)”的技巧。
在这一问题中,使用归一化可以在一定程度上实现对于图像方向向量的校正,通过一个设计好的“确定方向边界框(Oriented Bounding Box)”可以是达到这一效果的一个思路。
图
像
分
类
针对这一问题,进行分类的主要难点在于,由于某些字符的先天性的难以辨别,这会对分类器的收敛造成困难。
诸如0与O,I与l - 你真的能认出这两个谁是谁吗?!
不过对于这个问题,我也并不能想到什么好的解决方式,所以只能视若无睹了。
在真正开始训练之前,对于数据集还可以采取的一种常见策略叫做“数据增强(Data Augmentation)”。
大致上来说,数据增强常常就是对于数据集中的数据采取某种方式的变化,来扩大数据集。
不过要注意,对于采取的具体变化要小心。对于这个问题,可以采取的简单的变化方式主要有“投影(Shearing)”,“旋转(Rotation)”,“偏移(Shifting)”和“缩放(Zooming)”。
在进行旋转时,要注意只能在一个较小的幅度内进行,如对于“7”进行180度的旋转,就会变成一个类似于“L”的形状,然而其标签仍然为“7”,这显然就是一个噪音了。也可以通过增加一些噪音,如“高斯噪声(Gaussian Noise)”来实现数据增强,让模型更为健壮。
实现这一功能的代码如下:

其实对于这一问题而言,数据增强并不是必须的,因为获得一个新的验证码太容易了,并且我们已经有了一个相当大的训练集了。如果花费足够的时间产生一个足够庞大并且分布较为均匀的数据集,且与测试集服从相似的分布,模型在测试集上的表现就不会太差。
这里使用的数据增强的方式,在生成验证码图片的过程中是常常用到的,所以并不是什么必须的,或是能显著提升准确率的手段。这里提及更多的是作为一种介绍。
可能你注意到,在刚刚的代码块中用到了一个名为keras的Python库。Keras基本可以理解为一套便于开发人员开发高级神经网络的API,它支持使用TensorFlow,Theano等作为后端运行。个人感觉而言,它的语法要比原生的TensorFlow多少友好一些。
分类算法又可分为“二分类算法”和“多分类算法”两种。顾名思义,二分类算法就是对于数据集,只能将它们分为两种类别的算法。常见的二分类算法包括逻辑回归(Logistic Regression,LR)、支持向量机(Support Vector Machine,SVM)等。而最常见的多分类算法就是决策树(Decision Tree)了。
