付力力: 基于Impala构建实时用户行为分析引擎
Posted 神策数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了付力力: 基于Impala构建实时用户行为分析引擎相关的知识,希望对你有一定的参考价值。
本文来自神策数据联合创始人&首席架构师付力力在 QCon 北京 2017 年全球软件开发者大会上的精彩分享,主题是“基于 Impala 构建实时用户行为分析引擎”。
付力力:大家好,今天的主题是“基于 Impala 构建实时用户行为分析引擎”。
我今天的分享共有四部分,第一,简单介绍一下什么是用户行为分析。第二,讲解用户行为分析需求,涉及的整体的架构以及这个架构下的整体数据模型。第三,讲解架构关键点——如何实现实时导入。第四,讲一些针对具体场景的查询性能优化点。
什么是用户行为分析
用户行为五大要素:4W1H
用户行为是非常普遍常见的定义,无非是谁在什么时候干了什么事情。有很多很多的例子,无论是线上 APP 的操作、网页浏览或者是线下购物,都包含了几个要素。首先有参与者,谁是这个中心的主体,这是必须包含的;其次发生的时间、地点、行为的方式、具体做了什么事情,都会构成用户行为的几大要素。
所以用户行为是非常普遍的容易做抽象处理的数据,生产活动会涉及到大量行为数据,这个数据可以被收集并产生很大的价值。从技术的角度讲,它是一种特化的日志数据。
其实大家在不知不觉中已经用到了用户行为数据,可能是做用户分析,产生一些 BI 报表,或者统计 PV、UV。其次是 PM 做产品改进,比如观察产品的用户黏性,或者新功能点给用户带来的影响、核心的交易流程或者注册流程的转化率符不符合预期,这些都与用户行为直接相关,用户行为分析也可以支持商务、市场、销售部门进行业务决策。
用户行为需求:灵活性>及时性>时效性
首先主要总结一下应用的需求特点:
时间轴、大量维度、维度取值分散;
分析灵活性要求高,查询模式变化多;
要求实时响应;
查询频率较低;
灵活性> 及时性 > 时效性。
需求特点非常显著,首先,行为数据有一个最大的特点是时间轴:随着时间不断累计。且维度非常多,因为业务的范围千差万别。另一个特点是灵活性要求非常高,因为什么业务都可以基于用户行为分析来做。另外是行为分析要求及时性。与传统的 BI 报表相比,最大的区别在于用户行为分析需要反复迭代和尝试。最后,行为分析查询频率比较低,不需要它支撑频率较高的业务。
在整体设计目标上,系统的灵活性必须是第一位,其次是及时性,就是能够实时响应分析的需求,让分析人员能够快速迭代,最后是时效性。
如何搭建整体架构及数据模型简介
如何选择合适的查询引擎
现在有非常多的查询引擎,大家支持的特性和业务场景都差万别,我们在选择查询引擎的时候,需要有两个特点,一方面是足够灵活。能够比较完善地支持标准的SQL。另一方面是要足够快。查询引擎只是支持SQL很简单,无非就是速度慢,但有一个很大的问题,不够快的查询引擎,不能实现交互查询,不能满足快速分析迭代的需求。
详细解析 Impala 架构
我们选择 Impala,因为今天的整个架构优化是围绕 Impala 来讲的,所以简单讲一下 Impala 本身有什么特点:
