比拼Mesos/Marathon?基于Docker 1.12 Swarm集群管理深度实践
Posted 高可用架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了比拼Mesos/Marathon?基于Docker 1.12 Swarm集群管理深度实践相关的知识,希望对你有一定的参考价值。
正文开始前先八卦一下,关注 Docker 技术的小伙伴们应该清楚 Docker 1.12 的 Swarm mode 颇受争议:首先是有人认为 Docker 公司 Market Drive Develop,违背了 Linux 信徒恪守的哲学——一个工具只干一件事情;其次, 有人认为 Swarm mode 的功能不及 Mesos 和 K8S,还不适合生产环境使用,这一点我倒认为稳定性而不是功能才是 Swarm 目前不适合生产环境的原因;最后, Docker 的向后兼容性不足也引来口水无数,毕竟 Docker 还在 active develop。其它的像容器网络标准的争议, Runc 的争议这些都把 Docker 推到了风口浪尖。当然,不辩不明,相信 Docker 给我们提供的不止眼前这些。
我们首先从应用编排( Application Stack)谈起,应用编排是 Docker 1.12 引入的概念,目前还是 experimental 的功能,必须得安装 experimental 的包才可以尝试。除去编排 (stack), Docker 1.12 还引入了服务 (service) 和任务 (task) 的概念, Docker 借此重新阐述了应用与容器 (container) 之间的关系。上述几个概念的关系如下图所示:
(图片来自网络)
即:一个应用编排代表一组有依赖关系的服务,服务之间可以相互发现(后面详细介绍),每个服务由多个任务组成,任务的数量可以扩缩 (scale),而任务则物化为一个具体的 Docker 容器及其配置。
Docker 通过扩展名为 dab( Distributed application bundles) 的文件来描述一个应用编排,下图是一个带有两个服务的 dab 文件例子:

这里有dab文件的详细介绍:
https://github.com/docker/docker/blob/master/experimental/docker-stacks-and-bundles.md
其中 Image 这里推荐使用 image@digest 而不是 image:tag,原因是为了避免这种情况 : 在集群中部署服务时, image:tag 无法保证镜像是全局一致的,本地的 image:tag 可能与镜像仓库里面的 image:tag 数据不一致,这个问题在跨机环境中被放大。而 image@digest 这种方式通过中心化仓库设置全局唯一的 digest 值,避免了上述问题。
除此之外,还有下述几个关键特性值得分享:
滚动更新:服务的镜像更新是一个基本诉求。 Docker 可以通过关键词 update-parallelism 和 update-delay 来控制并行更新的频率。 Marathon 也提供了类似的功能。这个特性很关键,如果无法控制更新频率,成百上千的镜像拉取和任务调度会导致严重的资源波峰。 Docker 文档还声称支持更新失败回滚,尝试了下,目前没发现怎么玩,还没来得及看底层代码。
服务模式 (service mode): Docker 1.12 提供了两种方式控制任务数量—— replicated 和 global,在 replicated 方式下,我们需要提供期望的任务数量, Swarm 将一直尝试维护这个任务数;而在 global 方式下, Swarm 尝试在每个节点上启动一个任务,这种方式特别适合向每个节点下发 agent 的场景。
stop-grace-period 参数:在服务缩容时,我们比较关心容器被强制 kill 而带来的事务 (transaction) 问题,配合该参数 stop-grace-period( 强制杀死容器前的等待时间 ) 和容器内部的退出信号监听,可以达到容忍程序友好退出和快速回收资源之间的平衡。 Mesos / Marathon 也采用了类似的策略来解决这个问题。
with-registry-auth 参数:在服务创建时,该参数声明将管理节点 (Swarm manager) 上的 registry authentication 信息带到工作节点 (worker node) 上,从而为工作节点提供从 registry 拉取镜像的认证信息。在 Docker 的非 Swarm 场景下, Docker-client 负责 registry 认证信息的管理,但在 Swarm 方式下,不再是 Docker-client 触发镜像拉取动作,所以服务无法使用工作节点本地的 registry 认证信息了,必须要通过上述方式从管理节点分发认证信息。同时节点间的加密通信也保证了认证信息传输的安全性。
任务的生命周期:在容器的生命周期之上, Docker 1.12 引入了任务 (task) 的生命周期。某任务下的容器异常退出时,带有同样任务编号 (slot) 的新容器将会被尝试启动。不同于容器的生命周期只囿于一台固定主机上,任务的生命周期是与主机无关的,我们可以依此对容器的日志进行聚合得到任务的日志。这一点正好是 Mesos / Marathon 所欠缺的。
