:Mesos的体系结构和工作流
Posted 锐智之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:Mesos的体系结构和工作流相关的知识,希望对你有一定的参考价值。
来源:http://www.infoq.com/cn/articles/analyse-mesos-part-02
在本系列的第一篇文章中,我简单介绍了Apache Mesos的背景、架构,以及它在数据中心资源管理中的价值。本篇文章将深入剖析Mesos的技术细节和组件间的流程,以便大家更好地理解为什么Mesos是数据中心操作系统内核的重要候选者。文中所述的大部分技术细节都来自Ben Hindman团队2010年在加州大学伯克利分校时发表的白皮书。 顺便说一句,Hindman已经离开Twitter去了Mesosphere,着手建设并商业化以Mesos为核心的数据中心操作系统。在此,我将重点放在提炼白皮书的主要观点上,然后给出一些我对相关技术所产生的价值的思考。
Mesos流程
接着上一篇文章说。并结合前述的加州大学伯克利分校的白皮书以及Apache Mesos网站,开始我们的讲述:
我们来研究下上图的事件流程。上一篇谈到,Slave是运行在物理或虚拟服务器上的Mesos守护进程,是Mesos集群的一部分。Framework由调度器(Scheduler)应用程序和任务执行器(Executor)组成,被注册到Mesos以使用Mesos集群中的资源。
Slave 1向Master汇报其空闲资源:4个CPU、4GB内存。然后,Master触发分配策略模块,得到的反馈是Framework 1要请求全部可用资源。
Master向Framework 1发送资源邀约,描述了Slave 1上的可用资源。
Framework的调度器(Scheduler)响应Master,需要在Slave上运行两个任务,第一个任务分配资源,第二个任务分配资源。
最后,Master向Slave下发任务,分配适当的资源给Framework的任务执行器(Executor),接下来由执行器启动这两个任务(如图中虚线框所示)。 此时,还有1个CPU和1GB的RAM尚未分配,因此分配模块可以将这些资源供给Framework 2。
资源分配
为了实现在同一组Slave节点集合上运行多任务这一目标,Mesos使用了隔离模块, 该模块使用了一些应用和进程隔离机制来运行这些任务。 不足为奇的是,虽然可以使用虚拟机隔离实现隔离模块,但是Mesos当前模块支持的是容器隔离。 Mesos早在2009年就用上了Linux的容器技术,如cgroups和Solaris Zone,时至今日这些仍然是默认的。 然而,Mesos社区增加了Docker作为运行任务的隔离机制。 不管使用哪种隔离模块,为运行特定应用程序的任务,都需要将执行器全部打包,并在已经为该任务分配资源的Slave服务器上启动。 当任务执行完毕后,容器会被“销毁”,资源会被释放,以便可以执行其他任务。
我们来更深入地研究一下资源邀约和分配策略,因为这对Mesos管理跨多个Framework和应用的资源,是不可或缺的。 我们前面提到资源邀约的概念,即由Master向注册其上的Framework发送资源邀约。 每次资源邀约包含一份Slave节点上可用的CPU、RAM等资源的列表。 Master提供这些资源给它的Framework,是基于分配策略的。分配策略对所有的Framework普遍适用,同时适用于特定的Framework。 Framework可以拒绝资源邀约,如果它不满足要求,若此,资源邀约随即可以发给其他Framework。 由Mesos管理的应用程序通常运行短周期的任务,因此这样可以快速释放资源,缓解Framework的资源饥饿; Slave定期向Master报告其可用资源,以便Master能够不断产生新的资源邀约。 另外,还可以使用诸如此类的技术, 每个Fraamework过滤不满足要求的资源邀约、Master主动废除给定周期内一直没有被接受的邀约。
分配策略有助于Mesos Master判断是否应该把当前可用资源提供给特定的Framework,以及应该提供多少资源。 关于Mesos中使用资源分配以及可插拔的分配模块,实现非常细粒度的资源共享,会单独写一篇文章。 言归正传,Mesos实现了公平共享和严格优先级(这两个概念我会在资源分配那篇讲)分配模块, 确保大部分用例的最佳资源共享。已经实现的新分配模块可以处理大部分之外的用例。
