分布式流式计算框架(JStorm)精华一页纸
Posted 一页纸世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式流式计算框架(JStorm)精华一页纸相关的知识,希望对你有一定的参考价值。
1、流式处理框架的兴起
I、选择数据库
还有一个其他的类似名称 CEP(复杂事件处理系统);最初的系统分析,比如求 一段时间内的用户数,最大值,TOP 排名,排序等等,都是基于数据库系统来实现的。随着数据量的增大,数据库逐渐力不从心。
一边接受数据的插入,另一边不断的计算。而且数据库受架构调度影响,有一定的瓶颈。另外,数据库处理有一定的延后性。
能否把数据在内存中计算好了?
当数据量比较大的时候,要多台机器并行处理,这就涉及到 多台机器如何调度(单节点是否完成、如果任务失败怎么办、节点宕机怎么办)?数据如何切割(如何分发给多个节点)?最后如何合并结果等等?所有这些操作,都需要有一个处理调度框架,在没有使用开源以前,很多公司自己开发平台。所幸,现在有非常多的开源框架可选
II、开源框架
a、MapReduce
基于 HDFS/HBase 等数据源的 处理框架,只是一个面向批处理的框架,可以满足数据统计,但实时性差。参见本博《分布式计算框架 MapReduce 入门精华一页纸》
b、Spark/Spark Streaming
最火的流式处理框架,生态系统比较完善,参见本博关于Spark的讨论
c、Storm/JStorm
实时处理框架,真正的实时信息流处理
d、其他
S4 - Yahoo 开发的实时系统处理框架
2、JStorm 概览
流式处理框架本质是信息流,一个信息流通过系统各个处理节点,最终到达目的地;而各个处理节点,就构成一个信息流图,称为有向无环图。一般这些框架包含两个大的阶段,Map阶段 - reduce阶段;其中 map阶段,就对数据的整理、联合、分组 -- 可以简单类比 数据库的数据提取,只处理维度部分;reduce 阶段 对数据进行 联合、分组、汇聚、统计等等。 -- 可以简单类比数据的 聚合函数统计部分,处理 KPI 指标。
I、组件
a、两类节点(进程)
Numbus -- 调度节点 类似于 Map/Red 的 Master节点 JobTracker/ResourceManager
Supervisor -- 工作节点,类似于 Map/Red 的 Slaver 节点 TaskTracker/NodeManager
具体任务执行是由 Woker - Task 来负责完成的,类似于 Map/Red 的Task
b、模块组件
Topology -- 拓扑,storm 运行的一个任务的单元。 即一个任务的流水线组成的一个有向无环图, 类似于Spark的 RDD, Map/Red 的 Job中的setMap和setReduce的功能。
Spout -- 龙卷风? 接收/生成 数据流Stream, 类似于 Map/Red 中的 Map 函数处理
Bolt -- 雷电 , 数据真实处理单元,接收 Spout或者其他 Bolt的数据, 类似于 Map/Red 中的 reduce 函数
c、节点协调
和其他集群产品一样,也是通过 Zookeeper协调;在 *.yaml 中配置 Numbus Supervisor 等一系列参数
d、节点通讯
Storm中 Spout和Bolt之间、Bolt和Bolt之间的通信,是通过zeroMQ的消息队列实现的;在Jstorm中采用了netty + disruptor 替换 zmq + blockingQueue
II、架构图
III、工作节点与并发度
Worker - Excutor - Task
Worker:
Worker 是运行在工作节点Supervisor 上面,Supervisor节点的worker可以有多个,每个worker使用一个单独的端口。每个Worker对应于一个 特定 topology的全部执行任务的一个子集。也就是说,一个Worker里面只会运行某一个 topology的执行任务。对Topology中的每个component(Spout/Blot)运行一个或者多个Executor线程来提供Task的运行服务(这段话的理解可以参照 ThreadPoolExecutor )。其数目可以通过设置yaml中的topology.workers属性以及在代码中通过Config的setNumWorkers方法设定。
Excutor:
Worker进程中的工作线程,只能运行同一个component(Spout/Blot) 的Task。 其数目可以在Topology的入口类中setBolt、setSpout方法的最后一个参数指定,不指定的话,默认为1;
Task:
具体的任务处理,在Topology的生命周期中,每个组件的Task数目是不会发生变化的,在代码中通过TopologyBuilder的setNumTasks方法设定具体某个组件的task数目。
Task 和 Excutor 的对应关系
Task >= Excutor, 在 setXXX(component, excutorNum).setNumTasks(TaskNumber), 比如 2个 Excutor 4 个Task,则每个Excutor 有 2个Task
