Impala:大数据丛林中敏捷迅速的黑斑羚
Posted 中兴大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Impala:大数据丛林中敏捷迅速的黑斑羚相关的知识,希望对你有一定的参考价值。
文 | 徐东辉
在大数据蓬勃发展的今天,基于Hadoop黄金搭档HDFS和MapReduce的Hive,已经无法满足人们对于海量数据处理速度越来越快的要求。时势造英雄,Cloudera依据Google的Dremel为原型开发了跨时代的查询引擎:Impala。
Impala的本意是黑斑羚,产于非洲中南部,行动敏捷,奔跑迅速。下面我们就来揭开这只敏捷迅速黑斑羚的神秘面纱,以飨各位看官。
概述
Impala是基于MPP的SQL查询系统,可以直接为存储在HDFS或HBase中的Hadoop数据提供快速、交互式的SQL查询。Impala和Hive一样也使用了相同的元数据、SQL语法(Hive SQL)、ODBC驱动和用户接口(Hue Beeswax),这就很方便地为用户提供了一个相似并且统一的平台来进行批量或实时查询。
Impala系统架构图如下所示:
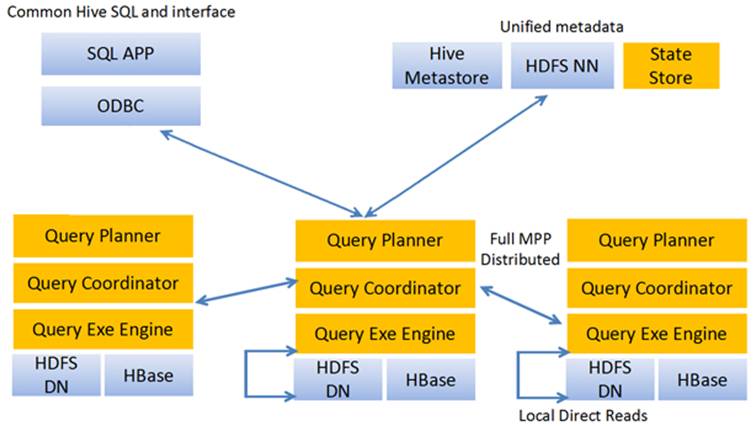
Impala主要包括以下组成部分:
Impala Shell:客户端工具,提供一个交互接口ODBC,供使用者连接到Impalad发起数据查询或管理任务等。
Impalad:分布式查询引擎,由Query Planner、Query Coordinator和Query Exec Engine三部分组成,可以直接从HDFS或者HBase中用SELECT、JOIN和统计函数查询数据。
State Store:主要为跟踪各个Impalad实例的位置和状态,让各个Impalad实例以集群的方式运行起来。
Catalog Service:主要跟踪各个节点上对元数据的变更操作,并且通知到每个节点。
Impala支持以下特性:
支持ANSI-92 SQL所有子集,包括CREATE/ALTER/SELECT/INSERT/JOIN/subqueries
支持分区join、完全分布式聚合以及完全分布式top-n查询
支持多种数据格式:Hadoop原生格式(apache Avro,SequenceFile,RCFile with Snappy,GZIP, BZIP或未压缩)、文本(未压缩或者LZO压缩)和Parquet(Snappy或未压缩)
可以通过JDBC、ODBC、Hue GUI或者命令行shell进行连接
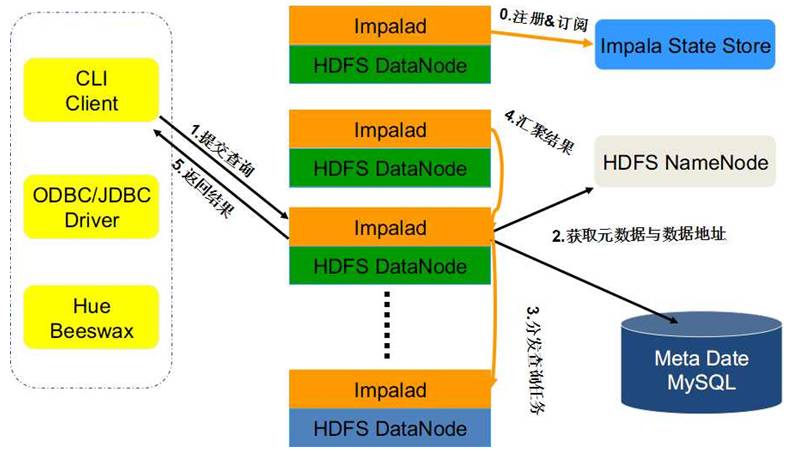
查询处理流程
Impalad分为Java前端(Frontend)与C++处理后端(Backend),接受客户端连接的Impalad即作为这次查询的Coordinator,Coordinator通过JNI调用Java前端对用户的查询SQL进行分析生成执行计划树,不同的操作对应不用的PlanNode, 如:SelectNode, ScanNode, SortNode, AggregationNode, HashJoinNode等等。
执行计划树的每个原子操作由一个PlanFragment表示,通常一条查询语句由多个Plan Fragment组成, Plan Fragment 0表示执行树的根,汇聚结果返回给用户,执行树的叶子结点一般是Scan操作,分布式并行执行。
Java前端产生的执行计划树以Thrift数据格式返回给Impala C++后端Coordinator,执行计划分为多个阶段,每一个阶段叫做一个PlanFragment,每一个PlanFragment在执行时可以由多个Impalad实例并行执行(有些PlanFragment只能由一个Impalad实例执行,如聚合操作),整个执行计划即为一个执行计划树。Coordinator收到执行计划后,数据存储信息(Impala通过libhdfs与HDFS进行交互,通过hdfsGetHosts方法获得文件数据块所在节点的位置信息),通过调度器(现在只有simple-scheduler, 使用round-robin算法)Coordinator::Exec对生成的执行计划树分配给相应的后端执行器Impalad执行(查询会使用LLVM进行代码生成,编译,执行),通过调用GetNext()方法获取计算结果,如果是insert语句,则将计算结果通过libhdfs写回HDFS,当所有输入数据被消耗光,执行结束,之后注销此次查询服务。