逻辑回归
分类器:
对于线性函数:
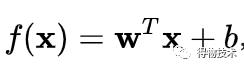
给定特征向量,一个类的概率是:
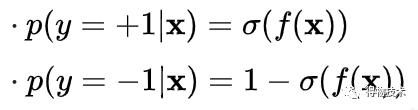
sigmoid函数:
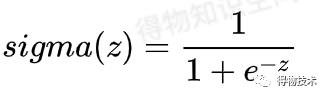
逻辑回归的损失函数:
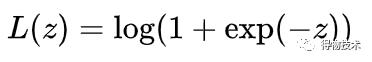
训练:
最大化训练集的可能性
通过正则化(regularization)防 止过拟合——通过交叉验证选取正则化超参数C
进行分类:
对于给定样本x*:
选取概率最高的类别p(y|x*):
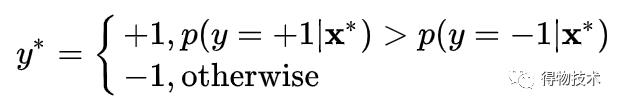
否则,直接使用f(x*)
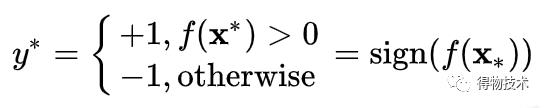
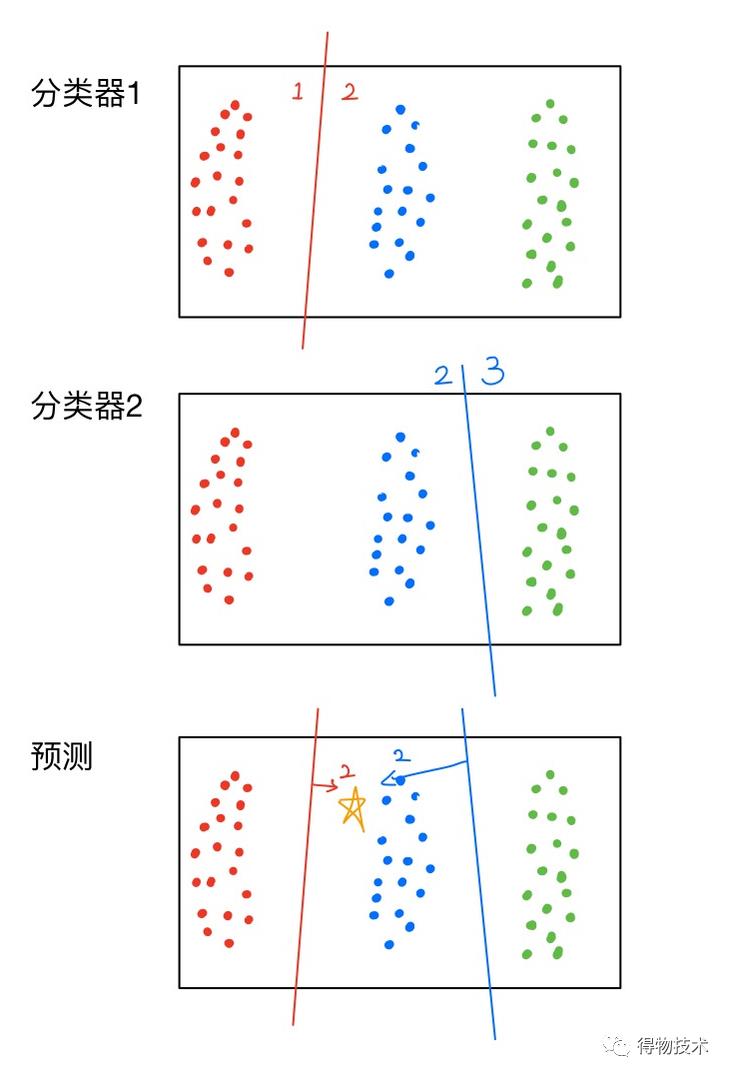
对于逻辑回归这样的二分类分类器,通过一些手段,也可将它们用于解决多分类问题。
其一是使用诸如“1-vs-rest”策略。换言之,即将多分类问题划分为若干个二分类问题,使用多个二分类分类器进行解决。
另一个得到多分类分类器的方法是定义一个多分类目标函数,并给每个类别C分配一个权重向量Wc。
通过softmax函数定义概率:
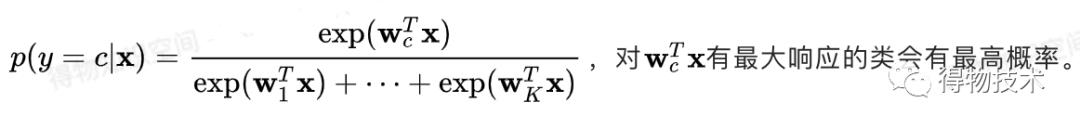
支持向量机
对于一个分类问题而言,可能会有若干个分类器:
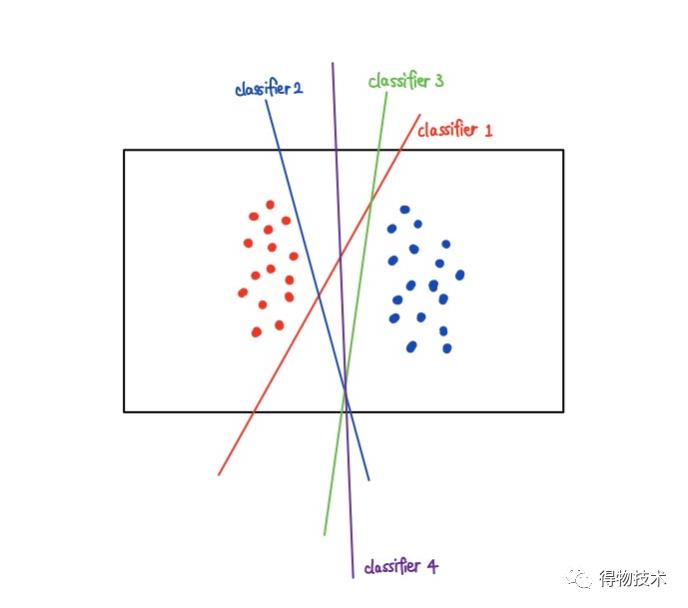
对于SVM而言,其目的就是要找【边缘(margin)最大】的那个分类器。
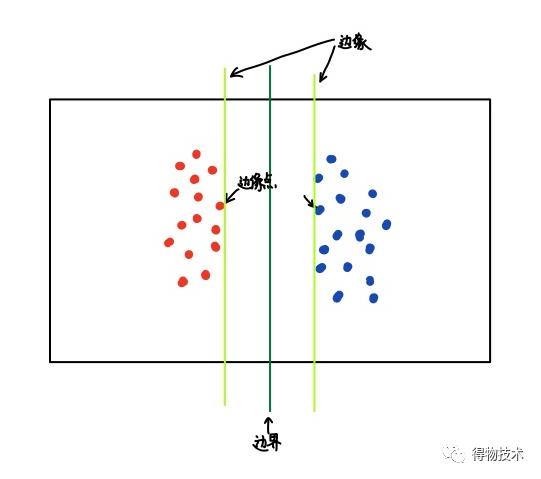
SVM这样决策的优点在于,在保证所有点都被正确分类的同时,也保证了最大不确定性。
训练:
对于给定训练集:
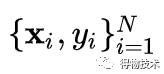
首先定义边缘距离:
从点Xi到超参数W的距离:
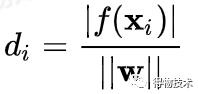
边界距离是到所有距离中的最短距离:
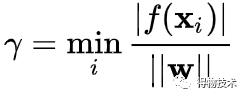
目标函数为:
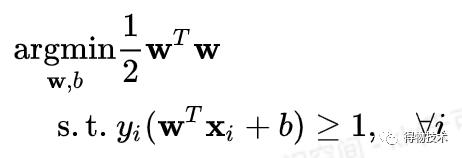
预测时,对于新的数据点
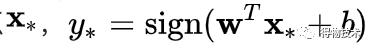
可以看到,SVM产生的决策边界是线性的。
可以使用“核函数(kernel function)”使得SVM可以做出非线性的判断。
这其实是一种将数据集向高维转化,使得数据集在高维上线性可分的做法。
K近邻法
K近邻法(K-Nearest Neighbors)是一种很简单的分类算法。
每次有新的样本,分类器就会找到在已知样本中距离其最近的K个,然后选取其中的大多数来作为新样本的分类。
这并不是一种好的分类方法,因为分类器什么都没有学到。
决策树
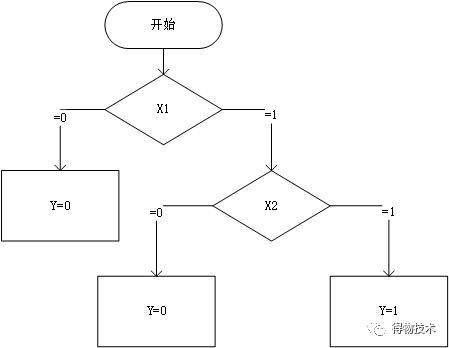
决策树也是一种较为简单的分类器,你可以将它想象成流程图。
对于一个“与”运算:

产生的一个决策树如下:
使用分类器的劣势在于,它很容易过拟合。幸好,这可以通过Bagging策略进行弥补。由于决策树本身是一种较为简单的分类器(占用资源少,运算速度快),使得其常常与Boosting和Bagging这两种策略相结合使用,以产生更好的结果。
Boosting:训练多个分类器,每个新的分类器专注于之前的分类器分类错误的部分。
Bagging:训练多个分类器,每个分类器只使用训练集中的随机一部分子集进行训练。在预测时,使用所有的分类器来投票,得到这个新样本的分类结果。使用决策树的Bagging策略又被称为“随机森林(Random Forest)”分类器。
用
神
经
网
络
进
行
验
证
码
识
别
使用神经网络解决该问题,可以使用两种思路。
1)多分类任务
多分类任务,也就是之间所介绍过的,最终的结果只有一个标签,但是标签会有若干种类别。
2)多标签任务
对于多标签任务而言,一条数据可能有一个或多个标签。
想象你正在听一首歌曲,如果你在里面听到说唱,那么说唱就是这首歌曲的一个标签。同样的,这首歌曲还可以有诸如流行、古典……等等标签。
