流式计算在商业的应用实践
Posted 之家技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流式计算在商业的应用实践相关的知识,希望对你有一定的参考价值。
总篇28篇 2019年第2篇
一 数据磨坊
1 简介
简单来说,数据磨坊是一个对sparkStreaming框架的一个封装,是一个通用的实时计算框架,由于实时任务开发难度高、涉及技术广等原因,我们开发了一套支持基于sql开发的实时计算框架,以降低开发实时任务的难度,提升工作效率。
数据磨坊基本上每个task的返回结果都会是一个spark 中的dataFrame(即table),数据接入返回是dataFrame、数据处理返回是dataFrame。所以我们大多数的计算逻辑直接配置sql就可以了,甚至离线计算的sql逻辑可以做到90%以上的直接迁移,大大节省了流式任务的开发难度和时间
2 架构
架构图如下:
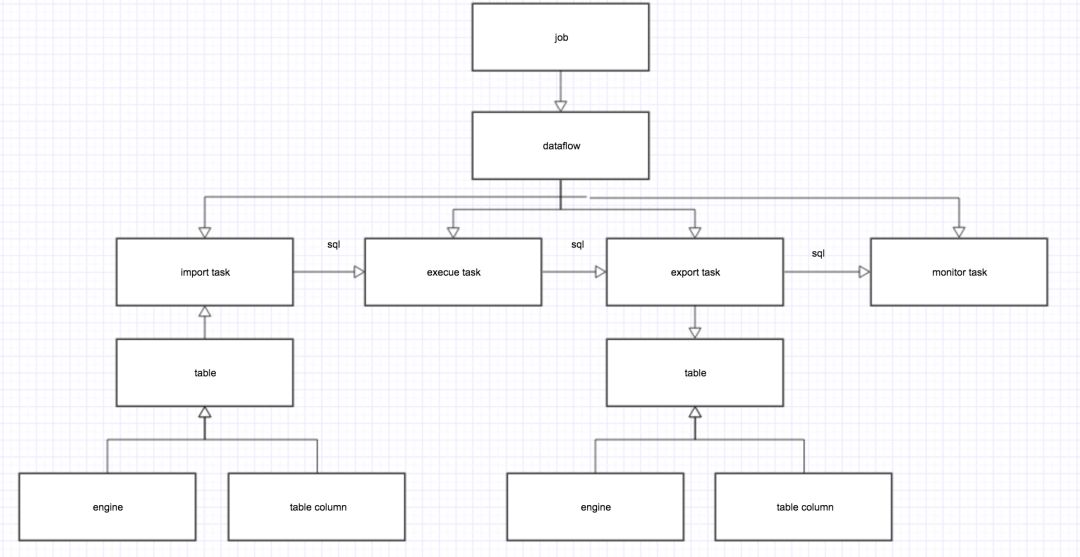
job
一个任务最高级别的抽象,任务启动的入口,任务的描述信息、资源配置都存储在其中
dataflow
数据流的抽象,理论上job和dataflow的关系是一对多,现支持一对一
task
任务执行的最小单位,保存任务的具体执行信息,dataflow和task的对应关系是一对多
–import task
数据导入任务,参数一般包括:数据引擎(engine)(一般为kafka),主要负责接入数据流并根据配置信息中的table和tablecolumn的信息解析数据流中数据,最终映射成spark 中的dataframe(table)
–execue task
数据处理任务,有多种,如sqlTask,cassandraQueryTask,cassandraHbaseTask等,每个task的最终返回结果都是dataframe(table)
–export task
数据导出任务,持久化一个或多个
dataframe(table)到不同的存储介质中
–monitor task
监测任务,记录任务每一个批次的执行信息,如offset信息、处理最小时间信息等
3 现有业务