并发度
Excutor 的数目 累加就是系统并发度
JStorm中,做了简化,去掉了Executor,只有Task
IV、任务过程
a、提交 信息流的 拓扑 Topology, storm 代码放到Nimbus节点的inbox目录下,之再把运行的配置stormconf.ser文件放在 stormdist目录,还有一些其他Topology信息
b、根据配置的 Worker、Excutor、Task 数量,进行计算和调度、分配任务
c、分配好任务之后,Nimbes节点会将任务的信息提交到zookeeper集群, Supervisor节点 负责启动Worker进程,并通过Zookeeper 维持心跳、 领取自己的任务
d、集群运行,通过Spouts来发送Stream流,通过Bolts来来处理接收到的Stream流。
e、手动关闭 Nimbus节点 storm kill topologyName kill。 代码调用 shutdown。
3、Spout - 获取数据并向拓扑发送信息流
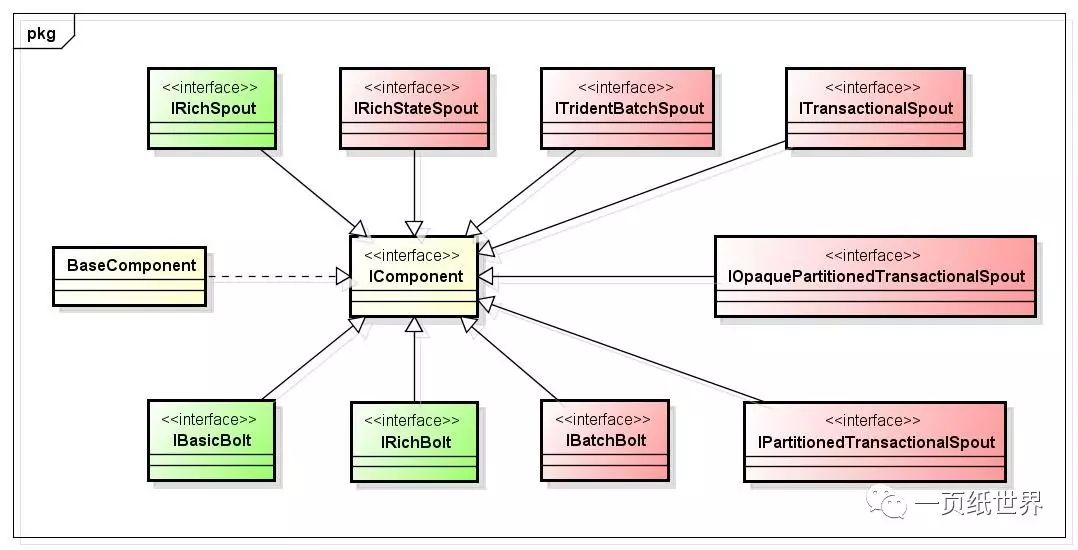
I、常用接口
backtype.storm.topology.IRichSpout -- 正常处理接口
backtype.storm.spout.ISpout -- Spout的主要接口
backtype.storm.topology.IComponent -- Storm 的组件接口,Spout和Blot都实现其接口
backtype.storm.transactional.partitioned.IPartitionedTransactionalSpout -- 事务处理接口
适配类 backtype.storm.topology.base.BaseRichSpout 类似java awt/swing 的空实现类, 只覆盖需要覆盖的方法;Base 目录下有很多类似的类
II、重要方法
a、生命周期
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector)
spout初始化时回调,包含系统配置参数 、 上下文对象、 发送引用, 一般用来获取配置信息,保存 发送引用
public void activate()
激活时回调
public void deactivate()
去活时回调
public void close()
spout关闭前回调,但是并不能得到保证其一定被执行。spout是作为task运行在worker内,在cluster模式下,supervisor会直接kill -9 woker的进程,这样它就无法执行了。而在本地模式下,只要不是kill -9, 如果是发送停止命令,是可以保证close的执行的。
b、处理逻辑
public void nextTuple()
此方法是核心方法,基本的发射处理逻辑都在此,由Storm 框架循环多次调用;所以此方法处理核心就是要快速和高吞吐量,从数据源取数据时尽量不要阻塞,单次调度尽量多发数据。
另外,调用nextTuple方法时,如果没有emit tuple,那么默认需要休眠1ms,这个具体的策略是可配置的;这个非常影响效率,编码时需要特别注意。
c、容错与监控
public void ack(Object msgId)
msgId 表示一个tuple。tuple被成功处理后调用。可以用来清理数据
public void fail(Object msgId)
tuple处理失败时执行。可以用来重发
d、组件方法
void declareOutputFields(OutputFieldsDeclarer declarer)
定义输出参数,主要是字段个数,供下游使用,如果用在 bolt中,则execute方法中,emit发射的字段个数必须和声明的相同;还可以用在fieldsGrouping分组用
Map<String, Object> getComponentConfiguration()
用于 针对当前组件的特殊配置,一般较少用到
III、数据来源
Spout的数据来源:
a、pull
一种场景是 自己主动取读取,比如读取 文件、网络、消息中间件、数据库等等,算是 pull
b、push
为了平滑处理;一般开发时,在 Spout 前端做一个封装,把 通过 redis,MQ,kafka,或者本地内部链接,的数据推push Queue 消息队列中;Spout从消息队列取数据。
这里的push or pull 主要指的是信息流 到处理他的进程
IV、并行度
a、获取Spout的Task数
通过 TopologyContext 获取上下文信息
context.getComponentTasks(context.getThisComponentId()).size(); -- 根据Spout的名字获取任务数
context.getThisTaskIndex(); -- 获取当前任务节点编号
b、对数据源进行 分割读取
可以通过取模 、 范围等等方式,把数据分发到不同节点处理。
