飞驰在Mesos的涡轮引擎上
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了飞驰在Mesos的涡轮引擎上相关的知识,希望对你有一定的参考价值。
回想起第一次接触Mesos,当时有很多困惑:“这到底是用来做啥的?跟YARN比有什么优势?有哪些大公司在使用么?”。
然而现在技术日新月异地发展,Mesos这个生态圈也开始被越来越多的团队熟悉关注,像k8s、Swarm之类的重量级竞品一个个地涌现。
在踩了或多或少的坑,现在重新回到这个问题,简而言之:
Q1:这到底是用来做啥的?
通俗地讲,就是把N台机器当做1台机器使用。
Q2:跟YARN比有什么优势?
更加通用,不局限在数据分析领域。
Q3: 有哪些大公司在使用么?
做技术预研的时候因为看到苹果在用,心里倍儿踏实。
Mesos在团队的变迁史
一
为Spark而Mesos
我们的分析团队一直都是在传统的CDH上跑Hadoop生态。对新业务评估时决定拥抱Spark,但CDH升级困难,Spark版本滞后,使用起来也远比Hadoop繁琐。最后我们决定基于Mesos从头构建新的数据分析基础环境。
但是Mesos上缺乏我们必须的HDFS和HBase。经过讨论我们决议了两种方案。
方案一
将HDFS,HBase和Mesos独立部署在裸机上,如下图
(前期方案一)
但实际使用时会因为HDFS和HBase并非在Mesos的隔离环境下运行,与Mesos会竞争系统资源。基于这样的考虑,我们否决了这种方案。
方案二
HDFS和HBase也运行在Mesos中。这种方案避免了上述问题,但也意味着我们需要自己实现这两个服务在Mesos中的部署。团队的大神担起了这个任务,制作了HDFS和HBase的Docker镜像, 通过marathon部署在Mesos中。
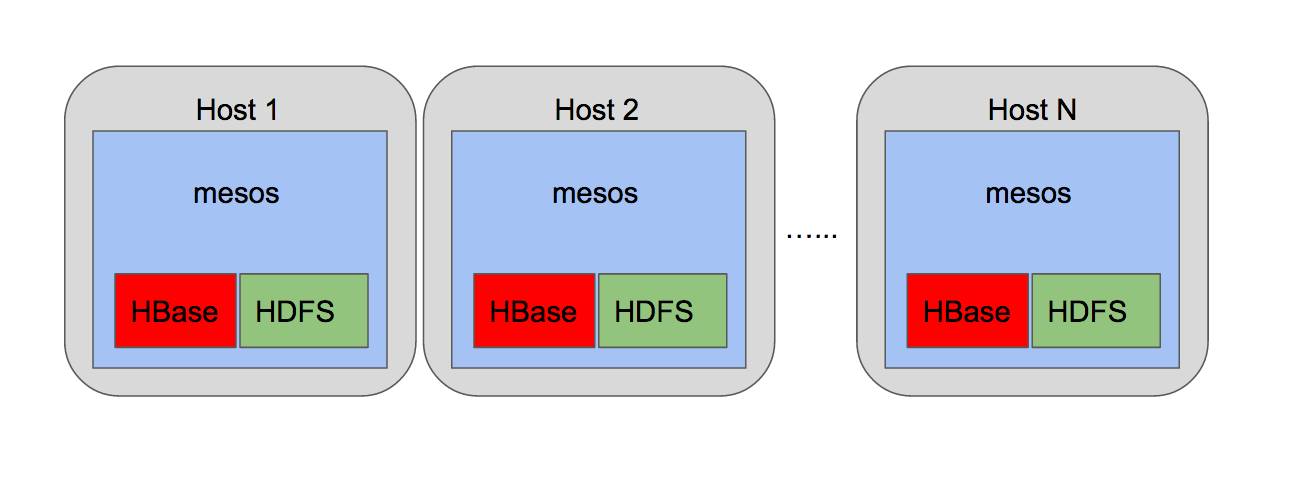
