如何在Impala中实现拉链表
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在Impala中实现拉链表相关的知识,希望对你有一定的参考价值。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
Fayson的github:https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档目的
拉链表是针对数据仓库设计中表存储数据的方式而定义的,即是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。传统数据仓库一般采用拉链的方式保留主数据(例如客户信息)的变化数据,采用这种设计方式的主要原因是减少数据冗余。这个需求在Hadoop中主要是有以下两种实现方式选择:
1.每天保留一份全量的切片数据。Hadoop平台由于采用通用的硬件设备,因此存储空间的成本较低,因此建议采用时间切片的方式保留每天的主数据信息。当前数据单独存放在当前表中,历史数据存放在历史表中,并按时间分区。
2.在Hadoop之上也可以实现拉链表。当前数据单独存放在当前表中(即下面要介绍的USER表),发生变化的历史数据存放在历史表中(即下面要介绍的USER_HIS表),每条数据按照start_dt和end_dt做拉链。
本文主要是使用Impala基于上面介绍的方案2来做实操讲解。我们知道HDFS是一个append-only的存储系统,所以Hive/Impala表都无法进行update操作。所以在拉链表有update操作时,需要改写SQL来实现,具体可以参考本文后面的SQL和脚本。以下我们先来看看拉链表的具体实现:
1.首先我们需要一份ODS层的用户全量表,用它来初始化,图中是‘2018-01-15’。在拉链表USER_HIS中创建开链分区‘9999-12-31’,并将‘2018-01-15’的USER表中的数据start_dt都设置为‘2018-01-15’,end_dt都设置为‘9999-12-31’并插入到USER_HIS的‘9999-12-31’分区中。
