分享吧大数据之流式计算在实时监控领域的应用研究
Posted 大连飞创
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分享吧大数据之流式计算在实时监控领域的应用研究相关的知识,希望对你有一定的参考价值。
大数据之流式计算
前言
云计算、物联网等新兴信息技术和应用模式的快速发展,推动人类社会迈入大数据新时代。大数据蕴含大信息,大信息提炼大知识,大知识将在更高的层面、以更广的视角、在更大的范围内帮助用户提高洞察力、提升决策力,为人类社会创造前所未有的大价值。但与此同时,这些总量极大的价值往往隐藏在大数据中,表现出了价值密度极低、分布极其不规律、信息隐藏程度极深、发现有用价值极其困难等鲜明特性,这些特征必然为大数据的计算带来前所未有的挑战和机遇。
流式数据是大数据环境下的一种数据形态,其理论诞生于20世纪末,并在云计算和物联网发展下逐步成为当前的研究热点。与静态、批处理和持久化的数据库相比,流式计算以连续、无边界和瞬时性为特征,适合高速并发和大规模数据实时处理的场景。当前大数据环境下的许多应用呈现多源并发、数据汇聚、在线处理的特征,实时数据处理的相关研究迅速发展,并在许多关键领域,如传感网络、金融、医疗、交通和军事领域得到了广泛的应用。
就我们而言,在未来新一代交易系统市场环境下,大数据给我们带来了更高频的交易委托、更复杂的交易行为,对市场交易的实时监控提出了更严格的要求。面对这新的机遇与挑战,开发二部紧跟时代步伐,立足于大数据技术,重点调研分析了目前主流的流式计算框架,并对Apache Storm(以下简称为Storm)进行了深入的研究学习,基于Storm构建了大数据在线实时分析平台,为后续在交易行为实时监控领域的应用奠定了技术基础。
流式计算的特点
大数据的计算模式主要分为批量计算(batch computing)、流式计算(stream computing)等,分别适用于不同的大数据应用场景。对于先存储后计算,实时性要求不高,同时数据的准确性、全面性更为重要的应用场景,批量计算更加适合。对于无需先存储,可以直接进行数据计算,实时性要求很严格,但数据的精确度往往不太苛刻的应用场景,流式计算具有明显优势。
与传统数据库批计算相比,流式计算的特点主要有以下几方面:
●无边界:数据到达、处理和向后传递均是持续不断的。
●瞬时性和有限持久性:通常情况下,原始数据单遍扫描、处理后丢弃,并不进行保存;只有计算结果和部分中间数据在有限时间内被保存和向后传递。
●价值的时间偏倚性:随着时间的流逝,数据中所蕴含的知识价值往往也在衰减,也即流中数据项的重要程度是不同的,最近到达的数据往往比早先到达的数据更有价值。
流式计算组件选型
Storm、Spark Streaming、Flink都是开源的分布式流式计算系统。流式计算系统通常是将任务分配到一系列具有容错能力的计算机上并行运算,通过提供简单的API来简化底层实现的复杂程度。
Storm是一个流计算处理框架,对流式数据按顺序逐个处理。Spark Streaming它并不会像Storm那样一次一个地处理数据流,它是在处理前按时间间隔预先将其切分为一段一段的批处理作业,属于微批处理。Flink是一个针对流数据和批数据的分布式处理引擎,对Flink而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。就框架本身与应用场景来说,Flink与Storm更加相似。