(前期方案二)
基于这样的部署形式,团队顺利地过渡到Spark生态,让我们的分析系统更加飞快地运转。
二
好马还需配好鞍,这个鞍叫DC/OS
DC/OS可谓Mesos生态里的Cloudera。但由于其商业收费,对于我们这样的初创团队一直都是”可远观而不可亵玩”。
直到其开放了社区版,我们才得以略窥一斑。在没有引入DC/OS之前,对于管理Mesos集群我们碰到以下几个痛点:
没有自动化运维脚本。新增、删除节点、变更配置均需要手工介入。
没有直观的可视化图表来查看各项运行指标。Mesos自带的界面相对比较简单,体验不佳。
没有集中的日志管理。
安装一些通用的服务比较繁琐。
通过DC/OS管理Mesos集群,可以轻松地使用Bootstrap节点方便地管理各个节点,其服务也都通过systemd来管理依赖,避免了手工管理的繁琐。
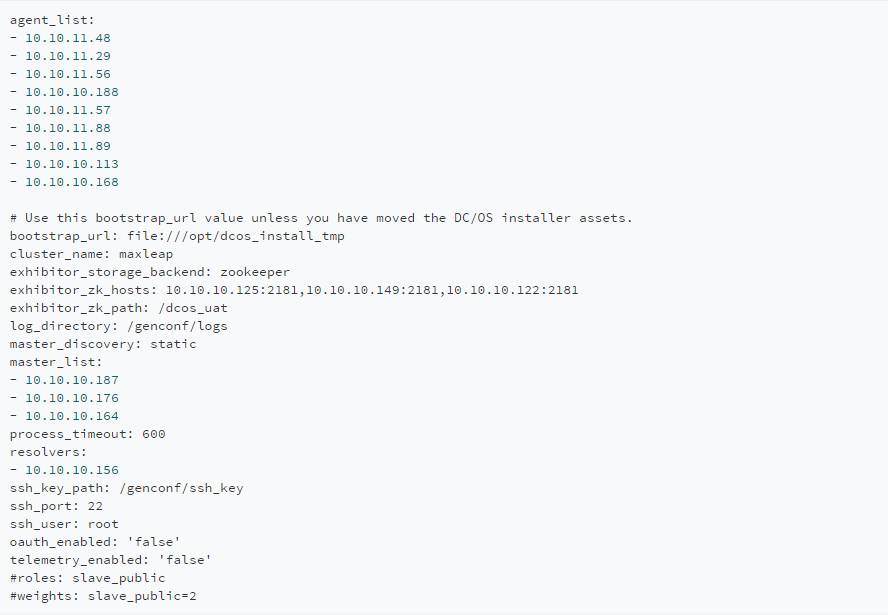
通过官方的教程,可以很方便地配置安装节点,以下是范例:
UI简洁易用,比较常用的一些功能大多都已包含。通过使用Universe的包管理器,我们可以很方便地一键安装各种常见服务。
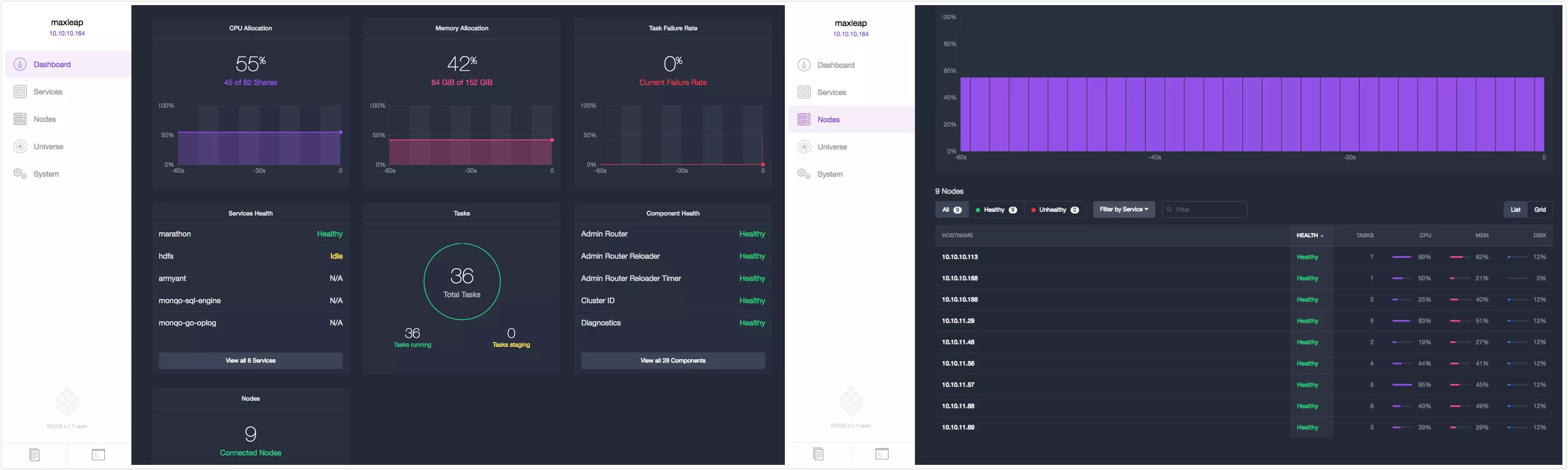
(DC/OS图示)
DC/OS默认也给我们安装了mesos-dns,我们可以使用DNS的A记录轮询来实现简陋的服务发现。通过marathon部署服务现在可以直接使用服务名.marathon.mesos直接定位服务所在节点。
在某些场合下这已经足够好用。Universe集成的HDFS也使用了DNS来定位各类型的节点,这样带来的很大的方便就是像core-site.xml,hdfs-site.xml这样的配置文件就相对稳定(之前我们使用主机hostname来管理,当节点发生变动时需要所有程序变更配置文件)。
