干货!OpenStack云主机网络异常丢包问题深入解析
Posted 苏研大云人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货!OpenStack云主机网络异常丢包问题深入解析相关的知识,希望对你有一定的参考价值。
点击关注哦
OpenStack云主机网络异常丢包问题的深入解析
某云主机在访问外网时,第一次DNS请求数据包在发送过程中被异常丢弃,导致每次访问都会有卡顿5秒才能完成的诡异现象,本文主要阐述这一现象背后的根本原因以及分析问题的具体方法。
问题描述

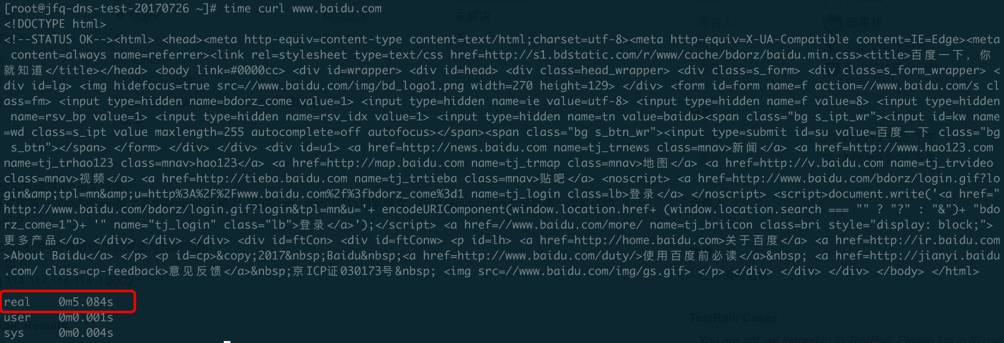
在openstack集群环境下某虚机访问外部网络时会发生延时现象,大概延迟5秒左右才会得到回应,例如使用curl命令访问百度网址结果耗时5秒多才结束:
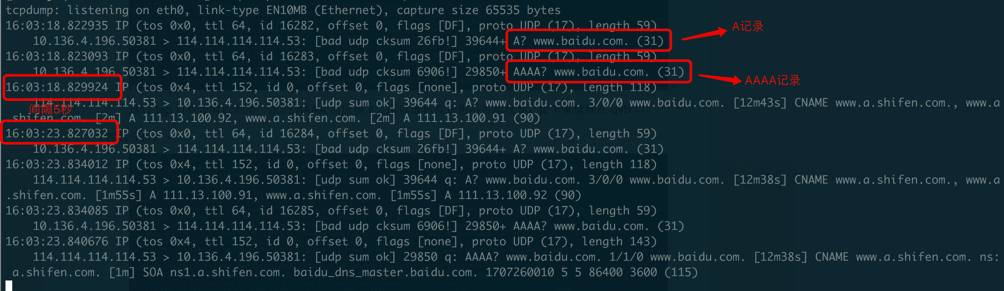
首先在虚机上通过抓包发现,在访问百度网址时,DNS请求耗时接近5秒:
分析过程
如果要弄清楚回应报文丢失的原因,我们可以先在计算节点上抓包分析,因为虚机到外网出去的包首先是经过的计算节点,包路径参考下图:
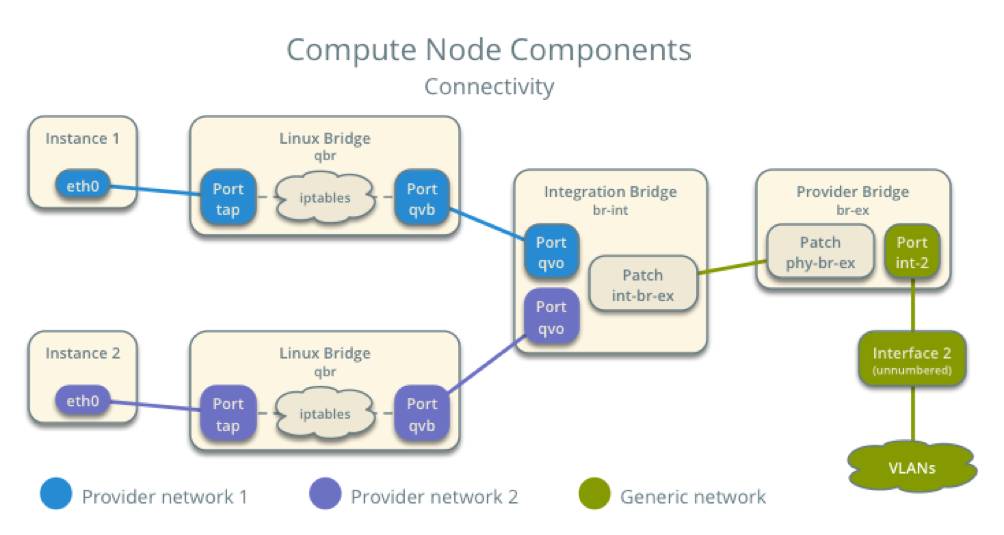