重启策略: Docker 1.12 提供了三种重启条件 -any, none, on-failure,其中 none 指的是退出不重启, on-failure 指的是失败( exit code 不是零)时重启,而 any 指的是无论任务正常或是异常退出,都重启。 any 方式配合参数重启间隔 (restart-delay) 可以满足定时任务的场景; none 方式则可以满足批处理任务场景。另外参数评估间隔 (restart-window) +参数尝试次数 (restart-max-attempts) 可以控制在一段时间内的任务重启次数,避免异常任务频繁重启带来的集群资源失控。
当然,Swarm mode 还有很多问题亟待解决:
dab 文件的表达能力有限:当前版本的 dab 文件只有寥寥数个关键词,服务 (service) 创建的诸多参数 dab 都无法支持。在我们的实践中,为了解决这个问题, team 不得不二次开发引入服务的其它参数,以期对服务的参数全量支持。
容器回收问题:按照目前的设计,只要服务 (service) 还在,退出的容器是不会被自动回收掉的,在某些场景下,这会导致集群失控,各主机的文件描述符被耗尽。
容器的健康检查 (healthcheck): 在我看来,这是 Swarm mode 之外, Docker 1.12 引入的最关键功能,有了 healthcheck 这个 feature,我们可以将业务内部真正的健康状况暴露出来了。这个功能落后于 Marathon 足足一年的时间。但可惜的是,服务( service)创建目前还不支持这个关键词,这就限制了服务 (service) 异常重启的能力,从而间接降低了服务容错能力。这一点 Marathon 做的特别好。
资源控制: 1.12 目前支持单个任务 CPU / mem 的资源控制。还无法像 Mesos 那样,自由的配置管理磁盘, GPU,端口等资源。
无法使用主机网络:通过服务( service)启动的容器是无法使用主机网络的 (network host is not eligible for Docker services),但同时按照网络上 Percona 提供的压测结果, overlay 网络相较于主机网络有 60% 的性能损耗。这严重局限了 Swarm 的应用场景,我们可以认为这是编排功能带来的架构副作用。而 Mesos 从资源维度管理集群很好的规避了这个问题。
接下来让我们看看下一层:Docker 是怎样在 stack, service, task container 之间建立联系的?同一个 stack 内的 service 又是如何相互发现的?
第一个问题很好回答, service label 和 container name, Docker 通过在 service 上添加 label: com.Docker.stack.namespace=XXX 来标示这个 service 属于哪一个 stack。我们可以 inspect 一个 service 看下:
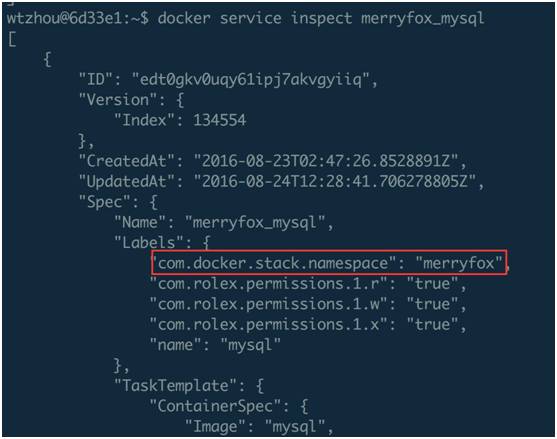
Docker 通过特定格式的 container name 标示这个 container 隶属于哪一个 service 下面,如下图所示:

容器名称 merryfox_mysql.1.by842qrj7xhsne93yzfpjp367 代表该容器是服务 merryfox_mysql 的任务 1 的容器。Docker 在很多地方使用了这种技巧来处理数据。而第二个问题就引出了我们下面的——服务发现。
服务发现
在谈服务发现之前,我们简单讨论下 Docker overlay 网络的性能问题,根据 https://www.percona.com/blog/2016/08/03/testing-Docker-multi-host-network-performance/ 的网络压测结果,相较于 host 网络, overlay 有 60% 的网络性能损耗,问题主要出在多 CPU 下网络负载不均。同时容器无法在 Swarm 编排模式下使用 host 网络,这带来的问题就是:在 Docker 1.12 Swarm mode 下网络性能损耗无法避免。
与 Marathon / Mesos 的 Mesos-DNS、 bamboo 类似, Swarm 的服务发现也分为内部服务发现 (internal service discovery) 与外部服务发现 (ingress service discovery),这两种服务发现使用了不同的技术。
如果想让一个服务暴露到集群之外,我们需要借助 service create 的参数 publish,该参数显式的声明将集群特定端口 PORT_N(集群端口 PORT_N 代表集群中所有主机的端口 PORT_N)分配给这个服务。这样无论该服务的容器运行在哪台主机上,我们都可以通过集群中任何主机的 PORT_N 端口访问这个服务了。下图可以形象的描述这个场景:
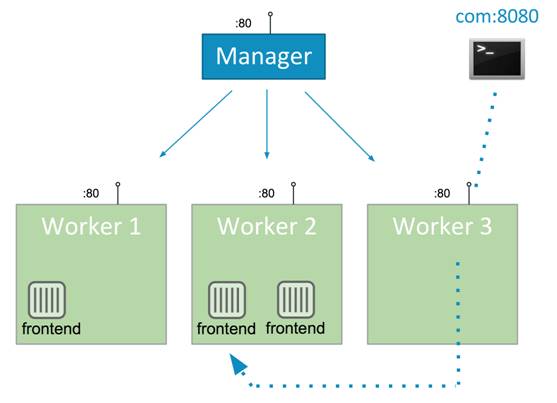
接下来,我们就可以把集群中部分或所有主机的 IP 加上述端口配置到我们的前置负载均衡器上对公网提供服务了。一般称这种分布式的负载均衡策略为 routing mesh,在 Calico 网络方案中也提到了类似的概念。由于没有了中心化的负载均衡器,集群不会因某台机器异常而导致整个服务对外不可用,很好的避免了单点问题,同时也带了可扩展性。关于routing mesh这个概念的详细介绍可以参考该链接(https://en.wikipedia.org/wiki/Mesh_networking)。
这里摘抄一个简短解释:
A mesh network is a network topology in which each node relays data for the network. All mesh nodes cooperate in the distribution of data in the network.