接下来我们开始尝试改造之前的基础服务。
HDFS
综上的几个优点,我们将之前Spark的HDFS切换到Universe提供的版本,这个版本的好处是其自己实现了一个Mesos的framework来实现HA,其数据也使用了Mesos的持久化卷。美中不足的是其使用了mesos原生的隔离,而没有使用docker,鉴于国内的网络环境,其下载速度惨不忍睹。为此我们搭建了Universe私服,改写了所有的资源文件指向到内网,加快了部署速度。官方的教程很详细,这里是传送门。
HBase
对于HBase,我们也重新制作了docker镜像。以下是Dockerfile:
# 基于debian的oracle-jdk8
FROM 10.10.10.160:8010/zero/java:8
MAINTAINER wcai wcai@maxleap.com
ENV \
HBASE_VERSION="1.2.1" \
HADOOP_VERSION="2.5.2" \
HBASE_HOME="/hbase" \
HADOOP_CONF_DIR="/etc/hadoop" \
JAVA_LIBRARY_PATH="/usrb/hadoop" \
HBASE_CLASSPATH="/etc/hadoop" \
HBASE_MANAGES_ZK="false"
RUN \
apt-get update -y && \
apt-get install curl -y && \
mkdir -p ar/log/hbase && \
curl -o /tmp/hbase.tar.gz http://mirrors.aliyun.com/apache/hbase/${HBASE_VERSION}/hbase-${HBASE_VERSION}-bin.tar.gz && \
tar xvzf /tmp/hbase.tar.gz -C /tmp/ && \