集大成者
现在来回答谈及Mesos时,“那又怎样”的问题。 对于我来说,令人兴奋的是Mesos集四大好处于一身(概述如下),正如我在前一篇文章中所述,我目测Mesos将为下一代数据中心的操作系统内核。
效率 - 这是最显而易见的好处,也是Mesos社区和Mesosphere经常津津乐道的。
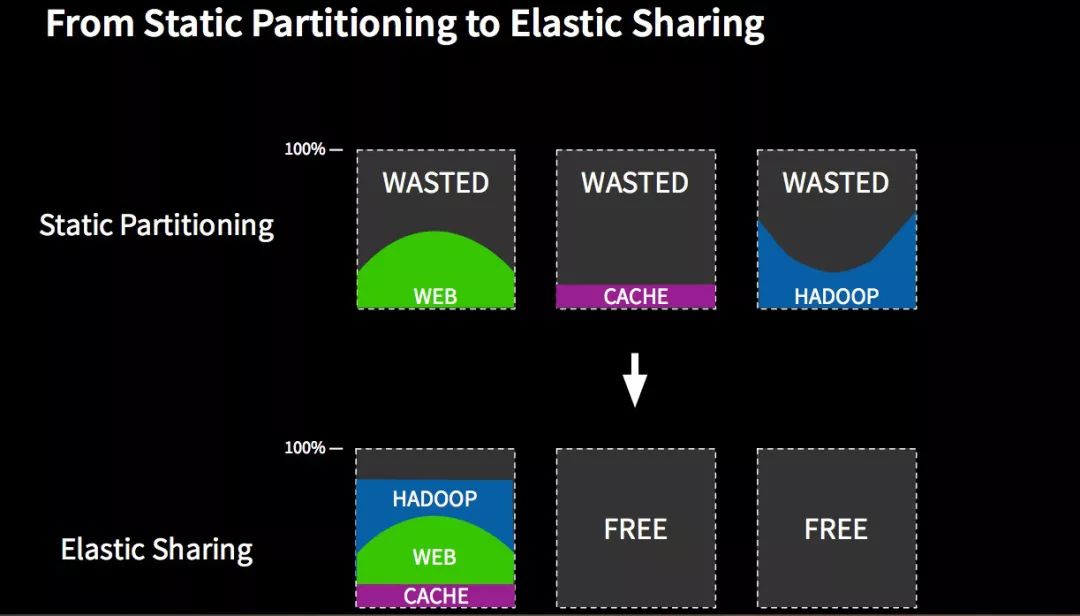
上图来自Mesosphere网站,描绘出Mesos为效率带来的好处。如今,在大多数数据中心中,服务器的静态分区是常态,即使使用最新的应用程序,如Hadoop。这时常令人担忧的是,当不同的应用程序使用相同的节点时,调度相互冲突,可用资源互相争抢。静态分区本质上是低效的,因为经常会面临,其中一个分区已经资源耗尽,而另一个分区的资源却没有得到充分利用,而且没有什么简单的方法能跨分区集群重新分配资源。使用Mesos资源管理器仲裁不同的调度器,我们将进入动态分区/弹性共享的模式,所有应用程序都可以使用节点的公共池,安全地、最大化地利用资源。 一个经常被引用的例子是Slave节点通常运行Hadoop作业,在Slave空闲阶段,动态分配给他们运行批处理作业,反之亦然。 值得一提的是,这其中的某些环节可以通过虚拟化技术,如VMware vSphere的分布式资源调度(DRS)来完成。 然而,Mesos具有更精细的粒度,因为Mesos在应用层而不是机器层分配资源,通过容器而不是整个虚拟机(VM)分配任务。 前者能够为每个应用程序的特殊需求做考量,应用程序的调度器知道最有效地利用资源; 后者能够更好地“装箱”,运行一个任务,没有必要实例化一整个虚拟机,其所需的进程和二进制文件足矣。
敏捷 - 与效率和利用率密切相关,这实际上是我认为最重要的好处。 往往,效率解决的是“如何花最少的钱最大化数据中心的资源”,而敏捷解决的是“如何快速用上手头的资源。” 正如我和我的同事Tyler Britten经常指出,IT的存在是帮助企业赚钱和省钱的;那么如何通过技术帮助我们迅速创收,是我们要达到的重要指标。 这意味着要确保关键应用程序不能耗尽所需资源,因为我们无法为应用提供足够的基础设施,特别是在数据中心的其他地方都的资源是收费情况下。
可扩展性 - 为可扩展而设计,这是我真心欣赏Mesos架构的地方。 这一重要属性使数据可以指数级增长、分布式应用可以水平扩展。 我们的发展已经远远超出了使用巨大的整体调度器或者限定群集节点数量为64的时代,足矣承载新形式的应用扩张。
Mesos可扩展设计的关键之处是采用两级调度架构。 使用Framework代理任务的实际调度,Master可以用非常轻量级的代码实现,更易于扩展集群发展的规模。 因为Master不必知道所支持的每种类型的应用程序背后复杂的调度逻辑。 此外,由于Master不必为每个任务做调度,因此不会成为容量的性能瓶颈,而这在为每个任务或者虚拟机做调度的整体调度器中经常发生。
模块化 - 对我来说,预测任何开源技术的健康发展,很大程度上取决于围绕该项目的生态系统。 我认为Mesos项目前景很好,因为其设计具有包容性,可以将功能插件化,比如分配策略、隔离机制和Framework。将容器技术,比如Docker和Rocket插件化的好处是显而易见。但是我想在此强调的是围绕Framework建设的生态系统。将任务调度委托给Framework应用程序,以及采用插件架构,通过Mesos这样的设计,社区创造了能够让Mesos问鼎数据中心资源管理的生态系统。因为每接入一种新的Framework,Master无需为此编码,Slave模块可以复用,使得在Mesos所支持的宽泛领域中,业务迅速增长。相反,开发者可以专注于他们的应用和Framework的选择。 当前而且还在不断地增长着的Mesos Framework列表参见此处以及下图:
总结
在接下来的文章中,我将更深入到资源分配模块,并解释如何在Mesos栈的各级上实现容错。 同时,我很期待读者的反馈,特别是关于如果我打标的地方,如果你发现哪里不对,请反馈给我。 我也会在Twitter响应你的反馈,请关注 @hui_kenneth。
下一篇是关于Mesos的持久性存储和容错的。
查看英文原文: DIGGING DEEPER INTO APACHE MESOS
以上是关于:Mesos的体系结构和工作流的主要内容,如果未能解决你的问题,请参考以下文章