2.假设过了一天,到了‘2018-01-16’。这时最新的‘2018-01-16’的用户全量表已经insert overwrite到USER表中。这时我们首先在拉链表USER_HIS中创建闭链分区‘2018-01-16’,然后通过比较最新USER表和USER_HIS表的开链(分区为‘9999-12-31’)数据,找到变化数据,做成闭链(start_dt为‘2018-01-15’, end_dt为‘2018-01-16’)后插入到USER_HIS的闭链分区‘2018-01-16’中。
3.通过USER表,USER_HIS的‘2018-01-16’分区和‘9999-12-31’分区的数据,通过较为复杂的SQL将‘2018-01-16’那天没变的数据,新增的数据(start_dt需设为‘2018-01-16’),更新的数据(start_dt也需设为‘2018-01-16’)一起insert overwrite到拉链表USER_HIS的9999-12-31’中。
4.后面每天的操作基本相似。
文档概述
1.拉链表设计
2.拉链流程实现
3.总结
测试环境
1.CM和CDH版本为5.13.1
前置条件
1. 集群已安装Impala
2.拉链表设计
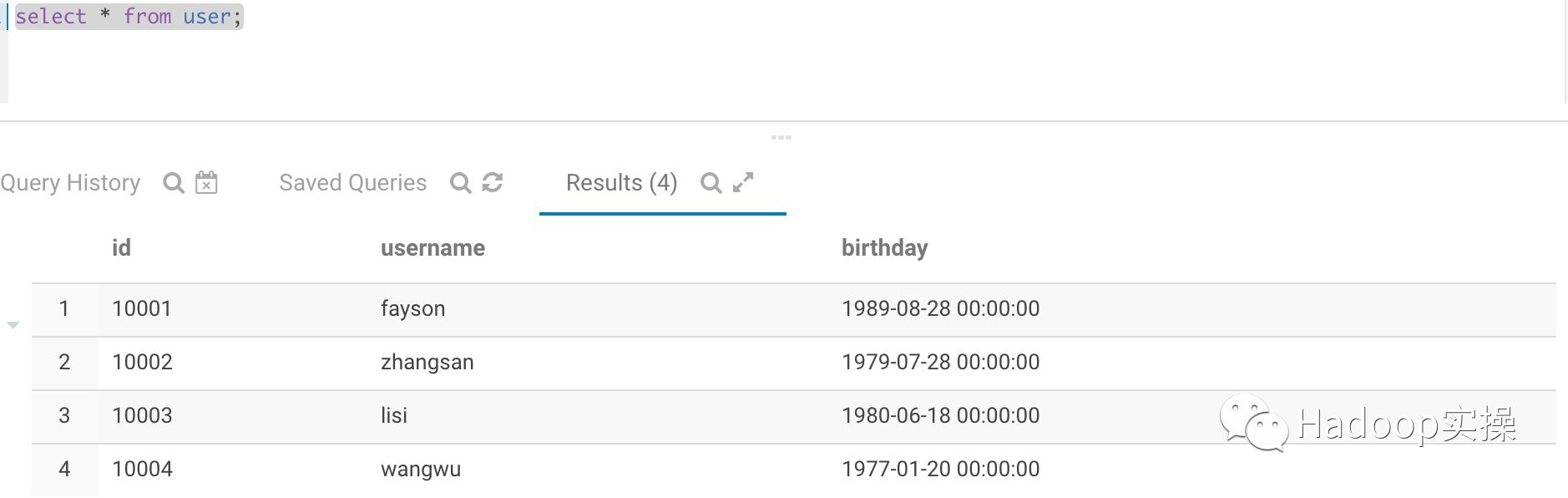
1.用户表USER,用于存储用户最新的全量信息
表字段 |
类型 |
描述 |
id |
bigint |
用户ID |
username |
string |
用户名称 |
birthday |
timestamp |
用户生日 |
建表语句:
create table user(
id bigint,
username string,
birthday timestamp
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS parquet;