大部分功能特性和 Hive 类似;
基于MPP 的查询引擎;
较低的容错性;
较高的内存需求;
较高的查询效率。
首先,Impala 出现的时间不短,功能特性上和 Hive 比较像,但是它是基于 MPP 的查询引擎,这是和 Hive 比较大的区别。Hive 的查询执行层完全基于如 MapReduce、Spark 的底层的执行引擎,本身并不包含执行层的东西,但是 Impala 是一个含有自己的 MPP 执行层的查询引擎,这是它能实现较快查询的本质原因。第三,容错性较差,Impala 不像MR或 SPARK,故障之后会有自动重试机制。第四,内存需求比较高,绝大部分中间的数据操作都会在内存中完成。第五,查询效率比较高,这是选择它的最大原因。
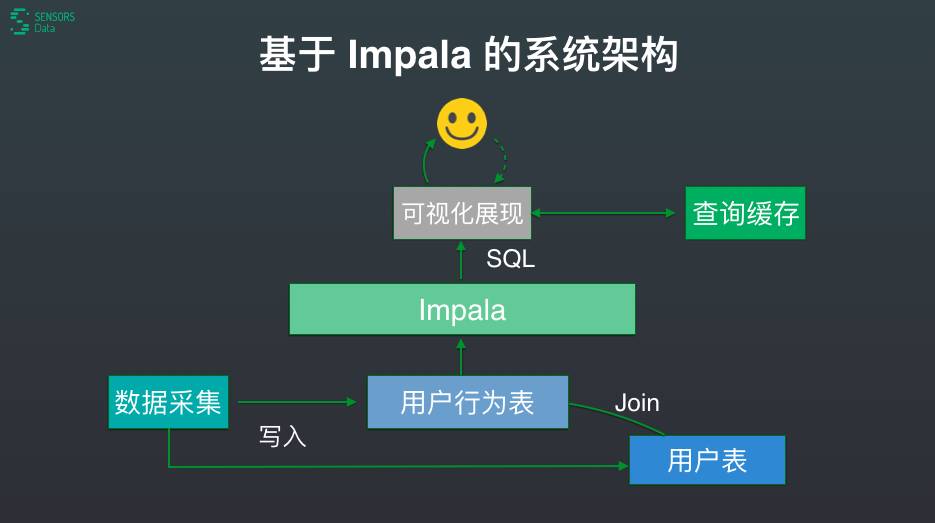
很多客户会问我们,为什么他们用 Impala 这么慢,这里有很重要的一点,Impala 官方推荐的是与数据节点要同机混部,实际上很多企业没有做到这点。基于 Impala 可以推导出一个非常简单的系统架构,最前端的头像表示用户使用交互界面,之后把前端用户查询的需求转化成 SQL 发给 Impala,左侧是数据采集,会实时写入用户行为表,右侧是查询缓存。
有两个表非常重要:用户行为表和用户表。神策的架构非常简化,因为数据模型简单。我们的数据源多种多样,例如客户端操作、服务端日志、订单数据、注册数据、业务数据、商品的信息、书或漫画的信息,客户通过 SDK 和导入工具可以导入这些数据,最终构建了用户行为表和用户表。概念虽然简单,但是却是架构的核心。首先,简单的模型有助于大大减少 ETL 计算成本和管理数据的成本。其次,在业务上两张表的逻辑便于业务员了解,这点很重要,因为最终的设计还是为业务服务的。
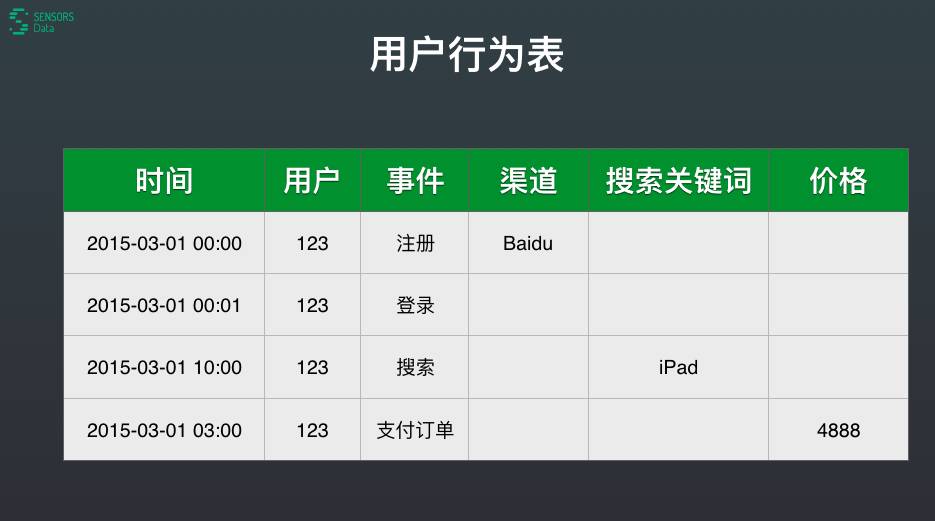
用户行为表就是每一条数据代表一个用户的行为,简单抽象,整个表非常宽,设计物理存储的时候需要考虑这个因素。
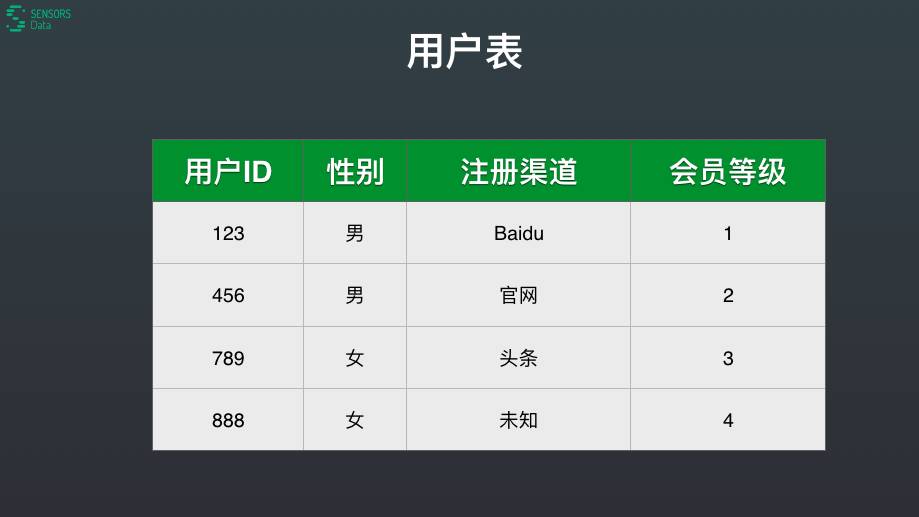
 用户表相对简单一些,记录了用户当前的状态,可更新。
用户表相对简单一些,记录了用户当前的状态,可更新。
在物理存储上,神策用 HDFS 存储数据。目录结构按日期做分区,每个分区存 N 个文件,每个文件是 Parquet 的文件。结构虽然简单,但是做分区和文件切割时,保持合理大小,Parquet 的扫描性能才能达到预期效果。以及,我们还会在存储时做一些局部排序。
用 Parquet 格式,是非常主流的做法,但是因为 Parquet 是一个支持批量写入、无法追加的文件格式,所以无法实现实时的数据流。
Kudu 优化查询视图
Kudu 作为新一代面向实时分析的存储引擎:
底层使用类似 Parquet 的存储结构;
支持实时写入、实时更新及随机查询;
扫描性能比 Parquet 略差。