rm -f /tmp/hbase.tar.gz && \
mv /tmp/hbase* ${HBASE_HOME} && \
rm -rf ${HBASE_HOME}/docs \
${HBASE_HOME}/bin/*.cmd \
${HBASE_HOME}/conf/*.cmd \
${HBASE_HOME}/*.txt && \
curl -o /tmp/hadoop.tar.gz http://mirrors.aliyun.com/apache/hadoop/core/hadoop-${HADOOP_VERSION}/hadoop-${HADOOP_VERSION}.tar.gz && \
tar xvzf /tmp/hadoop.tar.gz -C /tmp && \
rm -f /tmp/hadoop.tar.gz && \
mv /tmp/hadoop* /tmp/hadoop && \
mv /tmp/hadoopb/native /usrb/hadoop && \
rm -rf /tmp/hadoop && \
mkdir -p ${HADOOP_CONF_DIR} && \
apt-get remove curl -y && \
apt-get clean && \
rm -rf arb/aptsts/* /tmp/* ar/tmp/*
WORKDIR ${HBASE_HOME}
# 默认集成的hdfs配置,也可通过marathon的uris挂载进去。
COPY ./conf/* /etc/hadoop/
ENTRYPOINT [ "bin/hbase" ]
HMaster的marathon配置范例:
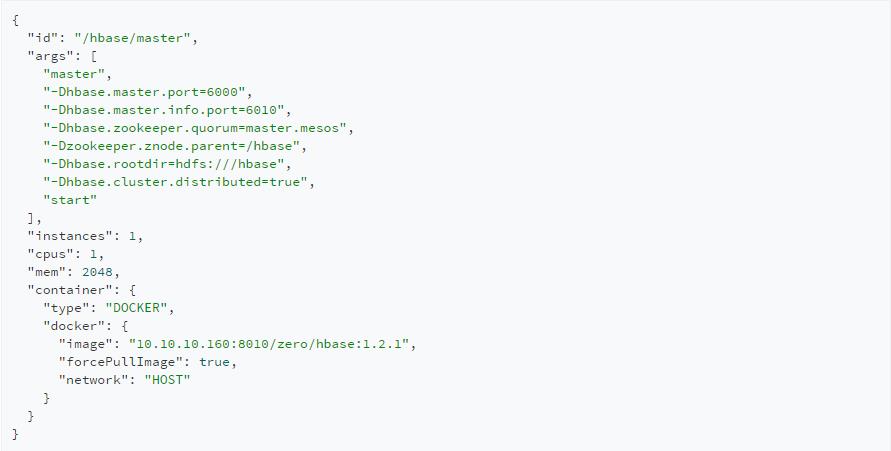
HRegion的marathon配置范例:
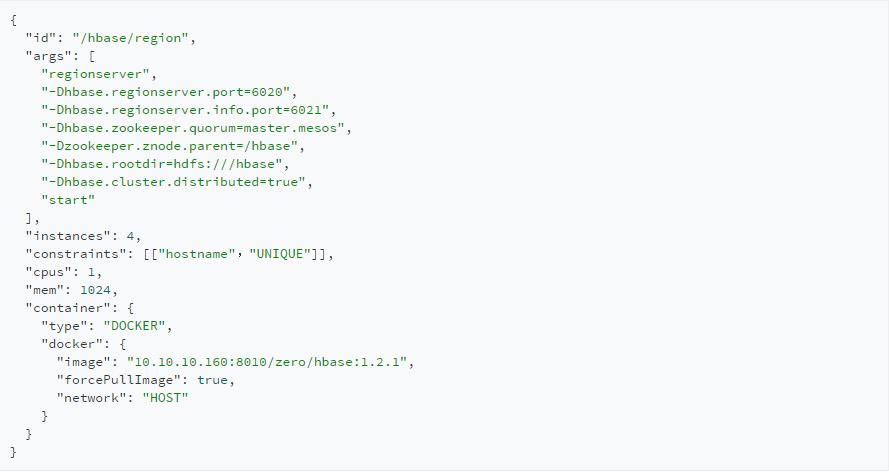
以上仅为范例,其他类型的实例也可类似启动,如backup,thrift2,rest等,在此略过。
另外可以进一步定制entrypoint,启动的端口可以通过marathon管理的PORT?来定义。甚至可以让marathon给你随机安排端口。
Spark
虽然Universe自带了Spark的dispatcher服务,默认使用了dist-url的方式,但我们想让Spark运行时全部在docker中。(老板~ 再来几串Dockerfile)
首先是mesos基础镜像
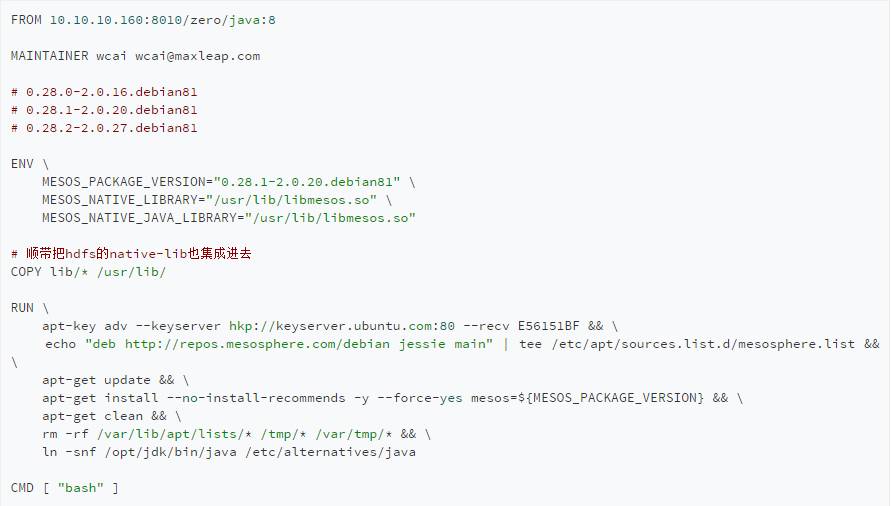
然后是Spark的
FROM 10.10.10.160:8010/zero/mesos:0.28.1
MAINTAINER wcai wcai@maxleap.com
ENV \
SPARK_HOME="/opt/spark" \
SPARK_VERSION="2.0.0" \
HADOOP_VERSION="2.6"
RUN \
apt-get update -y && \
apt-get install curl -y && \
curl -o /tmp/spark.tar.gz http://mirrors.aliyun.com/apache/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
tar xvzf /tmp/spark.tar.gz -C /opt && \
mv /opt/spark* /opt/spark && \
rm -rf /tmp/spark.tar.gz \
$SPARK_HOME/jars/*yarn*.jar \
$SPARK_HOME/bin/*.cmd \
$SPARK_HOME/data \