(可左右滑动)
初始数据:
INSERT INTO user values
(10001, 'fayson', '1989-08-28'),
(10002, 'zhangsan', '1979-07-28'),
(10003, 'lisi', '1980-06-18'),
(10004, 'wangwu', '1977-01-20');
(可左右滑动)
2.用户拉链表USER_HIS
表字段 |
类型 |
描述 |
id |
Bigint |
用户ID |
username |
string |
用户名称 |
birthday |
timestamp |
用户生日 |
start_dt |
timestamp |
拉链开始时间 |
end_dt |
timestamp |
拉链闭链时间 |
建表语句:
create table user_his(
id bigint,
username string,
birthday timestamp,
start_dt timestamp
) partitioned by (end_dt string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS parquet;
(可左右滑动)
我们在这里使用了分区表,主要是为了能够实现拉链数据的更新和删除。
3.使用上面的表创建USER和USER_HIS表,并初始化USER表数据。

3.拉链流程实现
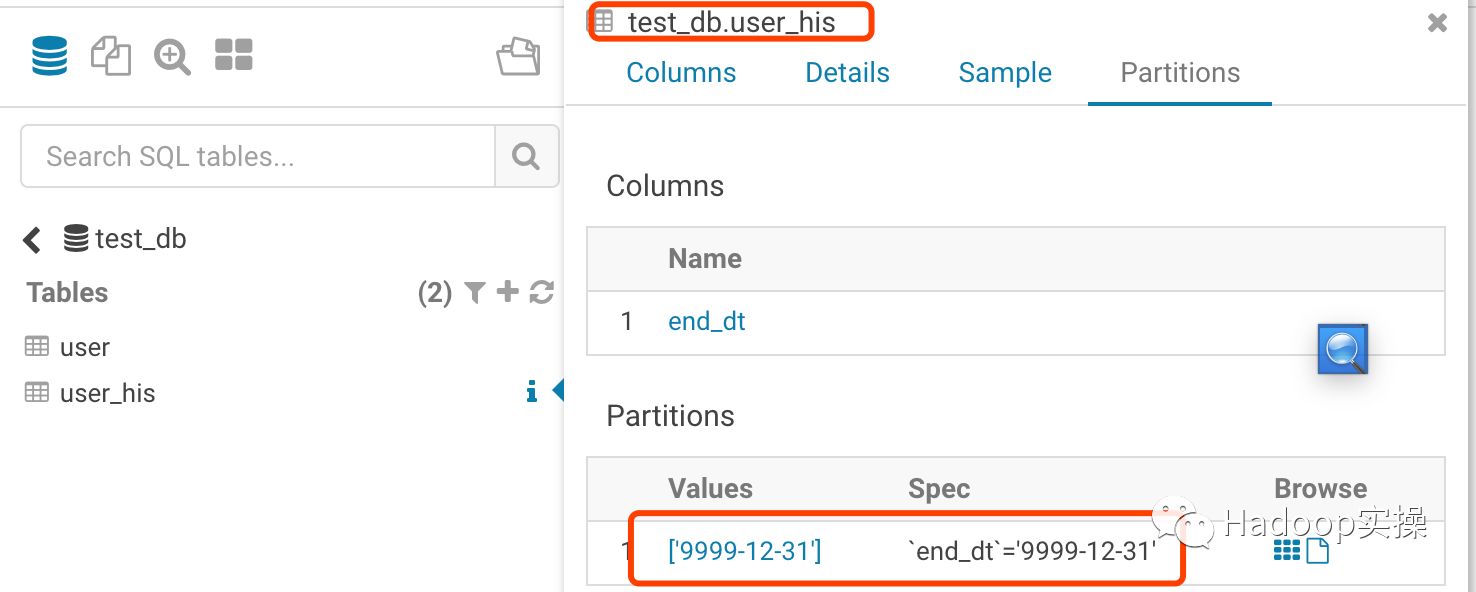
1.首先在USER_HIS表中创建一个’9999-12-31’的分区用于存储所有用户开链数据
ALTER TABLE user_his ADD PARTITION (end_dt='9999-12-31');
(可左右滑动)
2.首次USER_HIS表中无任何数据,通过USER表数据初始化拉链表USER_HIS表数据,插入所有用户的开链数据