Impala查询处理流程如下图所示:
访问Impala
访问Impala有两种方式,一种是使用命令行工具impala-shell,另一种是使用JDBC编程,下面分别阐述。
Impala-shell
可以通过命令行工具Impala-shell来创建数据库、表、插入数据、执行查询等。
Impala shell命令格式如下:
impala-shell [选项]
impala-shell使用选项如下:
选项 |
描述 |
-B or --delimited |
导致使用分隔符分割的普通文本格式打印查询结果。当为其他 Hadoop 组件生成数据时有用。对于避免整齐打印所有输出的性能开销有用,特别是使用查询返回大量的结果集进行基准测试的时候。使用 --output_delimiter 选项指定分隔符。使用 -B 选项常用于保存所有查询结果到文件里而不是打印到屏幕上。 |
--print_header |
是否打印列名。整齐打印时是默认启用。同时使用 -B 选项时,在首行打印列名 |
-o filename or --output_file filename |
保存所有查询结果到指定的文件。通常用于保存在命令行使用 -q 选项执行单个查询时的查询结果。对交互式会话同样生效;此时你只会看到获取了多少行数据,但看不到实际的数据集。当结合使用 -q 和 -o 选项时,会自动将错误信息输出到 /dev/null。 |
--output_delimiter=character |
当使用 -B 选项以普通文件格式打印查询结果时,用于指定字段之间的分隔符。默认是制表符 tab ('\t')。假如输出结果中包含了分隔符,该列会被引起且/或转义。 |
-p or --show_profiles |
对 shell 中执行的每一个查询,显示其查询执行计划 (与 EXPLAIN 语句输出相同) 和发生低级故障的执行步骤的更详细的信息 |
-h or --help |
显示帮助信息 |
-i hostname or --impalad=hostname |
指定连接运行 impalad 守护进程的主机。默认端口是 21050。你可以连接到集群中运行 impalad 的任意主机。假如你连接到 impalad 实例通过 --fe_port 标志使用了其他端口,则应当同时提供端口号,格式为 hostname:port |
-q query or --query=query |
从命令行中传递一个查询或其他 shell 命令。执行完这一语句后 shell 会立即退出。限制为单条语句,可以是 SELECT, CREATE TABLE, SHOW TABLES, 或其他 impala-shell 认可的语句。因为无法传递 USE 语句再加上其他查询,对于 default 数据库之外的表,应在表名前加上数据库标识符(或者使用 -f 选项传递一个包含 USE 语句和其他查询的文件) |
-f query_file or --query_file=query_file |
传递一个文件中的 SQL 查询。文件内容必须以分号分隔 |
-k or --kerberos |
当连接到 impalad 时使用 Kerberos 认证。如果要连接的 impalad 实例不支持 Kerberos,将显示一个错误 |
-s kerberos_service_name or --kerberos_service_name=name |
指示impala-shell对特定impalad服务主体进行身份验证。 如果没有设置 kerberos_service_name ,默认使用 impala。如果启用了本选项,而试图建立不支持Kerberos 的连接时,返回一个错误。 |
-V or --verbose |
启用详细输出 |
--quiet |
关闭详细输出 |
-v or --version |
显示版本信息 |