现已支持dsp全部业务、智能策略组实时训练相关需求
已有job25个
后面将具体介绍对dsp相关业务的支持
4 后续规划
可视化工具开发,提升可用性
故障自动处理机制开发
二 DSP业务支持
数据磨坊现已支持dsp全部业务、智能策略组实时训练相关需求,智能策略组相关业务比较简单,就不在文档中介绍了,这里只介绍dsp相关业务。
1 现状
以前的dsp业务数据都是离线的,stage层数据每小时同步一次,最终产生报表肯定大于1小时
dsp业务的数据模型是维度建模(星型建模),故数据表分为两类:事实表和维度表,我们汇聚stage层数据到ods层中,形成事实表,然后在adm层进行一次最细维度的预聚合工作,然后聚合表各种上卷和维度表进行关联形成不同维度的报表,下图为简单流程图:
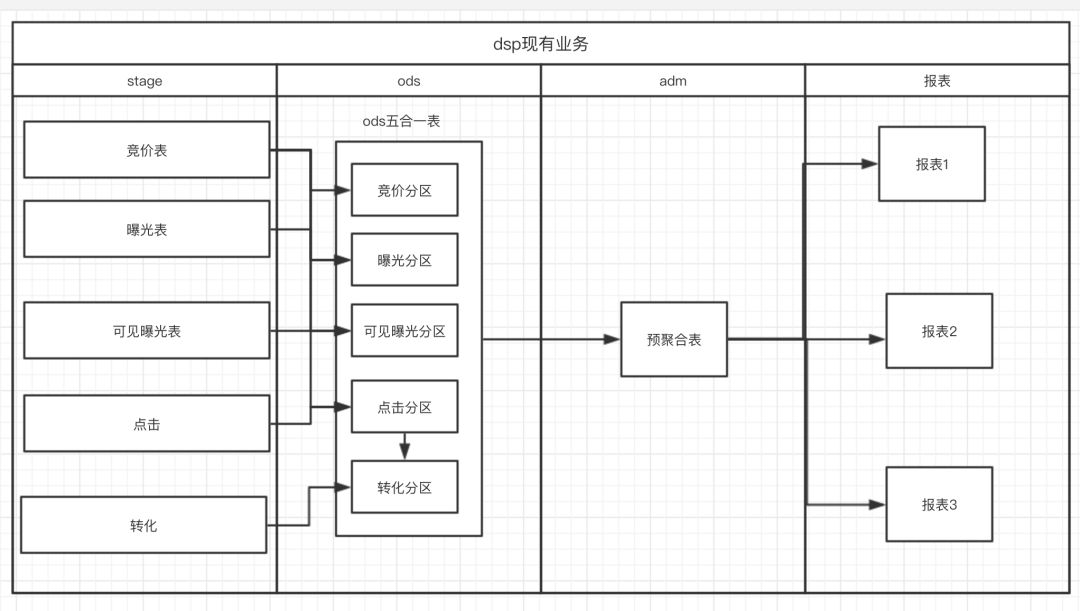
图中其他逻辑很明确,重点解释一下stage到ods层的逻辑,在竞价日志中的日志字段是最全的,所以我们在形成ods五合一表相应分区时,曝光日志、可见曝光日志、点击日志需要和竞价日志通过pvid关联获取相关字段形成分区中的数据,而转化日志中没有pvid,只能通过click_id和点击日志关联,故转化日志需要和ods五合一表中的点击表分区进行关联形成转化分区
2 业务需求
1.dsp商家需要在后台系统中看到收入金额,由于底层数据是每小时加载,加上计算的时间,接口的延迟时间大概是3个小时左右,业务方希望尽量缩短时间,这个需求最为迫切
2.我们小时级报表最小的延迟时间为3小时,业务方希望缩短这个时间
3 解决方案
经和需求方沟通,接口和报表的数据延迟时间定为15-30分钟,方案如下:
1.stage层直接从kafka中实时接入数据
2.stage到ods层实时进行关联,ods表延迟控制在1分钟以内
3.adm层的聚合15分钟进行一次
4.adm层聚合后马上跑报表
4 技术架构和难点
(1)技术架构
在理想情况下,流程图如下:
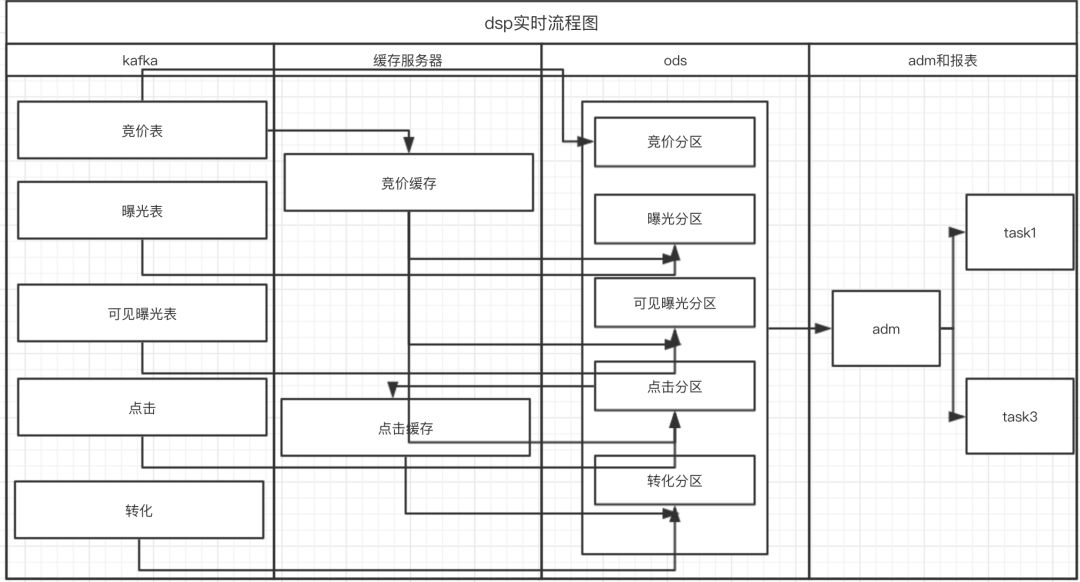
kafka日志接入
使用sparksteaming dirct方式接入数据,保证数据接入的稳定性及offset的准确性,在数据磨坊中相关导入模块已经实现