如图,虚机(instance)出来的包一开始经过的是linux bridge,对应的网桥为qbr,端口分别为tap及qvb口,首先在tap口抓包分析:
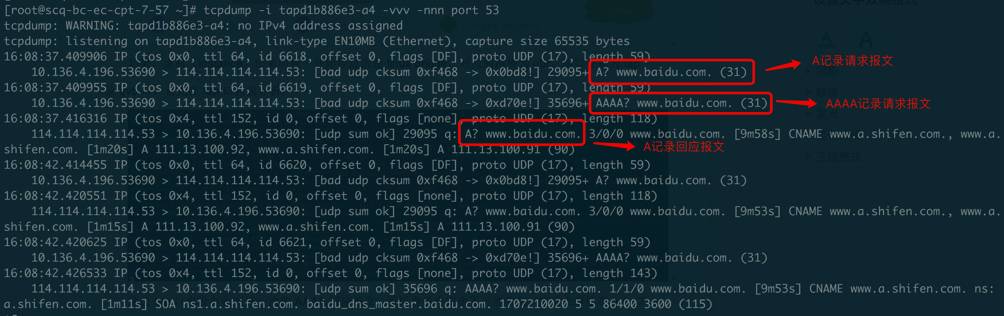
这边tap口跟在虚机里抓的包没啥区别,也没有收到第一次的AAAA回应报文,所以虚机肯定也不可能收到,接下来继续在qvb口抓包分析:
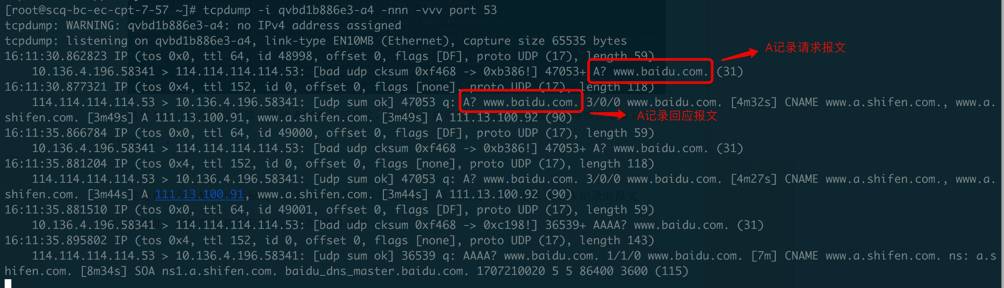
这边也没有AAAA记录回应报文,但是发出去的包只有A记录请求报文,而AAAA记录请求报文却不见了?其实细想一下,肯定是因为linux bridge丢弃了第二个AAAA请求报文,这就解释了为什么一直收不到AAAA记录回应报文的原因,不是回来的包丢了,而是出去的包被丢了。至于为什么出去的AAAA记录请求报文被丢弃,难道是防火墙挡掉了?
首先排查防火墙的原因,因为计算节点上默认设定了安全组规则,是通过iptables实现的,所以先清空防火墙规则:
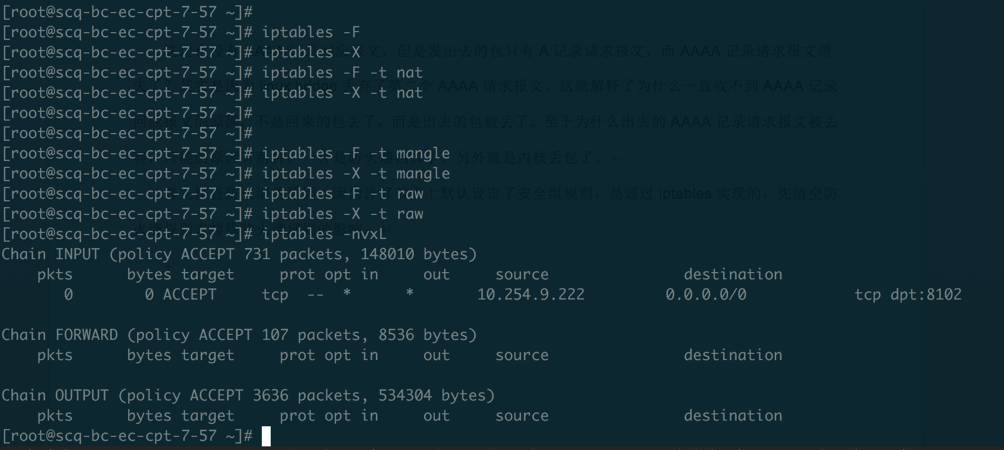
在禁用所有防火墙规则后,虚机curl访问百度网址依然有5秒超时的问题,所以排除了防火墙的原因,如果不是防火墙丢掉的包,那么到底是什么原因导致丢包的呢?