比如,读取文件分组,读取不同的数据分表(分区、分表)、不同的数据范围;读取 kafka 不同的分区
对于网络端口的同一个URL的流就比较麻烦,不好分割。
4、Blot - 拓扑处理节点,数据转换和聚合
I、常用接口
backtype.storm.topology.IRichBolt -- 正常处理接口
backtype.storm.task.IBolt -- Spout的主要接口
backtype.storm.topology.IComponent -- Storm 的组件接口,Spout和Blot都实现其接口
backtype.storm.transactional.TransactionalSpoutBatchExecutor -- 事务处理类
适配类 backtype.storm.topology.base.BaseRichBolt 类似java awt/swing 的空实现类, 只覆盖需要覆盖的方法
RichBolt vs BasicBolt
区别:直接用BasicBolt,会在execute()后自动ack/fail Tuple,而RichBolt则需要自行调用ack/fail。
II、重要方法
a、生命周期
void prepare(Map stormConf, TopologyContext context, OutputCollector collector)
blot初始化时回调,包含系统配置参数 、 上下文对象、 发送引用, 一般用来获取配置信息,保存 发送引用
void cleanup()
spout结束时 (拓扑结束、集群关闭时)调用,一般用来处理最终逻辑、或者最后一部分逻辑。
b、处理逻辑
void execute(Tuple input);
此方法是核心方法,基本的发射处理逻辑都在此,由Storm 框架循环多次调用;和Spout 一样,要保持高处理效率
c、组件方法
void declareOutputFields(OutputFieldsDeclarer declarer)
定义输出参数,主要是字段个数,供下游使用,如果用在 bolt中,则execute方法中,emit发射的字段个数必须和声明的相同;还可以用在fieldsGrouping分组用
Map<String, Object> getComponentConfiguration()
用于 针对当前组件的特殊配置,一般较少用到
III、数据来源
Spout 的分发、上游Blot 的信息流
5、拓扑
I、主要接口
backtype.storm.topology.TopologyBuilder -- 管理整个拓扑的容器,设置 Spout 和 Blot
backtype.storm.Config -- 可以覆盖 stor.yaml 配置参数
II、重要方法
public SpoutDeclarer setSpout(String id, IRichSpout spout)
有很多重载方法, 主要包括 Spout引用实现,编号,并发度等等
public BoltDeclarer setBolt(String id, IBasicBolt bolt)
有很多重载方法, 主要包括 Rich/Bascic Blot应用实现,编号,并发度等等
III、本地模式 VS 集群模式
a、LocalCluster -- 可以本地java 进程启动
LocalCluster cluster = new LocalCluster();
启动:cluster.submitTopology("拓扑名", conf, builder.createTopology());
停止:cluster.shutdown
b、StormSubmitter -- 集群jar启动
StormSubmitter.submitTopology("拓扑名", conf, builder.createTopology());
启动:和hadoop 集群运行方式一样 storm jar xx.jar xxx.xxx.MainCLass args
停止:storm kill 拓扑名
IV、分组策略 -- 数据流组
a、随机流组 - shuffleGrouping
数据任意分发,没有状态情况下使用
b、域数据流组 - fieldsGrouping
把相同的 域(字段 /key) 分发到同一个 处理器Blot 上 采用了一致性哈希的算法
c、全部数据流组 - allGrouping
向系统中所有的 blots 发送tuple 元素,对于每个tuple, 所有Bolt的所有task(也就是线程)都会收到, 也就意味着, 如果你的并行度设置>1, 则每个tuple会被bolt处理N次;一般用于全局的数据同步和共享才需要, 比如全局的配置更新、刷新缓存等
d、自定义数据流组 - CunstomStreamGrouping
通过实现 CustormStreamGrouping 接口,可以按照 用户 定义的 数据流转方向
e、直接数据流组 - emitDirect | directGrouping
在数据源中直接指定 发送的 处理器,相当于流程中的跳转??
f、全局数据流组