对金融领域交易行为实时监控的应用,数据的前后关联性较大,对交易数据的顺序要求较高,需要逐笔交易的监控,批处理不适用于我们的业务场景。而相对Flink,Storm的成熟度更高、应用更广泛。因此,我们选择Storm作为我们大数据在线实时分析平台的核心组件。
关于Storm
Storm是一个免费、开源的分布式的实时计算系统,是Apache的顶级项目。可以应用在在线机器学习、持续计算、实时分析、分布式远程调用等多个场景。具有低延时、高并发、分布式、可扩展、高可用等特点。
目前,全球范围内很多著名公司都在使用Storm。如大家耳熟能详的Yahoo、百度、阿里巴巴、Twitter等。

Storm的分布式设计
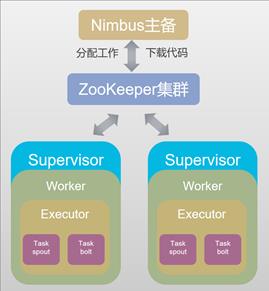
Storm的分布式集群系统由Nimbus、Supervisor、Worker三组进程组成,整个集群由ZooKeeper实现协同管理。
Nimbus是Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点去运行Topology对应的组件(Spout/Bolt)的Task。
Supervisor是Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker进程的启动和终止。
Worker是运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Task是Worker中每一个Spout/Bolt的线程,不同Spout/Bolt的Task可能会共享一个物理线程,该线程称为Executor。
ZooKeeper负责协调Nimbus和Supervisor,如果Supervisor因故障出现问题而无法运行Topology,Nimbus会第一时间感知到,并重新分配Topology到其它可用的Supervisor上运行。
Storm的编程模型
关于Storm的编程模型,首先需要了解以下几个基本概念。
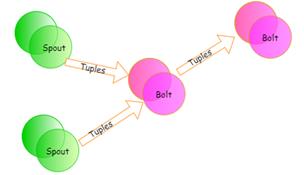
●Topology:Storm对任务的抽象,它将实时数据分析任务分解为不同的阶段,是把Spout、 Bolt整合起来的拓扑图。在Topology中定义了Spout和Bolt的结合关系、并发数量和其他配置等等。
●Spout:在一个Topology中获取源数据流的组件。通常情况下Spout会从外部数据源中读取数据,然后转换为Topology内部的源数据。
●Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
●Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
●Stream:Tuple的集合,表示数据的流向。
Topology的运行的原理如下图,Spout源源不断的向后续Bolt发送Tuple数据,Bolt根据不同的业务逻辑对数据进行深加工,并继续发送给后续Bolt,Bolt计算的最终结果可以存入消息中间件或数据库等。
Storm的消息处理容错机制
ack机制是Storm消息处理模式中非常重要的框架。为了保证所有数据能正确的被处理,对于Spout产生的每一个Tuple,Storm都会进行跟踪,以确定是被成功处理或失败处理。具体来说,Spout发送的每一条消息:
●在规定的时间内,Spout收到Acker的ack响应,即认为该Tuple 被后续Bolt成功处理;
●在规定的时间内,没有收到Acker的ack响应Tuple,就触发fail动作,即认为该Tuple处理失败;
●收到Acker发送的fail响应Tuple,也认为失败,触发fail动作。
