Spark/Mesos 发明人教你用决策树优化视频流媒体用户体验质量
Posted 智能运维前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark/Mesos 发明人教你用决策树优化视频流媒体用户体验质量相关的知识,希望对你有一定的参考价值。
我们今天讲解论文是发表在计算机网络领域的顶级会议ACM SIGCOMM 2013 的文章《Developing a Predictive Model for Internet Video Quality of Experience》。从海量运维数据中获得洞见,并终为实际系统进一步优化提供有效可行的方案,是每一个运维人员的最终目标。今天小编就带大家看看我们的老朋友Spark/Mesos发明人之一Ion Stoica 等作者是如何通过决策树建立预测模型,来改善视频流媒体用户体验质量。
性能参数和KPI间的复杂关系:我们直观感觉,更高的视频比特率应该会导致更高的用户参与度,但是在上篇文章中,我们也看到视频比特率和用户参与度之间并非简单的单调关系。这是因为, 当比特率高除了网络条件所能支撑的程度时, 就会导致视频缓冲率的增加,反而导致了用户参与度的下降。
性能参数间的依赖关系:作者在文中提出,较高的视频比特率,往往导致较高的缓冲比率,同时也会由于缓存需求的增高,而导致更长的加载时间,因此并非较高视频比特率就会意味着更好的视频流媒体质量。
混杂因素影响:除了视频流媒体性能参数,还会有一些混杂因素影响着用户参与度,例如用户兴趣,视频内容等。而其也往往会影响性能参数,因此对于不同的混杂因素,视频流媒体性能参数和KPI之间的关系也可能是不同的。
决策树——帮你处理多维复杂数据关系
那么面对性能参数和KPI指标之间的复杂关系,如何选择合适的机器学习模型对于视频流媒体用户参与度(KPI)进行建模呢?作者意识到,机器学习领域的决策树模型可以很好的帮助我们解决这个问题。
相比于线性回归这类简单的方法,决策树并不假定参数之间的线性关系,因此可以更好的处理复杂的参数关系。
不同于神经网络等这类复杂的黑箱结构,决策树最终给出的IF-THEN的预测规则,往往可以提供给使用者直观可行的指导,这恰恰就是我们所需要的。
决策树
决策树是附加概率结果的一个树状的决策图,是直观的运用统计概率的分析方法。机器学习中决策树是一个预测模型,它表示对象属性和对象值之间的一种映射,树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果。
决策树实例 下图中是基于本论文中的数据构造出的一棵简单的决策树,用于预测用户参与度的高低。树中的每个内部节点都表示一个属性条件判断,叶子节点表示用户参与度的高低。例如:用户甲观看某个视频,视频的Average Bitrate (平均比特率)为low (低),Buff Ratio(缓冲比)为low,Rate of buffering(缓冲事件频率)为low。通过决策树的根节点判断,用户甲符合左边分支 (平均比特率为low);再判断缓冲比,用户甲符合左边分支;然后判断缓冲事件频率,用户甲符合左边分支 ,该用户落在“Eng=high”的叶子节点上。所以预测用户甲在这次观看视频中,其用户参与度为high。
构建决策树的过程主要包含以下三个步骤:
特征选择:其指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准,从而衍生出不同的决策树算法。
决策树生成: 根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。
剪枝:决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
特征选择标准由决策树学习过程,我们可以看到,建立一棵决策树的重点在于选择恰当的特征选择标准。选择一个合适的特征作为判断节点,可以快速的分类,减少决策树的深度。最理想的情况是,通过特征的选择能把不同类别的数据集贴上对应类标签。因此这里特征选择的目标使得分类后的数据集比较纯。这里小编将对论文中使用的特征选择方式——信息增益进行介绍。信息熵表示的是不确定度。均匀分布时,不确定度最大,此时熵就最大。当选择某个特征对数据集进行分类时,分类后的数据集信息熵会比分类前的小,其差值表示为信息增益。信息增益可以衡量某个特征对分类结果的影响大小 (注:相关信息论内容,具体可参见上篇推文)。假设在样本数据集 D 中,混有 c 种类别的数据。构建决策树时,根据给定的样本数据集选择某个特征值作为树的节点。首先在数据集中,可以计算出该数据中的信息熵:
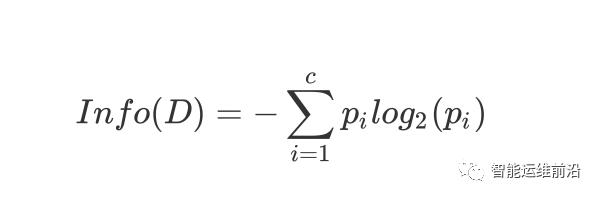
其中 D 表示训练数据集,c 表示数据类别数,Pi 表示类别 i 样本数量占所有样本的比例。对应数据集 D,选择特征 A 作为决策树判断节点时,在特征 A 作用后的信息熵的为InfoA(D),计算如下:
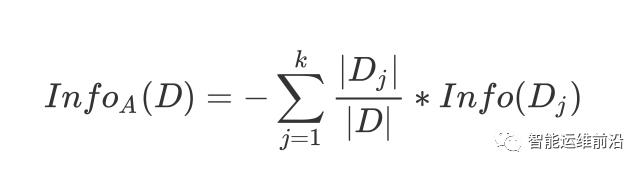
其中 k 表示样本 D 被分为 k 个部分。信息增益表示数据集 D 在特征 A 的作用后,其信息熵减少的值。公式如下:
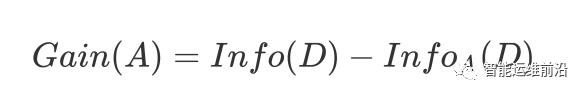
对于决策树节点最合适的特征选择,就是 Gain(A) 值最大的特征。
实际应用——视频流媒体用户体验质量预测决策树本身为一种有监督分类模型,因此在应用在视频流媒体用户体验质量预测这一实际问题时,需要对于原数据进行相应预处理。
KPI指标离散化:由前面的介绍我们可以看到,决策树是一种分类模型,但是作者在文中使用的用户体验质量指标 (KPI),如用户观看时间,却往往是一些连续的值,因此可以根据设定的类别数目和相应对阈值,对于KPI指标离散化,相应的就可以实现对于原始数据的分类。例如,我们可以根据用户观看视频的百分比,按照0-20%,20- 40%,40-60%,60-80%,80-100%的分类标准,将原始数据分为5类,并建立相应的预测模型。
性能指标粗粒度离散化:对于连续的性能指标参数,如视频加载时间(Join time),缓冲比 (BufRatio),我们也同样可以通过类似处理KPI指标的方式对于数据原始数据进行处理。但是作者在文中指出,对于高维海量数据集,细粒度的划分性能指标,会使得整个决策树变得庞大复杂,而失去其本身直观且具有指导作用的价值。因此作者在文中采用了对于性能指标较粗粒度的划分方式。例如将Average Bitrate(平均比特率)划分为Very Low,Low,High三类,将Buff Ratio(缓冲比),Rate of buffering(缓冲事件频率)为low划分为Low和High两类。