上述就是 Swarm 的外部负载均衡(也可以称为routing mesh),那么 Docker 在底层做了什么来实现上述功能的呢?如下图所示:
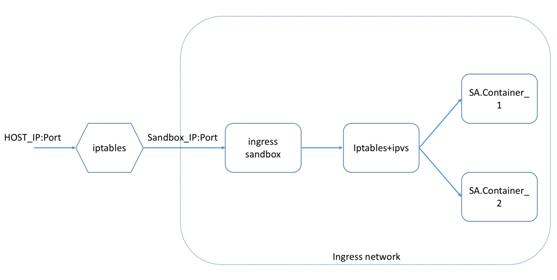
在 Swarm 集群初始化时, Docker 会创建一个 overlay 网络 ingress,同时在每个节点上创建与 ingress 关联的 sandbox 网络命名空间,这样集群中的每个主机都变为了 ingress 网络的一部分;
当我们创建 service 申请一个 publish port 时, Docker 会通过 Iptables rules 建立 主机 IP:Port 到 sandbox IP:Port 间的映射,即 : 将对应端口的包转发给 ingress 网络;
同时在 sandbox 网络命名空间内, Docker 通过 Iptables rules + IPVS 控制对应 端口/ Port 的包负载均衡到不同的容器。这里 IPVS(IP virtual server) 的功能与 HAproxy 类似,承担着 Swarm 集群内部的负载均衡工作。
对于只供集群内部访问的服务,无需使用上述 routing mesh,Swarm 还提供了一套内部服务发现 + 负载均衡。如下图所示(这里我们只讨论基于 VIP 的负载均衡方法):
manager 会为该 service 分配一个 VIP(Virtual IP),并在内部 DNS 上建立一条 VIP 与 service name 的映射记录。注意这里的 DNS server 也是分布式的,每一个主机上都有一个 DNS server ;
Iptables 配合 IPVS 将 VIP 请求负载到 service 下面的一个具体容器上。
另外,主机间 routing mesh,load balancing rule 等信息是利用gossip协议进行数据同步的,限于篇幅,这里不再深究这个问题。
最后友情提示几个雷区:
Q1:为什么我的机器无法加入 (join) 到 Swarm 集群中?终端报错:加入集群超时。
A1:这个问题极有可能是主机间时钟不同步导致的,建议开启 ntp 服务,同步主机时间。
Q2:为什么我在 manager A 上通过命令 Docker network create 的 overlay 网络无法在集群另外的机器 B 上通过 Docker network ls 发现?
A2: 这有可能是正常的。按 Swarm 当前的设计,只有使用相应网络的容器被调度到了机器 B 上, overlay 网络信息才会更新到机器 B 上去。
Q3: 为什么我的服务的 publish port 在有些机器上不生效?我使用 netstat – lnp 方式看不到端口监听。
A3: 与问题 1 一样,这也可能是时钟不同步导致的问题。
参考链接:
http://collabnix.com/archives/1391
https://sreeninet.wordpress.com/2016/07/29/service-discovery-and-load-balancing-internals-in-Docker-1-12/
国内首个基于 Docker SwarmKit 的容器管理面板——数人云 Crane 第一版最新出炉,欢迎点击“阅读原文”申请体验,点赞 or 吐槽都可以。
以上是关于比拼Mesos/Marathon?基于Docker 1.12 Swarm集群管理深度实践的主要内容,如果未能解决你的问题,请参考以下文章
云计算jenkins,docker,mesos,marathon,k8s相关资料
DCOS=Mesos+ZooKeeper+Marathon+Docker