Stream中的所有的tuple都会发送给同一个bolt任务处理,所有的tuple将会发送给拥有最小task_id的bolt任务处理
一般情况下, shuffleGrouping 和 fieldsGrouping比较常用
6、消息体 Tuple元组
I、接口
backtype.storm.tuple.ITuple -- 定义了各种数据类型的字段、存储、获取等等
backtype.storm.tuple.Tuple -- 定义了流、组件、任务号、消息号等流处理过程中的编号
II、几个关键参数
a、streamId -- 标注一个 流
允许一个blot 订阅另一个 blot 的指定流处理,具体使用案列,参见下文 第 9节 流的分拆和合并
b、messageId
自动生成的64位id,绑定每个 tuple,作为消息跟踪、事务处理的识别标志;一般会有一个全局 messageId,在发送开始时标注,然后每一个Tuple也标注一个
c、taskId
构造这个 tuple 的Task 编号
III、Tuple树
从 Spout创建 Tuple开始,这个 Tuple作为 树的根节点。后续每个处理节点 的Tuple 作为树的子节点,构成Tuple树。
需要注意的是,如果在 excute 方法中,发射 emit时,没有把 上游传入的 Tuple 作为参数传给下游 。则 新生成的 Tuple 和原先的Tuple 不再构成 Tuple树。
7、一个案例
I、配置 Spout 接受数据流
public void nextTuple() {
String message = MessageSender.INSTANCE.pullMessage();
if(message != null){ -- 此处阻塞 不调用 emit 会影响效率,仅做案例
String[] data = message.split(" ");
collector.emit(new Values(data[0], data[1], message), message);
}
}
II、配置 Blot 处理数据
Join的Blot节点,缓存17001消息,准备和17002join
public void execute(Tuple input) {
if(isTickTuple(input)) return ;
String event = input.getString(0);
String user = input.getString(1);
if(event.equalsIgnoreCase("17001"))
map.put(user, parseUser(input.getString(2))); -- 把消息构造一个用户对象存储做join用
else
collector.emit(input, new Values(map.get(user), parseScore(input.getString(2))));
collector.ack(input);
}
汇总统计的Blot节点,计数,统计最大值
public void execute(Tuple input) {
User user = (User)input.getValue(0);
Long currentCout = count.get(user);
if(currentCout != null)
count.put(user, currentCout + 1);
else
count.put(user, 1L);
Long currentMax = max.get(user);
long maxData = input.getLong(1);
if(currentMax != null)
max.put(user, maxData > currentMax ? maxData : currentMax );
else
max.put(user, maxData);
collector.ack(input);
}
public void cleanup() {
输出统计结果;
}
III、布置拓扑
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new xxxSpout());
builder.setBolt("join", new xxxJoinBlot(),2).fieldsGrouping("spout", new Fields("user"));
builder.setBolt("total", new xxxTotalBlot()).fieldsGrouping("join", new Fields("user"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Getting-Started-Topologie", conf, builder.createTopology());
8、容错机制 ack
I、可靠性ACK
并不是所有的 消息和业务都需要可靠性,在 Storm中 内置了可靠性的 技术 ack,需要可靠时,可以使用