INSERT overwrite TABLE user_his PARTITION (end_dt = '9999-12-31')
SELECT id,
username,
birthday,
from_timestamp(adddate(now(), -3), 'yyyy-MM-dd')
FROM USER;
(可左右滑动)
这里用三天前的日期方便演示,此时拉链表的数据如下:
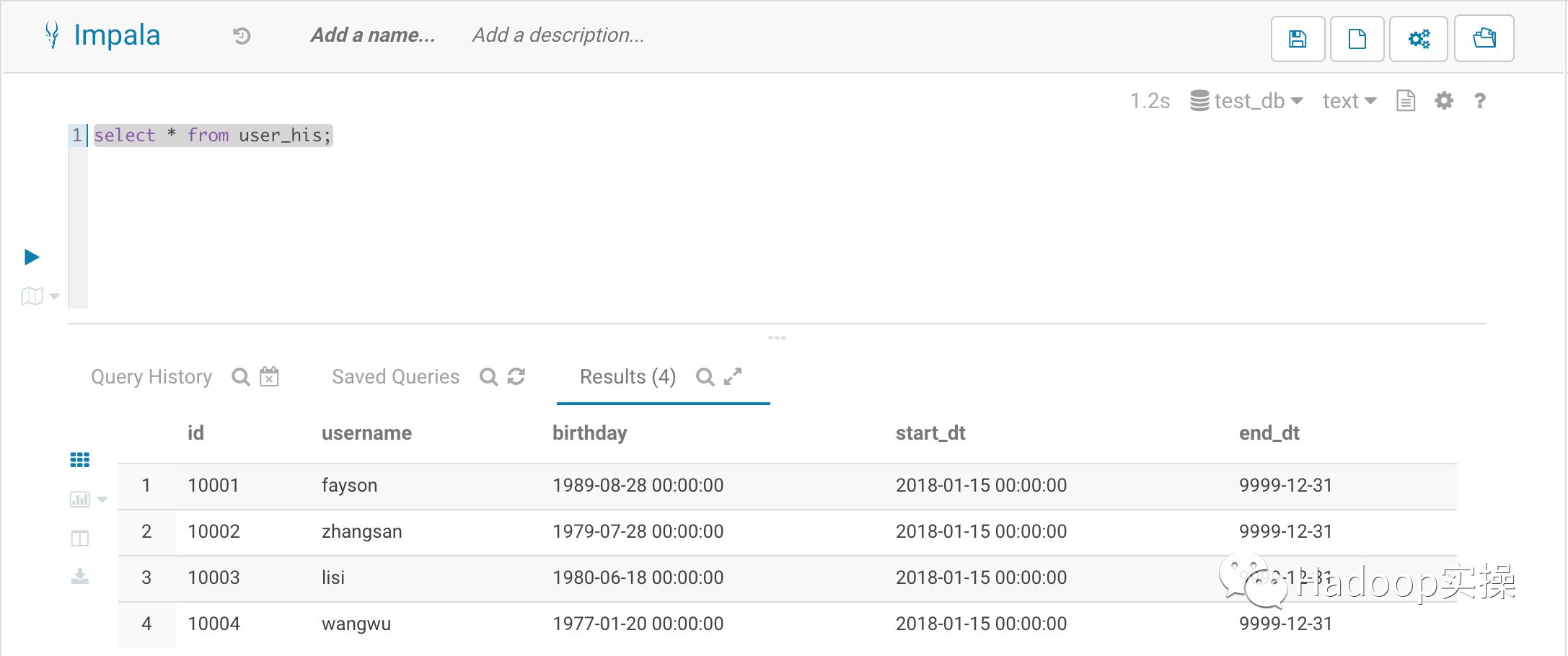
所有用户数据为开链状态。
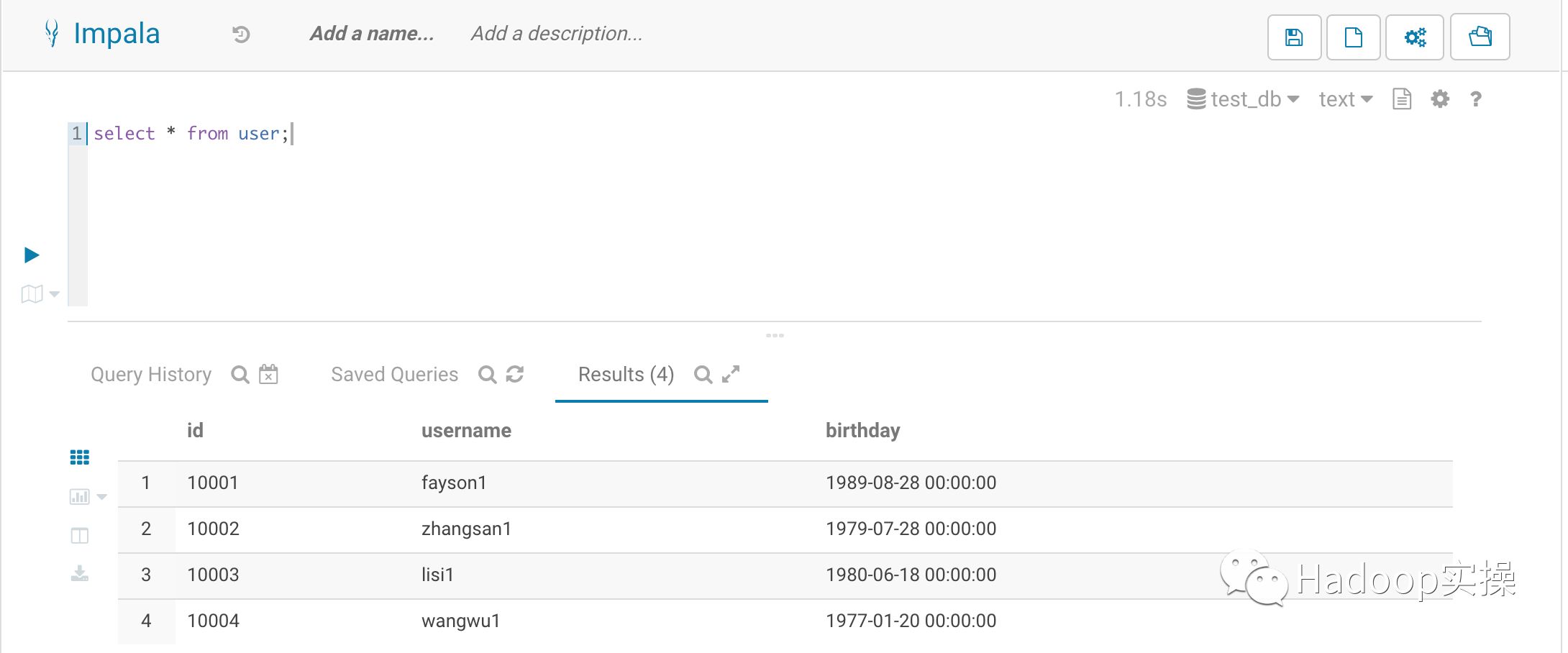
3.为了与拉链表对比用户数据的变更,这里把USER表的username修改为如下
INSERT overwrite TABLE USER
SELECT id,
concat(username,'1'),
birthday
FROM USER;
(可左右滑动)
4.在拉链表上创建”2018-01-16”的分区
--ALTER TABLE user_his ADD PARTITION (end_dt= from_timestamp(now(), 'yyyy-MM-dd'));
ALTER TABLE user_his ADD PARTITION (end_dt= "2018-01-16");
(可左右滑动)
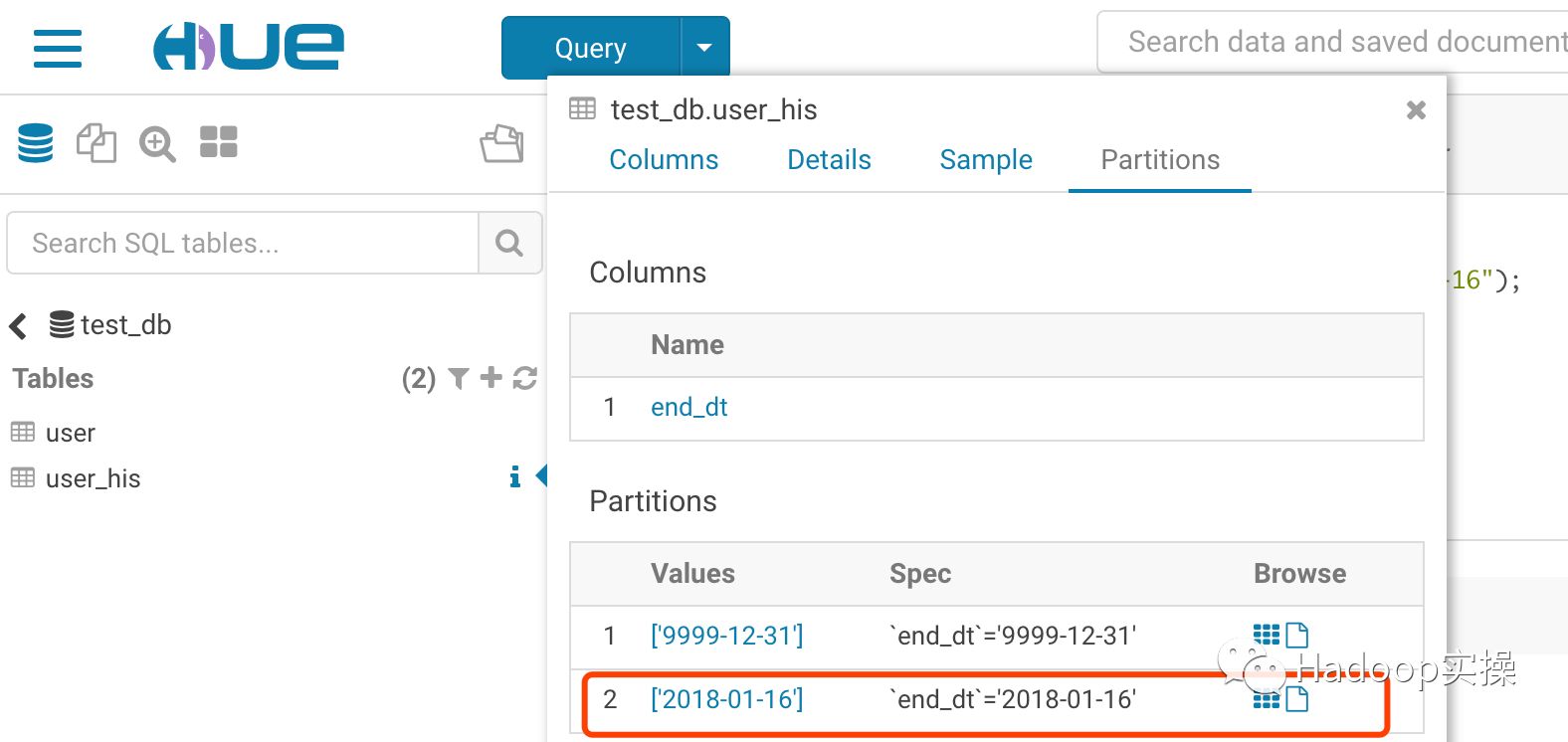
5.将修改的USER表用户数据与USER_HIS表中开链数据比对,将可以闭链的数据插入”2018-01-16”分区
INSERT overwrite TABLE user_his PARTITION (end_dt = "2018-01-16")
SELECT b.id,
b.username,
b.birthday,
b.start_dt
FROM USER a
LEFT JOIN user_his b ON a.id=b.id