Spout在触发fail操作后,会重发失败的消息,从而保证了每条数据都可以被正确处理过(At least Once)。
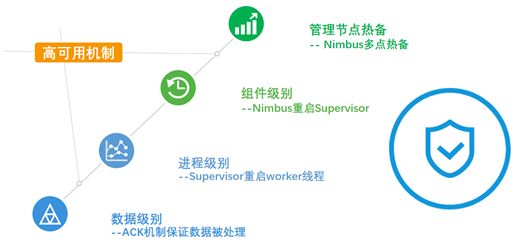
Storm的可靠性保证
除消息处理框架的ack机制外,Storm集群的可靠性还有多层保障。在进程级别,Worker失效,Supervisor会自动重启Worker线程。在组件级别,Nimbus和Supervisor都被设计成无状态,状态信息都存放在Zookeeper集群中,如果Supervisor节点失效,Nimbus会在其他节点重启该Supervisor任务,对Worker的运行没有影响。Nimbus也被设计成HA的机制,利用主从结构保证主节点挂了之后从节点一样能服务,对Supervisor和Worker没有任何影响。
Storm计算性能的水平扩展
作为分布式系统,Storm计算性能可以随配置增加而水平扩展。我们可以从三个维度提高其性能。
●Topology设计中,增加相同逻辑计算单元的节点数量。
●Topology运行中,增加参与计算的Worker的数量。
●物理配置中,增加实际参与计算的服务器的数量。

Storm的其他优势
得益于Storm的多语言协议,除了用Java实现Spout和Bolt,还可以使用任何你熟悉的编程语言来完成这项工作。多语言协议是Storm内部的一种特殊协议,这一协议极大的降低了Storm编程的学习成本。
另外,Storm还有UI监控友好、运维简单高效、API集成接口丰富、开源社区活跃等优势。

基于Storm的实时监控拓扑模型
通过分析实时监控类的业务,我们利用Storm的拓扑结构,抽象出统一的实时监控计算业务的拓扑模型。主要分为三层,首先Spout从消息中间件Kafka获取某一类交易数据并向后广播;Distribute Bolt是消息路由Bolt,主要职责是根据业务需要对消息进行分组标记,如合约、品种、客户等对消息进行分组,最后按组别进行再次路由转发;Calculate Bolt是并行计算的主要节点,为保证业务逻辑正确,相同分组的信息由同一个计算节点执行,N个Bolt并行计算,以保证大数据量下的高吞吐量。
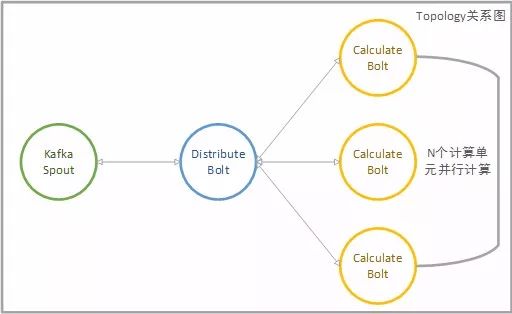
基于Storm的大数据在线实时分析平台
开发二部以Storm为流式计算核心,构建了一套实时交易数据的在线分析平台。该平台使用了自主研发的消息采集器Gate,实时获取交易数据沉淀至平台的消息中间件Kafka,Storm通过订阅Kafka实时交易数据,持续计算交易行为的合规性和市场异动,计算结果保存至Redis(实时库)和mysql(历史库)以满足不同的业务需求,最终结果在通用业务平台上向用户展示。
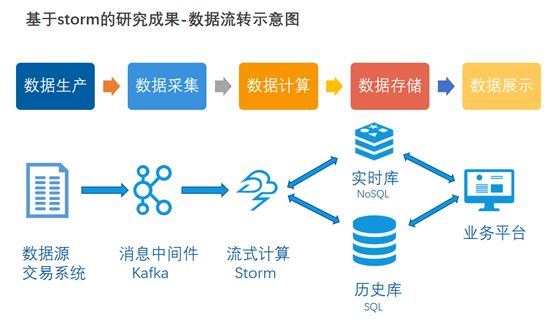
该平台大幅提升了原有实时交易监控的性能,目前匹配6.4期交易系统,后期可通过水平扩展匹配新一代系统;另外该平台补充了很多原有批处理框架下难以实现的业务场景,实现了幌骗交易筛查等复杂的业务场景,填补了逐笔计算的业务空白。
意义与收获
流式计算是开发二部大数据平台的子课题,经过多次的原型推演与修正,基于Storm的在线分析平台已经相对成熟稳定,可以应对新一代交易系统的高并发、大数据的性能压力,满足客户更加丰富多样的业务需求。同时,开发二部在大数据技术开发研究方向积累了丰富的经验,为交易所新一代监察系统的开发打下了坚实的基础。
大连飞创
以上是关于分享吧大数据之流式计算在实时监控领域的应用研究的主要内容,如果未能解决你的问题,请参考以下文章