$SPARK_HOME/examples \
$SPARK_HOME/python \
$SPARK_HOME/yarn \
$SPARK_HOME/R \
$SPARK_HOMEcenses \
$SPARK_HOME/CHANGES.txt \
$SPARK_HOME/README.md \
$SPARK_HOMETICE \
$SPARK_HOME/LICENSE \
$SPARK_HOME/conf/* && \
apt-get remove curl -y && \
apt-get clean && \
rm -rf arb/aptsts/* /tmp/* ar/tmp/*
# 如果你想加入一些自己的配置
COPY ./spark-defaults.conf $SPARK_HOME/conf/spark-defaults.conf
ENV TZ=Asia/Shanghai
WORKDIR $SPARK_HOME
CMD [ "bash" ]
最后是spark-mesos-dispatcher的
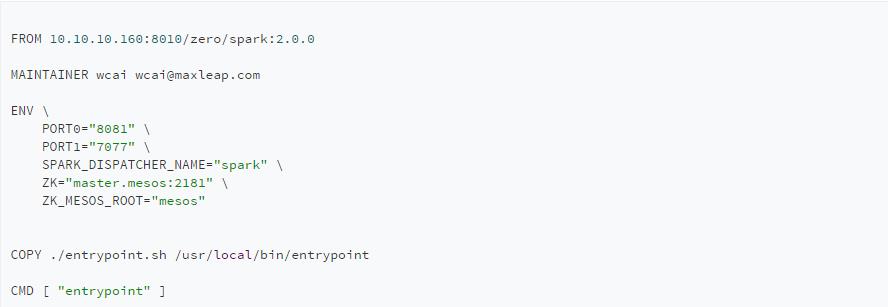
其中的entrypoint脚本
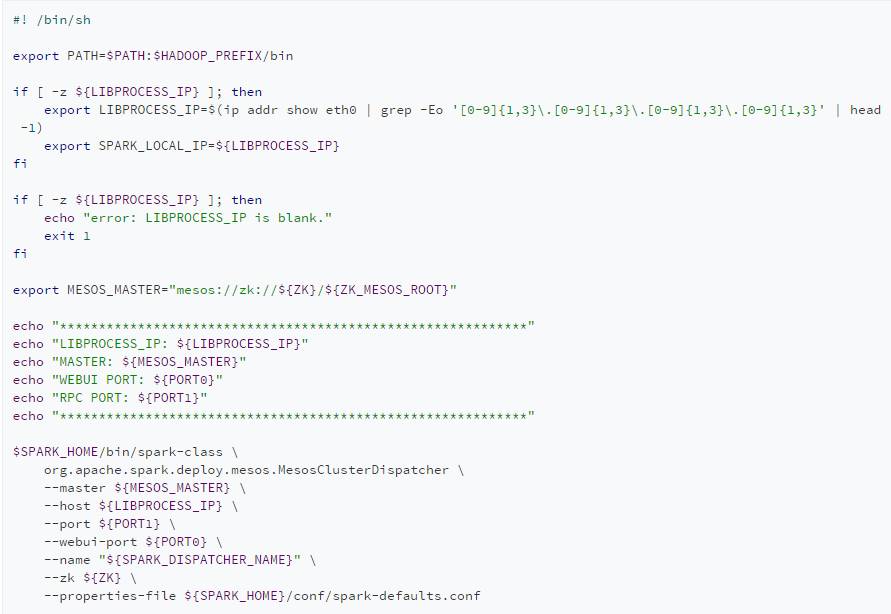
大功告成,只需要在marathon中启动dispatcher。spark-submit时指定spark.mesos.executor.docker.image为spark的docker镜像即可。你可以制作不同版本的spark镜像,随意切换。(麻麻再也不用担心我追不上spark官方的升级速度了)
三
marathon-lb,你值得拥有
Mesos的资源专供数据分析团队使用是相当浪费的。为此团队开始尝试将公司的其他服务陆续迁移进来。