WHERE b.end_dt = '9999-12-31'
AND (a.username != b.username
OR a.birthday != b.birthday);
(可左右滑动)
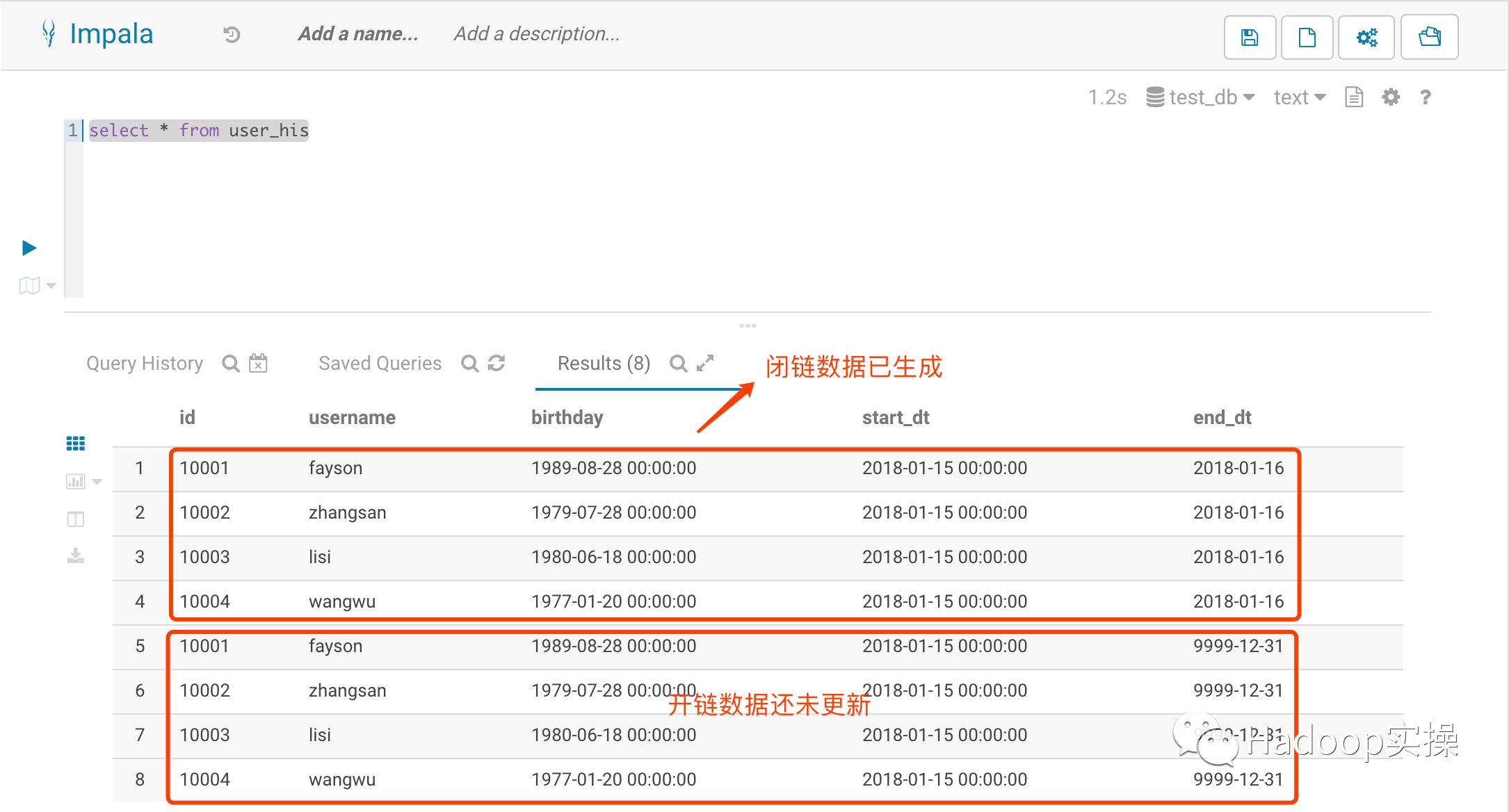
执行完上述语句后可以看到之前开链的数据已闭链,但用户的开链信息还未更新。
6.在用户表中新增一条用户信息,模拟用户表数据不存在拉链表的开链数据中
INSERT INTO user VALUES (10005, 'zhaoda', '1976-02-09');
(可左右滑动)
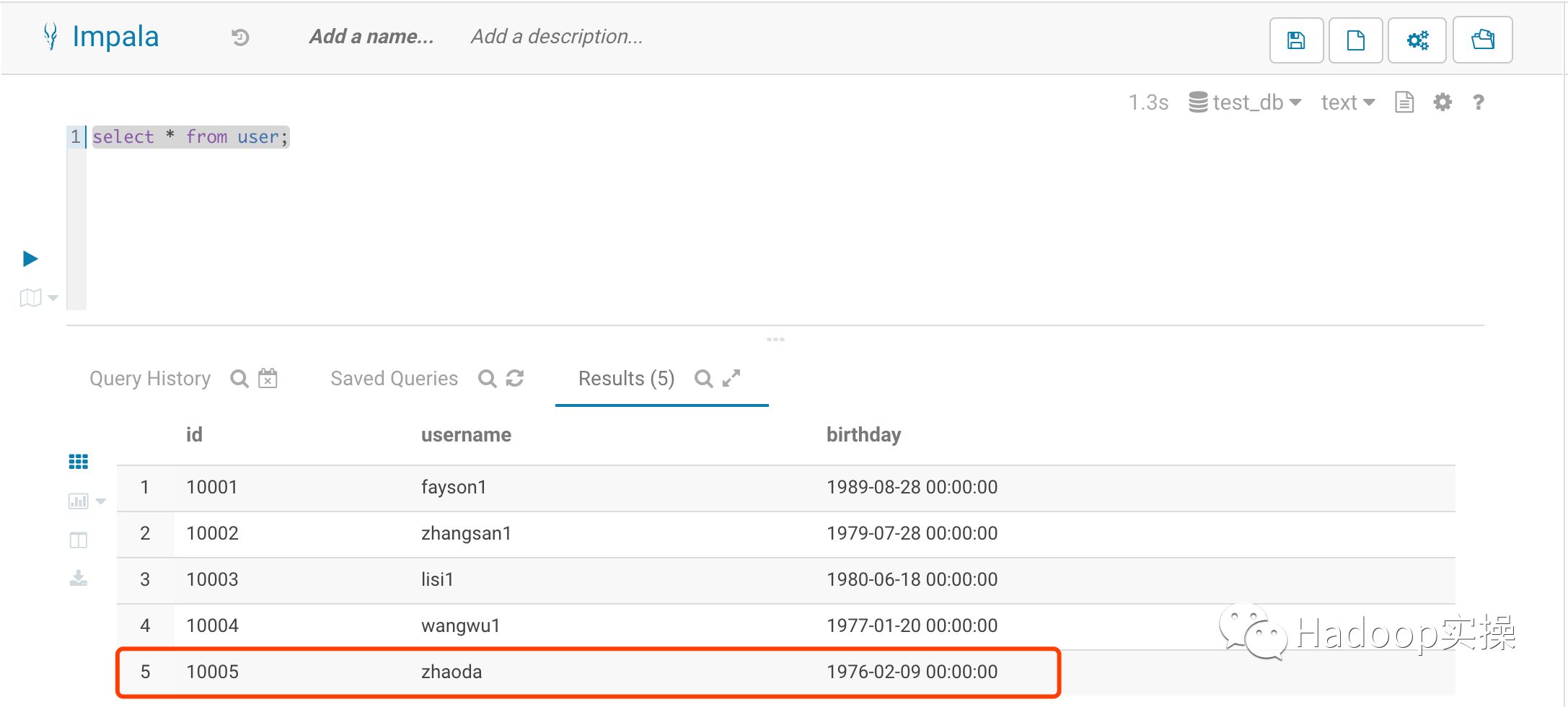
7.更新拉链表USER_HIS的开链数据(包含已更新的用户、未更新用户和新增用户)
INSERT overwrite TABLE user_his PARTITION(end_dt = '9999-12-31')
SELECT a.id,
a.username,
a.birthday,
b.end_dt AS start_dt
FROM USER a
LEFT JOIN user_his b ON a.id = b.id
WHERE b.end_dt = "2018-01-16"
union all
SELECT b.id,
b.username,
b.birthday,
b.start_dt
FROM user_his b
WHERE NOT EXISTS
(SELECT id
FROM user_his c
WHERE c.end_dt = "2018-01-16" and b.id = c.id)
AND b.end_dt = '9999-12-31'
union ALL
SELECT a.id,
a.username,
a.birthday,
"2018-01-16" AS start_dt
FROM USER a
WHERE NOT EXISTS
(SELECT 1
FROM user_his b
