走进大数据之storm流式计算
Posted 5xuexi我学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走进大数据之storm流式计算相关的知识,希望对你有一定的参考价值。
诞生
在2011年Storm开源之前,由于Hadoop的火红,整个业界都在喋喋不休地谈论大数据。Hadoop的高吞吐,海量数据处理的能力使得人们可以方便地处理海量数据。但是,Hadoop的缺点也和它的优点同样鲜明——延迟大,响应缓慢,运维复杂。有需求也就有创造,在Hadoop基本奠定了大数据霸主地位的时候,很多的开源项目都是以弥补Hadoop的实时性为目标而被创造出来。而在这个节骨眼上Storm横空出世了。Storm带着流式计算的标签华丽丽滴出场了。
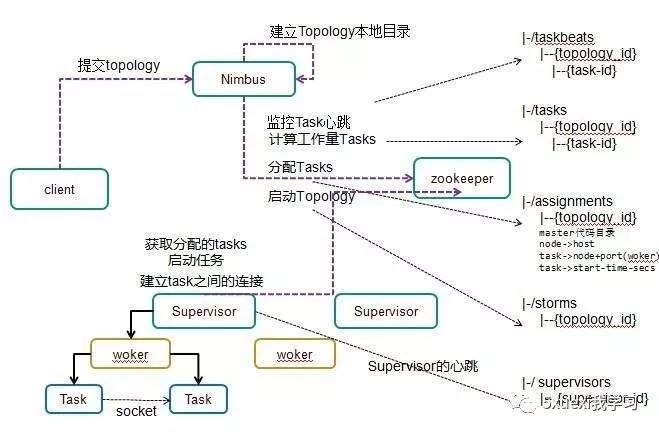
认 识
Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。Storm的部署管理非常简单,而且,在同类的流式计算工具,Storm的性能也是非常出众的。Storm主要分为两种组件Nimbus和Supervisor。这两种组件都是快速失败的,没有状态。任务状态和心跳信息等都保存在Zookeeper上的,提交的代码资源都在本地机器的硬盘上。
优 点
编程模型简单
基于Google Map/Reduce来实现的Hadoop为开发者提供了map、reduce原语,使并行批处理程序变得非常地简单和优美。同样,Storm也为大数据的实时计算提供了一些简单优美的原语,这大大降低了开发并行实时处理的任务的复杂性,帮助你快速、高效的开发应用。
可扩展
在Storm集群中真正运行topology的主要有三个实体:工作进程、线程和任务。Storm集群中的每台机器上都可以运行多个工作进程,每个工作进程又可创建多个线程,每个线程可以执行多个任务,任务是真正进行数据处理的实体,我们开发的spout、bolt就是作为一个或者多个任务的方式执行的。因此,计算任务在多个线程、进程和服务器之间并行进行,支持灵活的水平扩展。
高可靠性
Storm可以保证spout发出的每条消息都能被“完全处理”,这也是直接区别于其他实时系统的地方,如S4。Storm保证了每个消息至少被处理一次,但是对于有些计算场合,会严格要求每个消息只被处理一次,幸而Storm的0.7.0引入了事务性拓扑,解决了这个问题
高容错性
如果在消息处理过程中出了一些异常,Storm会重新安排这个出问题的处理单元。Storm保证一个处理单元永远运行(除非你显式杀掉这个处理单元)。
支持多种编程语言
Storm支持多语言编程主要是通过ShellBolt, ShellSpout和ShellProcess这些类来实现的,这些类都实现了IBolt 和 ISpout接口,以及让shell通过java的processBuilder类来执行脚本或者程序的协议。
支持本地模式
Storm有一种“本地模式”,在进程中模拟一个Storm集群的所有功能,以本地模式运行topology跟在集群上运行topology类似,对开发和测试来说非常有用。
未 来
在流式处理领域里,Storm的直接对手是S4。不过,S4冷淡的社区、半成品的代码,在实际商用方面输给Storm不止一条街。如果把范围扩大到实时处理,Storm就一点都不寂寞了。
Puma:Facebook使用puma和Hbase相结合来处理实时数据,使批处理 计算平台具备一定实时能力。
HStreaming:尝试为Hadoop环境添加一个实时的组件HStreaming能让一个Hadoop平台在几天内转为一个实时系统。分商业版和免费版。也许HStreaming可以借Hadoop的东风,撼动Storm。
Spark Streaming:作为UC Berkeley云计算software stack的一部分,Spark Streaming是建立在Spark上的应用框架,利用Spark的底层框架作为其执行基础,并在其上构建了DStream的行为抽象。利用DStream所提供的api,用户可以在数据流上实时进行count,join,aggregate等操作。
当然,Storm也有Yarn-Storm项目,能让Storm运行在Hadoop2.0的Yarn框架上,可以让Hadoop的MapReduce和Storm共享资源。
课程链接:http://ai.5xuexi.com/toCourseDetail/96.action
识别下图二维码,可直接进入课程:
时不我待,小编带你一览本课程目录
课时1 storm基础入门_01课程简介
课时2 storm基础入门_02Storm简介
课时3 storm基础入门_03Storm原理
课时4 storm基础入门_04zookeeper简介
课时5 storm基础入门_05zookeeper安装配置
课时6 storm基础入门_06zookeeper命令行访问
课时7 storm基础入门_07zookeeper集群环境搭建
课时8 storm基础入门_08Storm安装配置
课时9 storm基础入门_09Storm集群环境搭建
课时10 storm基础入门_10基础入门课程总结
课时11 storm基础进阶_02_01Storm课程简界
课时12 storm基础进阶_02_02Storm基本概念
课时13 storm基础进阶_02_03StormAPI简介
课时14 storm基础进阶_02_04Storm案例环境搭建
课时15 storm基础进阶_02_05Spout组件编写及测试
课时16 storm基础进阶_02_06SplitBolt组件编写及测试
课时17 storm基础进阶_02_07CountBolt组件编写及测试
课时18 storm基础进阶_02_08Storm案例集群运行
课时19 storm基础进阶_02_09Grouping分组策略
课时20 storm基础进阶_02_10StormGrouping策略实例
课时21 storm基础进阶_02_11并发度
课时22 storm基础进阶_02_12Storm数据可靠性保证
课时23 storm基础进阶_02_13基础进阶课程总结
以上是关于走进大数据之storm流式计算的主要内容,如果未能解决你的问题,请参考以下文章