海云译见 | 深度学习最新进展:“IMPALA”深度强化多任务学习架构
Posted 海云数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海云译见 | 深度学习最新进展:“IMPALA”深度强化多任务学习架构相关的知识,希望对你有一定的参考价值。

深度强化学习已迅速成为深度学习生态系统中最热门的研究领域之一。强化学习之所以有如此大的魅力,是因为从所有的深度学习模式来看,它最近似于人类学习的模式。在过去的几年中,世界上没有任何一家公司比Alphabet的子公司DeepMind在深度强化学习方面做得更多。
自从著名的AlphaGo代理商发布以来,DeepMind一直处于强化学习研究的前沿。几天前,他们发布了一项新的研究,试图研究强化学习解决方案中最具挑战性的一面:多任务处理。
在我们还是一个婴儿的时候,多任务就成为了我们认知的固有要素。同时执行和学习类似任务的能力对于人类思维的发展至关重要。从神经科学的角度来看,多任务处理在很大程度上仍然是一个谜,对这一点我们无须感到奇怪,目前在实现理想中的“可以高效学习多个域而不需要占用过多资源”的人工智能代理方面,我们仍面临着很多困难。这种挑战在深度强化学习模型的情况下更为明显,这些模型基于可以轻松跨越单个领域界限的试验和错误为练习。不过从生物学角度讲,你可以争辩说,所有的学习都是多任务练习。
我们来看一个典型的深度强化学习场景,比如自驾车。在这种情况下,人工智能代理需要在快速变化的参数(如视觉质量或速度)下运行时,同时知悉不同方面,如距离,记忆或导航。目前大多数强化学习方法都侧重于学习单一任务,并且跟踪多任务学习的模型也难以应用于实践。
在最近的研究中,DeepMind团队提出了一种称为“IMPALA”的深度强化多任务学习的新架构。受另一种流行的强化学习架构A3C的启发,IMPALA利用不同参与者和学习者的拓扑结构,可以协作在不同领域建立知识。从传统角度来看,深度强化学习模型使用基于单个学习者与多个参与者相结合的架构。在该模型中,每个行为都会生成轨迹并通过队列发送给学习者。在开始下一个轨迹之前,进一步从学习者中检索最新的策略参数。IMPALA使用收集经验的体系结构,并将收集到的经验进一步传递给计算梯度的中央学习者,从而形成一个完全独立的行为和学习模型。同时,这种简单的架构,也使学习者能够加速使用显卡。
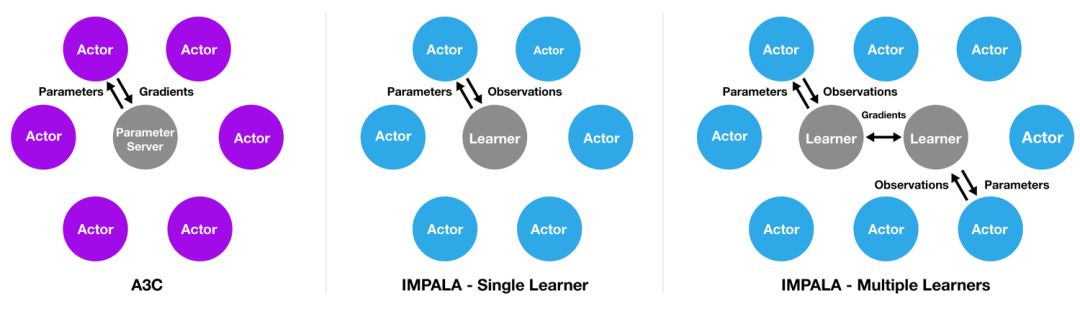
除了多参与者体系结构模型之外,IMPALA研究还引入了一种称为V-Trace的新算法,该算法专注于脱离政策学习,即减少行为动作产生的时间与学习者估计渐变时间之间的误差。
DeepMind团队使用著名的DMLab-30训练集在不同场景下测试了IMPALA,结果令人印象深刻。在数据效率、稳定性和最终性能方面,IMPALA的性能优于 A3C变体。这可能是第一个能够在多任务环境中有效运行的深度强化学习模型。
特别声明:本文转自Towards Data Science,由海云数据独家翻译。
合作须知:合作及投稿请在微信后台直接回复或发邮件:houqianru@hiynn.com
推荐阅读


海云数据(HYDATA)
海云数据是AI应用与可视分析领导者,专注于利用人工智能与可视分析技术,赋予用户在灵活科学地分析数据中形成更加智慧的业务决策能力,真正帮助用户实现业务场景中的效率提升与价值变现
你还可以在
【新浪微博】【今日头条】【一点资讯】
【百度百家】【搜狐新闻客户端】
【网易新闻客户端】【爱奇艺】
找到我们
如果你喜欢我们的文章请点击右上方分享哦
▼ 喜欢请按赞哟~ ヾ(o◕∀◕)ノ
以上是关于海云译见 | 深度学习最新进展:“IMPALA”深度强化多任务学习架构的主要内容,如果未能解决你的问题,请参考以下文章