WHERE end_dt = '9999-12-31'
AND a.id = b.id);
(可左右滑动)

8.模拟更新部分用户信息,验证拉链业务是否正常
用户最新开链数据:

USER表数据
INSERT INTO user values
(10001, 'fayson2', '1989-09-27'),
(10002, 'zhangsan2', '1979-07-28'),
(10003, 'lisi1', '1980-06-18'),
(10004, 'wangwu1', '1977-01-20'),
(10005, 'zhaoda', '1976-02-09');
(可左右滑动)
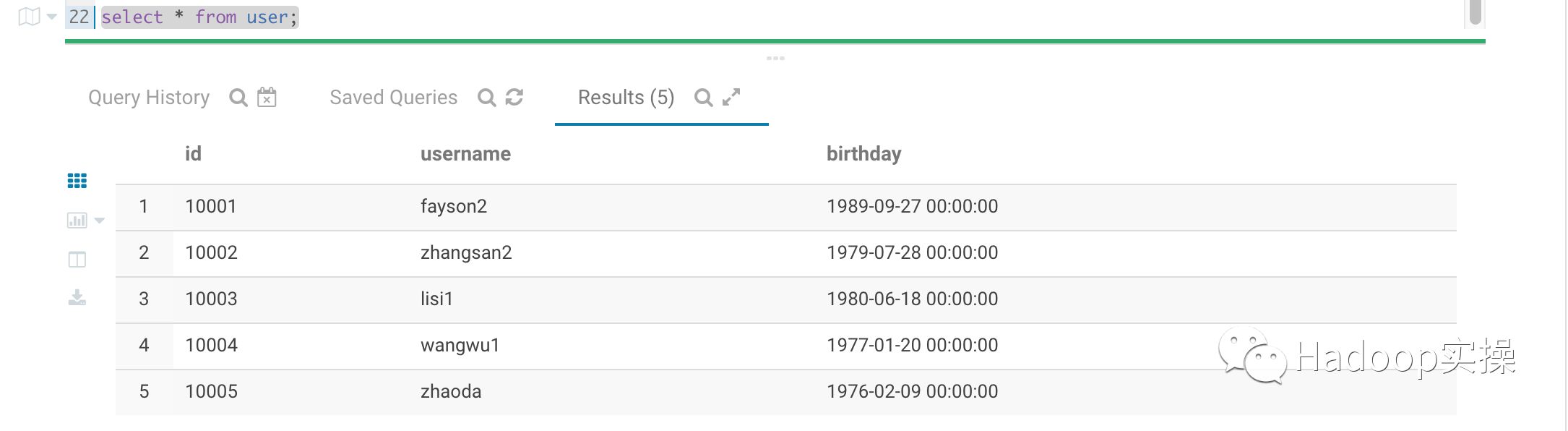
创建USRE_HIS表“2018-01-17”分区
ALTER TABLE user_his ADD PARTITION (end_dt= "2018-01-17");
(可左右滑动)
将用户的闭链数据插入到“2018-01-17”分区
INSERT overwrite TABLE user_his PARTITION (end_dt = "2018-01-17")
SELECT b.id,
b.username,
b.birthday,
b.start_dt
FROM USER a
LEFT JOIN user_his b ON a.id=b.id
WHERE b.end_dt = '9999-12-31'
AND (a.username != b.username
OR a.birthday != b.birthday);
(可左右滑动)

根据USER和USER_HIS中“2018-01-17”分区的闭链数据,更新所有用户开链数据:(含新增用户、闭链用户和开链用户)
INSERT overwrite TABLE user_his PARTITION(end_dt = '9999-12-31')
SELECT a.id,