a、首先在 spout 中分发/投递时,标记一个消息ID, collector.emit(new Values(…),tupleId) 并且扩展实现 ack/fail 方法,成功和失败时,系统会回调这两个方法
b、其次每个 Blot 在处理完成时,需要 锚定 collector.ack(tuple) / fail(tuple) ,标记本次处理结果
当所有的处理都通过时,表明消息正确处理了;当有处理失败,或者超时时,则处理失败
如果不想手工调用,则 可以扩展 BaseBasicBolt 实现自动确认消息,避免了 每次手动 ack消息
II、原理 acker
系统有一个 专门的 Task acker,负责跟踪每一个 Tuple消息发送。
a、Spout创建一个Tuple时,生成一个ack消息,包含 messageId,一个 20 位的整数 ack-val
b、每个blot处理 发射一个Tuple或Ack一个Tuple时,这个Tuple的id就要跟这个校验值异或一下,并且把得到的值更新为ack-val的新值。
c、这样 每发射一次 每处理一次 都进行异或, 如果所有的都处理完成,异或值为 0
失败如何处理?
如果 某个 任务失败; 则应用可以在 Spout的 fail 方法二次开发,重新发送这笔数据
要实现 acker 容错
必须要 在 emit 时,把 上游 Tuple 发送到下游,这个过程称为锚定
9、流的分拆和合并
I、合并
可以级联多个 shuffleGrouping 把多个流合并到一个流处理
builder.setBolt("xxx", new xxxBlot(), 2).shuffleGrouping("1").shuffleGrouping("2").shuffleGrouping("3");
II、拆分
a、配置拓扑
定义多个Blot,上游为同一个Blot,并且指定 流
builder.setBolt("xxx1", new xxxBolt1(), 3).shuffleGrouping("上游blot", "stream1");
builder.setBolt("xxx2", new xxxBolt2(), 3).shuffleGrouping("上游blot", "stream2");
builder.setBolt("xxx3", new xxxBolt3(), 3).shuffleGrouping("上游blot", "stream3");
b、上游blot
定义多个输出流
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declareStream("stream1", new Fields());
declarer.declareStream("stream2", new Fields());
declarer.declareStream("stream3", new Fields());
}
在逻辑处理时,指定 流发射 emit(streamid, Tuple)
public void execute(Tuple input)
emit("stream1", Tuple)
emit("stream2", Tuple)
emit("stream3", Tuple)
10、事务
Storm的容错机制,可以保证 at least once 至少处理一次,一旦出现错误,则从Spout的fail 函数重发一次,但不能保证有且只有一次
Storm事务采用类似2PC 两段式事务的处理模型,分为 process 处理阶段、commit 提交阶段。
I、开启事务
传统的信息流从 Spout 开始发射出去,因为开启事务的过程需要 Spout 执行。为了标记事务,事务Spout做了一些设置。需要继承如下的事务Spout 接口和类。
backtype.storm.transactional.ITransactionalSpout
backtype.storm.topology.base.BaseTransactionalSpout<T>
主要有两个方法,返回两个接口 Coordinator 和 Emitter
Coordinator<T> getCoordinator(Map conf, TopologyContext context)
Emitter<T> getEmitter(Map conf, TopologyContext context)
这两个方法和接口的作用
Coordination Spout 用来
a、处理数据范围 TransactionMetadata 协调生成批次;
b、发送一个 batch tuple,开启事务 通知所有的 emit ,通过 all group 分组消息
Emitter Blot 用来
c、分发数据,并且每笔数据携带 TransactionAttempt (批次编号txid,当前元祖编号 -- 可以理解为 版本号)
通过批处理目的是,提高处理效率,就和平时执行 insert sql 一样,单条提交效率低,通过一个批次,批量处理提交事务,提升性能。
通过事务标志 txid,来标识每批数据事务是否完成,和 ack 机制一样,每次发送必须携带这个数据,不然无法跟踪。