公司已有的Rest API大多都是docker容器形式部署在各个服务器上。本来的计划是通过marathon部署,使用域名做服务发现,然后nginx反向代理到公网。但实际实施中踩了个坑。因为nginx的配置域名的upstream很成问题,一旦指向的ip变动就会导致解析失败。尝试使用网上的各种方法(如配置resolver设置upstrem变量,改用tengine的ngx_http_upstream_dynamic_module) 都无法完美解决这个问题。
最后团队还是决定引入marathon-lb,替代原先基于mesos-dns的服务发现。
marathon-lb其实是一个HAProxy的包装,它能动态地绑定marathon的服务。我们以internal形式部署,某个服务如果需要做服务发现负载匀衡,只需要加一个label为HAPROXY_GROUP: internal即可,非常方便。这样最终的形态就变成如下的架构:
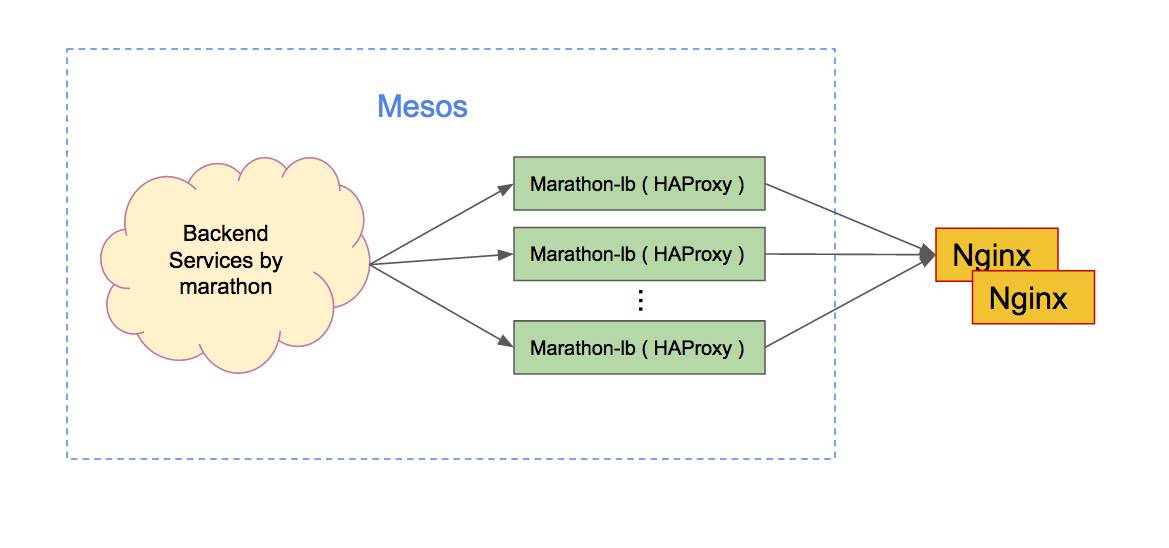 (部署架构)
(部署架构)
在小范围的服务迁移测试稳定之后,团队陆续将一些其他服务迁移过来,也释放了一些服务器资源,将这些空闲的服务器也重新回收纳入到我们的Mesos集群中。
在此之后,维护这些服务变得简单便捷,泡杯咖啡,点点鼠标就可以轻松搞定,运维压力减小了很多。
未来的愿景(补轮子篇)
拥有了以上的这些基础架构服务之后,一切都可以运转起来。但总有一些痛点需要我们自己造轮子去解决。
1
作业管理
当你有大量的Spark批处理作业时,一个很头疼的事情就是如何去调度这些作业。
以前我们通过chronos来做执行管理,但这个工具太过简陋,对于cluster-mode下的spark作业,如果你想定义依赖,则需要使用它的异步回调来通知作业已完成,这样一来无可避免需要侵入业务代码。(程序猿表示如果要妥协强行写这些跟业务半点关系都没有的代码,我选择狗带)