-c |
查询执行失败时继续执行 |
-r or --refresh_after_connect |
建立连接后刷新 Impala 元数据,与建立连接后执行 REFRESH 语句效果相同 |
-d default_db or --database=default_db |
指定启动后使用的数据库,与建立连接后使用 USE 语句选择数据库作用相同,如果没有指定,那么使用 default 数据库 |
-l |
启用 LDAP 认证 |
-u |
当使用 -l 选项启用 LDAP 认证时,提供用户名(使用短用户名,而不是完整的 LDAP 专有名称distinguished name),shell 会提示输入密码 |
JDBC编程
Impala支持JDBC访问,JAVA程序通过JDBC驱动访问Impala。配置Impala的JDBC连接包括以下步骤:
配置Impala JDBC端口
默认的Impala JDBC访问端口是21050,确保Impala上此端口能被其他机器访问;如果使用其他端口,启动impalad时带上--hs2_port参数。
在客户端安装Impala JDBC驱动
客户端impala JDBC驱动包含一些jar文件,文件列表如下:
下载上述jar文件到impala JDBC客户端。
保存jar文件到CLASSPATH路径中。
设置CLASSPATH环境变量包含jar文件路径
在linux系统:增加jar路径到CLASSPATH前面:比如jar文件保存到/opt/jars/,设置命令为:export CLASSPATH=/opt/jars/*.jar:$CLASSPATH
在windows系统:在“系统属性”控制面板中修改“环境变量”,设置CLASSPATH开头包含jar文件路径
Java应用程序配置JDBC连接字符串,连接Impalad
JDBC驱动类是org.apache.hive.jdbc.HiveDriver,连接分为以下几种:
连接的Impala集群没有使用Kerberos鉴权,JDBC连接字符串形式为:jdbc:hive2://host:port/;auth=noSasl
连接的Impala集群使用Kerberos鉴权,JDBC连接字符串形式为:jdbc:hive2://host:port/;principal=principal_name
连接的Impala集群使用LDAP鉴权,JDBC连接字符串形式为:jdbc:hive2://host:port/db_name;user=ldap_userid;password=ldap_password
下面的例子使用Impala JDBC编程接口查询指定表的数据:

性能调优
Impala性能调优使用以下方法:
选择合适的文件格式
通常情况,对大量数据,Parquet文件格式是最好的,因为它结合了列存储布局、大的I / O请求大小、压缩和编码。
避免数据摄入过程产生许多小文件
使用INSERT……SELECT复制表数据,避免对任何海量数据或影响性能的关键型表使用INSERT……VALUES,因为每一个这样的语句产生一个单独的小数据文件。
如果在数据处理中产生过多小文件,需要使用INSERT……SELECT将数据复制到另外一张表,这样解决了小文件过多的问题。
选择合适的分区技术
分区是一种技术,基于一个或多个列的值物理上把数据分成多部分。当你发出查询请求一个特定分区键列的值或值范围,Impala可以避免读取无关的数据可能产生的巨大的磁盘I / O。
分区技术适用于以下情况:
表的数据量非常大,读取整个表的时间不在我们的承受范围之内
表总是依据某些特定的列进行查询
列有合理的基数(不同值的数量)
数据已经经过ETL处理
使用COMPUTE STATS搜集连接查询中海量数据表或者影响性能的关键表的统计信息
最小化返回结果给客户端的传输开销
使用聚合、过滤、限制、避免精细打印结果集等方法返回最小化结果。
在运行查询前使用EXPLAIN查看执行计划是否高效合理
在运行查询后使用PROFILE从底层确认IO、内存消耗、网络带宽占用、CPU使用率等信息是否在预期范围内
以上是关于Impala:大数据丛林中敏捷迅速的黑斑羚的主要内容,如果未能解决你的问题,请参考以下文章