stage层到ods关联
–曝光日志、可见曝光日志、点击日志和竞价日志关联,我们采用的方案是cache竞价日志,其他日志实时流入和竞价日志关联。在离线中关联竞价日志的时间范围是36小时,所以在实时cache日志时间也是36小时
–转化日志需要和ods层的点击分区中数据进行关联,故点击日志和竞价日志关联后数据也要进行cache,然后转化日志再和该缓存中数据进行关联,cache时间同样是36小时
adm层聚合
直接把计算时间频次缩短为15分钟,生成15分钟分区
报表聚合
依赖adm层15分钟分区,计算报表
(2)问题及解决
改进后流程图过于复杂,就先不画了,主要问题及改进如下
缓存峰值对缓存服务器压力较大,开始选用hbase,但占用资源比较多,影响其他业务的使用。后搭建scylla(c版的cassandra),用比较小的资源解决了该问题
缓存延迟问题,如:竞价日志处理延迟,其他日志关联不上,最终被抛弃,造成数据丢失。最终的解决方案是,增加二次关联机制,关联不上的数据,进另外的一个job,在这个job中反复关联,1小时以上关联不上的数据才丢弃
同一个pv_id的请求,可见曝光日志可能比曝光日志来的早,造成关联不上,数据丢失。解决方案同上,增加二次关联机制
adm 15分钟任务启动时间问题,记录每个流式任务每批次中数据的最小处理时间,当前时间大于最小批次处理时间才启动adm 15分钟作业(如:15:16,adm 15分钟任务启动,需要跑15:00-15:15的分区,那么所有流的最近一个批次的最小时间要大于15:15)
增加了离线补数逻辑,应对极端情况
增加了故障自动处理机制,增强稳定性,提升工作效率
5 效果
达到目标,报表时间15-30分钟完成,效率提升600%以上
流式任务最长持续运行最长1个月,出现极端情况采用离线补数逻辑处理,基本满足业务需求
6 后续规划
增加稳定性
由于数据流天然的特性,很难支持数据流和cache中的数据进行left join,后续需支持
极端情况下,二次关联堆积数据量会比较大,需要持续改进


以上是关于流式计算在商业的应用实践的主要内容,如果未能解决你的问题,请参考以下文章