Storm把 TransactionMetadata 跟 txid一起保存在zookeeper。这样就确保了一旦发生故障,Storm可以利用分发器重新发送该批次
II、事务处理部分
backtype.storm.coordination.IBatchBolt
backtype.storm.topology.base.BaseBatchBolt
backtype.storm.topology.base.BaseTransactionalBolt
BaseBatchBolt 和传统普通的 Blot 不同的是,不能处理完立即发射元祖数据
void execute(Tuple tuple) -- excute 方法只能处理不能发送
void finishBatch() -- 该批次处理完成,才能实现发射
BaseTransactionalBolt -- 只是指定了泛型类 TransactionAttempt 用于事务,其他和BaseBatchBolt一样没有扩展
CoordinateBolt原理
事务Blot 在具体运行时,系统会包裹一个外壳Bolt,在应用的基础功能之上,包装了以下功能
a、元数据记录了 当前Bolt 上游的 Task,下游的Task, 这个信息通过 Group分组可以获取
b、发完消息后,告诉下游,一共发送了多少个Tuple(通过 emitDirect 单独通知),下游可以判断是否有丢消息
anchoring/acking 机制在哪?
事务方式下,和继承BasicBolt 类似,隐藏了显式调用,内部调用
III、事务提交部分
backtype.storm.transactional.ICommitter
实现了这个接口的 BatchBolt,在提交时,执行 finishBatch(而普通不实现这个提交接口的,则不一定)
a、Storm通过anchoring/acking机制来检测事务是否已经完成了processing 阶段
b、如果完成后了,前面开启事务的 coordinator 通过all grouping方式 发射一个事务提交的 Tuple 到 commit(支持事务的Bolt,即实现接口的Bolt)节点,此时进入commit阶段。
c、事务提交后,同样通过anchoring/acking机制确认已经完成了commit阶段,接收到ack后,在zookeeper上把该transaction标记为完成。
事务的顺序,在事务提交部分严格保证,必须上一个流提交完成,下一个流才能执行
IV、拓扑
backtype.storm.transactional.TransactionalTopologyBuilder
V、事务类型
Storm支持三种事务
a、普通事务
就是上面的事务部分
b、分区事务
backtype.storm.transactional.partitioned.IPartitionedTransactionalSpout
Coordination 的方法 initializeTransaction 返回元数据的, 改成 numPartitions 返回分区数
Emitter 的方法 新增了一个 emitPartitionBatchNew 方法从分区读取数据 并返回元数据,并调用emitPartitionBatch 发射
c、模糊分区事务
backtype.storm.transactional.partitioned.IPartitionedTransactionalSpout
主要是为了解决,当消息中间件某个部分挂掉以后,批处理发送不会阻塞,继续发送下个批次。
11、定时任务
现实应用中,很多是定时计算数据;Storm 实现了定时统计的功能
I、设置定时间隔
在配置拓扑时,在配置信息中增加配置时间
conf.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 60);
II、在每个Bolt的execute方法中检查是否是定时消息
protected static boolean isTickTuple(Tuple tuple) {
return tuple.getSourceComponent().equals(Constants.SYSTEM_COMPONENT_ID)
&& tuple.getSourceStreamId().equals(Constants.SYSTEM_TICK_STREAM_ID);
}
12、性能与优化
I、典型应用
消息中间件(数据来源,比如KafkaSpout) + jstorm + 外部存储(数据结果)
有很多处理场景,并不需要保证事务和容错,从效率上讲 关闭容错ack > 支持容错机制 > 事务 > trident 高级接口;根据需要来考虑使用场景
II、组件
nextTuple 是数据发射的开始,所以要尽可能的多发数据,单次发送多笔数据;
数据来源方,按照比较合理的顺序布局,方便 Spout 并发
合理配置并发度(worker默认 内存大概 800多M,小任务可以分配并发,大任务可以扩大内存)
尽量采用无状态的 随机分组 shuffleGrouping,减少单点压力过大
以上是关于分布式流式计算框架(JStorm)精华一页纸的主要内容,如果未能解决你的问题,请参考以下文章