我们需要一个零侵入的Spark通用作业流程解决方案。为此我们自己实现了一个小项目(Armyant),旨在解决这个问题。
整体架构很简单,通过Activiti做流程引擎,Quartz做定时调度,Zookeeper来做状态通知:
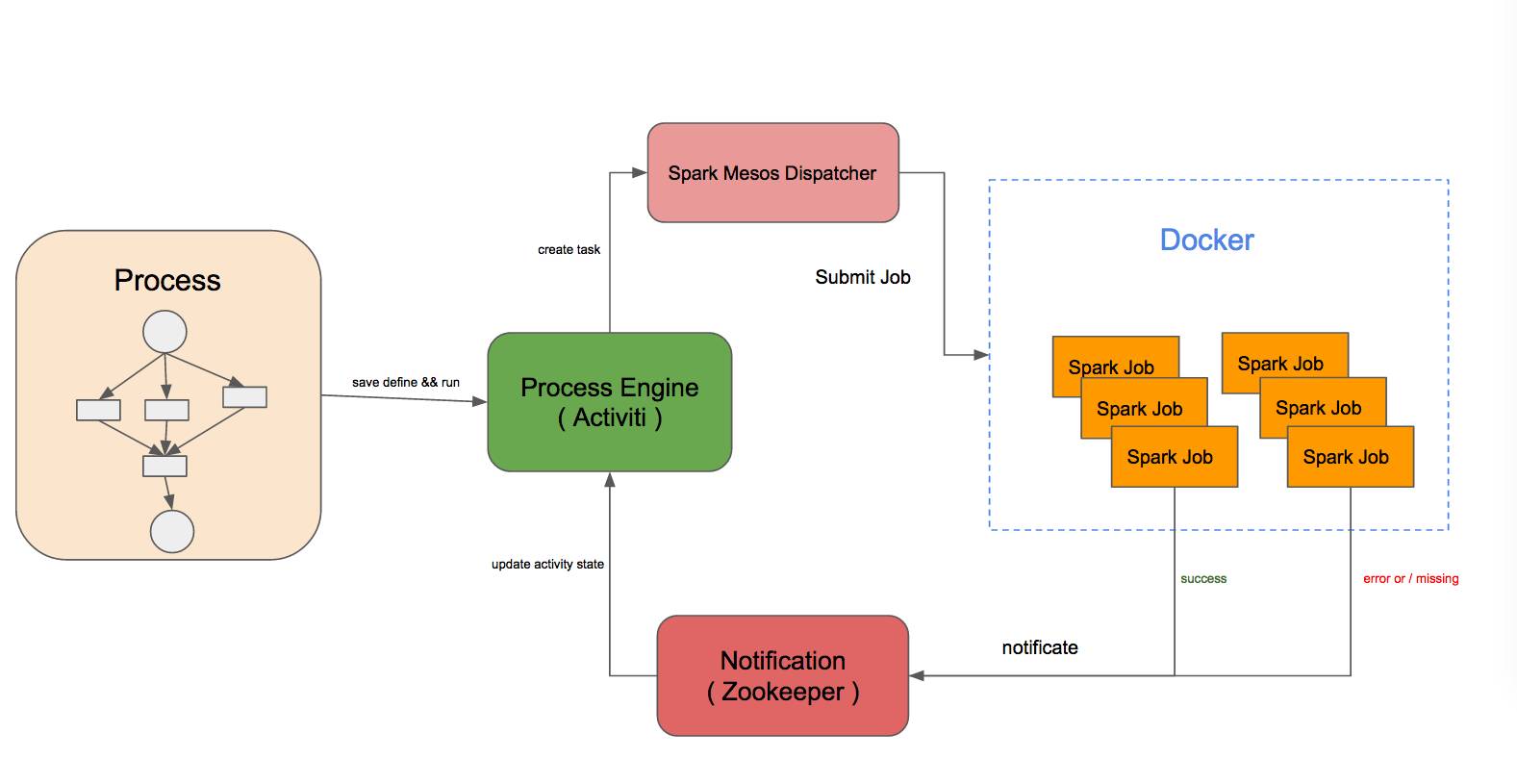
(armyant架构图)
外加一套易用的UI,第一个版本就能顺利跑起来。
(armyant图示1)
后续又实现了一个mesos framework,这样也可以定义一些one-off形式的任意docker任务。接着再向上封装一下,包装一层任意的Java服务也很方便。当然mesos生态圈其实也有很多专门为one-off形式的作业而生的工具,如eremetic等等。
(armyant图示2)
2
监控报警
虽然DC/OS社区版可以查看当前的运行状态,但它没有监控报警相关的功能(天下没有免费的午餐)。目前我们在每个节点上部署了传统的nagios。
在接下来的阶段,团队也会对此做进一步的探索。
3
日志系统
DC/OS再配合mesos自带的日志其实已经很大程度上方便了查看日志的需求。甚至DC/OS本身也可以接入ELK。但我们期望有更高级的日志分类收集,这需要定制一些收集处理模块。团队的大神亲自操刀正在实现这些高级的功能,随着业务的扩张,能有一个可以灵活定制的日志处理系统是很有好处的。我的Leader也常说,大厂和小厂的东西,区别就在于大厂的监控报警运维系统做得非常完善易用。
文末最后,作为一个初创小团队,笔者觉得Mesos对我们的利好是不言而喻的。也希望让我们的集群更加稳定健壮,来支撑我们日益增长的业务系统。
声明
CSDN作者原创投稿文章,未经许可,禁止转载。
本文系力谱宿云LeapCloud旗下MaxLeap团队_数据分析组成员:蔡伟伟 【原创】
以上是关于飞驰在Mesos的涡轮引擎上的主要内容,如果未能解决你的问题,请参考以下文章