只要你在其中听到了相应的特征,它就有可能作为这首歌曲的一个标签,得到该标签对应的概率。
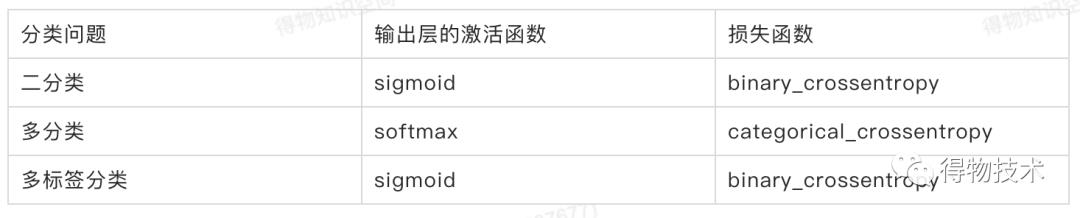
在训练神经网络时,不同任务使用的激活函数和损失函数关系如下:
如果你想对多标签任务有更多的了解,可以查阅收录于 2014 TKDE 的张敏灵与 周志华的论文:
A review on multi-label learning algorithms。
限于时间和篇幅的关系,对于神经网络相关的内容这里也就不做过多的讨论了,如果说起来,恐怕这篇文章就要没完没了了。以下为神经网络的一个实现:
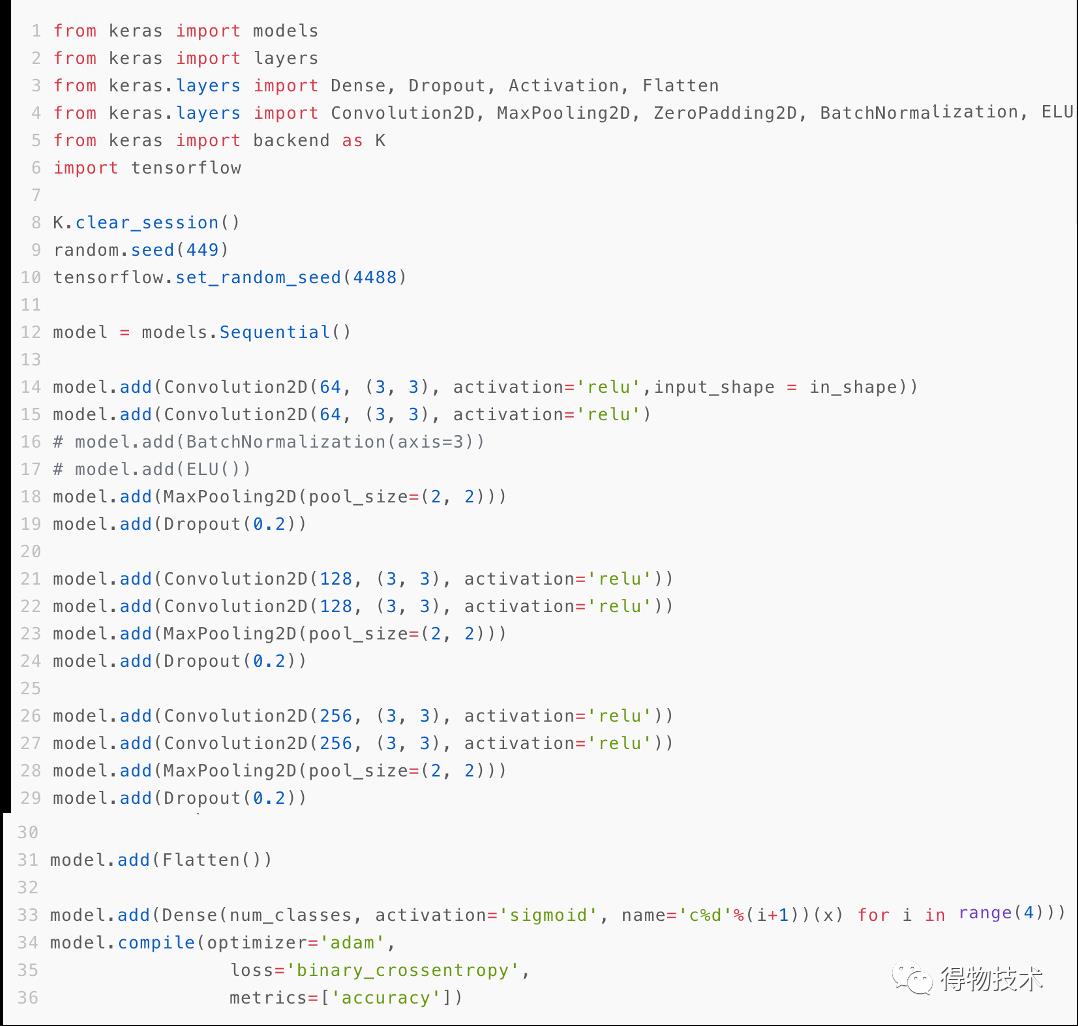
这里使用了卷积神经网络(Convolution Neural Network,CNN)。CNN在计算机视觉问题中被广泛使用。相比于传统的DNN(Deep Neural Network,这里即MLP,Multi-Layer Perceptron多层感知机),它能够同时兼顾“整体”与“局部”,找到不同区域间的关联关系。
这个模型中包含了很多神经网络(也可以用于传统机器学习)的常见内容,比如“优化器(optimizer)”(近几年最常用的应该就是Adam,虽然有很多大佬并不喜欢它)、“池化(Pooling)”(最常见比如MaxPooling,即在一个矩阵中取最大值,然后将这个矩阵进行缩小,通过这个过程神经网络可以“看得更广”)、“dropout”(一部分结点不响应也做出决策,使得神经网络更加robust,用于解决过拟合)、还有激活函数(ReLU、sigmoid等等……),大家有兴趣可以自己多去了解。
这里使用神经网络的方法,也可以说是对于使用神经网络而言最简单的方法:定义好一个网络结构,然后把数据塞进去,看看结果怎么样。如果结果不太理想的话,就调整网络结构再试试。
这也正是使用神经网络和使用传统机器学习算法的一个显著区别:神经网络由数据驱动,人为的干预往往也只是定向的输入数据,通过数据来校正网络;而传统机器学习算法则由工程师预先设计好各种情况,如果算法的结果不够好,常常也只是因为设计好的算法对于某些情况处理不当。因此,你也大可以修改网络的结构,或者使用别的网络来试试。