既然是linux bridge丢的包,我们先从这边入手,linux网桥有一个bridge-nf-call-iptables开关,可以先尝试将其关闭,目的是将要转发的数据包直接走二层处理,不经过三层,既不受iptables规则的约束:
[root@scq-bc-ec-cpt-7-57 ~]# echo 0 > /proc/sys/net/bridge/bridge-nf-call-iptables
[root@scq-bc-ec-cpt-7-57 ~]# cat /proc/sys/net/bridge/bridge-nf-call-iptables
0
此时,从虚机访问百度,5秒超时的问题消失了,这次DNS解析在1秒之内完成:
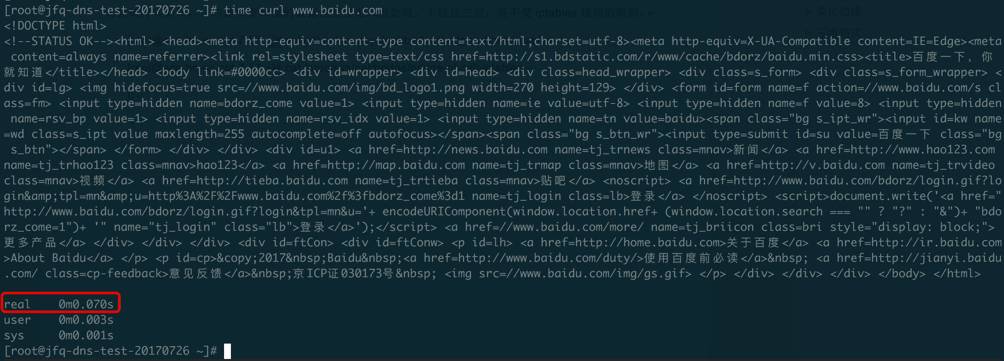
同时,在计算节点的qvb口抓包分析,DNS的AAAA记录请求及回应报文都有了:
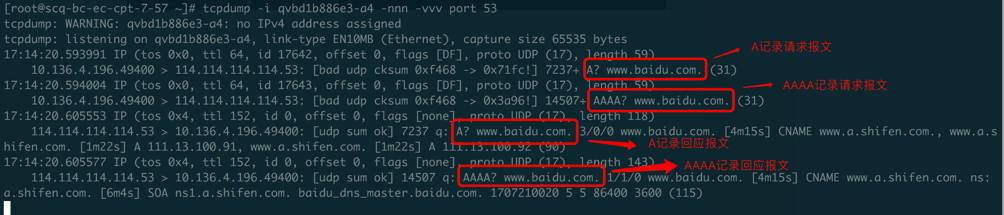
总结一下,如果关掉计算节点上linux网桥的bridge-nf-call-iptables,DNS请求延时的现象就会消失,但是我们不能这样做,因为openstack的安全组的实现依赖于它,如果不开启它,基于网桥的iptables规则无法生效,安全组的功能就不能用了,所以真正解决问题的方法是要找到开启bridge-nf-call-iptables时导致DNS丢包的原因。
这样又回到原点了,但是我们唯一可以确定的是内核丢的包,所以可以先利用dropwatch找一下丢包的点:

结果发现每次在虚机里面尝试curl的时候,dropwatch显示说明都会在nf_hook_slow处出现一次丢包,难道DNS的第二个AAAA记录请求报文是在这边被丢弃的?nf_hook_slow内核netfilter模块的核心函数,遍历了下内核netfilter模块的相关代码,发现有个地方比较可疑,包在离开协议栈的时候,会调用__nf_conntrack_confirm,如果连接跟踪确认失败,insert_failed计数会增加,最后返回NF_DROP:

insert_failed计数器是在/proc/net/stat/nf_conntrack文件里统计的,其内容格式如下:
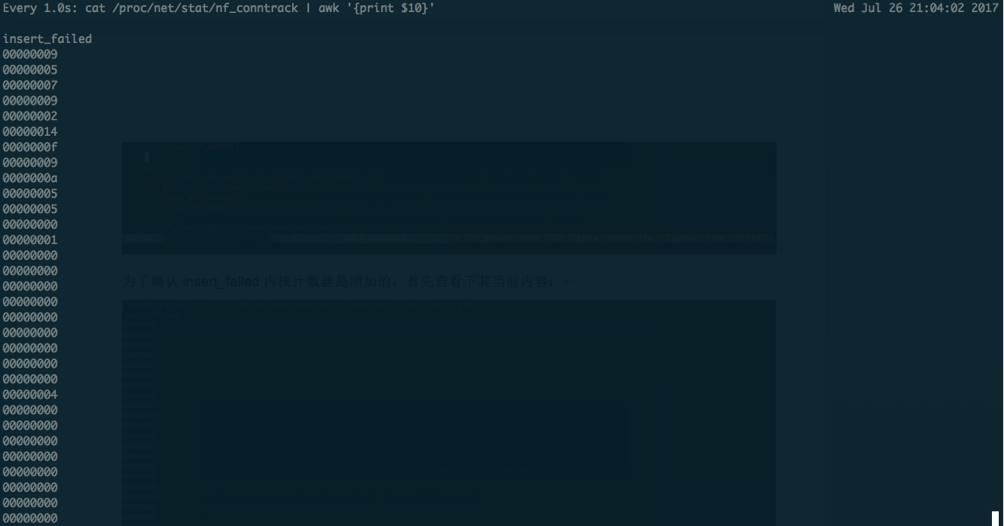
因为该计数器是每CPU计数器,所以其中每行数值的行号都对应着相应的CPU编号,可以看到,有的CPU计数器是有值的,但不足以证明器是DNS丢包导致增加的,如果要确认,可以尝试在虚机里面curl访问百度网址10次,例如在虚机里面执行如下命令:
# for i in `seq 1 10`;do curl www.baidu.com; done
同时,在计算节点上通过watch命令查看insert_failedl计数器是否不停地的在增加,命令如下:
# watch -n 1 "cat /proc/net/stat/nf_conntrack | awk '{print \$10}'"
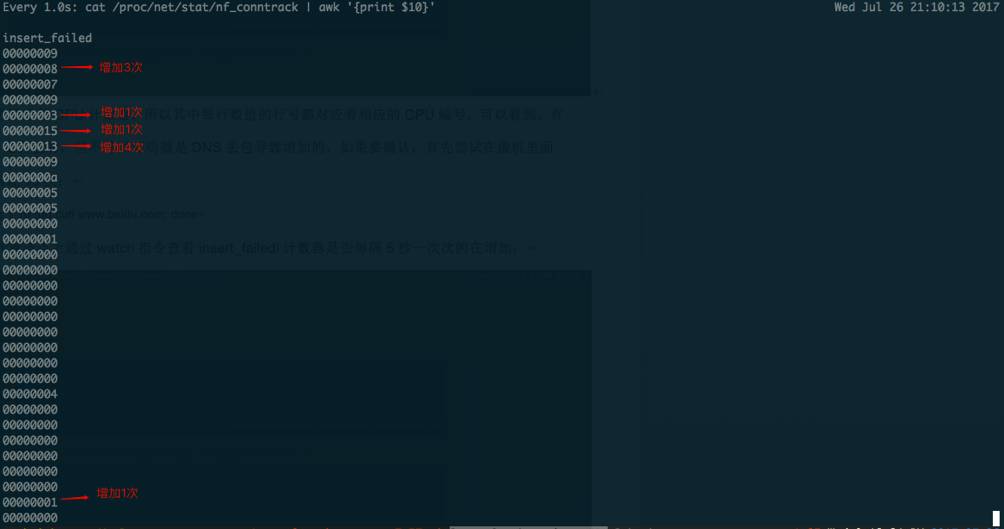
可以发现,在所有curl访问完成后,每次dns解析都会超时5秒,共超时10次,一共执行了50多秒,而insert_failed内核计数器也增加了10,既一共发生了10次丢包:
现在基本可以断定内核丢包的地方是在__nf_conntrack_confirm函数里, __nf_conntrack_confirm函数是netfilter连接跟踪实现的核心函数,它主要是对其数据包进行连接跟踪记录确认,并最后调用__nf_conntrack_hash_insert将新建的连接跟踪记录添加到连接跟踪表中。应该是第二次DNS(AAAA)请求的conntrack连接跟踪记录没有被确认导致失败返回NF_DROP,所以先分析__nf_conntrack_confirm函数代码,返回NF_DROP的条件如下:

nf_ct_tuple_equal目的是判断已建立的连接中是否存在完全一致的正向或反向五元组信息,如果存在就表示有冲突,直接跳转到out处代码,为什么要这样做呢?