a.username,
a.birthday,
b.end_dt AS start_dt
FROM USER a
LEFT JOIN user_his b ON a.id = b.id
WHERE b.end_dt = "2018-01-17"
union all
SELECT b.id,
b.username,
b.birthday,
b.start_dt
FROM user_his b
WHERE NOT EXISTS
(SELECT id
FROM user_his c
WHERE c.end_dt = "2018-01-17" and b.id = c.id)
AND b.end_dt = '9999-12-31'
union ALL
SELECT a.id,
a.username,
a.birthday,
"2018-01-17" AS start_dt
FROM USER a
WHERE NOT EXISTS
(SELECT 1
FROM user_his b
WHERE end_dt = '9999-12-31'
AND a.id = b.id);
(可左右滑动)
4.拉链表实现完整脚本
执行脚本的前置条件,拉链表已存在且已创建了开链分区,脚本中将分区替换为当前日期按照每天的一次的频率执行。
use test_db;
--创建当天闭链分区
ALTER TABLE user_his ADD PARTITION(end_dt= from_timestamp(now(), 'yyyy-MM-dd'));
--将闭链数据插入当天闭链分区中
INSERT overwrite TABLE user_his PARTITION(end_dt = from_timestamp(now(), 'yyyy-MM-dd'))
SELECT b.id,
b.username,
b.birthday,
b.start_dt
FROM USER a
LEFT JOIN user_his b ON a.id=b.id