上述的代码使用的是运用多标签任务的方法的,你也可以修改为多分类任务的网络(应该只需要修改全连接层的激活函数和损失函数即可,并且根据我的查阅,这一方法也是可行的,并且准确率可以到很高的程度),来看看结果如何。
当然,也不是所有人在运用神经网络的时候,都使用这种“端到端(end-to-end)的方法,即一个神经网络解决所有问题。你也可以对于输入网络的数据进行更多的预处理(预处理也可以由别的结构的网络来完成),来看看是否能得到更好的结果。
更进一步地说,这里所采用的CNN网络是解决CV(Computer Vision,计算机视觉)问题的一个常见解决方法,而对于图形验证码问题,也可以采取NLP(Natural Language Processing)的思路进行解决。
使用一些RNN(Recurrent Neural Network, 循环神经网络),例如前几年比较流行的LSTM,也可以对这个问题进行求解。
这里的网络事实上只预测了36个分类。
训练过程的截图在此:

可以看到在第5个epoch,模型在验证集(10000个的训练集中,9000个用于训练而1000个用于验证集——一个不参与训练,只检验模型训练成果的数据集)上的表现已经开始下降,这说明模型已经开始过拟合于训练集。当然这个过程其实不一定要手动干预,使用早停法(early stop)就可以实现。可以看到,我大约在准确率为95.81%的时候停止了训练。
模型的一个预测结果如下,可以看到这是一个正确的预测。

模型在测试集上的表现为0.9390625,也就是大约93.9%。

·
结
语
·
当然,验证码的形式多样,越来越复杂的验证码也越来越难以攻破。
例如部分网站现在所采用的图像验证码,为给出多张图片,要求用户在找出其中具有某种物体的图片并进行选择。这个问题的难度,就远超于单纯的字符识别问题了。对于这样的问题,就要求算法应具备识别相当数量物体(例如,数百种物体:轿车、大象、花朵、红绿灯等等)的能力。
综上所述,针对于测试工作而言,最好用的方法肯定还是和开发哥哥姐姐们商量一下,绕过一下验证码,不仅省去了开发整个识别验证码系统的时间,还可以提高通过的准确率,毕竟无论怎样的机器学习方法都不可能产出100%的准确率(假设训练集不可能包含所有可能情况)。
-END-
文 /PokemonFish
以上是关于精选文章 | 机器学习在图形验证码识别上的应用的主要内容,如果未能解决你的问题,请参考以下文章