树的后剪枝策略:使用新的叶子节点替换子树,该节点的预测类由子树数据集中的多数类决定。通过这中方式可以使得生成的决策树变得更加简单,从而更具有指导价值。
混杂因素作用下的决策树模型
如同我们在文章开头提到的,除了视频流媒体性能参数,还会有一些混杂因素,如视频类型,连接方式等,影响着用户参与度。而这些混杂因素也同时会影响视频流媒体性能参数,从而在不同的混杂因素下,性能参数和用户参与度之间可能会呈现出不同的关系。在论文中,作者采用相对信息增益,决策树结构和容忍水平三种方法,从视频,用户,时间三个角度可能存在的混杂因素进行了检验,并且发现视频类型,用户设备类型,网络连接方式,观看时间是对于结果影响最大的混杂因素(注:具体分析可参见原文)。对于这些混杂因素的影响,如何建立决策树的模型,是作者这里面对的主要问题,这里作者提出了两种解决方案:
将混杂因素直接作为决策树模型输入参数,训练一个针对全部数据集的统一的模型
根据混杂因素对于数据进行分割,对不同混杂因素下的数据集,分别建立决策树模型。
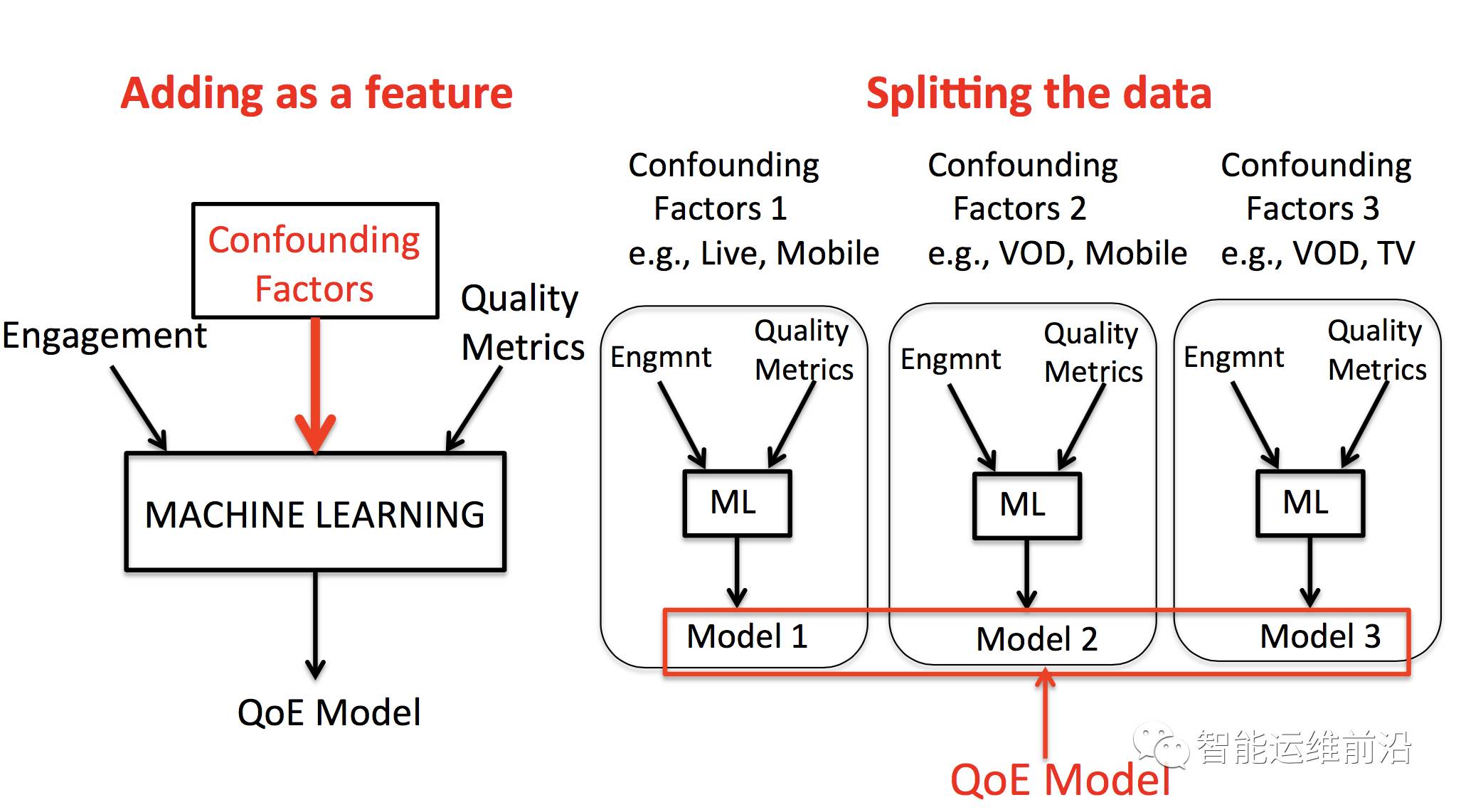
而在文中作者指出,尽管分割数据集,会面临高维数据集下,某一种数据集样本数过少的问题,但是通过事先对于混杂因素的筛选和视频流媒体的海量数据,可以很好的解决这个问题。并且相比于训练一个统一的模型,分割数据集的做法,在实际场景下更具有指导价值。例如,我们很有可能会想要知道,对于移动用户,视频流媒体性能指标和用户参数度之间的关系,从而可以针对移动端用户设计更好的比特率调整算法。另外作者也对这两种方法建立的决策树模型的准确性进行了对比,从下图中我们可以看到,针对混杂因素,分割数据集可以更有效的提升预测模型的准确度。
效果评估
为了评估用户参与度的预测模型的实际效果,作者在基于实际视频流媒体流量的仿真场景下,对比了采用不同方法调整视频比特率的效果,从下图中可以看到,对于点播视频和直播视频,基于决策树的用户参与度预测模型,相比于在不同场景下的最优比特率选择策略(注:具体可见原文介绍),用户参与度都有着约20%的提高。
由此我们可以看到通过决策树建立的视频流媒体预测模型,可以有效的指导实际场景下对于视频比特率选择,从而获得更高的用户参数度。
小结
在海量历史运维数据中提炼关键特征信息,训练基于机器学习的、可解释的预测模型,从而对实际场景提供可行的优化策略,是智能运维的重要目标之一。面对性能指标和KPI之间的复杂关系以及可能存在的混杂因素的影响,Spark/Mesos发明人之一Ion Stoica在Developing a Predictive Model for Internet Video Quality of Experience (SIGCOMM2013)这篇论文中,通过决策树建立对于视频流媒体用户参与度(KPI)的预测模型,来指导关键性能指标的优化策略,最终有效地改善视频流媒体用户体验质量,这是基于机器学习的数据分析方法在运维领域一次有意义的尝试。这种数据驱动的运维方法,也将会在更多场景下发挥更大的作用。
想见更多精彩分析,点击阅读原文,获取论文原稿:
以上是关于Spark/Mesos 发明人教你用决策树优化视频流媒体用户体验质量的主要内容,如果未能解决你的问题,请参考以下文章