WHERE b.end_dt = '9999-12-31'
AND (a.username != b.username
OR a.birthday != b.birthday);
--更新拉链表数据开链数据(包含已更新的用户、未更新用户和新增用户)
INSERT overwrite TABLE user_his PARTITION(end_dt = '9999-12-31')
SELECT a.id,
a.username,
a.birthday,
b.end_dt AS start_dt
FROM USER a
LEFT JOIN user_his b ON a.id = b.id
WHERE b.end_dt = from_timestamp(now(), 'yyyy-MM-dd')
union all
SELECT b.id,
b.username,
b.birthday,
b.start_dt
FROM user_his b
WHERE NOT EXISTS
(SELECT id
FROM user_his c
WHERE c.end_dt = from_timestamp(now(), 'yyyy-MM-dd') and b.id = c.id)
AND b.end_dt = '9999-12-31'
union ALL
SELECT a.id,
a.username,
a.birthday,
from_timestamp(now(), 'yyyy-MM-dd') AS start_dt
FROM USER a
WHERE NOT EXISTS
(SELECT 1
FROM user_his b
WHERE end_dt = '9999-12-31'
AND a.id = b.id);
(可左右滑动)
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于如何在Impala中实现拉链表的主要内容,如果未能解决你的问题,请参考以下文章