在引入 Kudu 后,架构发生了变化,中间虚线框是用户行为表下的一个 HDFS 文件,上面是 Parquet 文件,实时写入 Kudu 后,有一个第三方模块定时把 Kudu 的数据转化成 Parquet 的数据,存储在 HDFS 上。顶层形式是两张物理的表,一张在 Kudu 一张在 Parquet,在上层构建一个查询试图,这个查询视图有两个优点,1. Kudu 实时的特性,能够达到秒级的实时写入,并发写入量非常可观,很容易达到 3-5 万的写入量;2. 保留了 Parquet 高速扫描的能力。
虽然底层是两张表,但是从上层应用或者系统其他模块看,顶层是一张表。这就是刚才讲的,使用 UNION ALL,能够让数据拷贝零损耗,达到查询上层和底层的视图完全等效。
查询性能优化 Tips
基本查询优化
这个架构为什么能够满足行为分析的查询需求,很重要的是查询优化。
首先要有合理的硬件。我们给客户做系统部署时,都会按照我们的要求做严格的基准测试。CPU 以 16 核为主,正常 IO 的磁盘,不要用性能很差的磁盘或虚拟磁盘,至少要千兆网络,内存要 64G,不要用十台 8G 的的机器充当一台 64G 的机器。
其次,就是写好 SQL。很多查询系统慢的重要原因是 SQL 写的不好。 Impala 有一个缺陷,资源隔离做的不是特别好,写的很烂的 SQL 会导致整个系统资源完全被占满,无法进行其他工作。
我们用三个标准节点做了一些基准测试,在不做任何其它优化的情况下,基本 10 秒内可以完成 10 亿内行为数据的分组聚合。大家如果没有达到这个效果,可能需要反思一下是不是硬件配置有问题,或者是 Parquet 文件大小不合适等前面提过的原因。
后面是一些特定场景下的优化点供大家参考,不一定每人都能用到。
查询抽样
为什么要做抽样:节约成本、提高效率。
查询抽样 vs 采集抽样:
(1)存储便宜,应该尽量存储最全的数据。
(2)抽样分析的局限性,例如细分维度的分析。
有一些业务点只有少数用户能触发,采集抽样可能会达不到抽样的结果,偏差很大。
查询抽样的抽样逻辑:首先按照用户抽样,不能随机抽样,必须保证用户行为的完整性,
抽样实现有非常多的方式。
根据用户 ID 的 Hash 值得到抽样编号。
Parquet / Kudu 数据按照抽样编号排序。
Impala 进行查询扫描时根据需要只扫描需要部分的数据。
实现转化漏斗
漏斗是非常常见的产品应用,可以分析产品各个流程的转化。神策分析可以实现任意定义转化逻辑,任意选择查询时段,得到每个用户精确的转化信息。
计算逻辑
从用户行为表抽取需要的事件数据。
事件数据按照用户 ID 分组,每个分组内按照时间排序,得到用户序列。
进行具体的转化逻辑计算。
实现方式
实现自定义的分析函数(UDAnF),需要对 Impala 进行改造
优化最耗时的步骤:全局排序 -> 预排序 + 归并排序
Join 优化
优化逻辑
使用每天的活跃用户数据构建 Bloom Filter;
Join 之前先用 Bloom Filter 对用户表进行过滤;
优化效果:Join 右表的数据量从数亿降到数千万。
总结
综上所述,架构的数据模型非常简化,用户表加用户行为表,这是大前提,基于这个数据模型选择支持 SQL 的通用查询引擎:Impala 和 Kudu,针对应用场景进行针对性的性能优化,最后完成实时用户引擎的构建。
以上是关于付力力: 基于Impala构建实时用户行为分析引擎的主要内容,如果未能解决你的问题,请参考以下文章