我们再来看一下DNS发出请求的前两个A及AAAA记录请求报文的特点:
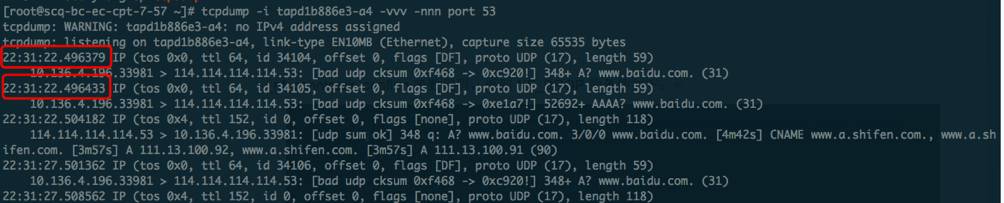
这两个包之间的间隔时间非常短,第一个时间戳是22.496379秒,第二个时间戳是22.496433秒,相差无几,可以认为这两个包是并行发出的,而且其源端口、源IP、目的端口、目的IP也是完全一样的,既五元组信息一致,难道是内核在处理这两个包时,误以为第二个包是超时重传的,所以丢弃了第二个包?
其实内核真正的目的是这样的,如果第一个包被确认了并且五元组信息加入到了连接跟踪表中,第二个包进入时会查找连接跟踪表,因为已经有相同的五元组信息在连接跟踪表汇总,所以会查找成功并根据匹配到的五元组信息进行无条件转发,所以不需要进入到__nf_conntrack_confirm进行再次确认;但是还有一种情况就是如果第二个包进入时,第一个包还没有来得及被确认或者加入到连接跟踪表中,这时就会存在竞争,第二个包也会进入到__nf_conntrack_confirm进行再次确认,根据之前分析,因为已经存在该连接跟踪记录,所以就产生了冲突,此时就会发生丢包。
解决方案
如果对数据包不启用连接跟踪,DNS延时问题就会得到解决,一个临时的解决方案是添加防火墙规则对DNS的数据包不执行连接跟踪,规则内容如下:
# iptables -t raw -I PREROUTING -p udp -m udp --dport 53 -j CT –notrack
# iptables -t raw -I PREROUTING -p udp -m udp --sport 53 -j CT –notrack
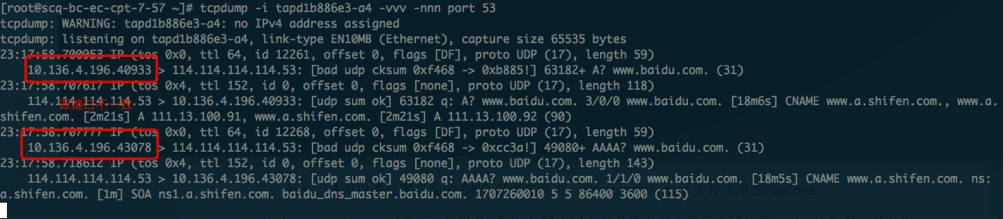
另外,还可以通过客户端的DNS配置来解决,在/etc/resolv.conf文件里增加"options single-request-reopen"选项,使得DNS的A和AAAA记录请求报文使用不同的源端口:
以上都是临时的解决方案,只解决了DNS请求延时的问题,如果在虚机中有某个应用通过多线程并发两个或多个udp请求包,第二个包也会有一定概率会被丢弃的,其实内核netfilter社区很早就已经在尝试解决类似这种前后两个udp包竞争导致丢包的问题,其中最关键的补丁如下:
https://git.kernel.org/pub/scm/linux/kernel/git/next/linux-next.git/commit/?id=71d8c47fc653711c41bc3282e5b0e605b3727956

但是这个补丁在我们openstack集群环境下测试验证下来,还是有点问题的,在nat模块被加载的情况下它会导致第二个AAAA记录请求报文在被转发时,源端口发生了变化,这样回来的包目的端口不就对了,DNS请求依然会超时,所以我们重新向netfilter社区提交了修复补丁,详情可以参考如下链接:
https://patchwork.ozlabs.org/patch/775645/
1
END
1
更
多
精
彩
请猛戳右边二维码
苏研大云人
以上是关于干货!OpenStack云主机网络异常丢包问题深入解析的主要内容,如果未能解决你的问题,请参考以下文章